
精准营销排重系统主要为集团八大产业所有会员的营销活动的推广进行排重服务,根据不同的规则进行实时排重,增加用户体验,定位为精准营销核心平台之一。在每次集团双十一等大促活动中,各个产业活动所包含客群的促销信息会涉及到大量重叠会员信息,如果不通过排重系统进行消息过滤处理,客户接受到大量促销信息,对客户产生骚扰而引起客户反感,降低体验,进而会产生促销反面效果,如果所有符合条件的会员都发送多个促销信息也会增加运营成本。
客户营销主要应用场景包括:在线营销、离线营销、各终端(红孩子、苏宁小店、苏宁易购、PPTV、体育等)推送、各渠道(PUSH、短信、邮件等)触达等。以上所有相关场景的数据交叉、实时排重的处理,将排重处理后的营销会员数据发送到待发送系统达到营销活动的推送。
排重服务定位
精准营销排重服务属于营销执行平台核心组件,作用于营销活动收尾环节,对营销执行平台中的营销事件、营销标签、用户特征计算符合条件的用户进行排重服务,将排重后的数据通过不同的渠道推送到各个终端中;通过排重服务能够精准的对会员进行活动营销,减少对用户的多次骚扰,增加用户体验;通过排重服务能够过滤掉黄牛会员信息,减少营销成本。
排重服务分为已立项排重、已执行排重:
-
已立项排重:客户群和预计发送记录表进行排重;
-
已执行排重:客户群和历史发送记录表进行排重。
排重服务对不同渠道的会员进行历史排重,对同渠道的会员进行立项排重,对所有业务场景进行数据的交叉、实时排重等处理达到各种业务场景、各渠道的精准推送。
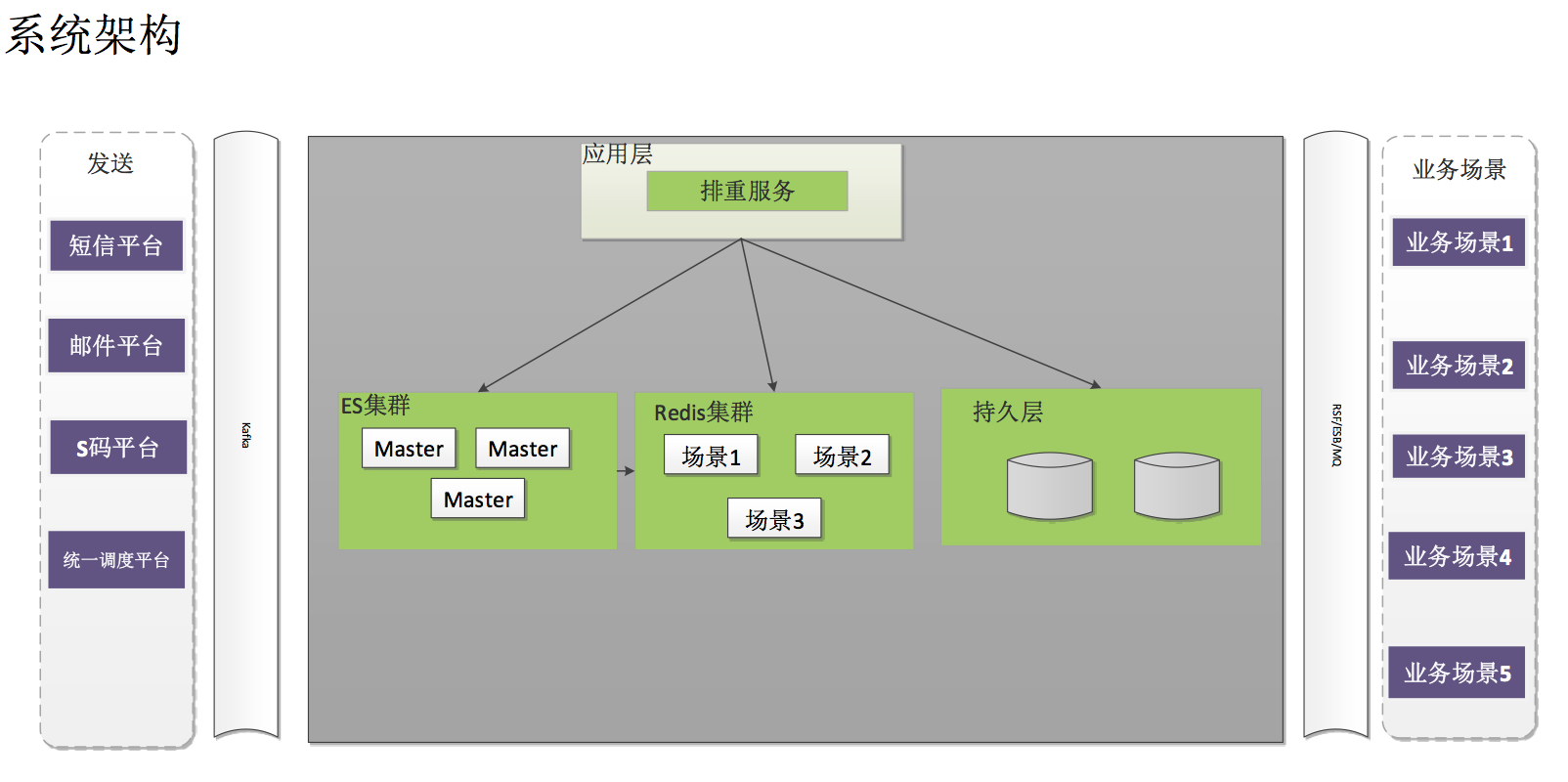
系统架构如下图:
