

“也许这有点不合常理,但这是我很长时间以来看到的最好的谷歌 I/O。”有开发者对昨晚如期而至的谷歌 I/O 2023 大会作出了如此评价,“我知道今年人工智能将受到极大关注,但我仍对许多新功能以及这些集成发生的速度感到惊喜。”
在这次 I/O 大会上,谷歌试图向大众呈现出自己与 OpenAI 抗衡的实力:发布了与 GPT-4 对打的 PaLM 2、Bard 进化后向所有人开放、移动端也可以用 AI 新功能等等。正如谷歌首席执行官Sundar Pichai 说的,谷歌正在重构自己的所有核心产品,包括搜索。
与 GPT-4 对打的 PaLM 2
毫无疑问,被寄予厚望的 PaLM 2 成为这次大会的亮点之一。PaLM 2 是⼀种基于 Transformer 的模型,使⽤类似于 UL2 的混合⽬标进⾏训练。
谷歌于 2022 年 4 月首次宣布推出 PaLM 模型。PaLM 的应用在这一年取得了很大的进展,今年 3 月,该公司推出了一款适用于 PaLM 的 API 以及一系列人工智能企业工具,帮助企业“通过简单的自然语言提示生成文本、图像、代码、视频、音频等”。这次大会上,Pichai 宣布推出 PaLM 2 预览版本,改进了数学、代码、推理、多语言翻译和自然语言生成能力。
多语言能力
谷歌声称,PaLM 2 是一种最先进的语言模型,具有改进的多语言、推理和编码功能。PaLM 2 在所有数据集上都优于 PaLM,并取得了与 GPT-4 竞争的结果。
之前的大型预训练语言模型通常使用以英语文本为主的数据集,谷歌设计了一个更多语言和多样化的预训练混合模型,扩展到数百种语言和领域(例如编程语言、数学和并行多语言文档)。更大的模型可以处理更多不同的非英语数据集,而不会导致英语语言理解性能的下降,并应用重复数据删除来减少记忆。
