
随着云原生时代的到来和 Kubernetes(简称 K8s)的日渐成熟,越来越多的互联网团队开始将 Kubernetes 作为新的重要基础设施,一些云计算厂商也将其视作云服务及应用交付的新底座。在大家的普遍认知里,Kubernetes 是一个容器编排系统,擅长无状态的应用部署管理,在微服务领域起到了重要作用。由于容器对外部基础环境的不感知和状态易失的特性,与有状态应用的管理似乎有天然的矛盾。Operator 就是“有状态应用容器化”的一个优雅的解决方案,本文将介绍网易数帆旗下的轻舟中间件基于 Operator 的 Redis 容器化实践。
Redis、Kubernetes 预备知识
Redis 是基于 Key-Value 的缓存数据库,具有高性能、数据结构丰富、原生的高可用和分布式支持等特点,是目前业界使用最广泛的缓存中间件之一。从 Redis 3.0 版本开始,推出了 Redis Cluster 这一原生的、集群自治的分布式解决方案,支持在线水平扩缩容和故障自动转移,帮助我们突破了单机内存、并发、流量的瓶颈。
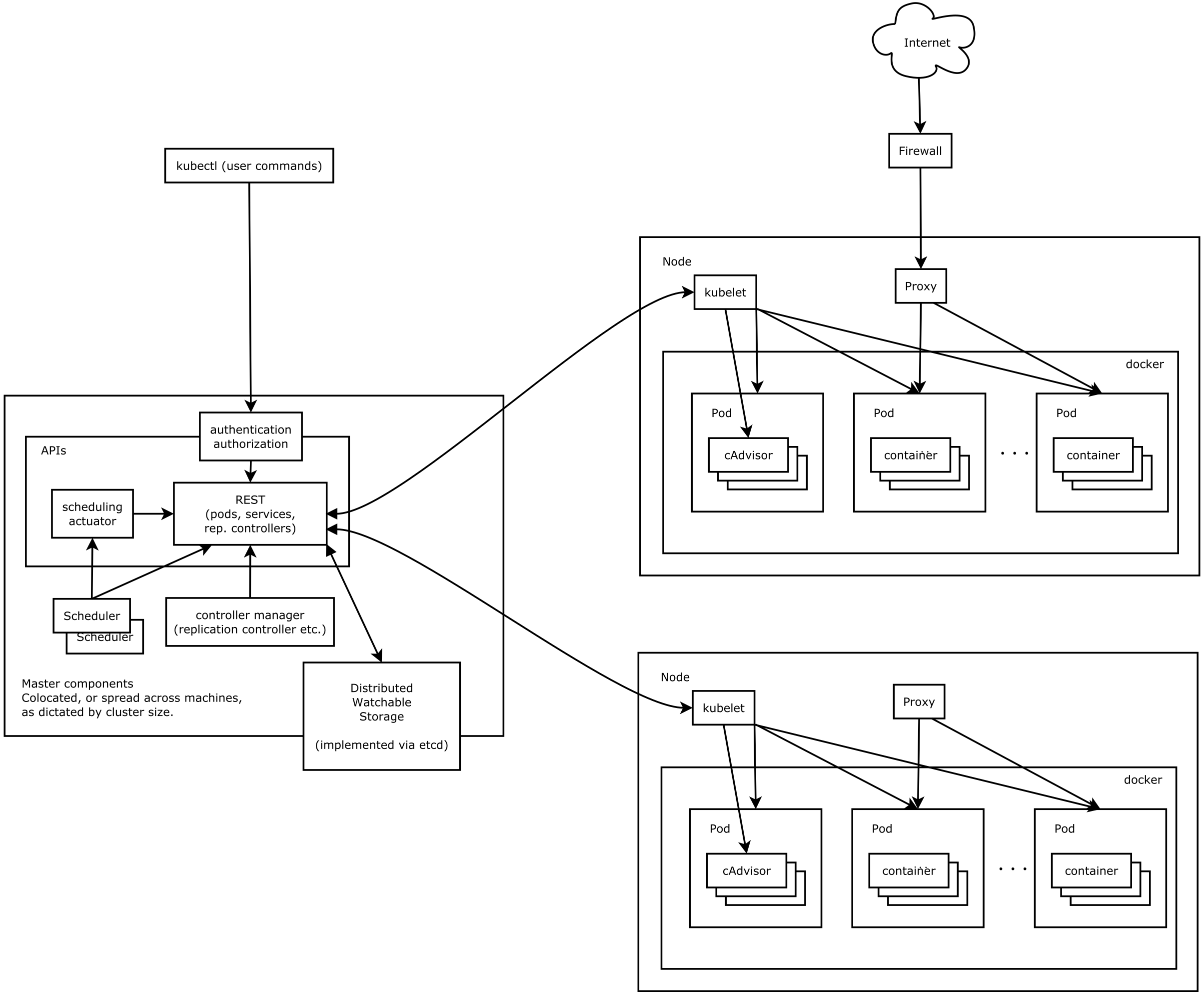
Kubernetes 是 Google 开源的容器编排管理系统,是 Google 多年大规模容器管理技术 Borg 的开源版本,主要功能有:
基于容器的应用部署、维护和滚动升级
负载均衡和服务发现
跨机器和跨地区的集群调度
自动伸缩
无状态服务和有状态服务
插件机制保证扩展性
下面简要介绍几种 Kubernetes 中的几种常用的 Kubernetes 核心组件和资源对象,便于下文的理解。
首先是几个本文中要多次提及的 Kubernetes 基础组件:
Controller Manager:
Kubernetes 中的大多资源对象都有对应的控制器(Controller),他们合在一起组成了 kube-controller-manager。
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。生活中最典型的控制回路的例子:空调。比如我们设置了温度,相当于告诉了空调我们的期望状态,房间的实际温度是当前状态,通过对设备的各种控制,空调使温度接近于我们的期望。控制器通过控制回路将 Kubernetes 内的资源调整为声明式 API 对象期望的状态。
ETCD:
是 CoreOS 基于 Raft 开发的分布式 Key-Value 存储,保存了整个 Kubernetes 集群的状态,可用于服务发现和一致性保证(比如选主)。
Etcd 被部署为一个集群,几个节点的通信由 Raft 算法处理。在生产环境中,集群包含奇数个节点,并且至少需要三个,通常部署在 Kubernetes Master 上。
API Server:
提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制。
它是其他模块之间的数据交互和通信的枢纽(其他模块通过 API Server 查询或修改数据,只有 API Server 才直接操作 ETCD)。
Kubelet:
负责维护容器的生命周期,同时也负责 持久卷(CVI)和网络(CNI)的 管理。
