WildFly,前身是 JBoss AS,从 V8 开始为区别于 JBoss EAP,更名为 WildFly。HornetQ 是 JBoss 开发的一个独立的消息中间件,被整合进 WildFly 作为消息子系统。
HornetQ 完全支持 JMS,HornetQ 不但支持 JMS1.1 API 同时也定义属于自己的消息 API(如下图中的 Core Client),以最大限度地提升 HornetQ 的性能和灵活性。
图 1 客户程序 HornetQ 的两种交互模式
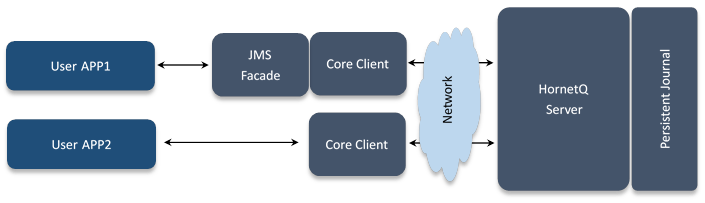
关于 Core Client 的 API 介绍请参见: http://docs.jboss.org/hornetq/2.3.0.CR2/docs/api/hornetq-client/
1.1.1. 消息类型
HornetQ 与 JMS 保持一致支持两种消息类型:Point-to-Point 和 Publish/Subscribe。
-
Point-to-Point
图 2 消息类型之 Point-to-Point

-
Publish/Subscribe 图 3 消息类型之 Publish/Subscribe
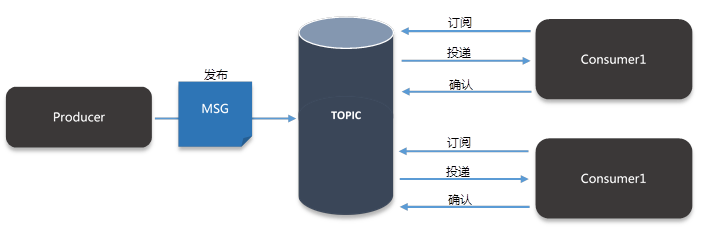
1.1.2. HornetQ 的专用术语说明
为了能够更好地使用 WildFly 的消息子系统,有必要对其专用术语做一下说明。其中有两组概念比较重要:
- Acceptors and Connectors
- Invm and Netty
1.1.2.1. Acceptors and Connectors
-
Acceptor
指定 HornetQ Server 接受什么类型的连接(Connection)
-
Connector
为客户端指定连接 HornetQ Server 的方式
相关配置定义在 standalone 以及 domain 的 profile 中,以下列举片段供参考。
<connectors>
<netty-connector name="netty" socket-binding="messaging"/>
<netty-connector name="netty-throughput" socket-binding="messaging-throughput">
<param key="batch-delay" value="50"/>
</netty-connector>
<servlet-connector name="servlet" socket-binding="http" host="default-host"/>
<in-vm-connector name="in-vm" server-id="0"/>
</connectors>
<acceptors>
<netty-acceptor name="netty" socket-binding="messaging"/>
<netty-acceptor name="netty-throughput" socket-binding="messaging-throughput">
<param key="batch-delay" value="50"/>
<param key="direct-deliver" value="false"/>
</netty-acceptor>
<in-vm-acceptor name="in-vm" server-id="0"/>
</acceptors>
1.1.2.2. Invm and Netty
Acceptor 和 Connector 是个相对的概念,因此定义时需要成对定义。而 Invm 和 Netty 就是用来定义 Client 和 HornetQ Server 是否在同一个 JVM 中。Invm 标识 Client 和 HornetQ Server 在同一个 JVM 中;Netty 标识 Client 和 HornetQ Server 在不同的 JVM 中
