
我是汪源,来自网易杭州研究院,网易有不同的事业单元,包括说媒体、教育、音乐、严选、游戏等,我们团队给所有的事业单元提供技术支撑。同时这几年我们也通过网易数帆品牌为 300 家以上中大型的客户提供技术服务。今天来ArchSummit全球架构师峰会上,主要分享我们长期以来对数据分析技术相关的趋势的观察和思考。
首先介绍一下自己。我可以说是干了一辈子数据相关的技术研发,我在网易杭州研究院也会管理基础设施、云原生、IT 等相关的团队,从我个人来说最关注的还是数据相关的领域,因为我在 2003 年作为核心开发人员参与神舟 OSCAR 国产数据库的建设,现在叫做神通数据库,最近他们也在科创板提交了招股书。2006 年,我在网易研究院成立的第一天加入了研究院,第一个项目做的是分布式数据库 DDB,也是国内最早的一批分布式数据库的产品。到后面持续在数据分析的链路上,2014 年我们做了网易猛犸,底层的以 Hadoop 基础的平台。今天我还作为网易数帆负责人,旗下有一个产品线叫网易有数,提供所有面向数据分析的技术栈,最底层是以 Hadoop 为基础的 NDH 的发行版,中间提供了数据研发的平台和数据治理的平台和数据中台的解决方案,最上层也提供了 BI 的产品。
因为我的工作,我在日常中非常关注数据分析领域相关的技术趋势和发展,我之前在个人公众号“冷技术热思考”上也分享过一些观察和思考,涉及到数据中台、数据基础设施创新的方向、数据湖之类的,有时候也会出来解释一下我们为什么要去做网易数帆有数大数据基础平台 NDH 这个产品。
当前在数据分析领域新的名词和新的方向是非常多的,所以有很多的客户比较困惑:有这么多的新方法、新趋势,我看得眼花缭乱,怎么办?我提炼出我认为最主要的三条主线,这些主线都是在发展过程中,当前并没有非常高的成熟度,但是我觉得是最值得关注的。
数据分析领域的发展与新概念
数据分析领域的方法论层出不穷,最核心的是上个世纪 90 年代形成的一系列分析方法,直到今天还是我们使用的最主要的方法。比如 1993 年由图灵奖获得者 Edgar Frank Codd 在一篇文章所提出的 OLAP 与多维分析的概念,由 Bill Inmon 和 Ralph Kimball 两位大师级人物提出的“数据仓库”的整套比较规范的建设方法。BI 的概念也在 90 年代开始盛行开来。另外还有数据治理、主数据管理、数据挖掘等概念。
最近 20 年,方法论的创新不是特别多,但是技术体系的进步非常大。有一个技术底座上很大的进步,就是大数据或者说数据湖的一套体系,分为几个主要模块,在最底层是低成本的分布式存储技术,包括在私有环境下部署的 HDFS 文件系统,在云端主要是对象存储。在计算层发展了 MapReduce 框架,包括 Spark 也还是在 MapReduce 框架之内,在调度层有 YARN 和 K8s。非常核心的一点是这个行业形成了一个标准并且开放的数据格式,最典型的代表就是 Parquet,它既可以表达结构化的数据,也可以有效表达半结构化的数据,比如 JSON 这种嵌套式的结构,也可以转化成 Parquet 格式。所有的上层应用都会和 Parquet 格式衔接,所以在这之上又形成了像 Hive MetaStore(HMS)这样的体系规范 Catalog,还有优秀的 SQL 引擎,像 Impala、SparkSQL、Presto。

