
1. 引言
正如我们所知,NGINX 采用了异步、事件驱动的方法来处理连接。这种处理方式无需(像使用传统架构的服务器一样)为每个请求创建额外的专用进程或者线程,而是在一个工作进程中处理多个连接和请求。为此,NGINX 工作在非阻塞的socket 模式下,并使用了 epoll 和 kqueue 这样有效的方法。
因为满负载进程的数量很少(通常每核 CPU 只有一个)而且恒定,所以任务切换只消耗很少的内存,而且不会浪费 CPU 周期。通过 NGINX 本身的实例,这种方法的优点已经为众人所知。NGINX 可以非常好地处理百万级规模的并发请求。

每个进程都消耗额外的内存,而且每次进程间的切换都会消耗 CPU 周期并丢弃 CPU 高速缓存中的数据。
但是,异步、事件驱动方法仍然存在问题。或者,我喜欢将这一问题称为“敌兵”,这个敌兵的名字叫阻塞(blocking)。不幸的是,很多第三方模块使用了阻塞调用,然而用户(有时甚至是模块的开发者)并不知道阻塞的缺点。阻塞操作可以毁掉 NGINX 的性能,我们必须不惜一切代价避免使用阻塞。
即使在当前官方的 NGINX 代码中,依然无法在全部场景中避免使用阻塞, NGINX1.7.11 中实现的线程池机制解决了这个问题。我们将在后面讲述这个线程池是什么以及该如何使用。现在,让我们先和我们的“敌兵”进行一次面对面的碰撞。
2. 问题
首先,为了更好地理解这一问题,我们用几句话说明下 NGINX 是如何工作的。
通常情况下,NGINX 是一个事件处理器,即一个接收来自内核的所有连接事件的信息,然后向操作系统发出做什么指令的控制器。实际上,NGINX 干了编排操作系统的全部脏活累活,而操作系统做的是读取和发送字节这样的日常工作。所以,对于 NGINX 来说,快速和及时的响应是非常重要的。
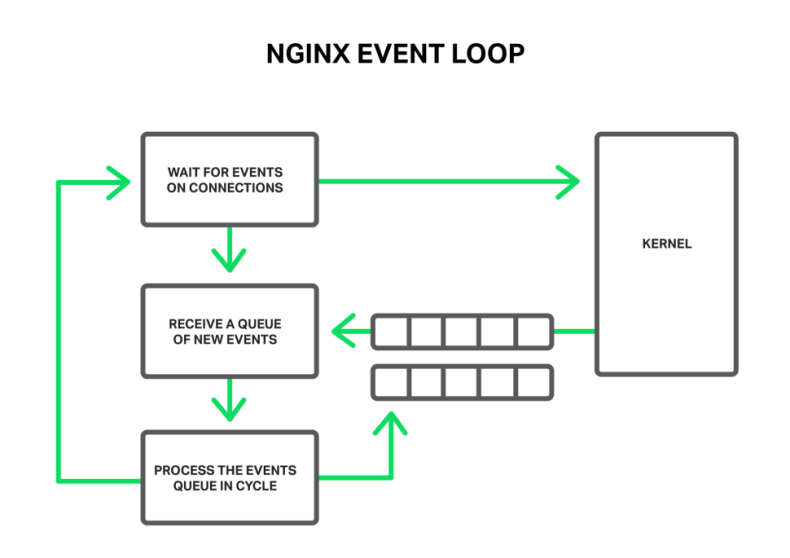
工作进程监听并处理来自内核的事件
事件可以是超时、socket 读写就绪的通知,或者发生错误的通知。NGINX 接收大量的事件,然后一个接一个地处理它们,并执行必要的操作。因此,所有的处理过程是通过一个线程中的队列,在一个简单循环中完成的。NGINX 从队列中取出一个事件并对其做出响应,比如读写 socket。在多数情况下,这种方式是非常快的(也许只需要几个 CPU 周期,将一些数据复制到内存中),NGINX 可以在一瞬间处理掉队列中的所有事件。

所有处理过程是在一个简单的循环中,由一个线程完成
但是,如果 NGINX 要处理的操作是一些又长又重的操作,又会发生什么呢?整个事件处理循环将会卡住,等待这个操作执行完毕。
因此,所谓“阻塞操作”是指任何导致事件处理循环显著停止一段时间的操作。操作可以由于各种原因成为阻塞操作。例如,NGINX 可能因长时间、CPU 密集型处理,或者可能等待访问某个资源(比如硬盘,或者一个互斥体,亦或要从处于同步方式的数据库获得相应的库函数调用等)而繁忙。关键是在处理这样的操作期间,工作进程无法做其他事情或者处理其他事件,即使有更多的可用系统资源可以被队列中的一些事件所利用。
我们来打个比方,一个商店的营业员要接待他面前排起的一长队顾客。队伍中的第一位顾客想要的某件商品不在店里而在仓库中。这位营业员跑去仓库把东西拿来。现在整个队伍必须为这样的配货方式等待数个小时,队伍中的每个人都很不爽。你可以想见人们的反应吧?队伍中每个人的等待时间都要增加这些时间,除非他们要买的东西就在店里。
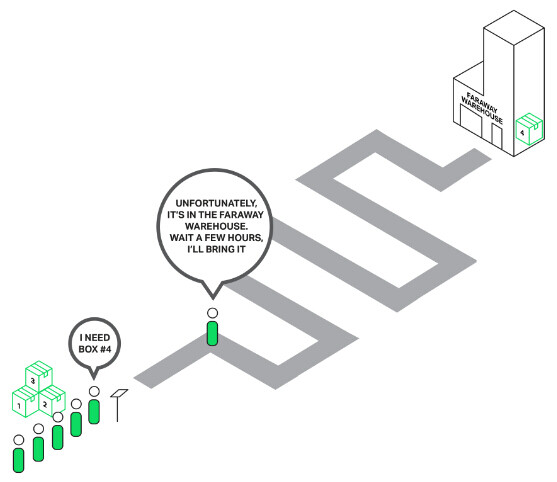
队伍中的每个人不得不等待第一个人的购买
在 NGINX 中会发生几乎同样的情况,比如当读取一个文件的时候,如果该文件没有缓存在内存中,就要从磁盘上读取。从磁盘(特别是旋转式的磁盘)读取是很慢的, 而当队列中等待的其他请求可能不需要访问磁盘时,它们也得被迫等待。导致的结果是,延迟增加并且系统资源没有得到充分利用。
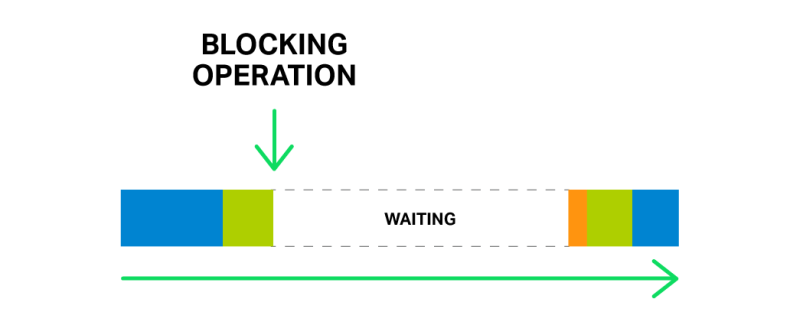
一个阻塞操作足以显著地延缓所有接下来的操作
一些操作系统为读写文件提供了异步接口,NGINX 可以使用这样的接口(见 AIO 指令)。FreeBSD 就是个很好的例子。不幸的是,我们不能在 Linux 上得到相同的福利。虽然 Linux 为读取文件提供了一种异步接口,但是存在明显的缺点。其中之一是要求文件访问和缓冲要对齐,但 NGINX 很好地处理了这个问题。但是,另一个缺点更糟糕。异步接口要求文件描述符中要设置 O_DIRECT 标记,就是说任何对文件的访问都将绕过内存中的缓存,这增加了磁盘的负载。在很多场景中,这都绝对不是最佳选择。
