
近日 OpenAI 在 Dota 2 上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不太稳定、更新不够及时等。今日,谷歌推出了一款全新的开源强化学习框架 Dopamine,该框架基于 TensorFlow,主打灵活性、稳定性、复现性,能够提供快速的基准测试。
配套开源的还包括一个专用于视频游戏训练结果的平台,以及四种不同的机器学习模型:DQN、C51、简化版的 Rainbow 智能体和 IQN(Implicit Quantile Network),相比 OpenAI 的强化学习基准,Dopamine 更多关注 off-policy 方法。 为了实现可重复性,Github 代码包括 Arcade Learning Environment 支持的全部 60 个游戏的完整测试和训练代码,并遵循标准化经验评估结果的最佳实践。 除此之外,谷歌还推出了一个网站,允许开发人员将训练中的多个智能体的运行情况快速可视化。
强化学习(RL)领域的研究在过去几年中取得了重大进展,这些进展让相关代理能够以超人类水平玩游戏——包括 DeepMind 的 DQN(AlphaGo 和 AlphaGo Zero)和 Open AI Five。具体地说,在 DQN 中引入重放记忆可以利用以前的代理经验,大规模分布式训练可以在多个工作进程之间分配学习任务,分布式方法让代理对完整的分布(而不只是期望值)进行建模,从而实现更完整的学习。这方面的进展非常重要,因为相关算法还可以应用到其他领域,例如机器人技术。
通常,这类进展要求在设计方面进行快速迭代——通常没有明确的方向——并颠覆已有的方法结构。然而,大多数现有的 RL 框架并不会提供灵活性和稳定性组合,让研究人员能够有效地迭代 RL 方法,发现新的但可能没有直接明显好处的研究方向。此外,在现有框架中重现结果通常太耗时,从而导致科学的可重现性问题。
今天,我们推出了一个全新的基于 Tensorflow 的框架——Dopamine,旨在为 RL 研究人员提供灵活性、稳定性和可重复性。这个框架受大脑奖励动机行为主要组件的启发,并反映了神经科学与强化学习研究之间强的历史联系,旨在实现可以推动激进发现的投机性研究。该框架还提供了一组解释如何使用框架的 Colab( https://github.com/google/dopamine/blob/master/dopamine/colab/README.md )。

易用性
清晰和简洁是这个框架的两个关键设计考虑因素。我们提供的代码非常紧凑(大约 15 个 Python 文件),并且有详细的文档。这是基于 Arcade 学习环境(一个成熟的、易于理解的基准)和四个基于值的代理 DQN、C51、Rainbow 代理的简化版本以及隐式分位数网络代理(刚在上个月的国际机器学习大会上发布)实现的。我们希望这种简洁能够让研究人员轻松了解代理的内部运作并快速尝试新的想法。
可重现性
我们非常关注可重现性在强化学习研究中的作用。我们的代码通过了完整的测试覆盖,这些测试用例也可作为某种形式的文档使用。此外,我们的实验框架遵循了 Machado 等人给出的使用 Arcade 学习环境标准化进行经验评估的建议。
基准测试
对于研究人员来说,能够根据已有方法快速对想法进行基准测试是非常重要的。因此,我们以 Python pickle 文件(用于使用我们的框架训练的代理)和 JSON 数据文件(用于与其他框架训练的代理进行比较)的形式提供了受 Arcade 学习环境支持的 60 个游戏的完整训练数据。我们还提供了一个网站,可以在上面快速查看所有的训练运行情况。下图展示了我们的 4 个代理在 Seaquest 上的训练运行情况。
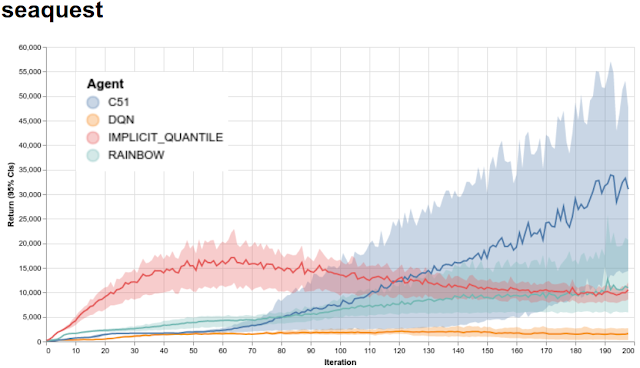
x 轴表示迭代,其中每次迭代是 100 万个游戏帧(4.5 小时的实时游戏);y 轴是每场比赛获得的平均分数;阴影区域显示来自 5 次独立运行的置信区间。
我们还提供这些代理训练的深度网络、原始统计日志以及 Tensorflow 事件文件。这些都可以从我们的网站上下载。
开源项目地址: https://github.com/google/dopamine
可视化网站: https://google.github.io/dopamine/baselines/plots.html
相关下载链接: https://github.com/google/dopamine/tree/master/docs#downloads
想了解更多关于强化学习的内容,请参看下面的文章:
查看英文原文: https://ai.googleblog.com/2018/08/introducing-new-framework-for-flexible.html

暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论