
HDFS(Hadoop 分布式文件系统)集群随着使用时间的增长,难免会出现一些“性能退化”的节点,主要表现为磁盘读写变慢、网络传输变慢,我们统称这些节点为慢节点。当集群扩大到一定规模,比如上千个节点的集群,慢节点通常是不容易被发现的。大多数时候,慢节点都藏匿于众多健康节点中,只有在客户端频繁访问这些有问题的节点,发现读写变慢了,才会被感知到。
因此,要想维护 HDFS 集群读写性能稳定,慢节点问题一直是一个绕不开的话题。在 Hadoop2.9 之后,社区支持了从 Namenode jmx 上查看慢节点的功能,小米基于此框架,开发了一整套 HDFS 集群慢节点监控及自动处理流程,在实际生产环境中,具有不错的应用效果,可以保证慢节点能够被及时准确发现,并在 NameNode 端自动规避处理。
1、HDFS 写 pipeline 的流程
为了保证高可靠性,文件默认以三副本的形式保存在 HDFS 上,当 client 开始写入一个新文件的时候,首先会找出三个 DataNode 建立 pipeline,随后数据以 packet 为最小单元,依次通过 pipeline 里的三个 DN,完成三副本写入。
具体的写入流程是:首先 DN0 收到从 client 端传过来的 packet,DN0 立即将 packet 传至下游 DN,随后对 packet 进行落盘操作,DN1 的操作与 DN0 一致,DN2 作为 pipeline 里的最后一个节点,在落盘数据之后,会向上游 DN 发送 ack,DN1 在收到 ack 后继续向上游转发,DN0 在收到 DN1 的 ack 后向 client 端转发,client 收到 DN0 的 ack 即完成一次完整的 pipeline 写入流程。
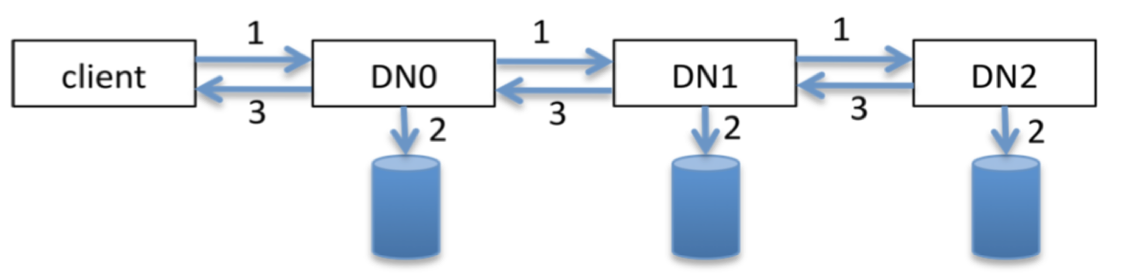
HDFS 写 pipeline 流程
在写 pipeline 的过程中,如果出现了网络慢节点,步骤 1 的耗时会明显增加,如果出现的是磁盘慢节点,步骤 2 的耗时会明显增加,因此,HDFS 的慢节点监控,主要是监控步骤 1 和步骤 2 的耗时。
2、网络慢监控原理
2.1 收集数据