为了有针对性地解决这一问题,在 NGINX 1.7.11 中引入了线程池。默认情况下,NGINX+ 还没有包含线程池,但是如果你想试试的话,可以联系销售人员,NGINX+ R6 是一个已经启用了线程池的构建版本。
现在,让我们走进线程池,看看它是什么以及如何工作的。
3. 线程池
让我们回到那个可怜的,要从大老远的仓库去配货的售货员那儿。这回,他已经变聪明了(或者也许是在一群愤怒的顾客教训了一番之后,他才变得聪明的?),雇用了一个配货服务团队。现在,当任何人要买的东西在大老远的仓库时,他不再亲自去仓库了,只需要将订单丢给配货服务,他们将处理订单,同时,我们的售货员依然可以继续为其他顾客服务。因此,只有那些要买仓库里东西的顾客需要等待配货,其他顾客可以得到即时服务。
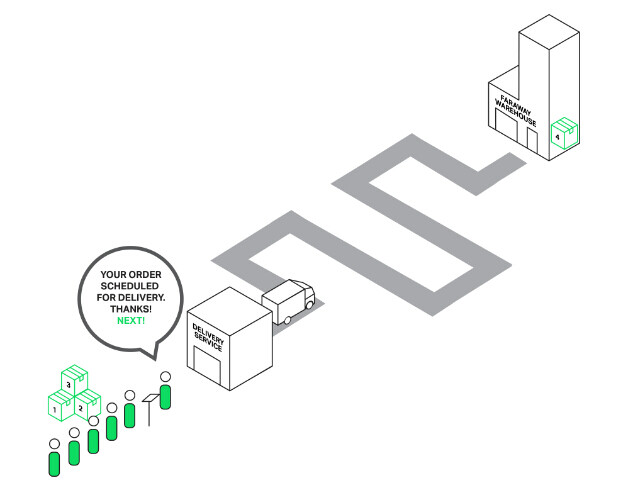
传递订单给配货服务不会阻塞队伍
对 NGINX 而言,线程池执行的就是配货服务的功能。它由一个任务队列和一组处理这个队列的线程组成。
当工作进程需要执行一个潜在的长操作时,工作进程不再自己执行这个操作,而是将任务放到线程池队列中,任何空闲的线程都可以从队列中获取并执行这个任务。

工作进程将阻塞操作卸给线程池
那么,这就像我们有了另外一个队列。是这样的,但是在这个场景中,队列受限于特殊的资源。磁盘的读取速度不能比磁盘产生数据的速度快。不管怎么说,至少现在磁盘不再延误其他事件,只有访问文件的请求需要等待。
“从磁盘读取”这个操作通常是阻塞操作最常见的示例,但是实际上,NGINX 中实现的线程池可用于处理任何不适合在主循环中执行的任务。
目前,卸载到线程池中执行的两个基本操作是大多数操作系统中的 read() 系统调用和 Linux 中的 sendfile()。接下来,我们将对线程池进行测试(test)和基准测试(benchmark),在未来的版本中,如果有明显的优势,我们可能会卸载其他操作到线程池中。
4. 基准测试
现在让我们从理论过度到实践。我们将进行一次模拟基准测试(synthetic benchmark),模拟在阻塞操作和非阻塞操作的最差混合条件下,使用线程池的效果。
另外,我们需要一个内存肯定放不下的数据集。在一台 48GB 内存的机器上,我们已经产生了每文件大小为 4MB 的随机数据,总共 256GB,然后配置 NGINX,版本为 1.9.0。
配置很简单:
worker_processes <span>16</span>; events { accept_mutex <span>off</span>; } http { <span>include</span> mime.types; default_type application/octet-stream; access_log <span>off</span>; sendfile <span>on</span>; sendfile_max_chunk <span>512</span>k; server { listen <span>8000</span>; location / { root /storage; } } } {1}
如上所示,为了达到更好的性能,我们调整了几个参数:禁用了 logging 和 accept_mutex ,同时,启用了 sendfile 并设置了 sendfile_max_chunk 的大小。最后一个指令可以减少阻塞调用 sendfile() 所花费的最长时间,因为 NGINX 不会尝试一次将整个文件发送出去,而是每次发送大小为 512KB 的块数据。
这台测试服务器有 2 个 Intel Xeon E5645 处理器(共计:12 核、24 超线程)和 10-Gbps 的网络接口。磁盘子系统是由 4 块西部数据 WD1003FBYX 磁盘组成的 RAID10 阵列。所有这些硬件由 Ubuntu 服务器 14.04.1 LTS 供电。
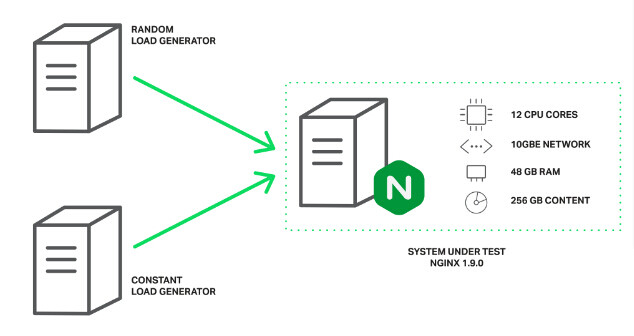
为基准测试配置负载生成器和 NGINX
客户端有 2 台服务器,它们的规格相同。在其中一台上,在 ** wrk ** 中使用 Lua 脚本创建了负载程序。脚本使用 200 个并行连接向服务器请求文件,每个请求都可能未命中缓存而从磁盘阻塞读取。我们将这种负载称作 _ 随机负载 _。
在另一台客户端机器上,我们将运行wrk的另一个副本,使用 50 个并行连接多次请求同一个文件。因为这个文件将被频繁地访问,所以它会一直驻留在内存中。在正常情况下,NGINX 能够非常快速地服务这些请求,但是如果工作进程被其他请求阻塞的话,性能将会下降。我们将这种负载称作 _ 恒定负载 _。
