
不止一次,我们都萌发过想对运行中程序的底层状况一探究竟的念头。产生这种需求的原因可能是运行缓慢的服务、Java 虚拟机(JVM)崩溃、挂起、死锁、频繁的 JVM 暂停、突然或持续的高 CPU 使用率、甚至于可怕的内存溢出 (OOME)。好消息是现在已有许多工具能帮你得到 Java 虚拟机运行过程中的不同参数,这些信息有助于你了解其内部状况,从而诊断上述的各种情况。
在这篇文章中,我将介绍一些优秀的开源工具。其中一些是 JVM 自带的,另一些则是第三方工具。我将从最简单的工具开始介绍,逐渐过渡到一些比较复杂的工具。本文的目的是帮助你找到合适的调试诊断工具,这样当程序出现执行异常、缓慢或根本不能执行时,手头随时有可用的工具。
好了,让我们出发。
如果程序出现不正常的高内存负载、频繁无响应或内存溢出,通常最好的分析切入点是查看内存对象。幸好 JVM 内置了工具“jmap”,让它天生就能完成这种任务。
Jmap(借助 JPM 的一点帮助)
Oracle 将jmap描述为一种“输出进程、核心文件、远程调试服务器的共享对象内存映射和堆内存细节”的程序。本文将使用 jmap 打印一张内存统计图。
为了运行 jmap,你需要知道被调试程序的 PID(进程标识符)。得到 PID 的简单办法是使用 JVM 提供的 jps,它能列出机器上每一个 JVM 进程及其 PID。jps 输出结果如下图:
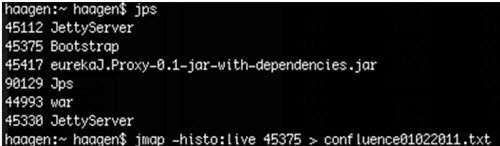
图 1:jps 命令的终端输出
为了打印内存统计图,我们需要打开 jmap 控制台程序,并输入程序的 PID 和“-histo:live”选项。如果不添加这个选项,jmap 将完整导出该程序的堆内存, 这不是我们想要的结果。所以,如果想得到上图中“eureka.Proxy”程序的内存统计图,我们应该用如下命令来运行 jmap:
jmap –histo:live 45417
上述命令输出如下:
(点击图片可以放大)

图2:命令_jmap -histo:live_ 的输出结果显示了堆中现有对象的个数
结果中每行显示了当前堆中每种类类型的信息,包含被分配的实例个数及其消耗的字节数。
本例中,我请同事有意给程序增加了一处明显的内存泄露。请特别注意位于第8 行的类, CelleData。将它与下图显示的 4 分钟后截屏进行比较:
(点击图片可以放大)

图3:_jmap_ 的输出表明_CelleData_ 类的对象数目增加了
请注意_CelleData_ 类现在已经变为系统中第二多的类,短短4 分钟内已经增加了631,701 个额外实例。等待约一小时后,我们观察到如下结果:
(点击图片可以放大)