监控一个 DN 网络传输变慢的原理是,记录集群里各个 DN 间的数据传输耗时,找出其中的异常值并作为慢节点上报给 NN。正常情况下各节点间的传输速率基本一致,不会相差太多,假如出现了 A 传 B 耗时异常,A 就往 NN 上报 B 是慢节点,NN 端在汇总所有慢节点报告后,会判断是否存在慢节点。比如 X 节点是故障节点,那么一定会有很多节点往 NN 上报 X 是慢节点,最终在 NN 端出现类似的慢节点报告,表明 X 是慢节点。
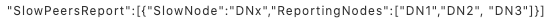
为了计算 DN 往下游传数据的平均耗时,DN 内部维护了一个 HashMap
HashMap 的 Queue 是一个固定大小的队列,队列长度 36,如果队列满了,就会踢掉队首成员把新的 SampleStat 加入队尾。这意味着,我们只会监控最近 3 小时(36 X 5=180min)的网络传输情况,目的是为了保证监控数据具有时效性。
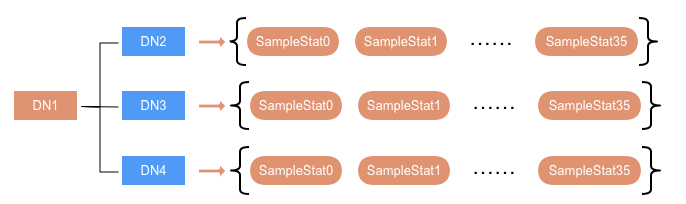
收集监控数据
这样,我们就可以知道 DN1 往集群其他 DN 传数据的耗时情况,如果存在慢节点,数据从 DN1 传到它的耗时一定会比其他线路高很多。
这里还要考虑到几个场景,一个是如果在最近五分钟内,DN1 没有往 DN2 传输数据,那 SampleStat 里的数据应该取什么?答案是直接复用上一个五分钟的数据,因为我们不能说在这五分钟没有数据传输,网络就是没有问题的,有很大的可能,它的网络状况和前一个五分钟是一致的,所以在没有数据传输的情况下,直接复用上一周期的数据是合理的。
更进一步的,如果超过 3 个小时 DN1 都没有往 DN2 传数据,HashMap 对应的 Queue 将会出现 36 个一样的 SampleStat,那么基于 Queue 生成的慢节点报告将不具备时效性。因此我们需要在 DN 做 snapshot 的时候,给 SampleStat 带上一个时间戳,保证我们只监控最近 3 个小时的数据。
还有一个问题是,pipeline 里有三个 DN,DN 间有两段网络传输,这两段网络传输我们都需要关注吗?其实我们只需要关注最后一段,即 DN1 往 DN2 传数据的情况就可以。一个是为了精简统计量,另一个原因是,第一段网络传输(DN0 到 DN1)在其他 pipeline 里可能就是最后一段,所以从整体上看只要监控最后一段的传输延迟,可以保证集群所有 DN 都能被监控到。