性能将由服务器上ifstat监测的吞吐率(throughput)和从第二台客户端获取的wrk结果来度量。
现在,没有使用线程池的第一次运行将不会带给我们非常振奋的结果:
% ifstat -bi eth2 eth2 Kbps <span>in</span> Kbps <span>out</span> <span>5531.24</span> <span>1.03e+06</span> <span>4855.23</span> <span>812922.7</span> <span>5994.66</span> <span>1.07e+06</span> <span>5476.27</span> <span>981529.3</span> <span>6353.62</span> <span>1.12e+06</span> <span>5166.17</span> <span>892770.3</span> <span>5522.81</span> <span>978540.8</span> <span>6208.10</span> <span>985466.7</span> <span>6370.79</span> <span>1.12e+06</span> <span>6123.33</span> <span>1.07e+06</span>
如上所示,使用这种配置,服务器产生的总流量约为 1Gbps。从下面所示的top输出,我们可以看到,工作进程的大部分时间花在阻塞 I/O 上(它们处于 top 的 D 状态):
<span>top</span> <span>-</span> 10<span>:40</span><span>:47</span> <span>up</span> 11 <span>days</span>, 1<span>:32</span>, 1 <span>user</span>, <span>load</span> <span>average</span>: 49<span>.61</span>, 45<span>.77</span> 62<span>.89</span> <span>Tasks</span>: 375 <span>total</span>, 2 <span>running</span>, 373 <span>sleeping</span>, 0 <span>stopped</span>, 0 <span>zombie</span> %<span>Cpu</span>(<span>s</span>): 0<span>.0</span> <span>us</span>, 0<span>.3</span> <span>sy</span>, 0<span>.0</span> <span>ni</span>, 67<span>.7</span> <span>id</span>, 31<span>.9</span> <span>wa</span>, 0<span>.0</span> <span>hi</span>, 0<span>.0</span> <span>si</span>, 0<span>.0</span> <span>st</span> <span>KiB</span> <span>Mem</span>: 49453440 <span>total</span>, 49149308 <span>used</span>, 304132 <span>free</span>, 98780 <span>buffers</span> <span>KiB</span> <span>Swap</span>: 10474236 <span>total</span>, 20124 <span>used</span>, 10454112 <span>free</span>, 46903412 <span>cached</span> <span>Mem</span> <span>PID</span> <span>USER</span> <span>PR</span> <span>NI</span> <span>VIRT</span> <span>RES</span> <span>SHR</span> <span>S</span> %<span>CPU</span> %<span>MEM</span> <span>TIME</span>+ <span>COMMAND</span> 4639 <span>vbart</span> 20 0 47180 28152 496 <span>D</span> 0<span>.7</span> 0<span>.1</span> 0<span>:00</span><span>.17</span> <span>nginx</span> 