
Apache Spark 是一个围绕速度、易用性和复杂分析构建的大数据处理框架。最初在 2009 年由加州大学伯克利分校的 AMPLab 开发,并于 2010 年成为 Apache 的开源项目之一。Apache Spark 社区刚刚发布了 1.5 版本,明略数据高级工程师梁堰波解析了该版本中的众多新特性,同时梁堰波也是QCon 上海《基于大数据的机器学习技术》专题的讲师,他将分享《基于机器学习的银行卡消费数据预测与推荐》的专题演讲。
DataFrame 执行后端优化(Tungsten 第一阶段)
DataFrame 可以说是整个 Spark 项目最核心的部分,在 Spark 1.5 这个开发周期内最大的变化就是 Tungsten 项目的第一阶段已经完成。主要的变化是由Spark 自己来管理内存而不是使用JVM,这样可以避免JVM GC 带来的性能损失。内存中的Java 对象被存储成Spark 自己的二进制格式,计算直接发生在二进制格式上,省去了序列化和反序列化时间。同时这种格式也更加紧凑,节省内存空间,而且能更好的估计数据量大小和内存使用情况。如果大家对这部分的代码感兴趣,可以在源代码里面搜索那些Unsafe 开头的类即可。在1.4 版本只提供UnsafeShuffleManager 等少数功能,剩下的大部分都是1.5 版本新加入的功能。
其它优化还包括默认使用code generation,cache-aware 算法对join、aggregation、shuffle、sorting 的增强,window function 性能的提高等。
那么性能到底能提升多少呢?可以参考DataBricks 给出的这个例子。这是一个16 million 行的记录,有1 million 的组合键的aggregation 查询分别使用Spark 1.4 和1.5 版本的性能对比,在这个测试中都是使用的默认配置。
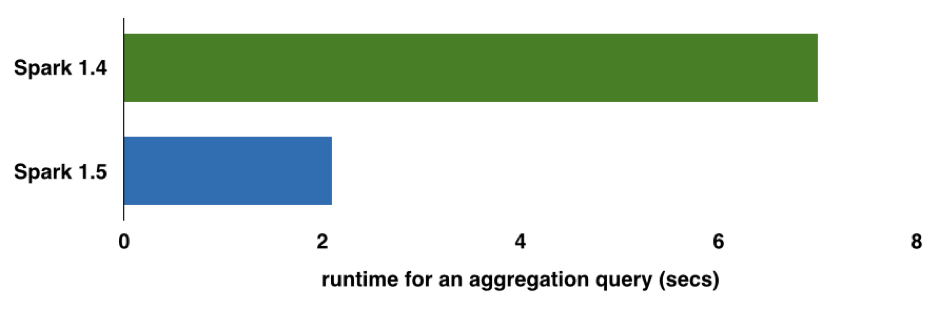
那么如果我们想自己测试下Tungsten 第一阶段的性能改如何测试呢?Spark 1.4 以前的版本中 spark.sql.codegen, spark.sql.unsafe.enabled等几个参数在 1.5 版本里面合并成 spark.sql.tungsten.enabled 并默认为 true,只需要修改这一个参数就可以配置是否开启 tungsten 优化(默认是开启的)。
DataFrame/SQL/Hive
在 DataFrame API 方面,实现了新的聚合函数接口 AggregateFunction2 以及 7 个相应的 build-in 的聚合函数,同时基于新接口实现了相应的 UDAF 接口。新的聚合函数接口把一个聚合函数拆解为三个动作:initialize、update、merge,然后用户只需要定义其中的逻辑既可以实现不同的聚合函数功能。Spark 的这个新的聚合函数实现方法和 Impala 里面非常类似。
Spark 内置的 expression function 得到了很大的增强,实现了 100 多个这样的常用函数,例如 string、math、unix_timestamp、from_unixtime、to_date 等。同时在处理 NaN 值的一些特性也在增强,例如 NaN = Nan 返回 true;NaN 大于任何其他值等约定都越来越符合 SQL 界的规则了。
用户可以在执行 join 操作的时候指定把左边的表或者右边的表 broadcast 出去,因为基于 cardinality 的估计并不是每次都是很准的,如果用户对数据了解可以直接指定哪个表更小从而被 broadcast 出去。
Hive 模块最大的变化是支持连接 Hive 1.2 版本的 metastore,同时支持 metastore partition pruning(通过 spark.sql.hive.metastorePartitionPruning=true 开启,默认为 false)。因为很多公司的 Hive 集群都升级到了 1.2 以上,那么这个改进对于需要访问 Hive 元数据的 Spark 集群来说非常重要。Spark 1.5 支持可以连接 Hive 0.13, 0.14, 1.0/0.14.1, 1.1, 1.2 的 metastore。
在 External Data Source 方面,Parquet 的支持有了很大的加强。Parquet 的版本升级到 1.7;更快的 metadata discovery 和 schema merging;同时能够读取其他工具或者库生成的非标准合法的 parquet 文件;以及更快更鲁棒的动态分区插入。
由于 Parquet 升级到 1.7,原来的一个重要 bug 被修复,所以 Spark SQL 的 Filter Pushdown 默认改为开启状态(spark.sql.parquet.filterPushdown=true),能够帮助查询过滤掉不必要的 IO。
Spark 1.5 可以通过指定 spark.sql.parquet.output.committer.class 参数选择不同的 output committer 类,默认是 org.apache.parquet.hadoop.ParquetOutputCommitter,用户可以继承这个类实现自己的 output committer。由于 HDFS 和 S3 这两种文件存储系统的区别,如果需要向 S3 里面写入数据,可以使用 DirectParquetOutputCommitter,能够有效提高写效率,从而加快 Job 执行速度。
另外还有一些改动,包括:StructType 支持排序功能,TimestampType 的精度减小到 1us,Spark 现在的 checkpoint 是基于 HDFS 的,从 1.5 版本开始支持基于memory 和local disk 的checkpoint 。这种类型的checkpoint 性能更快,虽然不如基于HDFS 的可靠,但是对于迭代型机器学习运算还是很有帮助的。