PaLM 2 在多语言文本方面接受了更多的训练,涵盖 100 多种语言,显着提高了其在多种语言中理解、生成和翻译细微差别文本(包括成语、诗歌和谜语)的能力。根据基准测试,对于具有思维链 prompt 或自洽性的 MATH、GSM8K 和 MGSM 基准评估,PaLM 2 的部分结果超越了 GPT-4。

PaLM 2 还通过了“精通”级别的高级语言能力考试。其中,PaLM 2 的日语水平达到了 A 级,而 PaLM 是 F 级。PaLM 2 的法语水平达到了 C1 级。
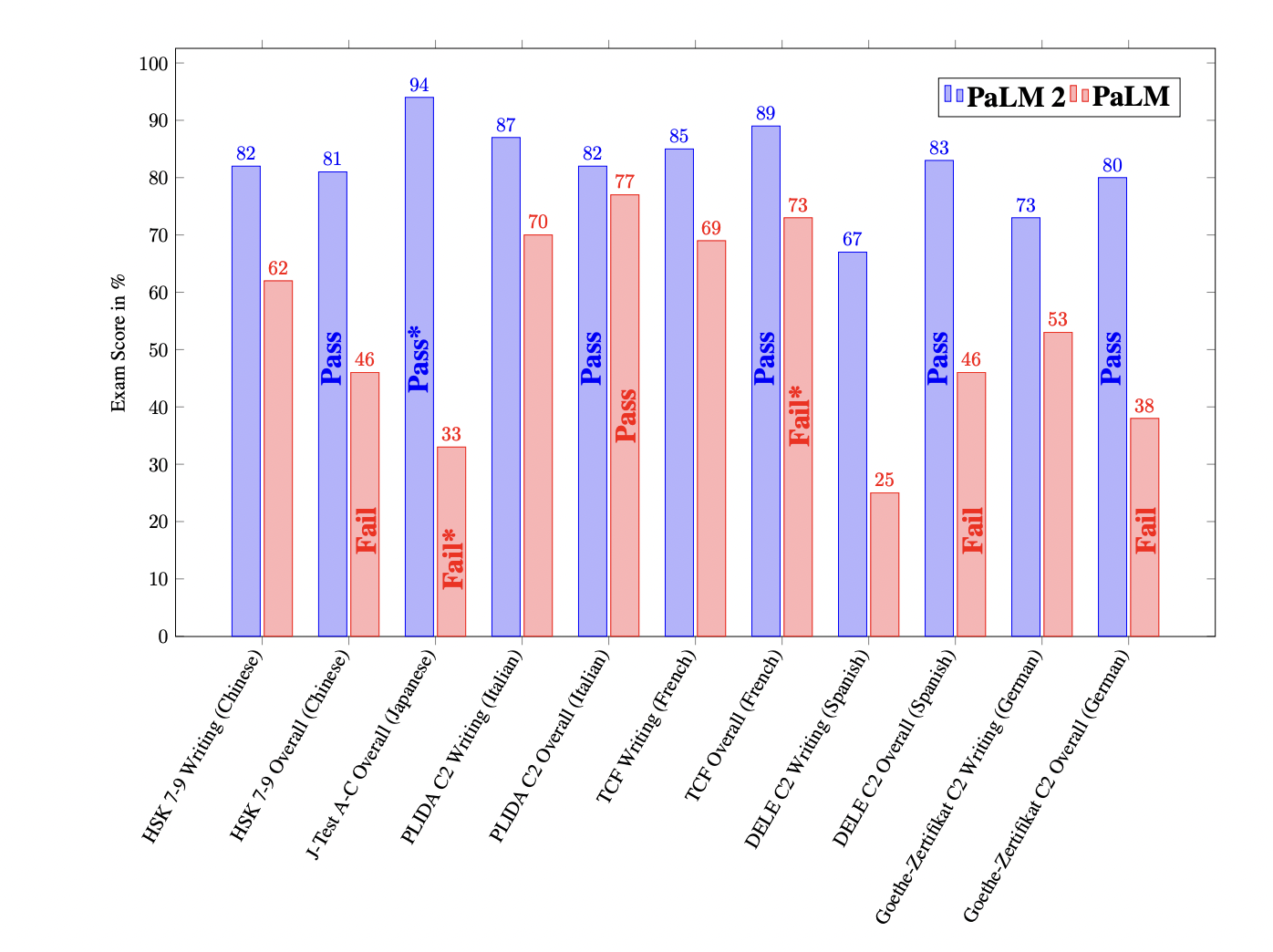
PaLM 2 和 PaLM 在最新的专业语⾔能⼒考试中的表现
不仅如此,PaLM 2 还了解重要的语言细微差别。在一篇描述 PaLM 2 功能的研究论文中,谷歌工程师声称该系统的语言熟练程度“足以教授该语言”,并指出这是由于其训练数据中非英语文本更为普遍。
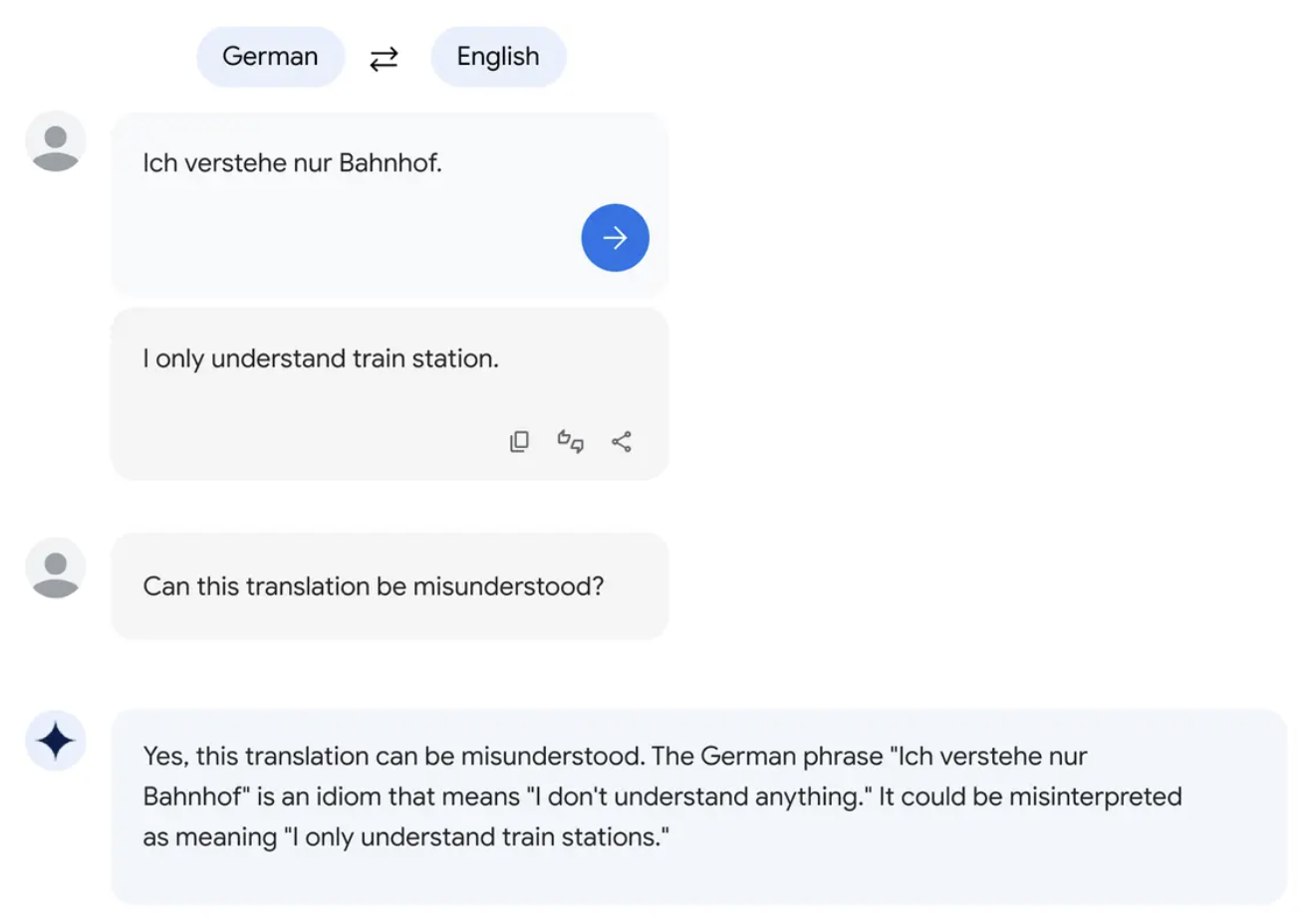
PaLM 2 的广泛数据集包括科学论文和包含数学表达式的网页,因此它还展示了逻辑、常识推理和数学方面的改进能力。

PaLM 2 推理能力示例
支持 20 种编程语言
PaLM 2 还改进了对编写和调试代码的支持。该模型使用 20 种编程语言进行了训练,包括 JavaScript 和 Python 等流行语言,还包括 Prolog、Verilog 和 Fortran 等语言。PaLM 2 构成了 Codey 的基础,Codey 是谷歌用于编码和调试的专业模型,它也作为其代码完成和生成服务的一部分推出。
代码语⾔模型是当今最具经济意义和被⼴泛部署的 LLM 之⼀。为了在开发⼈员⼯作流程中进⾏低延迟、⾼吞吐量部署,谷歌通过在扩展的、代码密集型、多语⾔的数据混合上继续训练 PaLM 2-S 模型,构建了⼀个⼩型的、特定于编码的 PaLM 2 模型,谷歌将⽣成的模型称为 PaLM 2-S* 。
PaLM 2-S* 在大量公开可用的源代码数据集上进行了预训练。它擅长 Python 和 JavaScript 等流行的编程语言,但也可以生成 Prolog、Fortran 和 Verilog 等语言的专用代码。