4632 <span>vbart</span> 20 0 47180 28196 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.11</span> <span>nginx</span> 4633 <span>vbart</span> 20 0 47180 28324 540 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.11</span> <span>nginx</span> 4635 <span>vbart</span> 20 0 47180 28136 480 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.12</span> <span>nginx</span> 4636 <span>vbart</span> 20 0 47180 28208 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.14</span> <span>nginx</span> 4637 <span>vbart</span> 20 0 47180 28208 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.10</span> <span>nginx</span> 4638 <span>vbart</span> 20 0 47180 28204 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.12</span> <span>nginx</span> 4640 <span>vbart</span> 20 0 47180 28324 540 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.13</span> <span>nginx</span> 4641 <span>vbart</span> 20 0 47180 28324 540 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.13</span> <span>nginx</span> 4642 <span>vbart</span> 20 0 47180 28208 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.11</span> <span>nginx</span> 4643 <span>vbart</span> 20 0 47180 28276 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.29</span> <span>nginx</span> 4644 <span>vbart</span> 20 0 47180 28204 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.11</span> <span>nginx</span> 4645 <span>vbart</span> 20 0 47180 28204 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.17</span> <span>nginx</span> 4646 <span>vbart</span> 20 0 47180 28204 536 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.12</span> <span>nginx</span> 4647 <span>vbart</span> 20 0 47180 28208 532 <span>D</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.17</span> <span>nginx</span> 4631 <span>vbart</span> 20 0 47180 756 252 <span>S</span> 0<span>.0</span> 0<span>.1</span> 0<span>:00</span><span>.00</span> <span>nginx</span> 4634 <span>vbart</span> 20 0 47180 28208 536 <span>D</span> 