这个体系完全基于开放的技术和标准,这些标准并非由某个单位制定,而是事实上的标准。如果 Hadoop 相应的技术体系要用传统的商业化产品如 Oracle、Teradata 等去满足,成本会特别高。这个体系可能是过去 20 年在基础侧所产生的最大成就。
过去 20 年我们在流计算也形成了非常成熟的基础产品。比如说传输方面有 Kafka 和 Pulsar,在计算方面有 Flink,当然早期还有 Storm,现在已经基本被淘汰。最近 20 年在应用场景上盛行各类机器学习相关的应用,我们有个性化推荐、搜索、精准广告、风控、量化交易等,这在 20 年前是比较少的,虽然与机器学习相关的数据挖掘在 30 年前被提出来了,但是机器学习真正盛行起来是在这 20 年。
现在数据分析领域相关的概念,有很多而且很杂,经过 30 年的发展,可能又进入到一个比较混乱的状态。比如说我日常最关注的一些概念,Lakehouse(湖仓一体),刚刚看到它在 InfoQ 技术采用生命周期已经进入晚期大众阶段。Data Fabric、Data Mesh 被列在最左边的早期采用者阶。有一些厂商死活跟一个词过不去,叫 ELT,并且产生了一系列的跟它相关的词。有的说我们不做 ETL 了,要做 ELT;有的说我做 AutoETL,甚至有的宣传我可以 NoETL;还有反向 ETL,就是把数仓里面分析的结果又灌到业务系统里面去。

还有很多词在刚才的曲线中还没有出现过,欧美讨论比较多。其中一个是 Semantic Layer(语义层)。大概是在 1991 年,Business Objects(BO)在还没有被 SAP 收购的时候,就提出了 Semantic Layer 的概念。后来这个词不温不火,最近两三年突然又火起来了,不少创业公司都宣称自己是在做一个 Semantic Layer 产品。有些叫得朴实一点,说做的是 Metric Layer(指标层)。还有一些把自己定位成 HeadlessBI,没有头的 BI,它不带展示和交互层,但是可以做语义的建模,可以定义好规范的管理。另外,我们国内最近五年一直在讨论的是数据中台、DataOps、数据虚拟化。
这些词都是当下数据分析领域经常看到的,这些词应该怎么梳理和整合呢?接下来就是我的核心观点:现代化数据分析领域主要发展趋势是三大主题,这三大主题我都用“统一”这个词来描述,我认为大家追求的是怎么样做一个统一的基础设施,怎么样做一个统一的中间层,怎么样做统一的数据资产。我也希望整个行业能够往这些方向去聚焦,不要产生太多的相互割裂的概念。
统一的基础设施
第一个是统一的基础设施。比较理想的统一的基础设施,是一个流式湖仓的基础设施——湖仓和流批都一体之后,我们把它称为流式湖仓——它的实现现在开始出现了非常扎实的基础,你不能说它是非常的完善,但是至少是可用的成熟度。这里面除了最底层的对象存储是各个云厂商提供的,其他的都是开源的技术。我们整个文化一直围绕开源的技术,这里面有一些项目就是由我们自己研发之后开源共享出来的。