2.2 发送慢节点报告
DN 在上报心跳的时候会判断是否需要生成 SlowPeerReport,并将其作为心跳信息的一部分发送给 NN。SlowPeerReport 的生成周期与 DN 做 snapshot 生成 SampleStat 的周期一致,默认取五分钟。首先从 Queue 取出所有 SampleStat 做叠加,求算数平均值 averageLatency,那么在最近三小时,DN1 往 DN2 传数据的平均延迟就是 averageLatency1_2。然后根据这些 averageLatency,算出慢节点上报阈 upperLimitLatency。当有节点的 averageLatency 大于 upperLimitLatency,即认为该节点属于一个网络慢节点,且由 DN1 上报。最后生成对应的 SlowPeerReport,通过心跳上报给 NN。
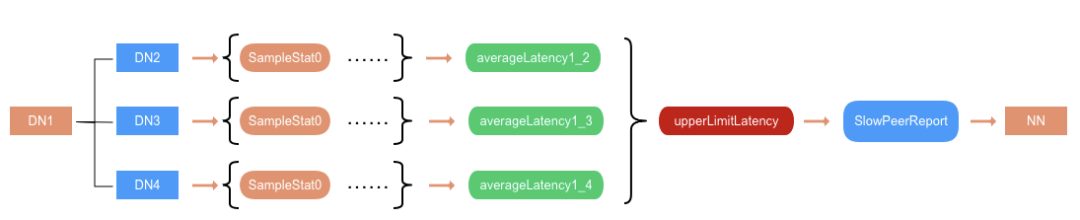
DN 发送慢节点报告
对于 upperLimitLatency 的计算,我们先算出 averageLatency 的中位数 median,并以此算出中位数绝对偏差 MAD(Median absolute deviation)[1]。MAD 是一个健壮的统计量,比标准差σ更能适应数据集中场景的异常值,也就是说少量的异常值不会影响最终结果。
MAD=median(∣Xi−median(X)∣)
通常认为 median + 3 x MAD 是异常值,出现的概率是千分之几,这一点类似于正态分布的 3σ定律[2]。
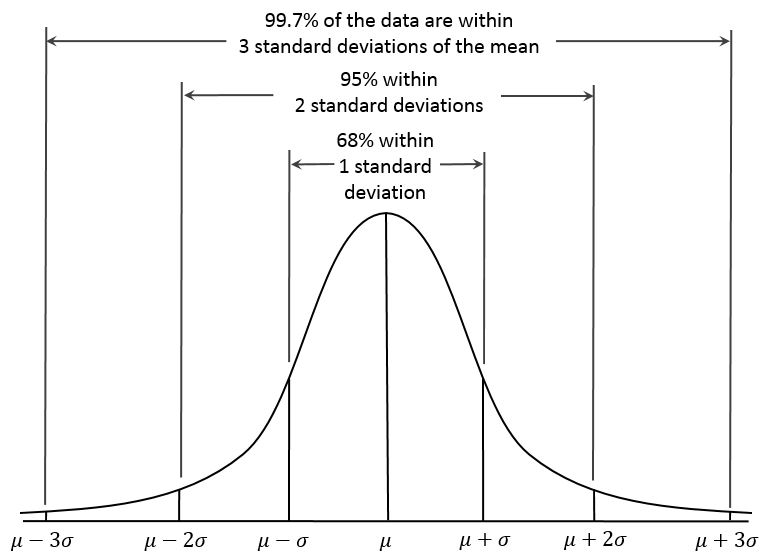
正态分布 3σ准则
因此慢节点上报阈值 upperLimitLatency 可以取 median + 3 x MAD,但是我们也要考虑到集群的容忍度,设定一个固定的 lowThreshold,取两者间的较大值为 upperLimitLatency。
2.3 监控
NN 内部维护一个慢节点 HashMap
慢节点报警通过使用一个独立的探测程序 Canary 实现,Canary 会定期查询 NN jmx,触发 getSlowPeersReport 方法,遍历 HashMap 查询是否存在 slowNode。
