

者在印尼 Manado 拍摄,Goniobranchus tritos, 一种体长 8 厘米的海蛞蝓。
本文基于 Andrew Ng 在斯坦福 MSx 论坛的演讲(Artificial Intelligence is the New Electricity),经演讲人授权,由InfoQ 中文站总结并分享。
2017 年 2 月,百度首席科学家、Coursera 的联合创始人 Andrew Ng 在斯坦福 MSx 未来论坛上的一个演讲,吸引了全球的眼球。 他认为,人工智能(AI) 对未来许多行业带来的变革,如同100 多年前,美国“触电”一样——电对制造、运输、农业(尤其是冷藏)、医疗等等带来了划时代的变革。
AI 驱动着百度的搜索和广告,调度百度外卖的快递员,选择路线,和预估运送时间。AI 正在彻底改变金融工程,对物流的转变进行了一半,医疗和自动驾驶刚开始,而前景巨大。和“电”带来的变革一样,很难想象哪个行业不会被 AI 改变。
监督学习
驱动百亿的市场容量的,基本上属于同一种 AI: 监督学习(Supervised learning),即用 AI 来确定 A–>B 的映射——输入 A 和响应 B 的映射。
- 用 Email 作为输入 A,判断是否是垃圾邮件是响应 B。
- 用图像作为输入,识别这是一千种物体中的哪种?
- 从声音 A 到文字 B,从英文到法文,或从文字到声音。
软件可以学习这些输入 A 到响应 B 的映射——有很多好的工具来让机器学习。比如 50,000 小时的音频和对应的文本,就能让机器学到如何从音频内容转化为文本内容。通过大量的电邮数据和区分垃圾的标签,也可以很快地训练出一个垃圾邮件过滤器。
现在的 AI 还很初级——A 到 B 的映射而已,不过已经推动着很大的市场。百度有很好的算法来预测某用户是否会点击某广告。向受众呈现更相关的广告,能为互联网营销和广告公司带来极大的赚钱机会。这可能是 AI 最赚钱的应用。
在哪些产品里能用到 AI?
产品经理常常希望了解 AI 能实现的,和不能实现的。一个简单的思路是:一般人能在一秒内想出来的事情,现在或很快就可以用 AI 自动实现。
AI 进展最快的领域正是人能做得到的领域。比如自动驾驶。人类能驾驶,所以 AI 也能驾驶。在医学影像阅片和分析上,人类放射科医生能够阅片,所以 AI 也很可能在未来几年内做到。
而人类难以做到的事情,比如预测股市变化,AI 可能也难。
原因 1:人类能做的,至少是可行的;
原因 2:可以利用人类的数据作为培训样本,比如前面提到的输入 A 和响应 B;
原因 3:人类能提供指导。如果 AI 对某个放射影像的结论有误,设计者可以向医生请教,医生所做的正确结论的原因是什么? 进而对 AI 进行改善。
在 Andrew Ng 所接触到的 80-90% 的 AI 项目中,都遵循这一规律:在人类能做到的领域,AI 的进展更快。很多项目的发展一旦超越人类水准,发展也会变得缓慢。这也带来一个社会矛盾:如果 AI 和人的水平类似,实质上是跟人类竞争。
AI 的发展趋势
AI 已经出现了几十年了,而近五年发展明显加速,为什么?
当以前的机器学习算法性能上升到一定程度,即使再增加数据样本量(前文谈到的输入 A、响应 B 的 A-B 映射),性能改善也很有限。似乎超过一定样本量之后,再多的数据也对算法不起作用。
而过去几年,主要由于 GPU,我们终于实现了能利用这么巨大的数据集的机器学习软件。将数据输入一个小的神经网络,当超过一定性能后,上升变得平缓。而不断地把数据输入一个很大的神经网络时,即使性能上升没有那么快,也会保持上升趋势,随着数据量的增大,不断提高。
因此,要想获得很好的 AI 性能,需要两样东西:
- 很大的 A-B 映射的数据集;
- 大的神经网络。现在常用的大型神经网络建立在 HPC 高性能计算集群上。
现在的大型 AI 团队包括机器学习和高性能计算两组人,才能获得足够计算能力。百度 AI 团队里的这两种人员都专注于各自领域,没有人能两者兼备。
什么是神经网络?有没可能取代人类大脑?