图4:程序执行1 小时后_jmap_ 的输出结果,显示超过2 千5 百万个_CelleData_ 类实例
现在有超过2 千5 百万个_CelleData_ 类实例,占用了超过1GB 内存!我们可以确认这是一个内存泄露。
这类数据信息的好处是,不仅非常有用而且对于很大的JVM 堆也能快速反馈结果。我曾经试过检测一个运行频繁并且占用17GB 堆内存的程序,使用jmap 能够在1 分钟内生成程序的性能统计图。
需要注意的是,jmap 不是运行分析工具,在生成统计图时JVM 可能会暂停,因此当生成统计图时需要确认这种暂停对程序是可接受的。以我的经验,通常在调试一个严重bug 时需要生成这种统计图,这种情况下,这些1 分钟的暂停对程序来说是可接受的。这里,我们引出了下一个话题 - 半自动的运行分析工具_VisualVM_。
VisualVM
另一个包含于 JVM 中的工具是 VisualVM,它的开发者将它描述为“一种集成了多个 JDK 命令行工具的可视化工具,它能为您提供轻量级的运行分析能力”。这样看来,VisualVM 是另一种你最有可能用到的事后分析工具,一般是错误已出现或性能问题已经用传统方法(客户抱怨大多属于此类)发现。
继续之前的示例程序和它严重的内存泄露问题,在程序执行 30 分钟后,VisualVM 帮我们绘制了如下图表:
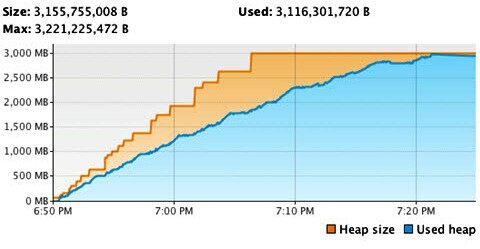
图 5:程序初始运行的 VisualVM 内存图
从这个图表,我们可以清晰地看到截止到 7:00pm,运行仅仅 10 分钟后,程序已经消耗掉超过 1GB 的堆空间。又过了 23 分钟,JVM 已经到了它启动参数–Xmx3g 最大值,导致程序响应缓慢,系统响应缓慢(持续的垃圾回收)和数量惊人的内存溢出错误。
借助 jmap,我们定位了这种内存消耗攀升的原因。修复后,我们让程序重新运行于 VisualVM 的严格监测之下,观察到下面的情况:
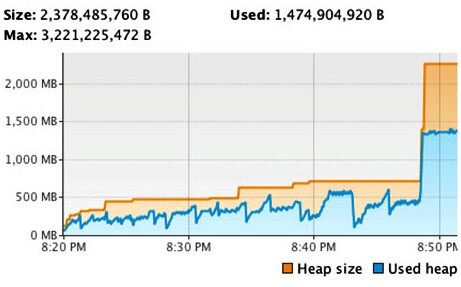
图 6:修复内存泄露问题后的 _VisualVM_ 内存图
如你所见,程序的内存曲线(启动参数仍然为–Xmx3g)有了明显改善。
除了内存图像工具,VisualVM 还提供了一个采样器和一个轻量级的剖析器(Profiler)。
VisualVM 采样器能周期采样程序 CPU 和内存的使用情况。得到的统计数据类似 jmap 的反馈,此外,你还可以通过采样得到方法调用对 CPU 的占用情况。它让你能快速了解周期采样过程中的方法执行次数:
(点击图片可以放大)

图7:_VisualVM_ 方法执行时间表
VisualVM 剖析器无需对程序周期采样就可以提供类似采样器的反馈信息,它还可以收集程序在整个正常执行过程中的统计数据(通过操纵程序源代码的字节码)。从剖析器得到的这种统计数据比从采样器而来的更精确和实时。
(点击图片可以放大)