每个 Node 节点上都运行一个 Kubelet 服务进程,默认监听 10250 端口,接收并执行 Master 发来的指令,管理 Pod 及 Pod 中的容器。
下面介绍一些常用的资源对象:
Pod:Pod 是一组紧密关联的容器集合,是 Kubernetes 调度的基本单位。多个容器在一个 Pod 中共享网络和文件系统,Pod 和容器的概念和关系有些类似于主机和进程。
Node:Node 是 Pod 真正运行的主机,可以是物理机,也可以是虚拟机,Node 上需要运行着 container runtime(比如 Docker)、kubelet 和 kube-proxy 服务。
StatefulSet:为了解决有状态服务的问题(对应 Deployments 和 ReplicaSets 是为无状 态服务而设计),通过稳定的存储、网络标识、Pod 编序等功能来支持有状态应用。
Deployment:是一种更高阶资源,用千部署应用程序并以声明的方式升级应用,替代和 ReplicationController 来更方便的管理应用。
ConfigMap:用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置 文件,在 Kubernetes 的使用中我们通过 ConfigMap 实现应用和配置分离。
Service:Kubernetes 中用于容器的服务发现和负载均衡的资源对象,分为 ClusterIP(生成 Kubernetes 集群内的虚拟 IP 作为入口)、NodePort(在 ClusterIP 基础上在每台机器上绑定一个端口暴露,使得能通过机器 IP 加该端口访问)、LoadBalancer 等。
整体 Kubernetes 架构如下图所示:
从传统主机到 Kubernetes,从无状态到有状态
在介绍 Kubernetes Operator 之前,我们先来分析一下传统的有状态应用部署方式所存在的问题。
以前当开发者想要在物理机或云主机上部署 Redis、Kafka 等有状态应用,并且对于这些应用的集群有一定程度的运维控制能力时,往往需要编写一套复杂的管理脚本、或者开发一个拥有诸多依赖的 Web 管控服务。站在普通使用者的角度,他们不得不为此学习与本身业务开发无关的运维知识。
如果是以脚本和运维文档的方式沉淀,缺乏标准化的管理会使得运维的学习成本和使用门槛随着使用过程中的修改而急速升高;而使用管控服务,则需要引入更多的底层依赖去满足管控服务与主机侧的交互的虚拟化和管理设施,云计算厂商许多都使用了 OpenStack 作为基础设施管理平台,严格来说,OpenStack 和 Kubernetes 不属于同一层面的框架,前者更多是属于 IaaS 层,更多是面向基础设施做虚拟化,Kubernetes 则更偏向上层的应用容器化编排管理。在实际使用中,我们认为自行组织 OpenStack 对于小规模用户私有云的使用需求,有些过于沉重了。
于是我们将目光投向对基础设施关注更少、自动化程度更高的 Kubernetes。我们都知道 Kubernetes 在无状态应用部署管理,尤其是微服务领域,已经大放异彩。例如管理一个无状态的 Web 服务,我们可以使用 Kubernetes 的 Deployment 部署多副本并且进行弹性伸缩和滚动升级,然后使用 Sevice 进行负载均衡,依靠 Kubernetes 原生的资源对象基本上可以覆盖无状态服务的整个生命周期管理。