问题是,我们不清楚人脑如何工作,所以很难造出取代人类大脑的神经网络。
什么是神经网络?先看个最简单的神经网络:
如果想输入房屋面积,得到房屋总价,可以用面积 - 总价的一阶近似的线性模型来描述这个神经网络。
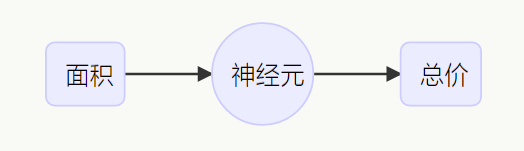
或者用更多因素建模,比如通过面积和卧室数,从第一个神经元得到可以支持的家庭人数。再通过所在地址的邮编和社区富裕程度,从第二个神经元得到附近学校的质量。
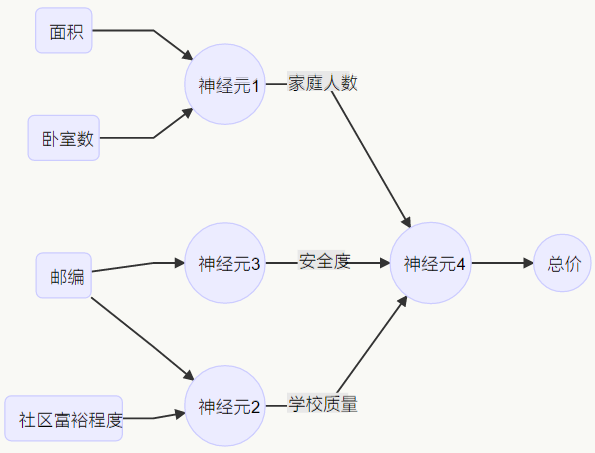
这就成为一个神经网络。面积、卧室数、邮编、社区富裕程度属于“输入”集合 A,总价属于“响应”集合 B。
好处在于,当训练这样一个神经网络时,用户无需关心中间因素,诸如家庭人数、安全度、学校质量等,也无需关心每个神经元如何将输入映射到中间结果。只需要给出输入集合 A 和响应集合 B,神经网络将自动形成中间的计算过程和参数。当 A 和 B 的集合足够大,神经网络可以自动算出很多东西。 神经网络看上去非常简单,让很多初学者觉得有点失望,但它确实能解决很多问题。关键在于数据量要够大——几万或几十万个样本本身能提供大量的信息,而软件本身只是一小部分。
如何保护 AI 业务?
AI 研究较前沿的团队都比较开放,常常发布研究成果。百度的 AI 研究论文也没有隐藏什么成果——在人脸识别等论文里,都分享了所有的细节。既然很难把算法本身隐藏起来,如何保护 AI 业务? 当前稀缺资源有两种,一种是数据,二是人才。获取巨量数据很难,要包括输入 A+ 响应 B。比如语音识别用了 5 万小时的音频来训练,今年准备用 10 万小时,相当于百度 10 年积累的音频。
以人脸识别所用的训练图像数量为例,
- 学术上最常用的基准测试 / 比赛:1 百万幅;
- 所用图像数最多的计算机视觉对象识别学术论文:1500 万幅;
- 百度用来训练世界上最先进的人脸识别系统:两亿幅!