图8: VisualVM 剖析器的输出
但是,你必须考虑的另一方面是该剖析器属于一种“暴力”分析工具。它的检测方法本质上是重新定义程序执行中的大多数类和方法,结果必然会明显减缓程序执行速度。例如,上述程序运行部分的常规分析,大约要 35 秒。开启 VisualVM 的内存剖析器后,导致程序完成相同分析要 31 分钟。
我们需要清楚的是 VisualVM 并非功能齐全的剖析器。它无法在你的产品 JVM 上持续运行,不会保存分析数据,无法指定阈值,也不会在超过阈值时发出警报。要想更多的了解功能齐全的剖析器的目标。下面,让我们看看 BTrace,这个功能齐全的开源 java 代理程序。
BTrace
想象一下,如果能收集 JVM 当前的任何信息,那么你感兴趣的信息有哪些?我猜想问题列表会将因人而异,因情形而异。就个人来说,我通常感兴趣的是以下的问题:
- 程序对堆、非堆、永久保存区(Permanent Generation),以及 JVM 包含的不同内存池(新生对象区、长期对象区、存活空间等)的内存使用情况
- 当前程序的线程数量,以及哪种类型线程正在被使用(单独计数)
- JVM 的 CUP 负载
- 系统平均负载 / 系统 CPU 使用总和
- 对程序中的某些类和方法,我需要了解它们被调用次数,各自平均执行时间和整体平均时间
- 对 SQL 调用的调用计数及执行次数
- 对硬盘和网络操作的调用计数及执行次数
利用 BTrace 可以采集到所有以上信息,你可以使用 BTrace 脚本定义需要采集的数据。方便的是,BTrace 脚本就是普通 Java 类,包含一些特殊注解来定义 BTrace 在什么地方及如何跟踪你的程序。BTrace 脚本会被 BTrace 编译器 -btracec 编译成标准的.class 文件。
BTrace 脚本包含许多部分,正如下图所示。如果需要了解下图脚本的详细内容,请点击该链接或访问 BTrace 项目网站。
由于 BTrace 仅仅是一个代理,记录结果后,它的任务就算完成了。除了文本输出,BTrace 并不具备动态展现被收集信息的功能。缺省情况下,BTrace 脚本输出结果将在 btrace.class 文件所在位置生成一个名为 _BTrace 脚本名.class.btrace_ 的 text 文件。
我们可以通过给 BTrace 设置一个额外参数,让它按某时间间隔循环记录日志。切记,它最多能在 100 个日志文件间循环,当达到 *.class.btrace.99,它将覆盖 *.class.btrace.00 文件。若让循环间隔在一个合理数字(如,每 7.5 秒)内,你就有充足时间来处理这些输出。只要在 java 代理的输入参数中加上 _fileRollMilliseconds=7500,_ 就可以实现日志循环。
BTrace 一大缺点是它比较原始,难以定义它的输出格式。你也许非常希望有一种更好的方式来处理 BTrace 的输出和数据,比如可以用一种一致的图形用户界面来展示。你可能还需要比较不同时间点的数据和超出阈值能发送警告。一个新的开源工具EurekaJ,就此应运而生。
(点击图片可以放大)

图9:激活方法分析时必需的_BTrace_ 脚本
EurekaJ
我最初开发EurekaJ是在 2008 年。那时,我正在寻找一种具有我需要功能的开源剖析器,但没有找到。于是,我开始开发自己的工具。开发过程中,我涉猎了大量不同的技术并参考了许多架构模型,直到 EurekaJ 第一个版本发布。你可以从项目网站上了解更多的EurekaJ 历史,查看源代码或下载并试着安装自己的版本。
EurekaJ 提供了两个主要应用:
- 一个基于 java 的管理器程序,可以接收传入的统计数据并一致地以可视化视图展现出来
- 一个解析 BTrace 输出的代理程序,将其转化为 JSON 格式并输入到 EurekaJ 管理程序的 REST 接口
EurekaJ 接受两种类型的输入数据格式。EurekaJ 代理期望 BTrace 脚本的输出被格式化为逗号分隔的文件(这点在 BTrace 中可很容易做到),而 EurekaJ 管理程序期望它的输入符合它的 JSON REST 接口格式。这意味着你能通过代理程序或直接经由 REST 接口来传递度量数据。
借助 EurekaJ 管理程序,我们可以在一张图上分组显示多个统计数据、可以定义阈值和给接收者发出警报。我们还可以方便的查看收集到的实时数据或历史数据。
所有收集到的数据排序成一种逻辑树结构,其结构由 BTrace 脚本作者指定。我建议 BTrace 脚本的作者对相关统计数据分组,这样,当它们显示在 EurekaJ 中时会更容易理解和观察。例如,我个人喜欢对统计数据进行如下的逻辑分组:
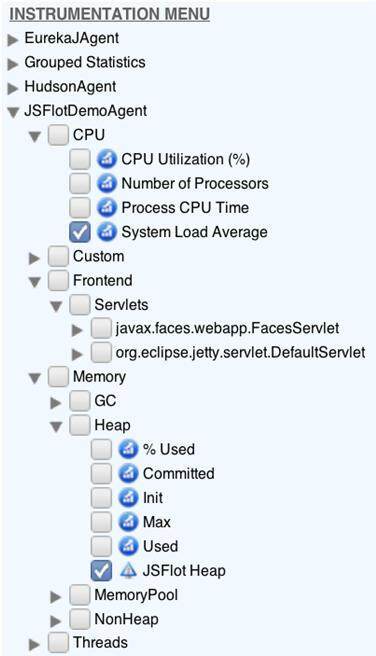
图 10:_EurekaJ_ 演示程序的统计分组示例
图例
一种需要采集的重要信息是程序运行时的平均系统负载。要是你正面对一个运行缓慢的程序,那么缺陷可能并不在程序自身,而是隐藏到应用驻留的主机某处。我曾经在调试运行缓慢的应用时偶尔发现,真正的根源是病毒扫描程序。如果不进行测量分析,这种事情会很难被发现。考虑到这一点,我们需要能够在一张图中显示系统平均负载和进程加载后产生的负载。下图显示了一个运行 EurekaJ 演示程序的 Amazon EC2 虚拟服务器的 2 小时平均负载(该应用登录的用户名和密码都是‘user’)。
(点击图片可以放大)