1.1.3. 消息持久化
WildFly 中的消息是默认做持久化并持久化到文件中 (Persistent Journal, 请参见图 15 客户程序 HornetQ 的两种交互模式)。文件操作有以下两种方式:
-
Java Non-blocking IO (NIO)
利用 Java 标准的 NIO API 操作文件以获取更好的性能,需要 Java SE 6 及更新版本。
-
Linux Asynchronous IO (AIO)
使用 Linux 的本地异步 IO 库进行操作,对 Linux(内核 2.6 及以上)系统强依赖。该方式性能优于 Java NIO。
WildFly 默认使用 AIO 进行消息持久操作,以获取最佳性能 ,如果在不具备 Linux AIO 的条件下,会自动切换到 Java NIO 方式进行消息持久化。
图 4 消息持久化场景模式
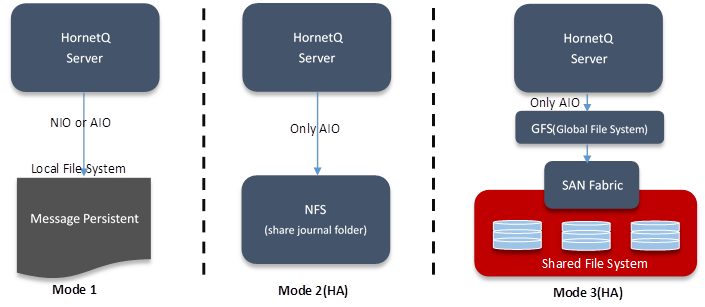
从上图中可以看出,WildFly 的消息子系统中消息持久化除了支持本地文件系统操作,也支持 NFS,基于 SAN 的 GFS V2 共享文件系统的操作。
[注意事项]
(1) 在使用模式 2 或者 3 时,Linux AIO 为唯一文件操作方式。
(2) 如果使用模式 1,即每个 HornetQ 服务器都将消息持久化到所在主机的本地文件系统,在做 HornetQ 服务器的 HA 特性 (Failoerver) 时,需要做消息复制(将消息日志由主 HornetQ 服务器复制到从 HornetQ 服务器上)。
【笔者观点】
- HornetQ 的消息持久化方式比较单一,没有灵活的持久化方式(比如数据库持久化)供用户选择或定制。好在提供了通过 NFS 或者 GFS V2 on SAN 进行消息持久化共享的方式,从而避免了在集群情况下由于做消息复制而造成的性能损耗。
- 在消息中间件负载要求过高的场景下,如果在消息持久层 (文件系统) 与 HornetQ 集群之间加入缓存集群 (Infinispan) 做消息共享,可以提供更好的 HA 特性。
1.1.4. 消息复制
消息复制是高可用性的前提功能,在集群环境中通过消息复制保持主 (Master) 节点和从 (Slave) 节点的状态对等(消息一致),当主节点失效后,从节点能够立刻替代主节点保证客户应用程序的运行不受影响。在消息持久化中讲到了消息持久化的3 种模式,集群中的各节点在模式2(NFS) 和3(GFS) 的场景下可以通过共享文件系统保证消息一致;在模式1 的场景下,要保证主从节点间的消息一致需要通过消息复制来实现。
图 5 消息复制
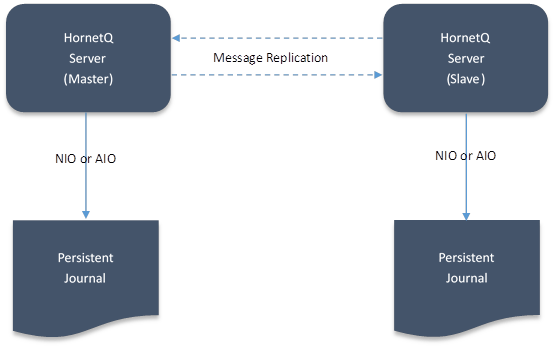
[注意事项]
在某节点被标识为从节点,并启动后,主节点上已经有消息 (persistent journal) 存在的情况下,从节点首先会从主节点上同步已存在的数据,在同步完成之前无法提供容错 功能。
1.1.5. 消息去重
试想以下两种消息处理场景:
-
场景 1
消息由消息发送者 (message sender) 到消息目标服务器 (message target),目标服务器或者网络在消息发送之后,目标服务器接受到消息之前发生故障。
-
场景 2
消息由消息发送者 (message sender) 到消息目标服务器 (message target),目标服务器或者网络在消息到达目标服务器,并且由目标服务器对消息处理完成之后,目标服务器返回响应之前发生故障。
消息发送者没有办法对以上两种场景进行辨别,统一做消息重新发送。对于场景 2 而言,同样的消息消费了 2 次。这对于一些订购系统 (比如网上购物) 而言,如果不做消息去重,在场景 2 中,对于同一件物品发生 2 次订购,对于消费者而言是不可接受的。
HornetQ 提供了消息去重的机制,实现思路如下图所示:
图 6 消息去重原理
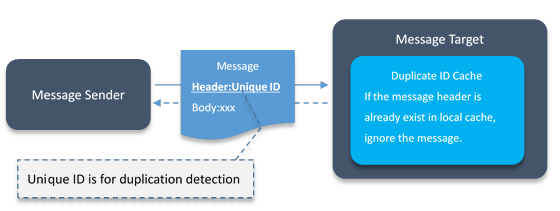