为了解决报警恢复的问题,我们通过修改 DN 心跳协议,在慢节点报告中增加当前五分钟传输延迟 currentLatency。基于此,报警触发以及恢复的标准如下:
currentLatency > threshold,触发报警
currentLatency > 0 && currentLatency < threshold,网络状况已恢复,报警 OK
currentLatency = 0.0 && averageLatency > threshold,最近五分钟没有数据传输,但三个小时内平均网络延迟很高,极有可能网络传输依然很慢,报警继续
3、磁盘慢监控原理
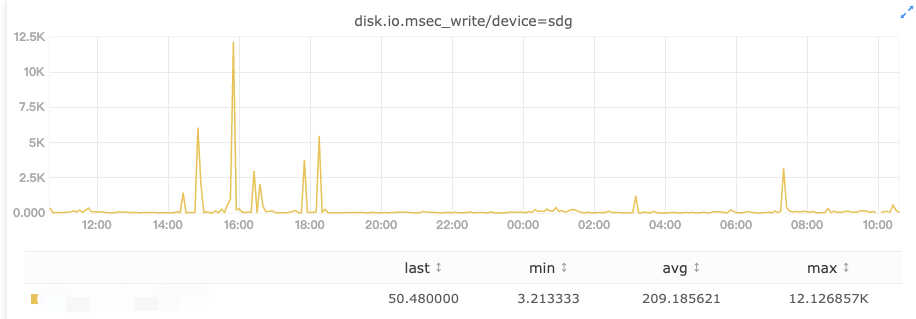
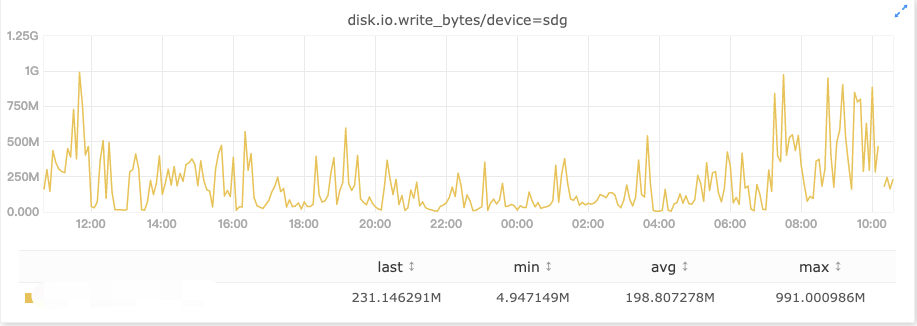
坏盘的间歇性卡顿
正常情况下对 hdfs 写入来说,各个盘的写入量是差不多的,如果进入写入高峰期,那就是整个节点所有盘的写入速度都明显变慢,没有异常值,这种情况是不会报磁盘慢的。但如果出现特殊情况,只有个别盘突然进入一个短暂高峰期,它的写延迟将明显上涨,直接判断这是一个慢磁盘显然是不合理的,因此慢节点探测需要规避掉这类场景。
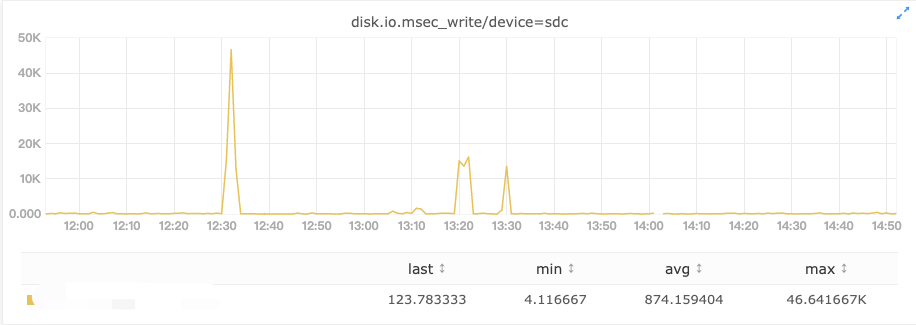
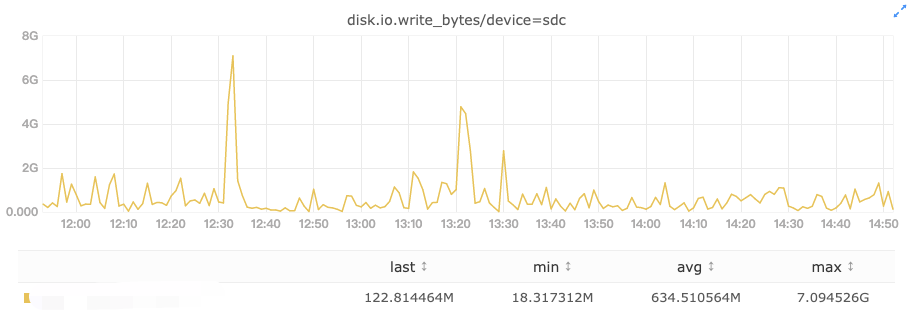
高峰流量造成短暂卡顿
为了提高探测准确率,我们决定采用计数的方式来判断这个磁盘是否真正出了问题。每 5 分钟做一次统计,如果在一个小时内,出现了 6 次以上的写入慢,可以认为这是一块有问题的磁盘,将生成 SlowDiskReport 报告给 NN。
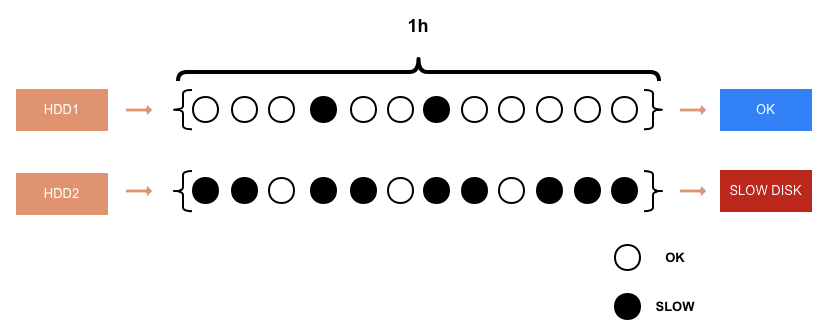
采用计数的方式判断慢盘
具体的实现方式是,每个盘都维护一个长度为 12 的 Queue,每 5 分钟尝试更新一次 Queue,如果盘的 WriteIo 平均值大于 upperLimitLatency,就将此刻 timestamp 加入 Queue,表示在这一周期出现了写入磁盘慢,如果 Queue 满了就把队首成员踢掉再入列。在生成 SlowDiskReport 的时候,如果队列是满的且队首成员的 timestamp 在一个小时以内,就意味着,在最近一个小时,磁盘写慢的时间超过了 30 分钟,该磁盘将会被加入 SlowDiskReport 上报给 NN。