如果只是 5-10 人的研发团队,很难获得这样规模的数据。百度这样的大企业的经常推出一些新产品不一定是为了营收,而是为了数据,然后通过后续的产品来获得收益。
另一个稀缺资源是人才。AI 的应用需要根据具体业务场景来定制。仅仅下载个开源包,无法解决问题。实际情况下,是否适合用某种垃圾邮件识别或语音识别技术?针对某种场景,机器学习怎么用? 所以各个公司都在为数据挖掘争夺 AI 人才,来定制 AI 技术,找到所需要的 A 和 B 各自代表什么,怎么找到这些数据和如何调整算法来适应业务场景。
AI 的良性循环
-
先做出某种产品。比如通过语音识别,以语音实现搜索;
-
然后吸引来很多用户,用户产生数据;
-
再通过机器学习,用数据改善产品。 这就形成了 AI 产品的良性循环。最好的产品能获得最多的用户,带来最多的数据,通过现代机器学习体系,能得到最好的 AI,最终让产品变得更好,周而复始。
百度发布新的产品,会特别考虑怎样推动这样的良性循环,会包括相当先进的产品发布策略,比如按地理区域、细分市场等,来更好地推动这个循环。
这种良性循环的理念很早就有了,只是最近变得更加明显。正如前文所述,当数据超过一定规模后,传统 AI 算法无法明显改善 AI 性能,因此数据多的优势不明显,大公司也很难保护自己的 AI 业务。现在数据越多,AI 性能越好,大公司也更容易保护自己的优势。
AI 炒作的非良性循环
许多人担心 AI 会不会取代或威胁人类。有一小部分研究 AI 的人专门从事对“邪恶 AI”的炒作,以获得投资人或政府机构的投资,来研究“反邪恶 AI”。道高一尺,魔高一丈,又进一步推动对“邪恶 AI”的炒作,从而形成非良性循环,非常不健康。
担心 AI 变得邪恶,类似于担心火星的未来人口过剩。现在看不出 AI 将会怎样走偏,因此也谈不上有针对地研究相应措施。 研究本身没有问题,不同的研究是好事,但是对邪恶 AI 的研究占用不恰当的资源,就不应该了。两个人,或者 10 个人来研究邪恶 AI 也许没问题,但是现在投资得太多。
AI 对就业的影响
AI 对就业带来的影响更让人担心。有些 AI 项目确实是瞄准了某些人类岗位,而从事这些工作的人并不清楚严重性。硅谷创造了大量财富,但也应该对其造成的问题承担责任,比如造成的失业问题。AI 取代人类岗位的现实问题,更应该引起重视,而不是被邪恶 AI 的炒作转移了注意力。
AI 产品管理
AI 是个让人兴奋的领域,同时也存在一些挑战。 如何将 AI 融入公司业务?
产品经理的职责是找到用户喜欢的,而工程师的角色是做出可行的产品。两者共同协作,才能做出理想的产品。
AI 是个新生事物,所以技术公司以前的流程和工作方法,不太适用。硅谷的产品经理和工程师的合作已有一套标准流程。比如开发 APP 时,产品经理先画出线框图,比如 logo, 按钮,各个板块等,工程师再写出代码来实现。 但是 AI 的 APP 无法通过画线框来描述。通过什么形式,把产品经理头脑里对 AI 产品的功能要求明白地分享给工程师呢?
比如开发语音识别系统,实现语音搜索,有很多改善方向。比如:
- 在嘈杂环境下如何改善, 比如车里或咖啡馆?
- 仅改善窄带语音信号;
- 对不同口音改善;
百度发现,产品经理通过 **数据** 和工程师沟通,是个较好的办法。 产品经理负责提供测试数据集给工程师,比如一万个音频和对应的文字,来说明所关心的问题,工程师也能更明白需要解决的问题。如果这些音频里有大量车辆噪音,工程师就知道车辆噪音是问题。 如果是混合了几种不同噪声,工程师也能想办法解决。最糟糕的情况是,产品经理提供的测试数据,并不能代表自己想解决的问题,那就出问题了。
同时,新产品设计的流程有很多, 比如想设计一个交流型 AI 机器人:
- 人:“我想叫个外卖”;
- AI:“你喜欢哪种类型餐馆?”;
- 人:“川菜”;
- AI:“这些可供选择,xxx,yyy,zzz,…”;
线框图只能显示对话过程,无法描述所需 AI 的复杂程度等。百度的产品经理和工程师会在一起,写五十种对话,
- 人:“请帮我定一个结婚纪念日的餐馆”;
- AI:“你需要订花吗?”;
这时候,工程师会问一些更具体的问题,比如每种场景是否都需要继续提配套产品的问题,比如谈到圣诞节时,是否要问对方要不要买圣诞装饰?一起思考,共同讨论需求和技术,很有效。
对 AI 的宣传里,有很多吸引眼球的技术,不过它们未必最有用。如何将吸引眼球的技术和产品、业务相结合?软件产业已经有标准流程,比如代码审查、敏捷开发等,如何组织 AI 的产品工作,有很长的路要走,现在正是考虑这些问题的时候。
短期内,AI 有哪些机会?