我认为整个统一的基础设施已经形成了六层架构,如果加上元数据就是七个模块的架构。最底层还是存储层,然后是 Parquet 文件格式层,中间加了缓存加速层,用来弥补上层需求和底层对象存储之间的性能差距,现在出现的有 Alluxio、JuiceFS、CurveFS,其中 CurveFS 是我们开源出来的一个平台,它能够做同样的工作。
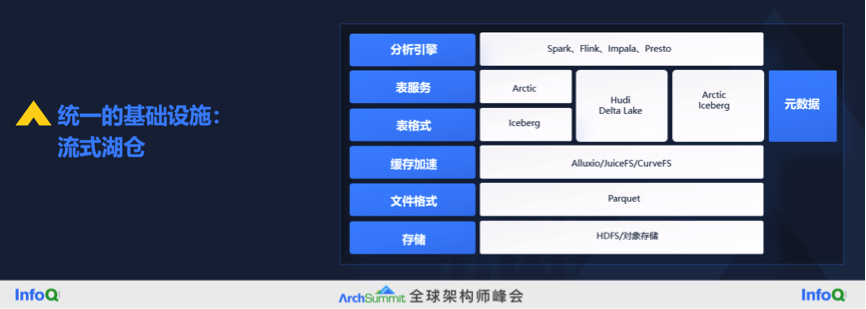
最核心的是在最近两三年我们整个行业中出现了两个新的层次,一个是表格式(table format),一个是表服务(table service),这两个层次能够解决底层大数据体系怎样做到满足湖仓一体、实时更新、版本一致性、ACID 等等,之前的大数据没有这样的功能,所以它无法做一些实时的分析服务,只能做 T+1 的分析。这两个层次可以看到有 Iceberg、Arctic、Hudi 等。最上层是分析引擎层。
Iceberg 是 Netflix 团队开源出来的,我认为它是现在社区里面最有希望成为 table format 标准的项目。跟它竞争的还有 Hudi(Hadoop Upsert anD Incremental),Hudi 最近迫于竞争压力,也把它的 table format 开放出来的。原来的数据湖三剑客,Delta Lake、Iceberg 和 Hudi 里面,Hudi 是一个相对封闭的体系,它的 table format 是不开放的。
Iceberg 从数据层面提供了 ACID 的能力,并且可以读到任何时间点的数据;第二个从元数据层面解决了 HMS 性能瓶颈,把原来集中式的元数据变成了分布式的元数据,并且相当于给数据构建了一个多级的索引,能够支持高级过滤,这能解决很多问题。很多时候在大数据的体系中,一个 query 所需要 touch 的文件数字非常多,可能是几千万、几亿,甚至更多的文件。那么这个 query 在准备的时候需要去读取哪些文件?我们在自己的场景中之前用 Hive 技术,一个 query 启动要花 20 分钟——它还没有开始跑,只是为了分析清楚到底哪些数据是需要读取的。Iceberg 可以把这个性能直线降低至不到一分钟,这是一个非常夸张的进步。
第二个比较核心的项目是 Arctic,这是我们在 8 月份的时候开源的一个项目,但这个项目在网易数帆内部研发已经将近三年的时间了。Arctic 主要用来帮助 Iceberg 把整体的技术体系构建完整,因为 Iceberg 只是一种格式,但是怎样利用这种格式把它组织成面向分析性能最优化的状态,它是不管的,所以我们在 Arctic 中主要提供了自优化的能力。我们提供了一个基于 Iceberg 的自优化的机制,并且我们提供了 upsert 的功能,也就是说支持高效的数据更新。
另外我们做到流批一体,一张流表和一张批表的定义是一致的,可以复用。最后为了让这个技术快速落地,我们是可以兼容 Hive 和 Iceberg,一张 Hive 的表,你不需要做任何动作可以无缝升级成 Arctic 表,不需要做数据迁移。