图11:显示平均系统负载的_EurekaJ_ 图表
图中,黄色和红色的线条表示警戒阈值。一旦图形超过黄线的次数超过预设的最小警戒次数时,则测量结果到达“警告”状态。类似,若突破红线,测量结果就到达“危险”或“错误”状态。每当发生状态转换,EurekaJ 都会发送一封邮件给之前注册的收件人。
在上面的情形中,好像有周期性的事件每20 分钟发生一次,从平均负载图上显示的波峰可以看到这一点。首先你要确定的是这个波峰确实由你的程序产生,而非其他原因。我们也可以通过测量进程的CPU 负载来确认这点。在EurekaJ 树菜单中,选择两个测量点后,两个图表结果会一起快速成像显示出来,其中一个位于另一个下面。
(点击图片可以放大)

图12:同时显示多个图表
在上面的例子中,我们清楚地看到进程CUP 占用和系统负载存在必然的联系。
许多应用需要在程序无响应或不可用时及时发出警告。下图是一个Confluence(Atlassian 的企业级Wiki 软件)的例子。这个例子中,程序内存占用快速上升,直到产生程序内存溢出。这时,Confluence 无法处理接收到的请求,同时日志文件记录了各种奇怪的错误。
你可能希望当程序运行导致内存溢出时,程序能立刻抛出一个OOME(内存溢出错误),然而,事实上JVM 不会抛出OOME 直到它发觉垃圾回收过于缓慢。结果,程序没有完全崩溃,又过了2 小时,Java 仍然没有抛出OutOfMemoryError,甚至两小时后程序依然在“运行”(意味着JVM 进程仍然在运行)。显然,这时任何进程监测工具都不能发现程序已经“停止”。
(点击图片可以放大)

图13:_EurekaJ_ 堆图显示内存溢出错误的一种可能情形
注意最后几个小时的执行情况,图表揭示了下面的度量指标。
(点击图片可以放大)

图14:前面图表放大后的效果
EurekaJ 使我们可以设置程序的堆内存警告,个人建议最好如此。若程序持续占用堆内存超过 95%-98%(取决于堆的大小),几乎可以肯定,程序存在内存问题,要么用–Xmx 参数为程序分配更多的堆,要么优化程序使其使用更少内存。同时,EurekaJ 未来版本计划增加统计数据不足的警报。
最后的图表示例展示了一个包含 4 个不同程序内存使用的图表组。这种类型的图表组可方便用来比较一个程序不同部分的、或甚至不同程序之间、服务器之间的数据。下图的这 4 个程序有不同的内存需求和内存占用模式。
如下图示,不同程序有不同的内存曲线。这些曲线非常依赖一些实际情况,比如使用的架构、缓存数量、用户数、程序负载等。我希望通过下图说明你需要掌握程序在正常和高负载下执行情况的重要性,因为这将直接关系到如何定义报警阈值。
(点击图片可以放大)

