
3 事件管理
事件管理应当是整个 RichClient/RIA 开发中的最难以把握的部分。这部分控制的好,你的程序用起来将如行云流水,用户的思维不会被打断。任何一 个做 RichClient 开发的程序员,可以对其他方面毫无所知,但这部分应当非常熟悉。事件是 RichClient 的核心,是“一切皆异步”的终极实现。前面所说的例子,实际上可以被抽象为事件,例如第一个,获取股票数据,从事件的观点看,应该是:
- 开始获取股票数据
- 正在获取股票数据
- 获取数据完成
- 获取数据失败
看起来相当复杂。然而这样去考虑的时候,你可以将执行计算与界面展现清晰的分开。界面只需要响应事件,运算可以在另外的地方 悄悄的进行,并当任务完成或者失败的是时候报告相应的事件。从经验看来,往往同样的数据会在不同的地方进行不同的展示,例如 skype 在通话的时候这个人 的头像会显示为占线,而具体的通话窗口中又是另外不同的展现;MSN 的个人签名在好友列表窗口中显示为一个点击可以编辑控件,而同时在聊天窗口显示为一个 不能点击只能看的标签。这是 RichClient 的特性,你永远不知道同一份数据会以什么形式来展现,更要命的是,当数据在一个地方更新的时候,其他所有 能展现的地方都需要同时做相应的更新。如果我们仍然以第一部分的例子,简单采用runInAnoterThread是完全不能解决这个问题的。
我们曾经犯过一些很严重的错误,导致最终即便重构都积重难返。无视事件的抽象带来的影响是架构级别的,小修小补将无济于事。
事件的实现方式可以有很多种。对于没有事件支持的语言,接口或者干脆某一个约束的方法就可以。有事件支持的语言能够享受到好处,但仍然是语法级别的,根本 是一样的。观察者模式在这里很好用。仍然以股票为例,被观察的对象就是获取股票数据对象StockDataRetriver,观察的就是StockWindow:
StockDataRetriver { observers: [] retrieve() { try { theData = ...// 从远程获取数据 observers.each {|o| o.stockDataReady(theData)} // 触发数据获取成功事件 } catch { observers.each { |o| o.stockDataFailed() } // 触发事件获取失败事件 } } } StockDataRetriver.observers.add(StockWindow) // 将 StockWindow 加入到观察者队列 StockWindow { stockDataReady(theData) { showDataInUIThread(); // 在 UI 线程显示数据 } stockDataFailed() { showErrorInUIThread(); // 在 UI 线程显示错误 } }
你会发现代码变得简单。UI 与计算之间的耦合被事件解开,并且区分 UI 线程与运算线程之间也变得容易。当尝试以事件的视角去观察整个应用程序的时候,你会更关注于用户与界面之间的交互。
让我们继续抽象。如果把“获取股票数据”这个按钮点击,让StockDataRetriver去获取数据当作事件来处理,应该怎么写呢?将按钮作为被观察 者,StockDataRetriver作为观察者显然不好,好不容易分开的耦合又黏在一起。引入一个中间的Events看起来不错:
Events { listeners: {} register(eventId, listener) { listeners[eventId].add(listener) } broadcast(eventId) { listeners[eventId].observers.each{|o| o.doSomething(); } } }
Events中维护了一个listeners的列表,它是一个简单的 Hash 结构,key 是eventId,value 是observer的列表;它提供了两个方法,用来注册事件监听以及通知事件产生。对于上面的案例,可以先注册StockDataRetriver为一个观察者,观察start_retrive_stock_data事件:
Events.register('start_retrive_stock_data', StockDataRetriever)
当点击“获取股票数据”按钮的时候,可以是这样:
Events.broadcast('start_retrive_stock_data')
你会发现StockDataRetriver能够老老实实的开始获取数据了。
需要注意的是,并非将所有事件定义为全局事件是一个好的实践。在更大规模的系统中,将事件进行有效整理和分级是有好处的。在强类型的语言(如 Java/C#)中,抽象出强类型的EventId,能够帮助理解系统和进行编程,避免到处进行强制类型转换。例如,StockEvent:
StockDataLoadedEvent { StockData theData; StockDataLoadedEvent(StockData theData); } Event.broadcast(new StockDataLoadedEvent(loadedData))
这个事件的监听者能够不加类型转换的获得StockData数据。上面的例子是不支持事件的语言,C#语言支持自定义强类型的事件,用起来要自然一些:
delegate void StockDataLoaded(StockData theData)
事件管理原则我相信并不难理解。然而困难的是具体实现。对一个新的 UI 框架不熟悉的时候,我们经常在“代码的优美”与“界面提供的特性”之间徘徊。实现这 样的一个事件架构需要在项目一开始就稍具雏形,并且所有的事件都有良好的命名和管理。避免在命名、使用事件的时候的随意性,对于让代码可读、应用稳定有非 常大的意义。一个好的事件管理、通知机制是一个良好 RichClient 应用的根本基础。一般说来,你正在使用的编程平台如 Swing/WinForm /WPF/Flex 等能够提供良好的事件响应机制,即监听事件、onXXX 等,但一般没有统一的事件的监听和管理机制。对于架构师,对于要使用的编程平台 对于这些的原生支持要了熟于心,在编写这样的事件架构的时候也能兼顾这些语言、平台提供给你的支持。
采用了事件的事件后,你不得不同时实践“线程管理”,因为事件一般来说意味着将耗时的操作放到别的地方完成,当完成的时候进行事件通知。简单的模式下,你可以在所有需要进行异步运算的地方,将运算放到另外一个线程,如ThreadPool.QueueUserWorkItem, 在运算完成的时候通知事件。但从资源的角度考虑,将这些线程资源有效的管理也是很重要的,在“线程管理”部分有详细的阐述。另外,如果能将你的应用转变为 数据驱动的,你需要关注“缓存以及本地存储”。
4 线程管理
在 WEB 开发几乎无需考虑线程,所有的页面渲染由浏览器完成,浏览器会异步的进行文字和图片的渲染。我们只需要写界面和 JavaScript 就好。如果你认同“一切皆异步”,你一定得考虑线程管理。
毫无管理的线程处理是这样的:凡是需要进行异步调用的地方,都新起一个线程来进行运算,例如前面提到的runInThread的实现。这种方式如果托管在 在“事件管理”之下,问题不大,只会给测试带来一些麻烦:你不得不 wait 一段时间来确定是否耗时操作完成。这种方式很山寨,也无法实现更高级功能。更好 的的方式是将这些线程资源进行统筹管理。
线程的管理的核心功能是用来统一化所有的耗时操作,最简单的TaskExecutor如下:
TaskExecutor { void pendTask(task) { //task: 耗时操作任务 runInThread { task.run(); // 运行任务 } } } RetrieveStockDataTask extends Task { void run() { theData = ... // 直接获取远程数据,不用在另外线程中执行 Events.broadcast(new StockDataLoadedEvent(theData)) // 广播事件 } }
需要进行这个操作的时候,只需要执行类似于下面的代码:
TaskExecutor.pendTask(new RetrieveStockDataTask())
好处很明显。通过引入TaskExecutor,所有线程管理放在同一个地方,耗时操作不需要自行维护线程的生命周期。你可以在TaskExecutor中灵活定义线程策略实现一些有趣的效果,如暂停执行,监控任务状况等,如果你愿意,为了更好的进行调试跟踪,你甚至可以将所有的任务以同步的方式执行。
耗时任务的定义与执行被分开,使得在任务内部能够按照正常的方式进行编码。测试也很容易写了。
不同的语言平台会提供不同的线程管理能力。.NET2.0 提供了BackgroundWorker, 提供了一序列对多线程调用的封装,事件如开始调用,调用,跨线程返回值,报告运算进度等等。它内部也实现了对线程的调度处理。在你要开始实现类似的 TaskExecutor 时,参考一下它的 API 设计会有参考价值。Java 6 提供的 Executor 也不错。
一个完善的TaskExecutor可以包含如下功能:
Task的定义:一个通用的任务定义。最简单的就是run(),复杂的可以加上生命周期的管理:start()、end()、success()、fail()…取决于要控制到多么细致的粒度。pendTask,将任务放入运算线程中reportStatus,报告运算状态- 事件:任务完成
- 事件:任务失败