我认为 Iceberg+Arctic 在新的技术栈里面处于核心的位置。在老的技术栈中,Parquet 是一个开放的文件格式,HMS 是大家公认的元数据的服务。在这 Parquet 和 HMS 下面有不同的存储体系,还有不同的计算体系,它们两个是唯一的标准,基本上没有别的选择。到今天由 Iceberg 和 Arctic 共同构建的这一层会成为一个新的事实的标准,在它下面有很多不同的存储,在它上面有不同的计算体系。这个中间基本上胜出的只有一家,不可能有多家,否则这个技术栈就混乱了。我们目前看好的是 Iceberg+Arctic 这条路,其实之前我们非常看好 Iceberg 的发展,所以就做了一个跟它配套的项目 Arctic。
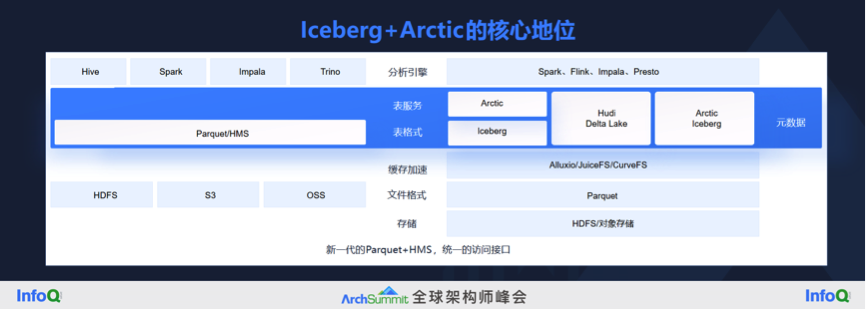
小结一下,统一的基础设施解决的四大问题,第一是湖仓一体,第二是流批一体,第三是标准格式,不仅是文件格式,还包括表格式,最后是实现存算分离。
统一的中间层
第二个话题是统一的中间层。一提到中间层我们就想到 ETL,现在很多人想灭掉它。这张图来自从蚂蚁金服出来创业的 Aloudata 团队,原来大家设想数据从数据源经过 ETL 进入到数仓再到 BI,但实际上如同这张图所画,ETL 环节是无所不在的。
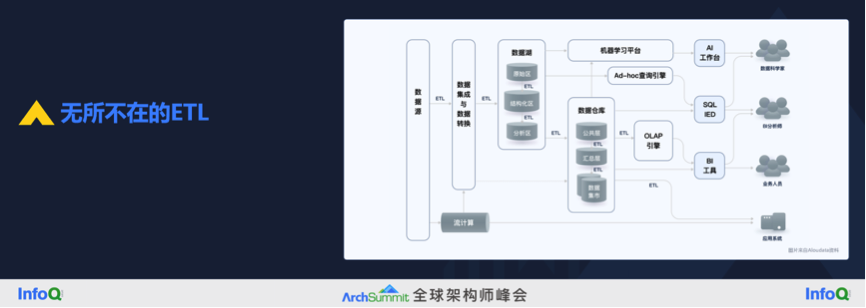
为什么会有 ETL 呢?所谓的 ETL 就是一个把原始数据转化成分析所需要的好用的数据的过程。理想的状态下,很多理论大师们给我们规划了一条路线,在数据仓库里面做好了所有的数据转化,每一个团队用很好的 BI 工具,应该只做数据的展现和交互,所有的计算逻辑应该都在数仓里面完成,或者说最多再加一个数据集市——数据集市其实也可以认为是数据仓库大体系的一部分。但实际上大家会发现每一个团队都会在自己的 BI 里面又去做了很多的计算逻辑,因为数据仓库的计算逻辑不够用,导致一个很大的问题就是分散的计算逻辑。大家在不同的 BI 产品中看到的数据口径是不一样的,结果也是不一样的,就是由分散的计算逻辑带来的。

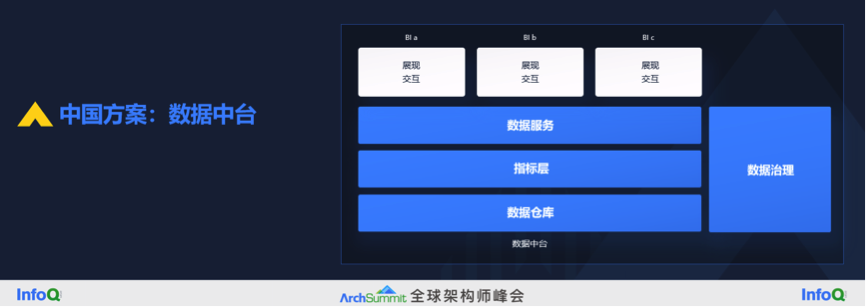
怎么样解决这个问题呢?有很多的方案,我把它们分为中国方案、国际方案和我们的方案。中国方案就是数据中台,要做到 OneData、OneService、OneID,解决指标口径不一致的问题,所有的口径定义、计算逻辑都应该在中台里面做好。
数据中台大致有这么几个模块,包括了数据仓库(我认为典型的数据中台是包括了数据仓库这一层)。在数据仓库定义了一套规范的指标层,包括原始指标、派生指标、复合指标,派生应该是原始指标加上时间周期加上修饰词等等。上面是数据服务层,对外提供所有对外的数据。同时又引入了数据治理的概念来保证中台输出的数据是高质量的,是符合安全要求的。