0<span>.0</span> 0<span>.1</span> 0<span>:00</span><span>.11</span> <span>nginx</span> 4648 <span>vbart</span> 20 0 25232 1956 1160 <span>R</span> 0<span>.0</span> 0<span>.0</span> 0<span>:00</span><span>.08</span> <span>top</span> 25921 <span>vbart</span> 20 0 121956 2232 1056 <span>S</span> 0<span>.0</span> 0<span>.0</span> 0<span>:01</span><span>.97</span> <span>sshd</span> 25923 <span>vbart</span> 20 0 40304 4160 2208 <span>S</span> 0<span>.0</span> 0<span>.0</span> 0<span>:00</span><span>.53</span> <span>zsh</span>
在这种情况下,吞吐率受限于磁盘子系统,而 CPU 在大部分时间里是空闲的。从wrk获得的结果也非常低:
Running <span>1</span>m test @ <span>http</span>://<span>192.0</span><span>.2</span><span>.1</span>:<span>8000</span>/<span>1</span>/<span>1</span>/<span>1</span> <span>12</span> threads <span>and</span> <span>50</span> connections Thread Stats Avg Stdev Max +/- Stdev Latency <span>7.42</span>s <span>5.31</span>s <span>24.41</span>s <span>74.73</span>% Req/Sec <span>0.15</span> <span>0.36</span> <span>1.00</span> <span>84.62</span>% <span>488</span> requests <span>in</span> <span>1.01</span>m, <span>2.01</span>GB <span>read</span> Requests/<span>sec</span>: <span>8.08</span> Transfer/<span>sec</span>: <span>34.07</span>MB
请记住,文件是从内存送达的!第一个客户端的 200 个连接创建的随机负载,使服务器端的全部的工作进程忙于从磁盘读取文件,因此产生了过大的延迟,并且无法在合理的时间内处理我们的请求。
现在,我们的线程池要登场了。为此,我们只需在location块中添加 aio threads 指令:
location / <span>{ root /storage; aio threads; }</span>
接着,执行 NGINX reload 重新加载配置。
然后,我们重复上述的测试:
% ifstat -bi eth2 eth2 Kbps <span>in</span> Kbps <span>out</span> <span>60915.19</span> <span>9.51e+06</span> <span>59978.89</span> <span>9.51e+06</span> <span>60122.38</span> <span>9.51e+06</span> <span>61179.06</span> <span>9.51e+06</span> <span>61798.40</span> <span>9.51e+06</span> <span>57072.97</span> <span>9.50e+06</span> <span>56072.61</span> <span>9.51e+06</span> <span>61279.63</span> <span>9.51e+06</span> <span>61243.54</span> <span>9.51e+06</span> <span>59632.50</span> <span>9.50e+06</span>
现在,我们的服务器产生的流量是9.5Gbps,相比之下,没有使用线程池时只有约 1Gbps!
