
华盛顿大学计算机科学系刚刚发布了 Max Krohn(MIT)所作的一次演讲,题目是“以分布式信息流控制维护Web 安全”。
Max 在演讲中解释说,他观察到一场计算领域的变革正在发生,正从桌面软件向服务器端软件和云计算变迁。
但他提醒道:
Web 软件是错漏不断的,为攻击者发现和利用。结果技术数据被盗或者被毁坏。
很多人都使用没法做静态分析的动态语言,很随意地使用第三方的代码、插件……照直说吧,为了让网站快速上线运行,我们做了很多草率的拼凑。
他定义了一个有意思的指标来粗略衡量软件的脆弱程度——用代码行数(LOC)除以装机数量。软件安装的次数越多,就像 Linux,缺陷被发现及纠正的机会就越大,因此缺陷的数量就会越少。他用了几页幻灯片来列举 Web 应用的 LOC 和 LOC/ 装机数量,以此阐明其观点。
Max 的研究目标是为新类型的应用和架构定义一个安全模型。像 Facebook 这类应用允许开发者在平台中插入代码,甚至允许第三方服务器在 Facebook 平台上提供功能,问题变得更加严峻。
为了应对新挑战,Max 和同事一起,以分布式信息流控制(Decentralized Information Flow Control,DIFC)模型为基础,开发了开源 Web 应用安全基础设施 Flume :
DIFC 这种安全手段,让应用程序的作者能够控制应用的组成部分与外部世界之间数据如何流动。
对于隐私数据,DIFC 允许不被信任的软件使用隐私数据,但由受信任的安全代码控制是否透露该数据;同时在数据完整性方面,DIFC 让受信任的代码保护不受信任的软件,使之免于意外的伪造输入之威胁。
他们将服务器视为一个黑盒,并在响应构造的时刻跟踪数据。整个安全架构由一个安全网关和一个操作系统库组成,Web 应用可使用该操作系统库标记数据。核心思路是把所有安全决策集中在网关,防止不希望出现的数据访问。
典型的 Flume 应用由两类进程构成。不受信任的进程完成大部分工作,它们受到 DIFC 控制的约束,且有可能自身并不知道 DIFC 的存在。另一方面,受信任的进程知道系统中存在 DIFC,它们设立隐私及数据完整性控制来约束不受信任的进程。受信任的进程还有特权,可以选择性地违反经典的信息流控制——例如可以解密隐私数据(以导出到系统外),或者为数据完整性做担保。
系统的核心建基于一组相当简单的数据跟踪规则,用标签(Tags and Labels)来跟踪数据。
标签 t 本身并无内在的涵义,但进程一般会将每个标签与某个加密或完整性的范畴联系起来。举例来说,Tag b 可能标示(label)Bob 的隐私数据。Label 是标签集(tag set)的子集。
如果 Flume 进程 p 有一个 label 是进程 q 的子集,那么 p 可以向进程 p 发送数据。Flume 模型假定在同一台机器上运行着许多进程,并且通过消息或“流”相互通信。模型的目标是通过管制进程的通信以及进程 label 的变化,实现对数据流的跟踪。
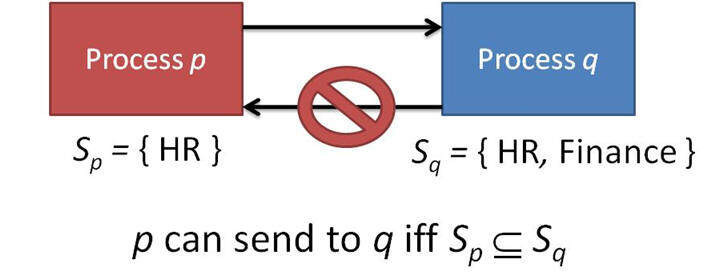
图 1. 通信规则
Max 指出这种思路并不是新的,而是从 80 年代就出现了。
网关是 Flume 安全架构的关键元素。首先 Web 应用不需要了解浏览器的任何情况,因为网关能够制定策略。但网关的中心角色使我们需要引入另一种新抽 象:Endpoint。由于网关需要协调多个系统的交互(浏览器、认证仓库、Web 应用……),不能向所有的进程公开同一组 label。Endpoint 有助于定义特别的 label 组合,专用于在网关与特定进程间实施通信。
演讲的第二部分集中展现一个基于 MoinMoin Wiki 的 用例。Max 以此用例说明 Flume 能解决的问题远不止已知的缺陷类型(缓冲区溢出、跨站脚本以及 SQL 注入)。他演示了 MoinMoin Wiki 日历功能中的一处安全缺陷,利用该缺陷,原本应该只限于特定用户组的日历条目可以被所有用户看到。而仅仅用了标准策略,Flume 就能阻止不该显示的日历内容。
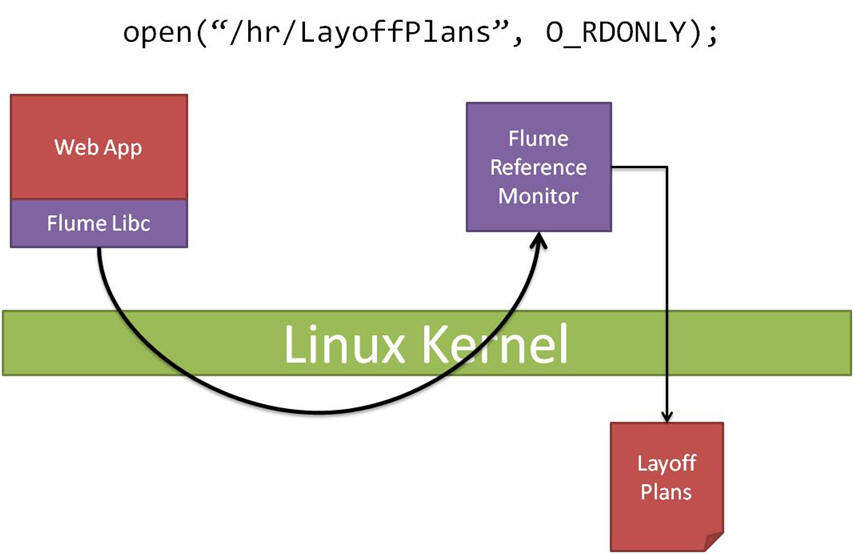
图 2. 系统调用委托
Max 总结说需要做的工作还很多。他们希望使系统更加灵活,以便能够处理 Web 应用中第三方上传的软件。他们也在研究如何让人们用同样的原则去共享数据。还有计划将触角延伸到浏览器层,把 JavaScript 纳入到架构之中。Max 预见在金融行业会有许多用途。
联网系统的发展越来越需要端到端的安全解决方案,用应用程序代码之外的手段,强制施行数据访问策略,阻止恶意的访问。您的观点如何?是否曾遇到过这类安全问题?您用了什么样的方法解决?
查看英文原文: Securing the Web with Decentralized Information Flow Control

暂无签名

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论