语音识别正在起飞
最近准确率已经提高到很有用的程度。4-5 个月之前,斯坦福大学计算机系教授 James Landay、百度、华盛顿大学一起展示了在手机上输入英文和普通话,用语音识别的速度比用手机输入快3 倍。去年百度的所有语音识别产品年度环比增长大约100%,现在正是语音识别技术腾飞之时。美国有几个公司做智能语音控制器(Smart Speakers),用语音控制家用设备也会很快推广。相关的操作系统和硬件都会很快发布。
计算机视觉也即将到来
中国的人脸识别发展速度很快。因为中国的手机比笔记本更普及,很多人有手机,而不一定有笔记本。 在中国可以仅仅凭手机申请助学贷款。涉及到钱,所以需要先验证身份和很多东西。这加速了人脸识别的发展。通过手机进行人脸识别,作为 用生物标识进行身份认证的一种方法,在中国发展很快。
在百度总部,不需要RFID 卡进行认证,而是直接刷脸进门,Andrew Ng 在 YouTube 上有一段视频。现在人们对人脸识别技术已经足够信任,并在安全要求较高的场景下使用。
百度在语音识别和计算机识别上的资金投入和数据投入巨大,任何小开发团体远远无法相提并论,也不太可能有其他出乎意料的技术突破。
医疗健康的 AI 应用
Andrew Ng 对 AI 对医疗健康领域带来的影响很看好。很多现在的放射科医生会被 AI 影响到。如果想在放射科一直工作四十年,不是个好的职业计划。
还有很多垂直领域将受到 AI 的影响,比如金融工程和教育。不过短期之内还不太会对教育产生实质性的影响。
永恒的春天
光从监督学习已经看得出 AI 将如何逐渐改变各个行业。其他的 AI 形式,比如无监督学习、强化学习、迁移学习等等,都还在研究阶段,现在的市场规模较小。
有很多行业会经历几个冬天,然后迎来永恒的春天。AI 经历过两个冬天,现在已经进入永恒的春天。就像硅的春天一样,半导体、晶体管、计算周期这些都将和人类一起发展很久。神经网络和深度学习会繁荣很长时间,一百年或许太远,但一些重要应用改变几个大行业的路线图已经很清晰。
AI 确实正在取代人类的一些岗位。当某些岗位被 AI 取代后,我们需要新的教育系统,来帮助失去工作的人获得新的技能。政府应该为这些愿意学习新技能的人,提供基本收入保障,重新成为劳动者的一员。我们需要新的系统和结构,来让帮助社会 **向新世界进化**。虽然会有新类型的工作,但工作岗位的消失也比以前更快。
一些问题
- 大公司在数据和人才上有巨大优势,那么创业公司的机会在哪里? 投资者可以关注哪种规模的创新? 在语音识别、人脸识别上,小公司非常难与大公司竞争,除非有意料之外的技术突破。同时,也有很多小垂直领域适合创业公司,比如医疗影像。有一些疾病的病例不多,如果有一千张影像,也许就涵盖了所有所需的数据了,一些垂直领域需要的数据量也不大。
另外,AI 的机遇非常多,大公司会放弃很多的小的垂直市场,因为精力有限,大的机会还研究不过来。
2. AI 在发明创造上,有哪些进展? 还很早期。AI 可以作曲,但这很主观。20 年前的技术做出来的曲子有人喜欢,有人不喜欢。有些项目用 AI 制作图片特效,用特效模仿某画家作品,这些都是小而有趣的领域。 现在还看不到有什么技术路线能发明复杂的系统。
3. 如果摩尔定律不再成立,对 AI 的扩展性有什么影响? 一些高性能计算公司的硬件路线图显示,摩尔定律在单芯片上不再那么有效,但神经网络、深度学习所需的计算类型在未来几年仍然能很好地扩展。SIMD(单指令多数据)让并行化处理负载非常容易。神经网络很容易并行化,加速计算的空间还很大。
AI 面对的诸多问题中,许多问题的瓶颈在于数据,也有很多的瓶颈在于计算速度——能便宜地处理数据的速度赶不上获得数据的速度。所以高性能计算的路线图应该包括这方面。
4. 算法是 AI 里的特殊作料。是否应通过知识产权保护,还是绕过这个问题去设计产品? 对机器学习的研究者,是否有和 AI 产品经理 - 工程师那样类似的流程或良性循环,来实现突破或改善研究流程? 知识产权的问题比较难讲。有些公司申请了大量专利,但是是否真能带来实质性的保护?所以我们往往从如何从战略上思考细节,比如让数据保护自己。