国际方案没有这么复杂,只有三个核心的概念:Semantic Layer、HeadlessBI 和 Metric Layer。它们其实是近义词,不同的公司有不同的叫法。有一些公司年头比较长了,比如 GoodData,最近宣传自己是 Semantic Layer 公司。Kyvos 宣称给印度政府建了全球最大的数据平台,之后做了很多相关的产品。
国际方案里面最贴切的描述是 HeadlessBI,我引用了其中一个产品叫 Cube,下图来自 Cube 官网,数据输入来自左边的各种数仓,它在 HeadlessBI 这一层要做的是数据建模、安全相关的访问控制、性能加速,最后以 API 的方式提供给右边的下游消费者,主要是 BI 工具,以及一些数据产品中内嵌的展示,也就是嵌入式的分析。
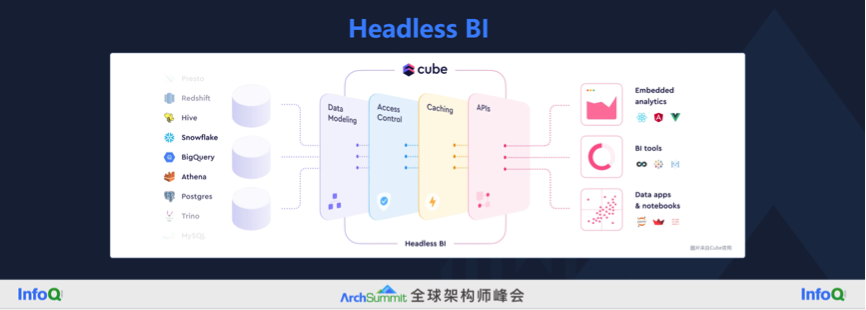
我们在这个方向也做了一点贡献,思路和大家不太一样。我们强调的是开发和治理一体化,让指标、模型等等持续保持高质量。大致的产品设计逻辑,是我们在建数仓、建指标这些开发活动的过程中,同步把数据治理的活动也做掉了。这是因为我们发现有很多客户,先找开发的厂商来做开发,做完之后发现数据质量不太行,又去找数据治理的厂商来做数据治理的项目。我们认为可以把开发和治理做到一体化,在开发环节同时把开发治理做好了,就不会有后遗症了。
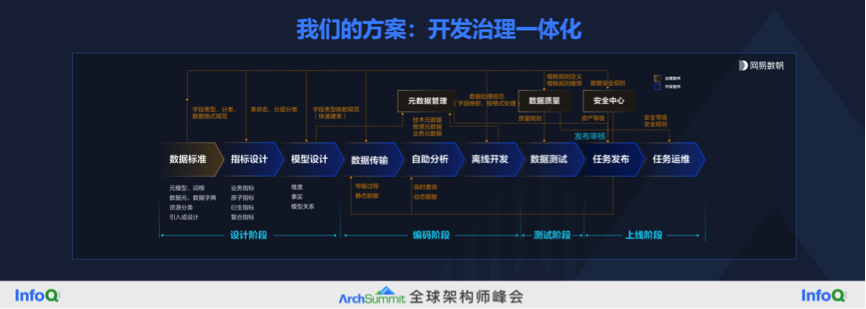
最终,我们希望会产生这样一个统一的中间层,包括数据仓库和 HeadlessBI 两层,后者能做建模,包括指标,做权限、加速和服务,同时把开发和治理一体化了,没有单独的数据开发和数据治理相关的模块。所以它的目标就是通过统一的模型指标计算逻辑和口径,实现事前事中事后的持续治理。这个时候 BI 层才可以真正的聚焦在展现和交付上,这一层 BI 我命名为 NecklessBI,底下的 HeadlessBI 是无头 BI,上面是只有头没有脖子的 BI。

最后再说一下 ETL。我认为 ETL 不会被消除的,它只能被转移或隐藏,因为从数据源到分析所需要的数据一定是有很多不匹配的,数据源在设计的时候不会考虑到为了分析需求设计的,所以说 ETL 是一定会有的。但是比较现实的是做 ETL 的自动化,比较低调一点叫 AutoETL,高调的 NoETL 其实也是 AutoETL。HTAP 这个场景的应用可能有限,大量的分析工作要做多源数据的整合,HTAP 在这个过程中发挥不了太多的作用。
统一的数据资产
最后是统一的数据资产。我们企业做数据分析的时候面临很多的问题,不是有强大的算力就可以了,有很多资产管理不到位带来的问题,比如说数据找不到,找到了看不懂,看了之后信不过、不敢用,因为不知道数据质量;最后从企业管理层的角度,他觉得这么多的数据管不牢。这都是在数据资产相关领域面临的很大的问题,之前建数据中台也是希望解决类似的问题,但我认为这主要还是数据资产管理的问题。