PaLM 2-S*在除了两种语言之外的所有语言上都优于 PaLM,同时在像 Julia 和 Haskell 这样的低资源语言上几乎没有下降。例如,PaLM 2-S*在 Haskell 上比更大的 PaLM-Coder-540B 提高了 6.3 倍,在 Julia 上提高了 4.7 倍。值得注意的是,Java、JavaScript 和 TypeScript 的性能实际上比原始语言 Python 更高。
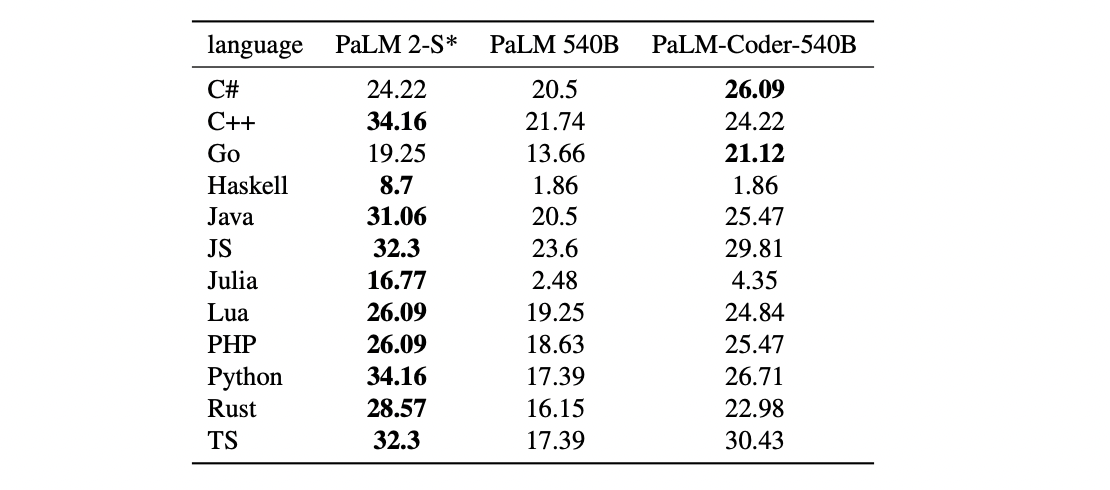
PaLM 2 可以跨编程和自然语言生成代码和自然语言。大会上,Pichai 还展示了在修改代码 Bug 后,PaLM 2 给出的韩语评论。

谷歌内部已经有超过 70 个产品团队正在使用 PaLM 2 构建产品,包括分别针对安全知识和医疗知识微调而成的 Sec-PaLM 和 Med-PaLM 2。
其中,Sec-PaLM 是专注于安全用例的版本,使用 AI 帮助分析和解释具有潜在恶意脚本的行为,并检测哪些脚本对个人或组织构成威胁。Med-PaLM 2 是基于健康数据训练的版本,可以轻松通过美国医学执照考试,达到“专家”水平。
不需要云,一部手机即可
Hoffmann 等人提出的计算最优缩放(Compute-optimal scaling)表明,数据大小至少与模型大小同等重要。谷歌在对更大的计算量进行验证后,同样发现数据和模型大小应该大致按 1:1 缩放,以实现给定训练量的最佳性能计算(与过去趋势相反,过去趋势将模型扩展的速度比数据集快 3 倍)。
谷歌表示,模型缩放并不是提⾼性能的唯⼀⽅法。相反,可以通过细致的数据选择和⾼效的架构/⽬标来释放性能。此外,更⼩但质量更⾼的模型显着提⾼了推理效率,降低了服务成本,并使模型的下游应⽤能够为更多的应⽤程序和用户服务。
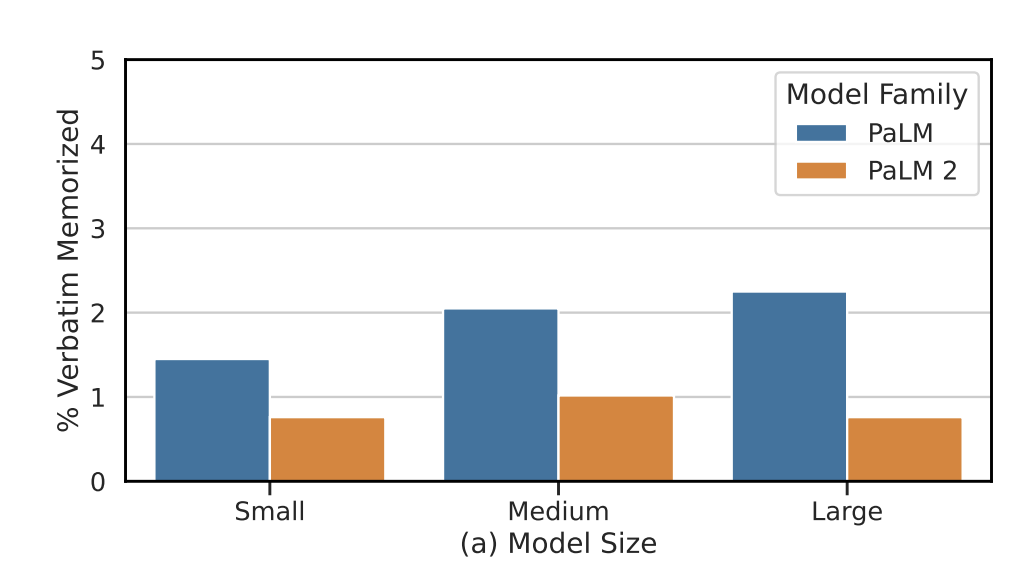