从上图可以看出,HornetQ 的消息去重实现原理很简单:
- 消息发送者为每一条消息附加带唯一值(官方建议用 UUID)的消息头;
- 目标服务器在接收消息之后,处理消息之前,先从本地缓存 (Duplicate ID Cahce) 中查找该消息 ID 是否已经存在 ;
- 如果消息头在本地缓存中已经存在则忽略该消息;如果不存在则处理该消息;
- 目标服务器处理完消息后在本地缓存中缓存该消息的消息头,以供去重检测用。
【笔者观点】
上述的处理逻辑在一定程度上可以避免消息去重,在极端情况下(目标服务器缓存也崩溃的时候)也难以避免消息被重复处理的情况。如果要考虑到极端情况的处理,就要牺牲一定的性能特别是分布式场景下。在实际业务场景中,比如订单系统与积分系统,支付系统,物流系统等系统间消息投递的场景中,出于性能考虑,一般不考虑如此极端的场景。淘宝 / 阿里的消息中间件(Notify 与 MetaQ)都没有为极端场景做特别设计。
鉴于目前分布式缓存大行其道,比如 Teracotta 的 BigMemory,Oracle Coherence 等等,可以采用类似于统一 Session 管理的方案,对 Duplicate ID 也做统一管理,这样集群中无论哪一个节点崩溃都可以避免消息重复消费的情况。
1.1.6. 严格消息顺序保证
为了说明消息的顺序消费的重要性,下图中勾画了一个网上购物的场景。
图 7 严格消息顺序消费场景
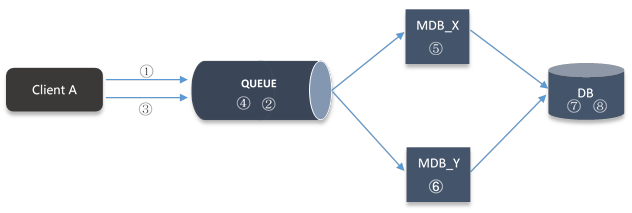
① A 客户订购一台 iPad 4
② 订购消息加入消息队列
③ A 客户取消①中订购的 iPad4
④ 取消订购消息加入消息队列
⑤ 从队列中消费订购消息
⑥ 从队列中消费取消订购消息
⑦ 往数据库中写入订购消息
⑧ 从数据库中删除订购消息
如果⑦和⑧的处理顺序颠倒,将导致客户的订购没有取消成功。
 如何保证消息消费的顺序呢?
如何保证消息消费的顺序呢?
JMS 规范(截至 JMS2.0)仅仅对“一个生产者,一个 QUEUE,一个消费者”的场景做了“消息的发送顺序必须与消费顺序严格一致”的规定,但对于分布式环境中,没有对消息发送与接受的顺序一致做强制要求。因此严格顺序保证依赖各消息中间件提供商的具体实现。
IBM 的 WebSphere MQ 中的消息分组与 Oracle 的 WebLogic JMS 的 Message Unit-of-Order 都可以解决上述场景中的问题。HornetQ 也提供了解决方案:Message Grouping。
1.1.6.1. Message Grouping
Message Grouping 通过将同一业务类型的消息分为一组,确保该组中的所有消息被同一个消费者消费(即使在集群环境中),从而确保消息能够被顺序消费。通过 HornetQ 的 Message Grouping 图 21 的消息消费路由将变成(如下图所示)。
图 8 采用 Message Grouping 后的消息顺序消费

【笔者观点】
HornetQ 的 Message Grouping 方案有以下前提:
- Queue 中消息顺序是正确的。即需要消息发送端意识到消息的先后顺序
- 消费端不可以使用多线程去处理消息。
另外需要注意的是,集群环境中由于负载均衡消息可能分布在不同的 Queue 上面,这种情况下 HornetQ也难以保证消息消费顺序的正确性。当然可以通过修改负载均衡算法,借助类似于 sticky session 的技术将来自于同一 session 的消息,都发往同一个 HornetQ 服务器上的同一个 Destination。
作者介绍
吴杰(新浪微博 @WildJay ),南京 JUG 联合创始人;05 年始在富士通南大软件技术有限公司,从事富士通中间件产品研发 8 年,现就职于苏宁云商电子商务总部信息中心负责中间件相关事宜。
感谢方腾飞对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