4、NameNode 自动处理慢节点
我们进一步扩展了慢节点监控的功能,在 NN 端维护一个 HashMap,用来记录已经上报的慢节点。这样 NN 在选 DN 建立 pipeline 的时候,可以尽量规避掉这些存在问题的节点。NN 周期性查询慢节点报告,当发现新的慢节点信息,就更新 HashMap,它的 key 为节点 ip,value 是慢节点信息过期时间 expire time,expire time=current+ interval,用来表明这个节点在 expire time 之前会标识为慢的状态。
NN 在选 DN 的时候,如果选中了慢节点,就加入 exclude 列表,重新选一次,最终选到正常节点建立 pipeline。但是这里也要考虑集群中正常节点数不够的情况,如果遍历完所有可用节点,依然选不到 DN 会抛 NotEnoughReplicasException,此时将触发重新选择,这一轮的选择不会考虑慢节点场景,这样可以保证 NN 在选 DN 的时候尽量不会选到慢节点。
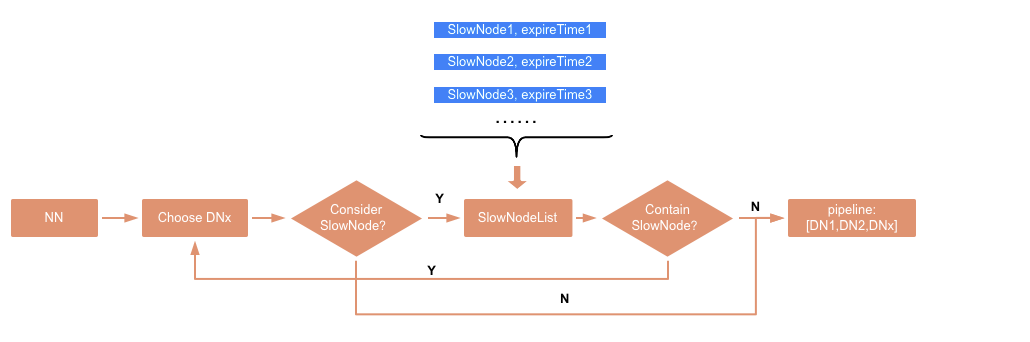
NameNode 自动处理慢节点
5、总结
整个慢节点监控的流程如下图所示:
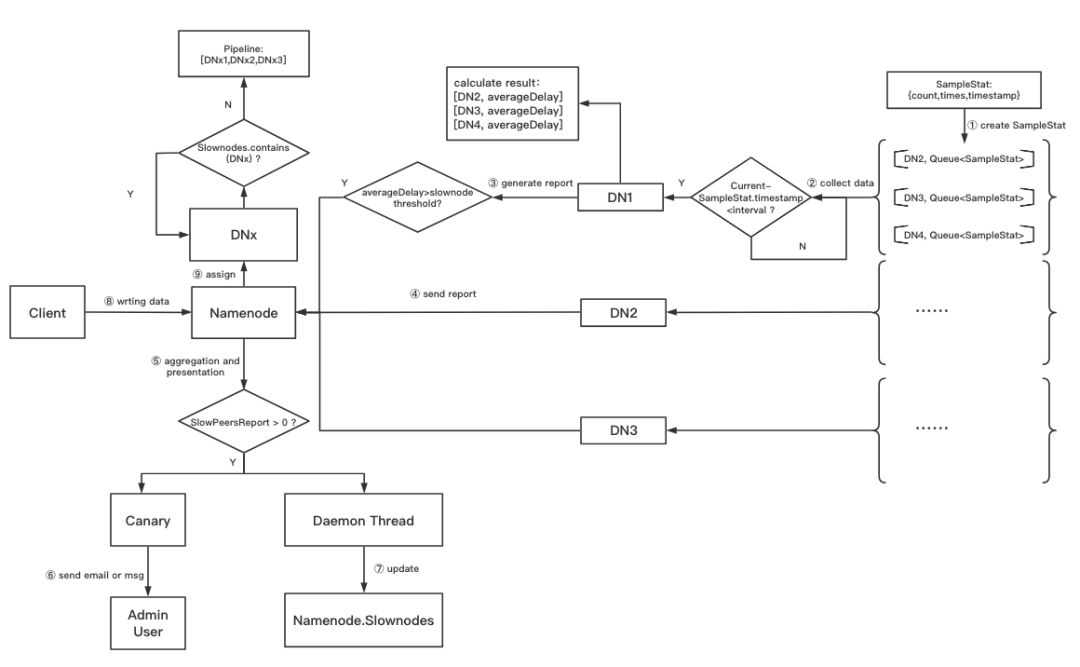
慢节点监控及自动处理流程
该功能目前已经上线小米规模最大的离线集群,探测的准确度在 90%以上,已累计为集群找出上百块坏盘。NN 自动处理慢节点极大节省了人工介入成本,SRE 只需要每周进行一次故障节点处理,即可保证集群读写性能稳定。
参考资料
[1]中位数绝对偏差 MAD:https://en.wikipedia.org/wiki/Median_absolute_deviation
[2]正态分布:https://en.wikipedia.org/wiki/Normal_distribution
备注:本文首发于小米技术,经授权转载。