然而,对于 Redis、Kafka 这类“有状态”的应用,Kubernetes 似乎并没有准备好接纳它们。首先我们总结一下有状态应用的两个重要的特点:
对外部存储或网络有依赖,比如 Kafka、TiDB 每个副本都需要稳定的存储卷。
实例之间有拓扑关系,比如 Redis Cluster 中存在主从关系和数据路由分布。
这就给 Kubernetes 带来了挑战,如果仍使用 Deployment 和 ReplicaSet 这些对象,Pod 在故障时,对于 Redis Cluster 无法只是简单地重启 Pod 就能恢复到健康的集群状态,同理 Kafka 的 Pod 也会“忘记”自己所使用的存储卷。
Kubernetes 推出了 StatefulSet 这一资源对象旨在解决有状态应用的管理问题,允许在 StatefulSet 中配置持久卷(PersistentVolume,简称 PV)、稳定的网络标识,对其内部的 Pod 进行编号排序等。但是对于 Redis Cluster 这种拥有自治能力的集群,StatefulSet 也显得不够灵活而且会与其自治能力有冲突。
Redis 也想要声明式管理
Kubernetes 的自动化哲学有两个核心概念:声明式 API 和控制器(controller)模式。比如我们声明一个三副本的 Deployment 提交给 API Server,Kubernetes 中负责 Deployment 的 controller 就会监视(Watch)它的变化,发现该 Deployment 的 Pod 数为零,对其进行调谐(Reconcile),创建三个 Pod,使它达到我们所声明的状态。
这引发了我们的思考:是否可以将 Redis 视作像 Deployment 一样的资源对象进行声明式的管理,同样拥有一个 controller 对它进行调谐呢?
这是一个合理且强烈的需求,即资源对象和 controller 都是由我们自定义,由我们自行编写资源的生命周期和拓扑关系的管理。于是 Operator 应运而生,可以将其简单的理解为:
Operator = CRD(Custom Resources Definition)+ Custom Controller如今 Operator 在社区中已经非常火热,但我们在最初设计做调研时,发现社区的 Redis Operator 实现上虽简洁,但运维能力和我们作为云计算服务商所强调的风险掌控、兜底能力不足,于是我们 NCR(Netease Cloud Redis)团队借鉴社区的经验开发了自己的 Redis Operator,下面针对 Redis Cluster 模式的管理进行解读,总体架构如下图所示:
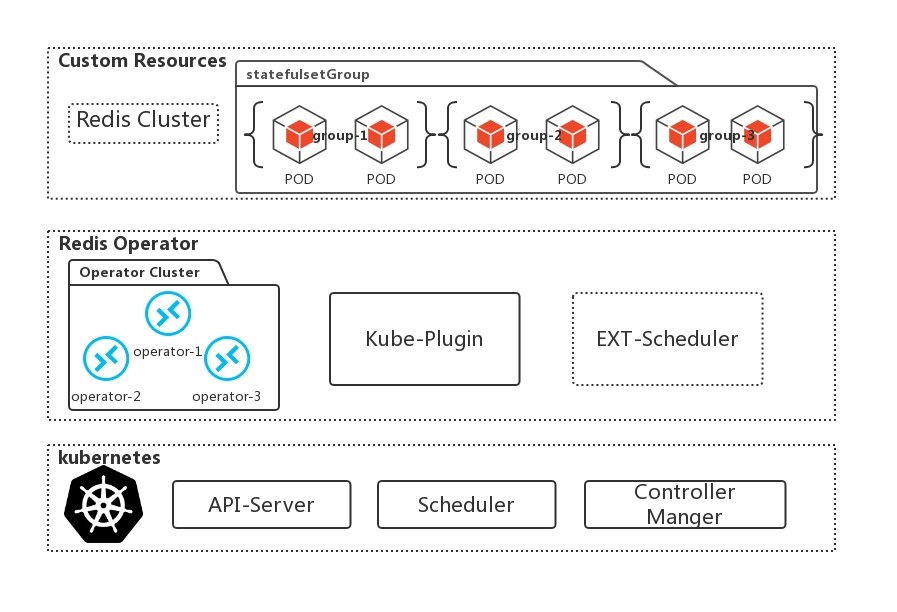
Redis Operator 自身采用 Deployment 进行三副本部署,通过 ETCD 选主。Redis Cluster 每个分片内的两个 Pod 上的 Redis 实例为一主一从,每个分片由一个 StatefulSet 管理;Pod 的调度策略由 Kubernetes 原生调度器和网易轻舟 Kubernetes 提供的扩展调度器共同保障,对于 StatefulSet、Pod 等原生资源对象的管理仍使用原生 API。