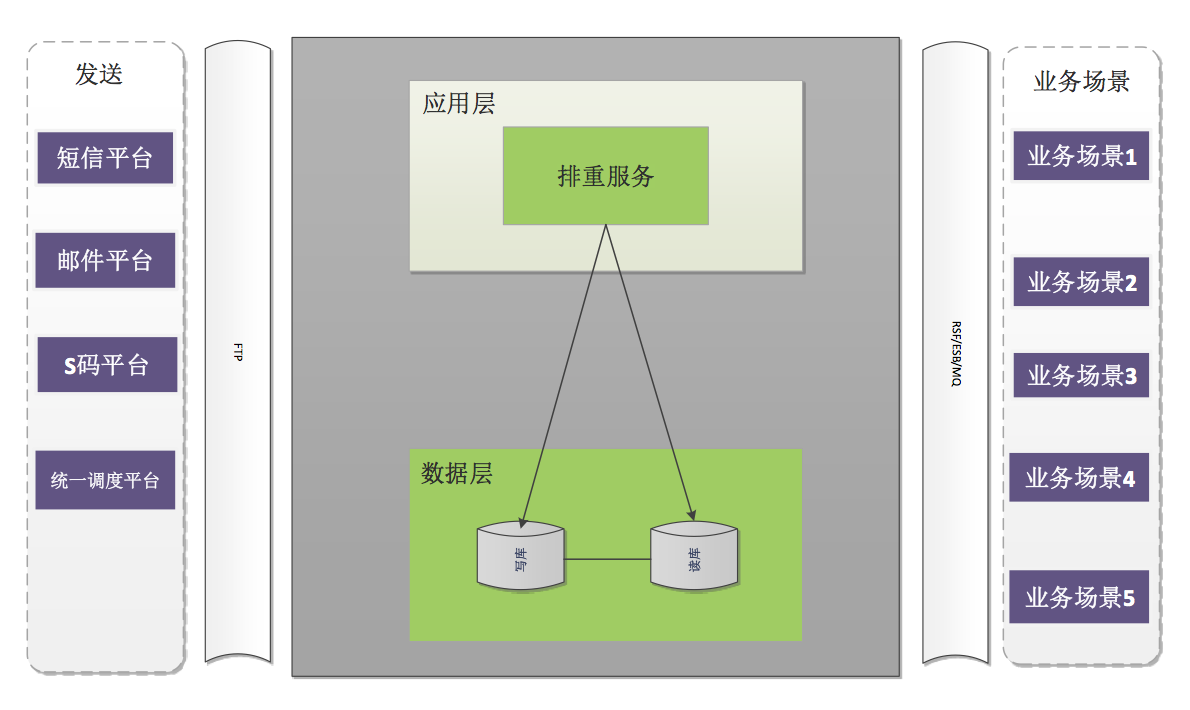
排重前世
系统初期数据排重实现通过数据库表关联排重。通过表 sql 关联进行排重随着数据量的增加效率随之降低,随着业务的发展, 活动涉及到的排重数据总量达到数十亿以上,虽然采取了分库分表策略提升处理能力, 但是以表关联进行排重方式已经不能支撑业务发展。而且待发送活动需要在前一日进行排重生成文件上传到 FTP 中,无法做到实时精准排重。
原有系统架构排重处理如下图:
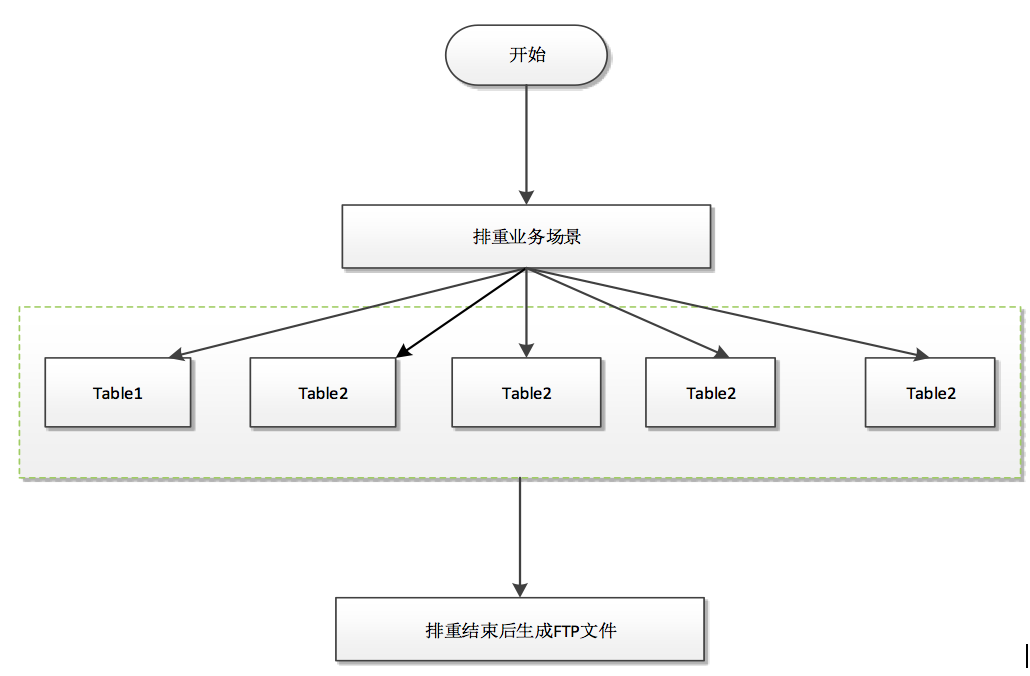
缺点:
1. 数据库性能
多个业务场景进行高并发排重,数据库存连接数固定,对历史数据等数据的排重需要进行多表关联,业务场景排重后的信息还要持久化到表中,导致读写操作频繁,致使数据库的 CPU、IO、网络等开销增高,会出现数据库宕机问题。
2. 排重效率低
历史数据和实时数据分部在不同的表中,如果每张表数据量达到百万级别,进行表关联排重效率低下。平均一次排重操作耗费 10 分钟以上。
3. 排重无法并发处理
业务场景排重需要相互交叉排重,否则会出现同一用户推送多次营销类信息,降低用户体验。数据库排重需要将不同的活动进行持久化操作,只有在持久化后才能够进行相互交叉排重,多个业务场景排重只能串行。
4. 排重实时性差
数据库排重效率低下和无法高并发处理,排重在发送前日一日提前生成,无法将当日符合活动的会员进行筛选排重,无法达到实时性。
5. 发送准确性差
业务场景在排重后需要生成待发送的文件,上传到指定的 FTP 服务器目录中,发送系统需要等待排重生成文件后才能执行后续业务。如果排重生成的文件大,发送系统需要先进行文件解析,发送系统如果文件解析出现失败,会导致部分会员的营销数据未发送,会导致营销效果大打折扣。