我看到了一个比较可行的思路就是 Data Fabric,它的目的是实现数据的整合利用,它是一个架构思想或者设计理念,并不绑定一个特定的技术实现。Data Fabric 强调元数据要集中管理,但是从数据本身可以兼容各种风格数据的处理手段,我们可以用 ETL 的方式来做 Data Fabric,也可以用虚拟化的方式来做。当然我个人认为如果用 ETL 和数据仓库的方式来做 Data Fabric,那么 Data Fabric 的优势就发挥得就没有那么明显。

其他几个做数据整合利用的方式的区别,第一个是数据仓库或者数据中台,比较强调数据的集中,同时也强调数据比较深度的预加工,数据仓库就是要对数据进行深度的预加工。第二个是数据湖,强调数据的集中,但是它强调数据不要做太多的预加工,应该按照原始的数据格式都存在湖里面,需要的时候再把它拿出来处理。Data Fabric 是强调元数据的集中。
Data Fabric 的实际落地需要构建四个方面的核心能力:
一是连接数据源,连接各种各样的数据源。比如一些产品更新以后,数据暴露的方式变了,我们再连接花了不少的时间。所以连接数据源是一个非常复杂和非常关键的能力,很多产品目前在这方面做得还不是特别好。

二是元数据的管理,要做到主动元数据(active metadata)。因为最传统的元数据是要靠手工登记注册的,这种情况下要管理企业的数据资产,工作量是非常大的,而且也很容易导致阶段性做元数据管理,而不是项目验收的时候元数据注册很好,结果项目验收完了,手动注册的元数据就跟不上变化。主动元数据可以主动地扫描这些数据源的数据变化,通过智能化的识别、知识图谱相关的技术帮助我们理解元数据和数据之间的关系。
三是数据虚拟化,我认为数据虚拟化能最大程度发挥 Data Fabric 的能力,因为它能够在数据没有完成集中之前就能够做一定程度的利用,当然它的天花板可能也不是太高,你不能假设所有的数据分析都可以基于数据虚拟化来做。
四是我们做的逻辑数据湖,也是 Data Fabric 的一种实现。逻辑数据湖从逻辑上看是一个湖,但是从物理实现上数据位置还是分散的,还是存在 Hadoop、Oracle、MySQL 里面。详见之前的回顾 | Data Fabric:逻辑统一、物理分散
总结
最后简要总结,现代数据分析技术的三大主题,第一个是构建一个统一的基础设施,这个基础设施能够支撑数据的实时的更新和消费,它本身又是一个开放的、低成本的体系,我们命名为流式湖仓。
第二个是统一的中间层,要做到统一的模型、指标、计算逻辑和口径,另外要做到事前事中事后持续的数据治理,它的组成部分包括了数据仓库和 HeadlessBI 这两个层次。
第三个是统一的数据资产,它的目的是要做企业全域数据资产的高效的发现、整合和管理,它在实现上能够兼容各种风格的数据处理技术,核心的概念有很多分析机构提倡的 Data Fabric,我们也提供了称为逻辑数据湖的 Data Fabric 实现。
【活动推荐】
在 12 月 2-3 日,ArchSummit 架构师峰会,将在北京举办,这次会议重点讲述架构演进,以及在架构层面的落地细节,同时也会分享在当前形势下,国内可替代的软件方案。更多细节可以查看会议官网 https://archsummit.infoq.cn/202212/beijing/track