研究机构更偏好新鲜、抢眼球的东西,来发表论文。训练新研究者的办法通常是读很多论文。而大家常常忽视重复论文里的试验的重要性。不一定要把精力大量用于发明新东西,而花时间重复别人的发布结果也是很好的培训方法。和培训博士生一样:去学习和理解别人的论文,重复别人的试验,争取获得类似的结果,很快你就能产生自己的想法去推动最新的科技。
5. 对希望从事机器人相关工作的机械工程学生,有哪些和 AI、机器人相关的机会比较适合? 很多机械工程背景的人,在 AI 领域很成功。可以上一些计算机 /AI 课程,和 AI 领域的老师聊聊。一些垂直领域存在有趣的 AI 机器人的机会,比如精准农业。Blue River 用计算机视觉来区分不同植物,比如不同品种卷心菜,选择留下哪些,除掉哪些,来提高产量。
中国也生产和销售很多社交和伴侣机器人,美国还没起怎么起步。
6. 让 AI 和人配合起来的前景如何?很多 AI 应用是基于 AI 自己,如果采用 AI+ 人的混合方案?比如自动驾驶等? 没有统一的规则,应该跟实际情况有关。很多语音识别是为了让人类更高效,比如通过手机。对自动驾驶汽车,可能需要 10-15 秒来转换控制权,因为难让容易分神的人快速接手驾驶,很困难。这种情况下,由 AI 独立控制更安全。 所以从使用者角度来讲,人类和 AI 混合的自动化比较困难。
7. 对在线教育而言,主要问题是动机,人们不愿意花那么多时间来学完整个课程。这是不是最大的挑战? 其他还有什么挑战? AI 对在线教育有帮助。个性化的辅导已经谈论了很长时间,Coursera 用 AI 推荐个性化的课程,自动打分,在细节上确实有帮助。但在利用 AI 之前,教育的数字化还有很长的路要走。很多行业都有个规律:先有数据,再有 AI,比如医疗,美国电子病历(EHR)的进展很大。随着电子病历的兴起,影像胶片变成数码图片,这些数字化产生了很多数据供 AI 使用,并产生价值。教育需要先经历数字化,这一阶段还有很多工作要做。
8. 百度如何用 AI 来管理自己的云上数据中心? 比如 IT 运维管理的例子? 两年前,百度做了个项目,可以提前一天自动检测出硬件故障,特别是硬盘故障。这就可以事先拷贝、热插拔进行预防处理。还可以降低数据中心的用电量,负载均衡等,都是很多小细节的改善。
9. 能否举一些例子说明能通过仔细地建模和规划,用 AI 解决的复杂问题?对这些问题,人类可能需要进行长时间的思考。 亚马逊是个很好的例子。它知道我浏览过什么,读过什么,比我太太更了解。电脑对人们看过什么,点击过什么广告更了解,所以在广告方面做得非常好。 对于有些任务,计算机可以处理的信息量远远超过人类,并根据规律建模,进行预测,这方面 AI 比人做得更好。
将 AI 融入人类工作的很大一部分,是将一块块的 AI 部分串成一个大系统。比如为了造自动驾驶汽车,要用相机拍摄的图像,雷达等,组成车前方的一幅图,再由监督学习估算和其他车的距离,以及和行人的距离,这只是两个重要的 AI 部件,还需要其他的部件来估计 5 秒后车的位置,行人的方向。还有一个部件来分析,根据行人车辆等不同对象的运动情况,我应该怎么走? 然后还需要算方向盘的旋转程度,以此类推。
所以复杂的 AI 系统有很多小 AI 部件,工程人员要知道如何将这种超级学习能力融合到更大的系统里,来创造价值。
10. 产品经理和社会学家、律师等如何协调?比如自动驾驶汽车在撞人前,开发者和 AI 应从驾驶者,还是行人的角度考虑问题?这只是个法律问题,但也有很多类似情况。产品管理者和不同的功能部门的合作时,应该扮演什么角色? 这个问题的一个相似版本是“有轨电车”问题,会产生伦理矛盾。一个电车走到岔道口,继续往前会撞死 5 个人,你可以用扳手将电车扳到另一条轨道,撞死该轨道上的一个人,而你成为凶手,你扳吗?
除了在哲学课里,很少有谁在现实生活里遇到过这个问题,所以,它并不重要。自动驾驶的开发者没去讨论它。实际上,如果谁真正遇到了,可能之前已经犯了其他错误了。自动驾驶处理的问题更实际,和你自己开车一样。比如,对面有个白色的大车,是否能及时刹车?
感谢冬雨对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论