理论上还可以产生更多的流量,但是这已经达到了机器的最大网络吞吐能力,所以在这次 NGINX 的测试中,NGINX 受限于网络接口。工作进程的大部分时间只是休眠和等待新的事件(它们处于 top 的 S 状态):
<span>top</span> <span>-</span> 10<span>:43</span><span>:17</span> <span>up</span> 11 <span>days</span>, 1<span>:35</span>, 1 <span>user</span>, <span>load</span> <span>average</span>: 172<span>.71</span>, 93<span>.84</span>, 77<span>.90</span> <span>Tasks</span>: 376 <span>total</span>, 1 <span>running</span>, 375 <span>sleeping</span>, 0 <span>stopped</span>, 0 <span>zombie</span> %<span>Cpu</span>(<span>s</span>): 0<span>.2</span> <span>us</span>, 1<span>.2</span> <span>sy</span>, 0<span>.0</span> <span>ni</span>, 34<span>.8</span> <span>id</span>, 61<span>.5</span> <span>wa</span>, 0<span>.0</span> <span>hi</span>, 2<span>.3</span> <span>si</span>, 0<span>.0</span> <span>st</span> <span>KiB</span> <span>Mem</span>: 49453440 <span>total</span>, 49096836 <span>used</span>, 356604 <span>free</span>, 97236 <span>buffers</span> <span>KiB</span> <span>Swap</span>: 10474236 <span>total</span>, 22860 <span>used</span>, 10451376 <span>free</span>, 46836580 <span>cached</span> <span>Mem</span> <span>PID</span> <span>USER</span> <span>PR</span> <span>NI</span> <span>VIRT</span> <span>RES</span> <span>SHR</span> <span>S</span> %<span>CPU</span> %<span>MEM</span> <span>TIME</span>+ <span>COMMAND</span> 4654 <span>vbart</span> 20 0 309708 28844 596 <span>S</span> 9<span>.0</span> 0<span>.1</span> 0<span>:08</span><span>.65</span> <span>nginx</span> 4660 <span>vbart</span> 20 0 309748 28920 596 <span>S</span> 6<span>.6</span> 0<span>.1</span> 0<span>:14</span><span>.82</span> <span>nginx</span> 4658 <span>vbart</span> 20 0 309452 28424 520 <span>S</span> 4<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.40</span> <span>nginx</span> 4663 <span>vbart</span> 20 0 309452 28476 572 <span>S</span> 4<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.32</span> <span>nginx</span> 4667 <span>vbart</span> 20 0 309584 28712 588 <span>S</span> 3<span>.7</span> 0<span>.1</span> 0<span>:05</span><span>.19</span> <span>nginx</span> 4656 <span>vbart</span> 20 0 309452 28476 572 <span>S</span> 3<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.84</span> <span>nginx</span> 4664 <span>vbart</span> 20 0 309452 28428 524 <span>S</span> 3<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.29</span> <span>nginx</span> 4652 <span>vbart</span> 20 0 309452 28476 572 <span>S</span> 3<span>.0</span> 0<span>.1</span> 0<span>:01</span><span>.46</span> <span>nginx</span> 4662 <span>vbart</span> 20 0 309552 28700 596 <span>S</span> 2<span>.7</span> 0<span>.1</span> 0<span>:05</span><span>.92</span> <span>nginx</span> 4661 <span>vbart</span> 20 0 309464 28636 596 <span>S</span> 2<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.59</span> <span>nginx</span> 4653 <span>vbart</span> 20 0 309452 28476 572 <span>S</span> 1<span>.7</span> 0<span>.1</span> 0<span>:01</span><span>.70</span> <span>nginx</span> 4666 <span>vbart</span> 20 0 309452 28428 524 <span>S</span> 1<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.63</span> <span>nginx</span> 4657 <span>vbart</span> 20 0 309584 28696 592 <span>S</span> 1<span>.0</span> 0<span>.1</span> 0<span>:00</span><span>.64</span> <span>nginx</span> 4655 <span>vbart</span> 20 0 30958 28476 572 <span>S</span> 0<span>.7</span> 0<span>.1</span> 0<span>:02</span><span>.81</span> <span>nginx</span> 4659 <span>vbart</span> 20 0 309452 28468 564 <span>S</span> 0<span>.3</span> 0<span>.1</span> 0<span>:01</span><span>.20</span> <span>nginx</span> 4665 <span>vbart</span> 20 0 309452 28476 572 <span>S</span> 0<span>.3</span> 0<span>.1</span> 0<span>:00</span><span>.71</span> <span>nginx</span> 5180 <span>vbart</span> 20 0 25232 1952 1156 <span>R</span> 0<span>.0</span> 0<span>.0</span> 0<span>:00</span><span>.45</span> <span>top</span> 4651 <span>vbart</span> 20 0 20032 752 252 <span>S</span> 0<span>.0</span> 0<span>.0</span> 0<span>:00</span><span>.00</span> <span>nginx</span> 25921 <span>vbart</span> 20 0 121956 2176 1000 <span>S</span> 0<span>.0</span> 0<span>.0</span> 0<span>:01</span><span>.98</span> <span>sshd</span> 25923 <span>vbart</span> 20 0 40304 3840 2208 <span>S</span> 0<span>.0</span> 0<span>.0</span> 0<span>:00</span><span>.54</span> <span>zsh</span>
如上所示,基准测试中还有大量的 CPU 资源剩余。
wrk 的结果如下:
Running <span>1</span>m test @ <span>http</span>://<span>192.0</span><span>.2</span><span>.1</span>:<span>8000</span>/<span>1</span>/<span>1</span>/<span>1</span> <span>12</span> threads <span>and</span> <span>50</span> connections Thread Stats Avg Stdev Max +/- Stdev Latency <span>226.32</span>ms <span>392.76</span>ms <span>1.72</span>s <span>93.48</span>% Req/Sec <span>20.02</span> <span>10.84</span> <span>59.00</span> <span>65.91</span>% <span>15045</span> requests <span>in</span> <span>1.00</span>m, <span>58.86</span>GB <span>read</span> Requests/<span>sec</span>: <span>250.57</span> Transfer/<span>sec</span>: <span>0.98</span>GB
服务器处理 4MB 文件的平均时间从 7.42 秒降到 226.32 毫秒(减少了 33 倍),每秒请求处理数提升了 31 倍(250 vs 8)!