6. 可扩展性差
从架构上应用数据库进行排重处理,无法进行系统的横向扩展。如果进增加数据库机器进行分库处理,业务逻辑处理单元需要对数据增删改查操作进行分库分表处理。不利于进行持续扩展。
7. 持久化数据上限
依靠数据库的存储能力,数据库容量已经达到瓶颈,如果进行机器内存等扩容也无法从根本上解决大数据量的持久化存储。
排重今生
随着苏宁各个产业的发展,营销业务场景的激增,涉及到的排重数据总量亿级以上,尤其是在大促期间数据总量在几十亿级以上。通过以往大促的数据量的预估,排重系统优化方案为引入引入缓存系统,应用 ES、redis 进行实时排重处理,依靠 Hbase 对数据存储持久化,依靠 Hive 进行报表和图形化系统的统计展示,依靠 kafka topic 进行排重消息数据实时推送。
从架构上设计如下:
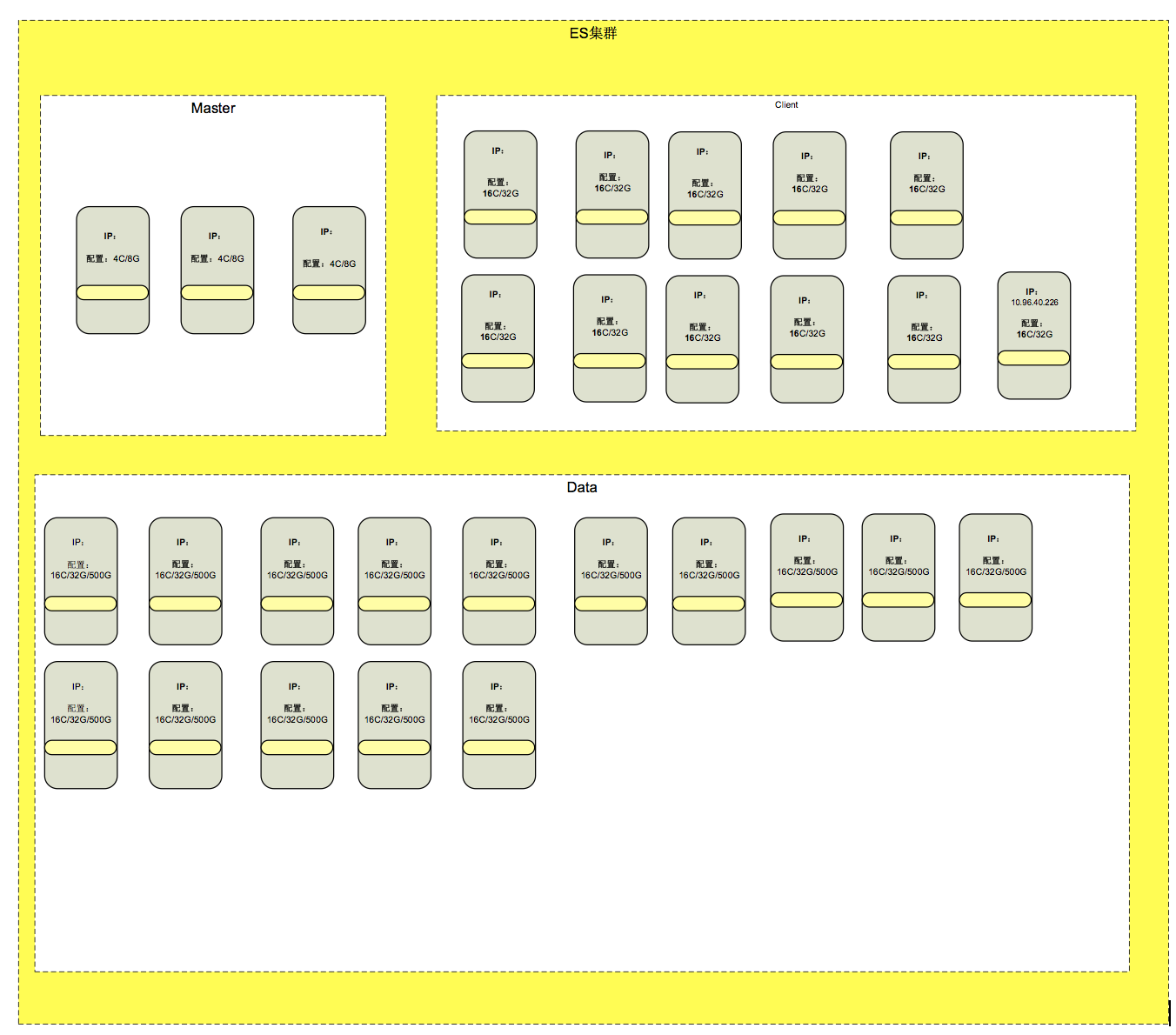
1.ES 集群
Elasticsearch(ES)是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES 能够横向扩展至数以百计的服务器存储以及处理 PB 级的数据。可以在极短的时间内存储、搜索和分析大量的数据。
通过 ES 特性,设立 ES 集群,ES 集群中分配为不同的小集群,每个集群通过 Shard 进行分配,形成一个大的 ES 集群,从架构上解决了单索引量大与查询时跨多 shards 后数据聚集到单 ES 实例导致此 ES 宕机等问题。
如下图:
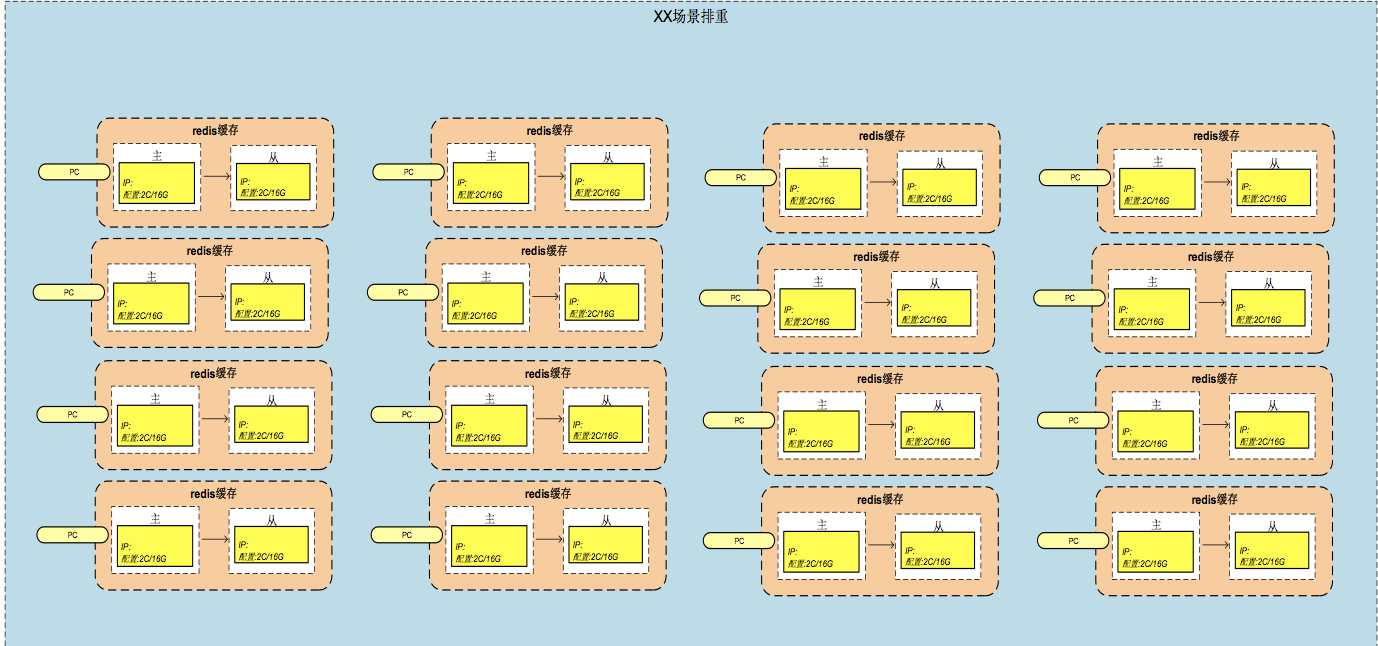
2.REDIS 集群
Redis 是当前比较热门的 NOSQL 系统之一,它是一个开源的使用 ANSI c 语言编写的 key-value 存储系统(区别于 MySQL 的二维表格的形式存储。)。
Redis 读取的速度是 110000 次 /s,写的速度是 81000 次 /s,支持多种数据结构:string(字符串);list(列表);hash(哈希),set(集合);zset(有序集合), 持久化,主从复制(集群)。针对 redis 的特性,对不同的排重场景分配不同的 redis 集群,每个集群通过 shard 进行数据分配,从架构上解决了不同排重场景数据的高并发处理排重达到数据处理的高效性、数据存储的分散性。对每台 redis 服务器设置一主一从配置,redis 的主从配置保证数据的安全性。
3. 持久化
Hbase 是一种 nosql 数据库,是一种分布式数据库系统,可以提供数据的实时随 机读写, 数据的最终持久化存储是基于 hdfs 的,特点是可以随时实现在线通过 廉价的 PC 扩容,将历史排重记录等信息通过 HBASE 进行永久存储,不会存在 存储容量瓶颈问题。
4. 报表
hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行,可以为报表系统展示历史数据业务场景的排重情况。
5. 消息推送