PaLM 2 比 PaLM 存储的训练数据更少
与其他需要大量时间和资源来创建的大型语言模型一样,PaLM 2 与其说是一个产品,不如说是一个产品系列。
PaLM 2 包含了 4 个不同参数的模型,包括壁虎(Gecko)、水獭(Otter)、野牛(Bison)和独角兽(Unicorn),并在特定领域的数据上进行了微调,为企业客户执行某些任务。这意味着用户不用花费大量的时间和资源来创建模型,直接部署即可。

其中,Gecko 非常轻巧,可以在移动设备上工作,每秒可以处理 20 个 token,大约每秒 16 或 17 个单词,即使在离线时也能在设备上运行出色的交互式应用程序。Gecko 不需要用户在云工作,也不需要特别强大的硬件,一个完全移动的手机芯片组就足够了。
“我们在工作中发现,并不是模型越大越好。”DeepMind 副总裁 Zoubin Ghahramani 说道,“这就是为什么我们提供了一系列不同尺寸的模型。实际上,参数规模并不是一种判断模型能力的有效方法,能力实际上是由使用模型的人来判断的,并确定它们在模型实现测试中是否有用。”
谷歌没有说明使用什么硬件来测试这个模型,只是说它在“最新的手机上”运行。然而,将语言模型的小型化意义重大。这样的系统在云端运行的成本很高,在本地使用可以减少成本。另外,还可以改善隐私等。不过问题在于,较小版本的语言模型不可避免地不如它们的较大版本。
另外大会上,谷歌还推出了个性化 Android 手机的新方法,包括 Magic Compose、Cinematic Wallpaper 和 Generative AI Wallpaper。其中,Magic Compose 是由生成式 AI 提供支持的 Google Messages 新功能,会根据消息的上下文提供回复建议,甚至会将用户写的内容转换为不同的风格。 下一代移动操作系统 Android 14 将支持这些新功能。