对此,我们的解释是请求不再因为工作进程被阻塞在读文件,而滞留在事件队列中,等待处理,它们可以被空闲的进程处理掉。只要磁盘子系统能做到最好,就能服务好第一个客户端上的随机负载,NGINX 可以使用剩余的 CPU 资源和网络容量,从内存中读取,以服务于上述的第二个客户端的请求。
5. 依然没有银弹
在抛出我们对阻塞操作的担忧并给出一些令人振奋的结果后,可能大部分人已经打算在你的服务器上配置线程池了。先别着急。
实际上,最幸运的情况是,读取和发送文件操作不去处理缓慢的硬盘驱动器。如果我们有足够多的内存来存储数据集,那么操作系统将会足够聪明地在被称作“页面缓存”的地方,缓存频繁使用的文件。
“页面缓存”的效果很好,可以让 NGINX 在几乎所有常见的用例中展示优异的性能。从页面缓存中读取比较快,没有人会说这种操作是“阻塞”。而另一方面,卸载任务到一个线程池是有一定开销的。
因此,如果内存有合理的大小并且待处理的数据集不是很大的话,那么无需使用线程池,NGINX 已经工作在最优化的方式下。
卸载读操作到线程池是一种适用于非常特殊任务的技术。只有当经常请求的内容的大小,不适合操作系统的虚拟机缓存时,这种技术才是最有用的。至于可能适用的场景,比如,基于 NGINX 的高负载流媒体服务器。这正是我们已经模拟的基准测试的场景。
我们如果可以改进卸载读操作到线程池,将会非常有意义。我们只需要知道所需的文件数据是否在内存中,只有不在内存中时,读操作才应该卸载到一个单独的线程中。
再回到售货员那个比喻的场景中,这回,售货员不知道要买的商品是否在店里,他必须要么总是将所有的订单提交给配货服务,要么总是亲自处理它们。
人艰不拆,操作系统缺少这样的功能。第一次尝试是在 2010 年,人们试图将这一功能添加到 Linux 作为 fincore() 系统调用,但是没有成功。后来还有一些尝试,是使用 RWF_NONBLOCK 标记作为 preadv2() 系统调用来实现这一功能(详情见 LWN.net 上的非阻塞缓冲文件读取操作和异步缓冲读操作)。但所有这些补丁的命运目前还不明朗。悲催的是,这些补丁尚没有被内核接受的主要原因,貌似是因为旷日持久的撕逼大战( bikeshedding )。
另一方面,FreeBSD 的用户完全不必担心。FreeBSD 已经具备足够好的异步读取文件接口,我们应该用这个接口而不是线程池。
6. 配置线程池
所以,如果你确信在你的场景中使用线程池可以带来好处,那么现在是时候深入了解线程池的配置了。
线程池的配置非常简单、灵活。首先,获取 NGINX 1.7.11 或更高版本的源代码,使用--with-threads配置参数编译。在最简单的场景中,配置看起来很朴实。我们只需要在http、 server,或者location上下文中包含 aio threads 指令即可:
aio threads;这是线程池的最简配置。实际上的精简版本示例如下:
<span>thread_pool</span> <span><span>default</span> threads=32 max_queue=65536;</span> <span>aio</span> threads=<span><span>default</span>;</span>
这里定义了一个名为“default”,包含 32 个线程,任务队列最多支持 65536 个请求的线程池。如果任务队列过载,NGINX 将输出如下错误日志并拒绝请求:
<span>thread</span> pool <span>"NAME"</span> <span>queue</span> overflow: N tasks waiting错误输出意味着线程处理作业的速度有可能低于任务入队的速度了。你可以尝试增加队列的最大值,但是如果这无济于事,那么这说明你的系统没有能力处理如此多的请求了。
正如你已经注意到的,你可以使用 thread_pool 指令,配置线程的数量、队列的最大值,以及线程池的名称。最后要说明的是,可以配置多个独立的线程池,将它们置于不同的配置文件中,用做不同的目的:
http <span>{ thread_pool one threads=128 max_queue=0; thread_pool two threads=32; server { location /one { aio threads=one; }</span> location /two <span>{ aio threads=two; }</span> } … }