根据不同的渠道和终端,建立不同的 kafka topic,在业务场景排重完成后,通 过 kafka 实时发送到各个渠道和终端系统中,保证了排重数据发送的准确性和实时 性,不再出现发送方 FTP 文件等待文件上传后再进行剩余业务处理。使用 kafka 也 解决了外围系统的耦合,在设计上每个 kakfa topic 的 partition 均按支持 1 万 TPS 设计。
如下图:
优点:
1. 性能
引用缓存系统,目前系统架构支持纵向横向扩展,不存在性能问题。
2. 效率
在排重中使用 ES 作为历史数据来源,针对历史在不同的 ES 集群中根据索 引对数据进行聚合分析、排重、筛选形成历史数据的初步排重,排除掉百分之 70 以上的数据量,ES 排重后的数据,与 REDIS 中存储的实时热点等数据进行交 叉排重达到排重效果。
3. 高并发
各种业务场景的排重可以启动线程同时进行排重操作,因为 ES 与 redis 以集群形式部署,可以很好的支撑多业务场景同事进行排重处理,在业务场景排重后通过 rediskey 进行交叉排重。
4. 实时性、准确性
通过高并发实时处理的排重数据,通过 kafka topic 发送到不同的渠道和终端,各发送系统通过实时消费处理数据进行营销数据的发送,避免出现解析文件失败出现部分营销数据未发送的情况,达到了实时性和准确性。
5. 可扩展性
通过集群和 shard 方式部署的 ES 和 redis 系统,可以达到系统的横向扩展,不需要对现有业务逻辑进行代码处理,直接生效。
数据存储结构的华丽转身
数据存储由原来的 db 存储转换成 redis、es、Hbase 等进行存储处理,有效的解决了高并发、大数据场景下数据处理能力,实现了数据的永久存储。
Redis 集群通过 shard 进行数据有效的将数据分配到不同的机器中,减少 key 存储的大小可以应用 redis 的 key 的聚合和合并减少 key 处理的复杂度,增加处理效率。