PaLM 2 现在可通过 Google 的 PaLM API、Firebase 和 Colab 提供给开发人员。借助 PaLM 2,谷歌希望缩小公司与微软等竞争对手之间的“人工智能差距”,否则可能会被认为实施其 AI 研究的速度缓慢。
在 Google Brain 和 DeepMind 合并之后,谷歌新的大模型也在研发当中。Pichai 表示,现在谷歌的研究重心正在转向 Gemini,这是一种多模态和高效的机器学习工具。
Bard 的进化
在谷歌内部内,PaLM 2 已经被用于支持 25 种功能和产品,包括该公司的实验性聊天机器人 Bard。Bard 在图像功能、编码功能和应用程序集成等方面都做了大幅更新。
Bard 将更加直观地响应用户问题。比如对于“新奥尔良有哪些必看景点?”之类的问题,除了文本之外,用户还将看到丰富的图片视觉效果。用户还可以在自己的要求中附加图像和文本:

编程方面,谷歌也将开发人员的反馈整合到了一些关键的编码升级中,包括:
来源引用:从下周起,代码引用将更加精确。如果 Bard 引入了一段代码或引用了其他内容,只需单击注释,Bard 就会在相应内容下划线并链接到源代码。
深色主题:这是开发人员要求的另一项功能,谷歌希望以此让开发人员更轻松地与 Bard 互动。
“导出”按钮:谷歌即将与合作伙伴 Replit 一起推出导出和运行代码的功能,首先会从 Python 开始。
另外,由于人们经常要求 Bard 抢先起草电子邮件和文档,谷歌大会上推出了两个导出操作,用户可以轻松将 Bard 的回复直接转移到 Gmail 和 Docs 中。
继微软 5 月 4 日宣布公司旗下基于 ChatGPT-4 的 Bing Chat 功能面向所有用户开放后,谷歌在本次大会上也宣布,Bard 将并向 180 多个国家和地区开放,其他更多国家和地区也将陆续开放。Bard 现在有日语和韩语版本,谷歌表示很快就会支持 40 种语言。
结束语