如果没有指定max_queue参数的值,默认使用的值是 65536。如上所示,可以设置max_queue为 0。在这种情况下,线程池将使用配置中全部数量的线程,尽可能地同时处理多个任务;队列中不会有等待的任务。
现在,假设我们有一台服务器,挂了 3 块硬盘,我们希望把该服务器用作“缓存代理”,缓存后端服务器的全部响应信息。预期的缓存数据量远大于可用的内存。它实际上是我们个人 CDN 的一个缓存节点。毫无疑问,在这种情况下,最重要的事情是发挥硬盘的最大性能。
我们的选择之一是配置一个 RAID 阵列。这种方法毁誉参半,现在,有了 NGINX,我们可以有其他的选择:
proxy_cache_path /mnt/disk1 levels=<span>1</span>:<span>2</span> keys_zone=cache_1:<span>256</span>m max_size=<span>1024</span>G use_temp_path=off; proxy_cache_path /mnt/disk2 levels=<span>1</span>:<span>2</span> keys_zone=cache_2:<span>256</span>m max_size=<span>1024</span>G use_temp_path=off; proxy_cache_path /mnt/disk3 levels=<span>1</span>:<span>2</span> keys_zone=cache_3:<span>256</span>m max_size=<span>1024</span>G use_temp_path=off; thread_pool pool_1 threads=<span>16</span>; thread_pool pool_2 threads=<span>16</span>; thread_pool pool_3 threads=<span>16</span>; split_clients <span>$request_uri</span> <span>$disk</span> { <span>33.3</span>% <span>1</span>; <span>33.3</span>% <span>2</span>; * <span>3</span>; } location / { proxy_pass http: proxy_cache_key <span>$request_uri</span>; proxy_cache cache_<span>$disk</span>; aio threads=pool_<span>$disk</span>; sendfile on; } {1}
在这份配置中,使用了 3 个独立的缓存,每个缓存专用一块硬盘,另外,3 个独立的线程池也各自专用一块硬盘。
缓存之间(其结果就是磁盘之间)的负载均衡使用 split_clients 模块,split_clients非常适用于这个任务。
在 proxy_cache_path 指令中设置use_temp_path=off,表示 NGINX 会将临时文件保存在缓存数据的同一目录中。这是为了避免在更新缓存时,磁盘之间互相复制响应数据。
这些调优将带给我们磁盘子系统的最大性能,因为 NGINX 通过单独的线程池并行且独立地与每块磁盘交互。每块磁盘由 16 个独立线程和读取和发送文件专用任务队列提供服务。
我敢打赌,你的客户喜欢这种量身定制的方法。请确保你的磁盘也持有同样的观点。
这个示例很好地证明了 NGINX 可以为硬件专门调优的灵活性。这就像你给 NGINX 下了一道命令,让机器和数据用最佳姿势来搞基。而且,通过 NGINX 在用户空间中细粒度的调优,我们可以确保软件、操作系统和硬件工作在最优模式下,尽可能有效地利用系统资源。
7. 总结
综上所述,线程池是一个伟大的功能,将 NGINX 推向了新的性能水平,除掉了一个众所周知的长期危害——阻塞——尤其是当我们真正面对大量内容的时候。
甚至,还有更多的惊喜。正如前面提到的,这个全新的接口,有可能没有任何性能损失地卸载任何长期阻塞操作。NGINX 在拥有大量的新模块和新功能方面,开辟了一方新天地。许多流行的库仍然没有提供异步非阻塞接口,此前,这使得它们无法与 NGINX 兼容。我们可以花大量的时间和资源,去开发我们自己的无阻塞原型库,但这么做始终都是值得的吗?现在,有了线程池,我们可以相对容易地使用这些库,而不会影响这些模块的性能。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...








评论