图 15:EurekaJ 图组会将图像彼此叠加在一起
注意性能干扰 – 让非热点区不受影响!
你使用的每一种测量方法似乎都会引起系统性能干扰。一些数据的测量可以被认为“无干扰”(或“忽略不计”),然而另外一些数据的测量可称得上代价昂贵。非常重要的一点是,要知道你需要 BTrace 测量什么。因此,你要将这种分析工具对程序的性能干扰减少到最小。关于这点,请参考下面的 3 条原则:
- 基于“采样”的度量通常可被认为“无影响”。采样 CPU 负载、进程 CPU 负载、内存使用和每 5-10 秒的线程计数,其带来的额外一两个毫秒的影响可被忽略。在我看来,你应该经常收集这类统计数据,它们对你来说不会有什么损耗。
- 对长时间运行的任务的测量也可被认为“无影响”。通常,它仅会对每个被测量方法带来 1700-2500 纳秒的影响。如果你正测量这些对象的执行时间:SQL 查询、网络流量、硬盘读写或一个预期范围在 40 毫秒(磁盘存取)到 1 秒(Servlet 处理)之间的 Servlet 处理过程,那么对这些对象每个增加额外的 2500 纳秒左右的时间也是可接受的。
- 绝对不要对循环内执行的方法进行测量
寻找程序热点区的一个通用规则是不要影响非热点区域。例如,考虑下面的类:
(点击图片可以放大)

图 16:需要测量的简单的数据访问接口类
第 5 行的 SQL 执行时间可能使 _readStatFromDatabase_ 方法可能成为一个热点。当查询返回相当多的数据行时,它无疑会成为一个热点,这对 13 行(程序和数据库服务器之间的网络流量)和 14-16 行(结果集中每行所需处理)会造成负面影响。如果从数据库返回结果时间过长,该方法也会成为一个热点(在 13 行)。
方法 _buildNewStat_ 就其本身来说似乎绝不会成为一个热点。即使被多次执行,每次调用都会在几纳秒内完成。另一方面,若给每次调用增加了 2500 纳秒的测量采集干扰,则无论 SQL 何时被执行,都势必会让该方法看起来像个热点。因此,我们要避免测量它。
(点击图片可以放大)

图 17:显示上面类哪些部分可以被测量,哪些需要避免
建立完整的运行分析
使用 EurekaJ 建立一个完整的运行分析,需要以下几个主要部分:
- 准备需要监测 / 操纵的程序
- BTrace - java 代理
- 告知 BTrace 如何测量的 BTrace 脚本
- 存储 BTrace 输出的文件系统
- 将 BTrace 输出传输到 EurekaJ 管理器的 EurekaJ 代理
- 安装好的 EurekaJ 管理器(本地安装或可通过互联网访问的远程安装)

图18:使用本文所描述工具对程序进行运行分析的概览图
关于这些产品的完整安装手册,请访问 EurekaJ 项目网站。
总结
这篇文章给我们介绍了一些用于程序运行分析的开源工具,它们不仅能帮我们完成对运行中 JVM 的深度分析,而且可以帮助我们对开发、测试和程序部署进行多方位的持续监测。
希望你已经开始了解不断收集度量信息的好处和超过阈值后及时报警能力的重要性。
非常感谢!
参考
[1] jmap 文档
[2] BTrace 脚本概念
[3] BTrace 项目网站
[4] EurekaJ 文档
[5] EurekaJ 项目网站
关于作者
 Joachim Haagen Skeie,挪威奥斯陆的 Kantega AS 公司的 Java 和 Web 技术的资深顾问,关注程序性能分析和开源软件。你可以通过他的Twitter 账号来联系。
Joachim Haagen Skeie,挪威奥斯陆的 Kantega AS 公司的 Java 和 Web 技术的资深顾问,关注程序性能分析和开源软件。你可以通过他的Twitter 账号来联系。
查看英文原文: Effective Java Profiling With Open Source Tools
感谢胡键对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论