“作为 AI-first 公司,我们的旅程已经有七年了,我们正处于一个激动人心的转折点。”Pichai 说道,“AI 的转变与它来时一样大,没有一家公司可以单独做到这一点。我们的开发者社区将是释放未来巨大机遇的关键。”
PaLM 2 无疑是谷歌在 AI 语言模型方面迈出的重要一步,但它面临着更广泛的、该类技术普遍存在的挑战。
例如,一些专家质疑用于创建语言模型的训练数据的合法性。这些数据通常是从互联网上抓取的,通常包括受版权保护的文本和盗版电子书。创建模型的科技公司通常拒绝回答他们从何处获取训练数据的问题。谷歌在其对 PaLM 2 的描述中延续了这一传统,仅指出该系统的训练语料库由“一组不同的来源组成:网络文档、书籍、代码、数学和对话数据”,但没有提供更多细节。
语言模型的输出也存在一些固有问题,例如“虚假”,或者这些系统倾向于简单地编造信息。谷歌研究副总裁 Zoubin Ghahramani 在接受外媒采访时表示,在这方面,PaLM 2 是对早期模型的改进,“从某种意义上说,我们正在投入大量精力来不断改进基础和归因指标”,但他也指出,整个领域在打击人工智能产生的虚假信息方面“还有很长的路要走”。
虽然很多开发者很开心看到谷歌的发布成果,但部分人还是对“实际用起来是否会像谷歌宣传的那样的好”保持怀疑。相信我们会很快看到这个问题的答案。
参考链接:
https://ai.google/static/documents/palm2techreport.pdf
https://blog.google/technology/ai/google-io-2023-keynote-sundar-pichai/#ai-responsibility
https://www.theverge.com/2023/5/10/23718046/google-ai-palm-2-language-model-bard-io

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论