
强化学习可以用于训练一种策略,使其能够在试错的情况下来完成任务,但强化学习面临的最大挑战就是,如何在具有艰难探索挑战的环境中从头学习策略。比如,考虑到 adroit manipulation 套件中的 door-binary-v0 环境所描述的设置,其中强化学习智能体必须在三维空间中控制一只手来打开放在它前面的门。

由于智能体没有收到任何中间奖励,它无法衡量自己离完成任务有多远,所以只能在空间里随机探索,直至门被打开为止。鉴于这项任务所需的时间以及对其进行精准的控制,这种可能性微乎其微。
对于这样的任务,我们可以通过使用先验信息来规避对状态空间的随机探索。这种先验信息有助于智能体了解环境的哪些状态是好的,应该进一步探索。
我们可以利用离线数据(即由人类演示者、脚本策略或其他强化学习智能体收集的数据),对策略进行训练,并将之用于初始化新的强化学习策略。如果采用神经网络来表达策略,则需要将预训练好的神经网络复制到新的强化学习策略中。这一过程使得新的强化学习策略看起来就像是预训练好的。但是,用这种幼稚的方式来进行新的强化学习通常是行不通的,尤其是基于值的强化学习方法,如下所示。
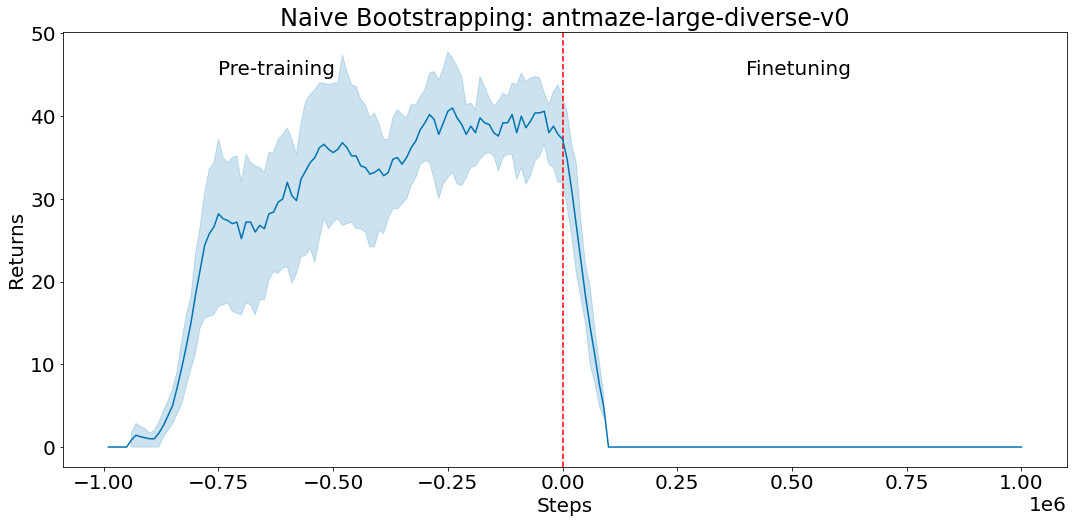
用离线数据在 antmaze-large-diverse-v0 D4RL 环境中对一种策略进行预训练(负向步骤对应预训练)。然后,我们使用该策略来初始化 actor-crittic 的微调(从第 0 步开始的正向步骤),以该预训练的策略作为初始 actor。crittic 是随机初始化的。由于未经训练的 critic 提供了一个糟糕的学习信号,并导致良好的初始策略被遗忘,所以 actor 的性能会立即下降,并且不会恢复。