写这样的一个线程管理的不难。最简单的实现就是每当pendTask的时候新开线程,当运算结束的时候报告状态。或者使用像BackgroundWorker或者Executor这样的高级 API。对于像 ActionScript/JavaScript 这样的,只能用伪线程, 或者干脆将无法拆解的任务扔到服务器端完成。
5 缓存与本地存储
纯粹的 B/S 结构,浏览器不持有任何数据,包括基本不变的界面和实际展现的数据。RichClient 的一大进步是将界面部分本地持有,与服务器只作数据通讯,从而降低数据流量。像《魔兽世界》10 多 G 的超大型客户端,在普通的拨号网络都可以顺畅的游戏。
缓存与本地存储之间的差别在于,前者是在线模式下,将一段时间不变的数据缓存,最少的与服务器进行交互,更快的响应客户;后者是在离线模式下,应用仍然能 够完成某些功能。一般来说,凡是需要类似于“查看 XXX 历史”功能的,需要“点击列表查看详细信息”的,都会存在本地存储的必要,无论这个功能是否需要向 用户开放。
无论是缓存还是本地存储,最需要处理的问题如何处理本地数据与服务器数据之间的更新机制。当新数据来的时候,当旧数据更新的时候,当数据被删除的时候,等 等。一般来说,引入这个实践,最好也实现基于数据变化的“事件管理”。如果能够实现“客户机 - 服务器数据交互模式”那就更完美了。
我们犯过这样一个错误。系统启动的时候,将当前用户的联系人列表读取出来,放到内存中。当用户双击这个联系人的时候,弹出这个联系人的详细信息窗口。由于 没有本地存储,由于采用了 Navigator 方式的导航,于是很自然的采用了Navigator.goTo('ContactDetailWindow', theContactInfo)。由于列表页面一般是不变的,因此显示出来的永远是那份旧的数据。后来有了编辑联系人信息的功能,为了总是显示更新的数 据,我们将调用更改为Navigator.goTo('ContactDetailWindow', 'contactId'),然后在ContactDetailWindow中按照contactId把联系人信息重新读取一次。远在南非的用户抱怨慢。还 好我没养狗,没有狗离开我。后来我们慢慢的实现了本地存储,所有的数据读取都从这个地方获得。当数据需要更新的时候,直接更新这个本地存储。
本地存储会在根本上影响 RichClient 程序的架构。除非本地不保存任何信息,否则本地存储一定需要优先考虑。某些编程平台需要你在本地存储界面和数 据,如 Google Gears 的本地存储,置于 Adobe Air 的 AJAX 应用等,某些编程平台只需要存储数据,因为界面完全是本地绘制的,如 Java/JavaFX/WinForm/WPF 等。缓存界面与缓存 数据在实现上差别很大。
本地存储的存储机制最好是采用某一种基于文件的关系数据库,如 SQLite、H2(HypersonicSQL)、Firebird 等。一旦确定要采用本地存储,就从成熟的数据库中选择一个,而不要尝试着自己写基于文件的某种缓存机制。你会发现到最后你实现了一个山寨版的数据库。
在没有考虑本地存储之前,与远端的数据访问是直接连接的:

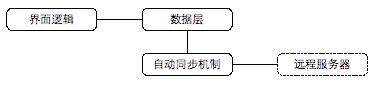
我们上面的例子说明,一旦考虑使用本地存储,就不能直接访问远程服务器,那么就需要一个中间的数据层:

数据层的主要职责是维护本地存储与远程服务器之间的数据同步,并提供与应用相关的数据缓存、更新机制。数据更新机制有两种,一种是 Proxy(代理)模式,一种是自动同步模式。
代理模式比较容易理解。每当需要访问数据的时候,将请求发送到这个代理。这个代理会检查本地是否可用,如果可用,如缓存处于有效期,那么直接从本地读取数 据,否则它会真正去访问远端服务器,获取数据,更新缓存并返回数据。这种手工处理同步的方式简单并且容易控制。当应用处于离线模式的时候仍然可以工作的很 好。

自动同步模式下,客户端变成都针对本地数据层。有一个健壮的自动同步机制与服务器的保持长连接,保证数据一直都是更新的。这种方式在应用需要完全本地可运行的时候工作的非常好。如果设计得好,自动同步方式健壮的话,这种方式会给编程带来极大的便利。
说到同步,很多人会考虑数据库自带的自动同步机制。我完全不推荐数据库自带的机制。他们的设计初衷本身是为了数据库备份,以及可扩展性 (Scalability)的考虑。在应用层面,数据库的同步机制往往不知道具体应用需要进行哪些数据的同步,同步周期等等。更致命的是,这种机制或多或 少会要求客户端与服务器端具备类似的数据库表结构,迁就这样的设计会给客户端的缓存表设计带来很大的局限。另外,它对客户机 - 服务器连接也存在一定的局限 性,例如需要开放特定端口,特定服务等等。对于纯粹的 Internet 应用,这种方式更是完全不可行的,你根本不知道远程数据库的结构,例如 Flickr, Google Docs.