机器学习MLlib
MLlib 最大的变化就是从一个机器学习的 library 开始转向构建一个机器学习工作流的系统,这些变化发生在 ML 包里面。MLlib 模块下现在有两个包:MLlib 和 ML。ML 把整个机器学习的过程抽象成 Pipeline ,一个 Pipeline 是由多个 Stage 组成,每个 Stage 是 Transformer 或者 Estimator。
以前机器学习工程师要花费大量时间在 training model 之前的 feature 的抽取、转换等准备工作。ML 提供了多个 Transformer,极大提高了这些工作的效率。在 1.5 版本之后,已经有了 25+ 个 feature transformer,其中 CountVectorizer, Discrete Cosine Transformation, MinMaxScaler, NGram, PCA, RFormula, StopWordsRemover, and VectorSlicer 这些 feature transformer 都是 1.5 版本新添加的,做机器学习的朋友可以看看哪些满足你的需求。
这里面的一个亮点就是 RFormula 的支持,目标是使用户可以把原来用 R 写的机器学习程序(目前只支持 GLM 算法)不用修改直接搬到 Spark 平台上来执行。不过目前只支持集中简单的 R 公式 (包括’.’,’~’,’+’和 ‘-‘),社区在接下来的版本中会增强这项功能。
另外越来越多的算法也作为 Estimator 搬到了 ML 下面,在 1.5 版本中新搬过来的有 Naive Bayes、K-means、Isotonic Regression 等。大家不要以为只是简单的在 ML 下面提供一个调用相应算法的 API,这里面变换还是挺多的。例如 Naive Bayes 原来的模型分别用 Array[Double] 和 Array[Array[Double]] 来存储 pi 和 theta,而在 ML 下面新的 API 里面使用的是 Vector 和 Matrix 来存储。从这也可以看出,新的 ML 框架下所有的数据源都是基于 DataFrame,所有的模型也尽量都基于 Spark 的数据类型表示。在 ML 里面的 public API 下基本上看不到对 RDD 的直接操作了,这也与 Tungsten 项目的设计目标是一致的。
除了这些既有的算法在 ML API 下的实现,ML 里面也增加了几个新算法:
- MultilayerPerceptronClassifier(MLPC)这是一个基于前馈神经网络的分类器,它是一种在输入层与输出层之间含有一层或多层隐含结点的具有正向传播机制的神经网络模型,中间的节点使用sigmoid (logistic)函数,输出层的节点使用softmax 函数。输出层的节点的数目表示分类器有几类。MLPC 学习过程中使用 BP 算法,优化问题抽象成 logistic loss function 并使用 L-BFGS 进行优化。
- MLlib 包里面增加了一个频繁项挖掘算法 PrefixSpan,AssociationRules 能够把 FreqItemset 生成关联式规则。
- 在 MLlib 的统计包里面实现了 Kolmogorov–Smirnov 检验,用以检验两个经验分布是否不同或一个经验分布与另一个理想分布是否不同。
另外还有一些现有算法的增强:LDA 算法、决策树和 ensemble 算法,GMM 算法。
- ML 里面的多个分类模型现在都支持预测结果的概率而不像过去只支持预测结果,像 LogisticRegressionModel、NaiveBayesModel、DecisionTreeClassificationModel、RandomForestClassificationModel、GBTClassificationModel 等,分别使用 predictRaw、predictProbability、predict 分别可以得到原始预测、概率预测和最后的分类预测。同时这些分类模型也支持通过设置 thresholds 指定各个类的阈值。
- RandomForestClassificationModel 和 RandomForestRegressionModel 模型都支持输出 feature importance
- GMM EM 算法实现了当 feature 维度或者 cluster 数目比较大的时候的分布式矩阵求逆计算。实验表明当 feature 维度 >30,cluster 数目 >10 的时候,这个优化性能提升明显。
- 对于 LinearRegressionModel 和 LogisticRegressionModel 实现了 LinearRegressionTrainingSummary 和 LogisticRegressionTrainingSummary 用来记录模型训练过程中的一些统计指标。
Spark 1.5 版本的 Python API 也在不断加强,越来越多的算法和功能的 Python API 基本上与 Scala API 对等了。此外在 tuning 和 evaluator 上也有增强。
其他
从 Spark 1.5 开始,Standalone、YARN 和 Mesos 三种部署方式全部支持了动态资源分配。SparkR 支持运行在 YARN 集群上,同时 DataFrame 的函数也提供了一些 R 风格的别名,可以降低熟悉 R 的用户的迁移成本。
在 Streaming 和 Graphx 方面也有非常大的改进,在这里不在一一赘述,详细可以参考发布说明。
感谢郭蕾对本文的审校。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...









评论