有鉴于此,我们在“跳跃式强化学习”(Jump-Start Reinforcement Learning,JSRL)中,提出了一种可以利用任意一种与现存在的策略对任意一种强化学习算法进行初始化的元算法。
JSRL 在学习任务时采用了两种策略:一种是指导策略,另一种是探索策略。探索策略是一种强化学习策略,通过智能体从环境中收集的新经验进行在线训练,而指导策略是一种预先存在的任何形式的策略,在在线训练中不被更新。在这项研究中,我们关注的是指导策略从演示中学习的情景,但也可以使用许多其他类型的指导策略。JSRL 通过滚动指导策略创建了一个学习课程,然后由自我改进的探索策略跟进,其结果是与竞争性的 IL+RL 方法相比较或改进的性能。
JSRL 方法
指导策略可以采取任何形式:它可以是一种脚本化的策略,一种用于强化学习训练的策略,甚至是一个真人演示者。唯一的要求是,指导策略要合理(也就是优于随机探索),而且可以根据对环境的观察来选择行动。理想情况下,指导策略可以在环境中达到较差或中等的性能,但不能通过额外的微调来进一步改善自己。然后,JSRL 允许我们利用这个指导策略的进展,从而提到它的性能。
在训练开始时,我们将指导策略推出一个固定的步骤,使智能体更接近目标状态。然后,探索策略接手,继续在环境中行动以达到这些目标。随着探索策略性能的提高,我们逐渐减少指导策略的步骤,直到探索策略完全接管。这个过程为探索策略创建了一个起始状态的课程,这样在每个课程阶段,它只需要学习达到之前课程阶段的初始状态。

这个任务是让机械臂拿起蓝色木块。指导策略可以将机械臂移动到木块上,但不能将其拾起。它控制智能体,直到它抓住木块,然后由探索策略接管,最终学会拿起木块。随着探索策略的改进,指导策略对智能体的控制越来越少。
与 IL+RL 基线的比较