ES 数据的 shard 分配解决了单索引数据量大,进行排重、筛选、交叉提高执行效率和跨索引引起的宕机问题。
总结
根据苏宁以往大促经验和数据增长点, 在双十一中各个产业的促销活动要对所有的会员用户进行营销,各种场景进行排重的数据达到数十亿以上,通过 Redis 的高读写速度、所有操作的原子性、多重数据结构和 ES 可以在极短的时间内存储、搜索和分析大量的数据的能力可以很好的支持排重系统的高并发排重。通过 ES 的高可用和可扩展而生,可以通过购置性能更强的服务器或者升级硬件来完成系统扩展,称为垂直或向上扩展(Vertical Scale/Scaling Up)。
另一方面,也可以增加更多的服务器来完成系统扩展,称为水平扩展或者向外扩展(Horizontal Scale/Scaling Out)。通过向集群中添加更多的节点来分担负载,增加可靠性,ES 天生就是分布式的:它知道如何管理多个节点来完成扩展和实现高可用性, 在后期持续扩展中应用不需要做任何的改动。现有的精准营销之排重服务系统能够支持集群机器的横向纵向扩展,能够很好的支撑业务数据量的增长,能够更加高效、实时、精准的数据排重服务,也能够根据数据的永久存储,追溯到历史数据,提供为报表系统的更加准确、更加全面的报表数据,为运营人员进行促销活动效果分析。
作者简介
于海涛,苏宁易购 IT 总部技术经理,主要负责精准营销产品开发部技术研发工作。同时,参与 818、双 11 等大促保障、系统稳定和性能优化工作。在苏宁的任职期间,经历了精准营销产品线产品的研发和系统的调优等工作。