开始使用 Redis Operator,首先我们需要提交一个属于 Redis 的资源定义(CRD),定义一个 Redis 集群所必要的规格描述(Specification),之后用户便可以提交 CR(通常是以 yaml 文件的形式),并在 CR 的 Spec 中填写自己需要的规格信息后提交,剩下的工作,无论是创建、弹性扩缩容、故障处理,统统交给 Redis Operator 自动化调谐。下面是一个典型的 CR 实例:
apiVersion: ncr.netease.com/v1alpha1kind: NcrCluster # 资源类型,在CRD中所定义metadata: name: cluster-redis # CR名称 namespace: ns # CR所在的namespacespec: availableZones: # 可用区列表,支持单、多AZ - azName: az1 configFile: ncr-cluster-configmap # 默认的配置参数模板 master: 3 # 分片数 port: 6379 # 端口号 version: redis:4.0.14 # Redis引擎版本 resourceReqs: # K8s标准资源规格描述 requests: cpu: 1 memory: 2Gi limits: cpu: 2 memory: 4Gi下面简要分析一个 Redis Cluster 的 CR 提交后的 Operator 主干工作流程:
Redis Cluster 对应的 Informer 感知到 CR 的 Add 事件。
对该 CR 的 Spec 进行校验,包括是否符合 CRD 中的校验规则以及 Operator 内置的校验逻辑。
校验通过后,开始对该集群进行调谐(Reconcile),感知到 CR 的 Status 为空判断为新创建的 Redis 集群,进入创建流程。
根据默认 Redis 配置模板生成引擎配置,生成一个该 CR 专用的引擎参数 ConfigMap 和一个调度 ConfigMap,我们通过在调度层面的策略针对单、多机房做了高可用保障。
创建 NodePortService 用于服务发现访问。
为 Redis Cluster 每个分片创建 StatefulSet 并将 CR 中的资源规格传入,作为最终 Pod 的资源规格。
待所有 StatefulSet 的 Pod 启动成功后,在每个 Pod 上运行 Redis Server 进程,并进行 Redis Cluster 的组建流程,如 cluster meet 和 add slots 等。
完成后将 CR 的状态更新为 Online,表明已完成创建,之后根据 Infomer 的机制,每 30s 会收到到 Update 事件,轮询式的进行 Reconcile。
Operator,拥有运维知识的专家
下图为 Redis Operator 的工作流程图,实际上 Operator 就是我们对 Kubernetes API 进行了扩展和自定义,整体的工作流程与原生内置的 controller 是一致的.