由于 JSRL 可以使用先前的策略来初始化强化学习,一个自然的比较是模仿和强化学习(IL+RL)方法,该方法在离线数据集上进行训练,然后用新的在线经验对预训练的策略进行微调。我们展示了 JSRL 在 D4RL 基准任务上与具有竞争力的 IL+RL 方法的比较情况。这些任务包括模拟的机器人控制环境,以及来自人类演示者的离线数据集、计划者和其他学到的策略。在 D4RL 任务中,我们重点关注困难的蚂蚁迷宫和 adroit dexterous manipulation 环境。

对于每个实验,我们在一个离线数据集上进行训练,然后运行在线微调。我们与专门为每个环境设计的算法进行比较,这些算法包括 AWAC、IQL、CQL 和行为克隆。虽然 JSRL 可以与任何初始指导策略或微调算法结合使用,但我们使用我们最强大的基线——IQL,作为预训练的指导和微调。完整的 D4RL 数据集包括每个蚂蚁迷宫任务的一百万个离线转换。每个转换是一个格式序列(S, A, R, S'),它指定了智能体开始时的状态(S),智能体采取的行动(A),智能体收到的奖励(R),以及智能体在采取行动 A 后结束的状态(S')。
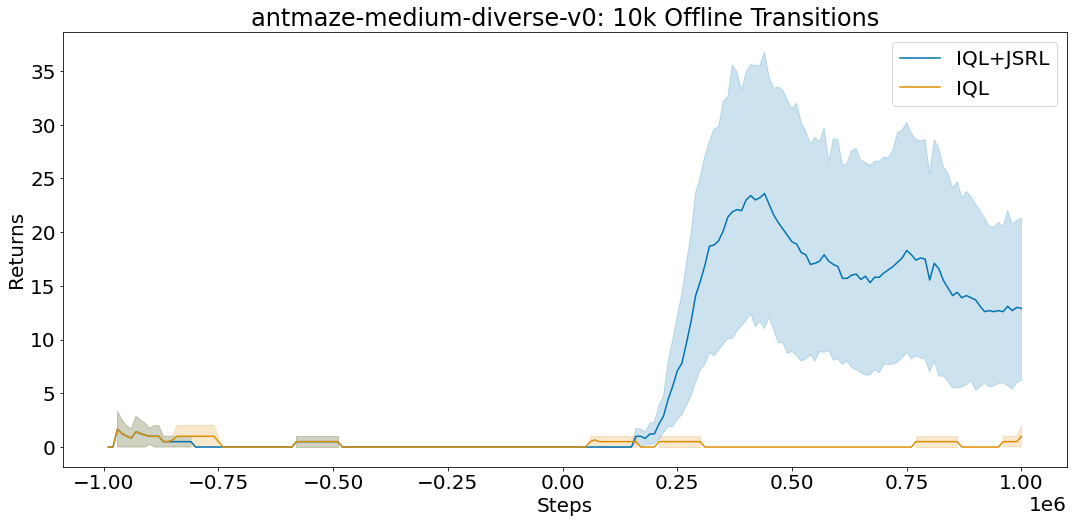
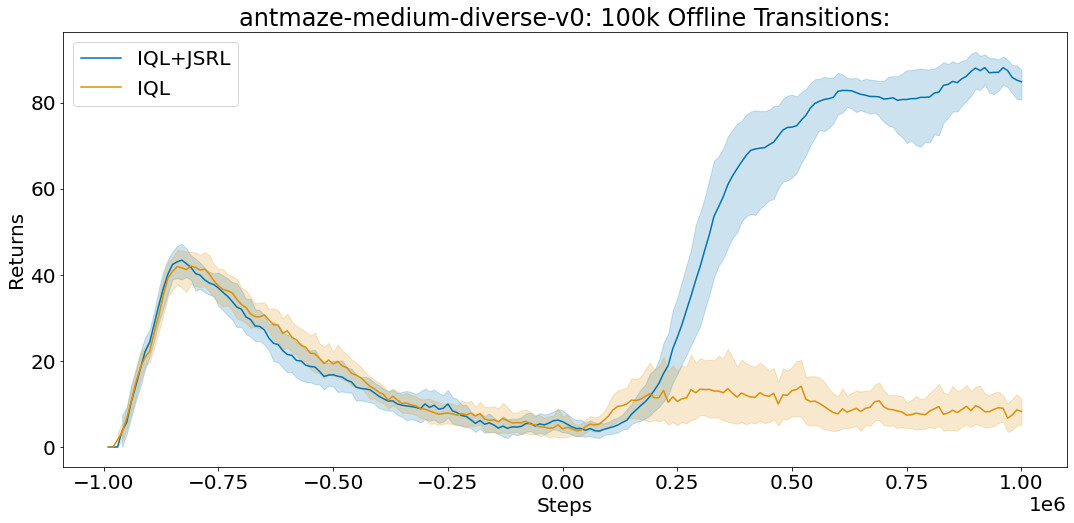
在 D4RL 基准套件的 antmaze-medium-diverse-v0 环境中的平均得分(最大值=100)。即使在有限的离线转换的情况下,JSRL 也可以改进。
基于视觉的机器人任务
由于维度的限制,在复杂的任务中使用离线数据特别困难,比如基于视觉的机器人操纵。连续控制动作空间和基于像素的状态空间的高维度,给 IL+RL 方法带来了学习良好策略所需的数据量方面的扩展挑战。为了研究 JSRL 如何适应这种环境,我们重点研究了两个困难的仿生机器人操纵任务:无差别抓取(即,举起任何物体)和实例抓取(即,举起特定的目标物体)。

