
JavaOne 次日,视频直播涵盖了四个会议室。这些会议的视频链接在本文末尾给出。
InfoQ 参与了会议《并行编程思想(Thinking in Parallel)》,本文主要讨论该话题(视频链接见文末)。该话题的演讲人是来自 Oracle 的 Stuart Marks 和 Brian Goetz。二人组完美的通过流 API(streams)解释了并行处理,其中 Marks 着重介绍了为什么要使用 Stream API,而 Goetz 着重介绍了为什么要使用并行化。
Marks 的演讲从一个将字符串数组转换成大写的示例开始,同时展示了常规实现和 Stream 实现。
常规实现使用一个 for 循环,内容如下:

这里输入数组从左往右顺序处理,但是主要运算逻辑仅仅是“转换成大写”,且每个字符串运算都相互独立。另外,数组中的数据可以以任何顺序处理,或者是并行处理。那么,如果使用 Stream 方式会怎样呢?

在使用 Stream 方式的示例中,输入数组被映射成大写,然后被重组成数组。输入和输出数组中的内容无需保证顺序,整个数组都被转换成大写。
Marks 声称 Stream 版本更好,因为它有更高级别的抽象、计算的独立性和聚合性。

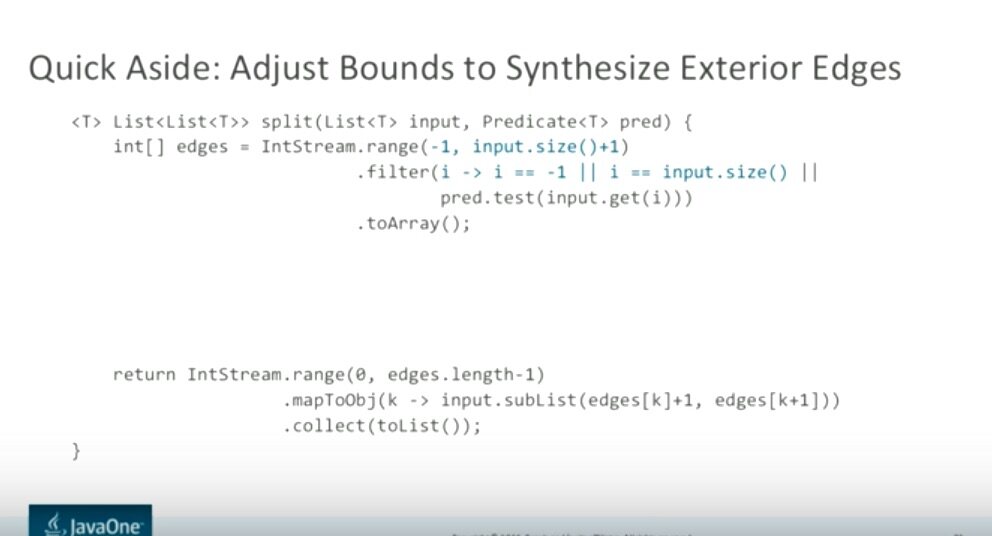
下一个示例演示的是通过指定关键字将一个列表分割,内容如下:

Marks 指出 subList 方法参数为原始列表索引值,为了完成这个需求,算法必须在“#”处分割。为了便于理解,Marks 在“#”处放置了黑条来表示子列表的边界,然后将每个边界切分并合成创建新的子列表边界。示意图如下:

使用传统方式实现这个算法:

以上实现有一些额外的复杂度,增加了理解成本,例如:start = cur + 1;语句和在 for 循环之外调用result.add方法。对此,Marks 的观点是:

Marks 对比了 Stream 实现,重新审视问题,我们唯一关心的是索引。因此,不同于之前的 for 循环,这里通过 Stream 来检查索引。由于断言和结果分割运算相互独立,我们可以针对每个元素做断言验证,并且这些验证都可以独立计算。上面描述的结果代码(消除了数组复制而改成追加到数组之后)大致如下:
Marks 总结了他的观点:Stream 实现更加清晰。

随后,Goetz 补充了 Marks 的演讲主题,考虑了并行计算的优势和劣势。他从下面这页演示文稿开始讨论并行化,指出并行化是消耗更多资源和更快得到结果的权衡。

Goetz 强调,并行计算总是会增加更多的并行化事务,例如划分工作,管理和协调任务以及他们的结果。所以,如果计算任务能够被成功的并行化,该任务本身应该是可并行化并且有优秀的并行计算框架(例如 fork-join 库)。最后,还应该有足够的数据来并行的处理。随后,Goetz 提供了一些可以有效进行并行化的示例,并向听众展示了如何分而治之:

Goetz 强调所有的并行解决方案实质上都看起来像上面分而治之的思想:将问题划分以避免同步开销。对于一个高效的并行算法,问题应该尽早的被分割。Goetz 提供了一个示例,展示了并行的对一个数组进行求和,并给出了一些性能考量:

最后,Goetz 讨论了并行 Stream 性能。Stream 容易被并行化,但是不是所有源数据都适合并行处理。
基于数组的源数据是最佳的。
根据 Goetz 的描述,“NQ 模型”是一个简单的模型,一个用来计算并行化提速的经验法则:

Goetz 探讨了“源数据分割效率”,提到了数组由于其底层实现方式,它的分割非常均匀且低成本。另外需要记得一些管道操作会依赖数据顺序,例如“限制 10 项”操作显然是按顺序应用到前 10 项。另一个需要考虑的的是有时归并操作可能成本会很高。
Goetz 总结了整个会议主题:

相关链接:

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...










评论