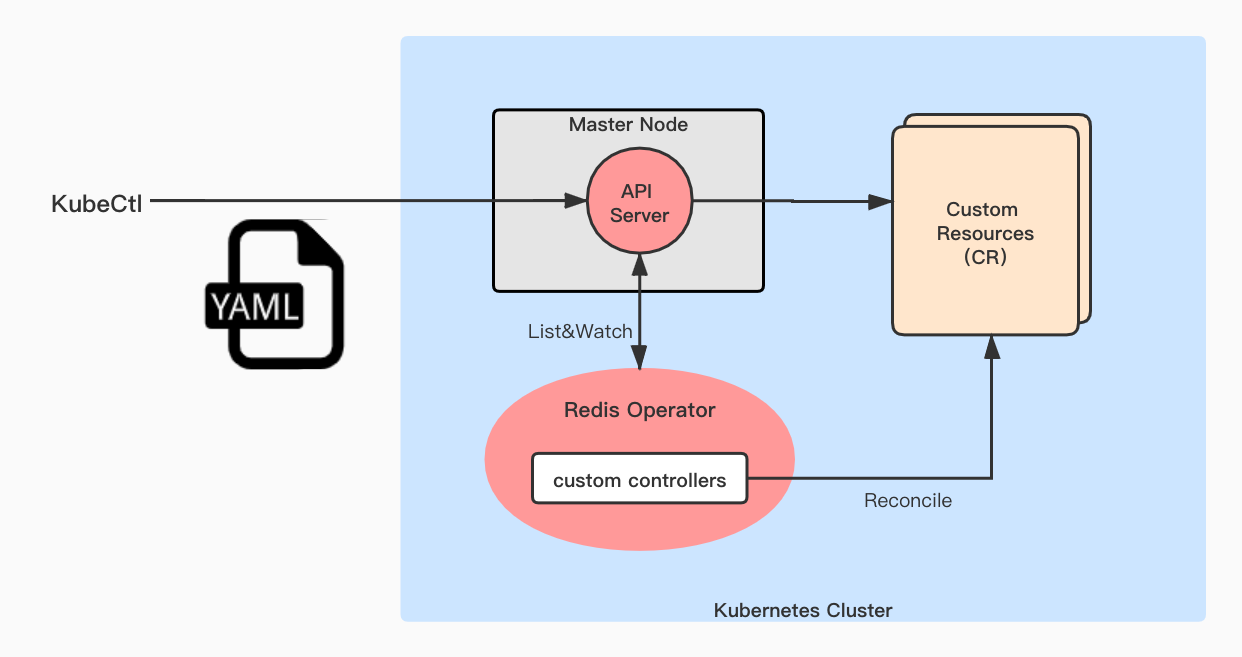
那么这种设计理念有什么好处呢?借用 Operator Framework 官网的一句话:
The goal of an Operator is to put operational knowledge into software.
即“Operator 旨在将领域性的运维知识编写成代码融入其中”。这个理念会影响我们对 Redis Operator 的设计与开发。
列举一个场景说明,假如我们有在物理机上手工部署的 Redis Cluster 集群其中一个 Master 实例故障,并发生了 Failover,此时该实例处于宕机状态,如果是人工恢复我们需要做的工作大致为:
判断分片是否正常工作,即分片内另一个节点是否已经接替成为 Master。
准备将该实例作为 Slave 重启,做操作的预检查。比如 Master 的流量很高时,需要更大的复制缓冲区,需要检查 Master 的内存空闲情况,或者 CPU 占用超过一定阈值时不做操作,待流量低峰时进行重启和复制。
重启实例,加入集群,并且复制指定 Master 实例,持续检查复制状态直到稳定。
上述每一步操作判断都涵盖了我们的 Redis 运维知识,根绝 Operator 的理念,我们应该将这些知识编写成代码。通过明确的指标去做判断,比如判断 QPS 低于 5000、CPU 使用低于 60%,Master 内存空闲大于 2GB 时允许自动重建修复,将故障自动恢复或调谐的能力交给 Operator,极大地提高了自动化运维的程度,可以称 Redis Operator 为运行在 Kubernetes 上,拥有 Redis 运维知识和判断能力的“运维专家”。
优势总结和落地情况
最后总结一下 Redis 采用 Operator 方案做容器化的优势:
降低运维成本,支持对更大规模 Redis 集群的管理。
容器部署相对于传统主机部署在资源方面更加有弹性。
调度控制实现反亲和更加简单,借助 Kubernetes 本身的调度器和 Taint、Toleration 等机制。
基于 Kubernetes 的方案对基础设施耦合低,用户可以根据实际规模选择用物理机或云服务器部署。
目前网易轻舟自研的 Redis Operator 提供的功能有:
两种模式的 Redis:Redis Cluster 和 Redis 主从版(Sentinel 管理)
单、多 AZ 高可用部署支持
集群创建、删除
集群在线水平、垂直扩缩容,热配置更新
实例重启、重建的运维功能
Prometheus 监控和报警功能
RDB 数据冷备与恢复
时至今日,Redis Operator 已经在网易云音乐线上环境自 2019 年底稳定运行至今,网易传媒、网易严选也在逐渐扩大线上的使用规模,得益于自动化运维的高效、资源成本的优化,相信 Operator 将成为成规模的有状态分布式应用容器化的标准。