当本地存储 + 自动同步机制与“事件管理”都实现的时候,应用会是一种全新的架构:基于数据驱动的事件结构。对于所有本地数据的增删改都定义为事件,将关心 这些数据的视图都注册为响应的观察者,彻底将数据的变化于展现隔离。界面永远只是被动的响应数据的变化,在我看来,这是最极致的方式。
结尾
限于篇幅,这篇文章并没有很深入的讨论每一种原则 / 实践。同时还有一些在 RichClient 中需要考虑的东西我们并没有讨论:
- 纯 Internat 应用离线模式的实现。像 AdobeAir/Google Gears 都有离线模式和本地存储的支持,他们的特点是缓存的不仅仅是数据,还包括界面。虽然常规的企业应用不太可能包含这些特性,但也具备借鉴意义。
- 状态的控制。例如管理员能够看到编辑按钮而普通用户无法看见,例如不同操作系统下的快捷键不同。简单情况下,通过 if-else 或者对应编程平台下提供的绑定能够完成,然而涉及到更复杂的情况时,特别是网络游戏中大量互斥状态时,一个设计良好的分层状态机模型能够解决这些问题。如何定义、分析这些状态之间的互斥、并行关系,也是处理超复杂
- 测试性。如何对 RichClient 进行测试?特别是像 WPF、JavaFX、Adobe Air 等用 Runtime+ 编程实现的框架。它们控制了视图的创建过程,并且倾向于绑定来进行界面更新。采用传统的 MVP/MVC 方式会带来巨大的不必要的工作量(我们这么做过!),而且测试带来的价值并没有想象那么高。
- 客户机 - 服务器数据交互模式。如何进行客户机服务器之间的数据交互?最简单的方式是类似于 Http Request/Response。这种方式对于单用户程序工作得很好,但当用户之间需要进行交互的时候,会面临巨大挑战。例如,股票代理人关注亚洲银行板块,刚好有一篇新的关于这方面的评论出现,股票代理人需要在最多 5 分钟内知道这个消息。如果是 Http Request/Response, 你不得不做每隔 5 分钟刷一次的蠢事,虽然大多数时候都不会给你数据。项目一旦开始,就应当仔细考虑是否存在这样的需求来选择如何进行交互。这部分与本地存储也有密切的关系。
- 部署方式。RichClient 与 B/S 直接最大的差异就是,它需要本地安装。如何进行版本检测以及自动升级?如何进行分发?在大规模访问的时候如何进行服务器端分布式部署?这些问题有些被新技术解决了,例如 Adobe Air 以及 Google Gears,但仍然存在考虑的空间。如果是一个安全要求较高的应用,还需要考虑两端之间的安全加密以及客户端正确性验证。新的 UI 框架层出不穷。开始一个新的 RichClient 项目的时候,作为架构师 /Tech Lead 首先应当关注的不是华丽的界面和效果,应当观察如何将上述原则和时间华丽的界面框架结合起来。就像我们开始一个 web 项目就会考虑 domain 层、持久层、服务层、web 层的技术选型一样,这些原则和实践也是项目一开始就考虑的问题。
感谢
感谢我的同事周小强、付莹在我写作过程中提供的无私的建议和帮助。小强推荐了介绍 Google Gears 架构的链接,让我能够写作“本地存储”部分有了更深的体会。
这篇文章是我近两年来在 RichClient 工作、网络游戏、WebGame 众多思考的一个集合。我尝试过 JavaFX/WPF/AdobAir 以及相关的文章,然而大多数的例子都是从华丽的界面入手,没有实践相关的内容。有意思的反而是《大型多人在线游戏开发》这本书,给了我在企业 RichClient 开发很多启发。我们曾经犯了很多错误,也获得了许多经验,以后我们应当能做得更好。
参考
- .NET 的 BackgroundWorker 定义: http://msdn.microsoft.com/en-us/library/system.componentmodel.backgroundworker.aspx
- ActionScript 的伪线程: http://blogs.adobe.com/aharui/2008/01/threads_in_actionscript_3.html
- Google Gears 架构: http://code.google.com/apis/gears/architecture.html
相关阅读:
[ ThoughtWorks 实践集锦(1)] 我和敏捷团队的五个约定。
[ ThoughtWorks 实践集锦(2)] 如何在敏捷开发中做好数据迁移。
[ ThoughtWorks 实践集锦(3)] RichClient/RIA 原则与实践(上)。
作者介绍:陈金洲,Buffalo Ajax Framework 作者,ThoughtWorks 咨询师,现居北京。目前的工作主要集中在 RichClient 开发,同时一直对 Web 可用性进行观察,并对其实现保持兴趣。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论