一个仿生机械臂被放置在一张有各种类别物体的桌子前。当机械臂举起任何物体时,对于无差别的抓取任务,会给予稀疏的奖励。对于实例抓取任务,只有在抓取特定的目标物体时,才会给予稀疏的奖励。
我们将 JSRL 与能够扩展到复杂的基于视觉的机器人环境的方法进行比较,如 QT-Opt 和 AW-Opt。每种方法都可以获得相同的成功演示的离线数据集,并被允许运行多达 10 万步的在线微调。
在这些实验中,我们使用行为克隆作为指导策略,并将 JSRL 与 QT-Opt 相结合进行微调。QT-Opt+JSRL 的组合比其他所有方法改进得更快,同时获得了最高的成功率。
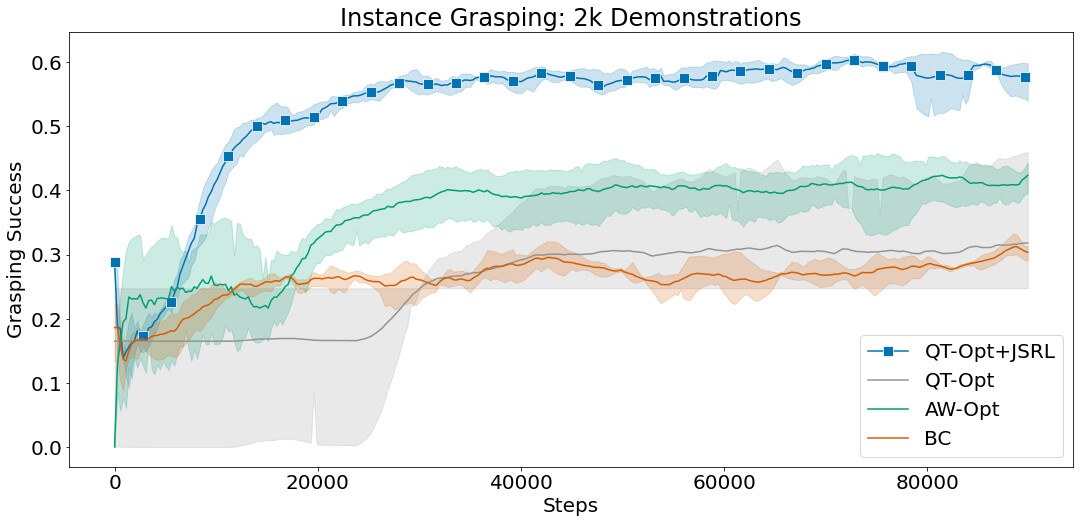
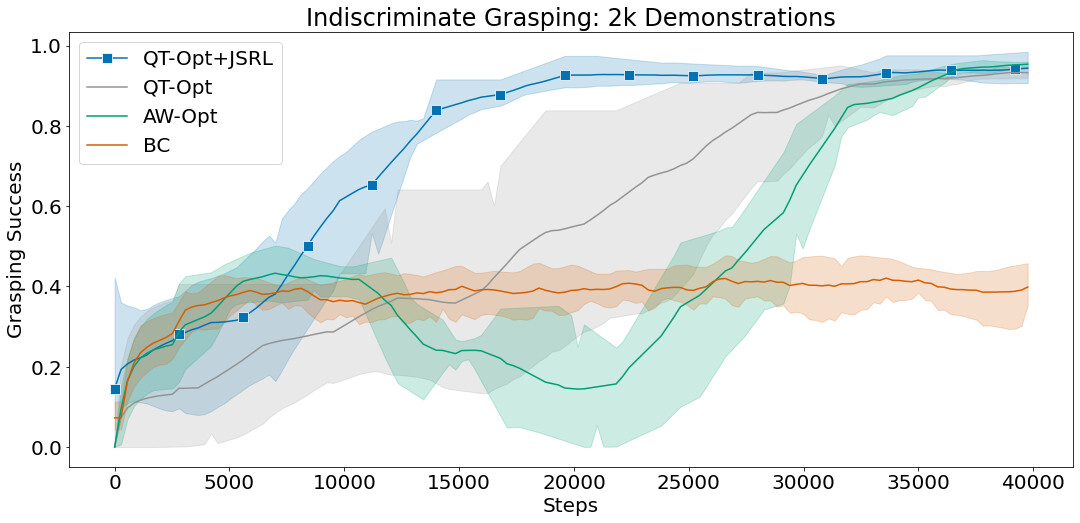
使用 2 千次成功演示,无差别和实例抓取环境的平均抓取成功率。
结语
我们提出了 JSRL,它是一种利用任何形式的先验策略来改进初始化强化学习任务的探索的方法。我们的算法通过在预先存在的指导策略中滚动,创建了一个学习课程,然后由自我改进的探索策略跟进。探索策略的工作被大大简化,因为它从更接近目标的状态开始探索。随着探索策略的改进,指导策略的影响也随之减弱,从而形成一个完全有能力的强化学习策略。在未来,我们计划将 JSRL 应用于 Sim2Real 等问题,并探索我们如何利用多种指导策略来训练强化学习智能体。
原文链接:
https://ai.googleblog.com/2022/04/efficiently-initializing-reinforcement.html




