
本文最初发布于 InterviewNoodle 博客。
软件设计是一个不断发展演进的过程。每个大型系统都是从小微系统开始的。当现有的架构遇到问题而又无法解决时,系统就会开始演进。每一次演进都会伴随着一些技术上的选择。需要解决什么问题?需要付出什么样的代价?作为一名架构师或高级工程师,必须找到一种合理的演进方式,在开发进度、技术栈、团队水平等各方面都能满足条件,这样才能制定出可行的解决方案。
本文将介绍 CQRS(命令查询职责分离)的基本理念和要解决的问题。我们将从一个小型单体架构开始,逐步演进,像每一个软件系统的演进一样。本文将介绍每一次演进背后的原因和方法。
传统单体架构
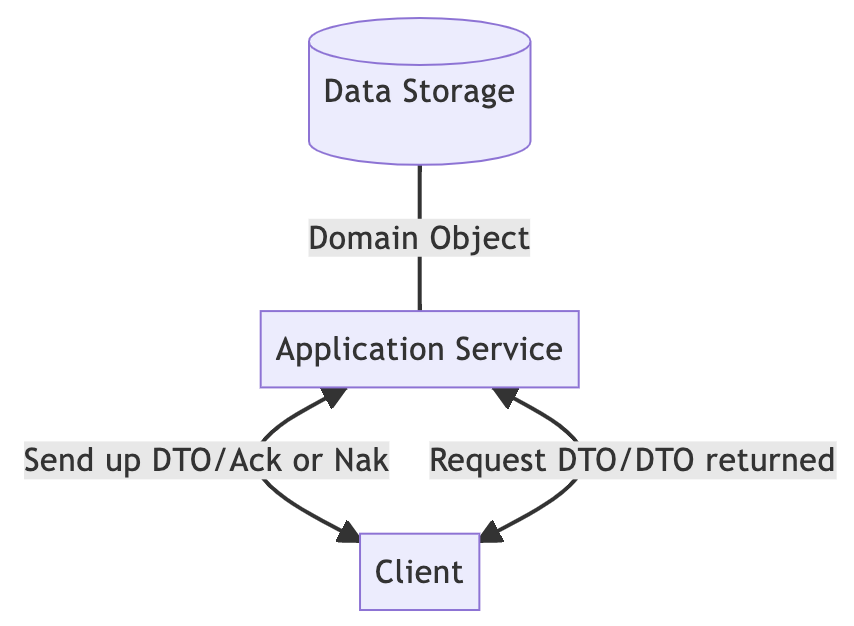
这是最常见的系统设计。有一台 API 服务器,通常是 restful API,和一个数据库。客户端事先与后端协商好传输格式。读和写都是通过 DTO,即数据传输对象完成的。然而,后端在处理业务逻辑时需要将 DTO 转换为具有领域知识的领域对象,并使用领域对象作为数据库的存储单元。
为了实现读 / 写分离,在左边的写路径中,客户端向后端发送 DTO,对数据库进行 CUD(创建 / 更新 / 删除)操作,后端在处理完成后向客户端返回表示成功的 Ack 或表示失败的 Nak。通常,在 restful API 中,2xx 表示成功,4xx 表示失败。右边的读路径只是通过读请求来获得相应的 DTO。
再从客户端的的角度来说下 DTO 的含义。在客户端,DTO 通常包含要在屏幕上呈现的所有数据。例如,当你在社交媒体上查看自己的个人资料时,它将包括你的名字、账户和其他个人信息,以及你自己最近的活动,甚至你关注的活动。DTO 包含所有需要在这个页面上呈现的信息。
为什么我们要强调读 / 写分离?我们不能在读 / 写路径上使用同一个程序吗?因为我们想在将来更好地优化我们的系统。写路径有特定的优化方法,读路径也是如此。比如说,做一个缓存,在读路径上可以使用预读缓存来减少响应时间。而且,写路径可以通过写入缓存来优化。其次,也可以把写入操作异步执行。将所有 DTO 写入消息队列中,并由工作者进程负责处理,通过这种方式来处理大量的数据写入。此外,可以使用适当的数据库进行写入和读取。
因此,读 / 写分离是必不可少的。而且,在系统设计的早期阶段就应该考虑到这一点。写路径专注于数据的持久化;而读路径则专注于数据的查询。
然而,这个系统设计模型有两个主要问题:
贫血模型,也被称为 CRUD 模型。后端专注于数据转换而不处理业务逻辑,这将导致业务逻辑散落在各处,领域知识也会消失。例如,对于一个电子商务网站,我们会说“购买”,而不是“插入一条订单记录”。
可扩展性不足。从系统架构的角度来看,数据库很容易成为整个系统的瓶颈。读取和写入都必须在它上面进行。因为缺少横向扩展能力,RDBMS 的问题就更加严重了。
基于任务的单体架构
为了解决上述传统单体架构中存在的问题,这里我们尝试引入域的概念。
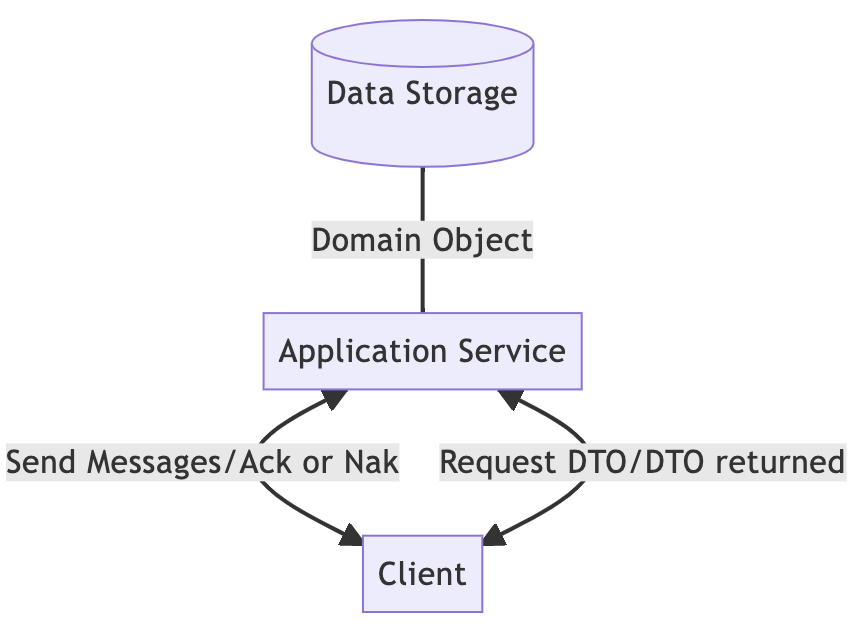
这个图与上面的图基本相同。唯一的区别是在写路径上用消息代替了 DTO。消息包含动作和数据,而不是像 DTO 那样只包含数据本身。因此,我们可以在消息中携带特定域的动作,使后端更容易识别每个动作,并有一个相应的域实现。
在这个阶段,CQRS 中的 C 出现了,消息就是一种命令。然而,可扩展性问题仍未得到解决。
另外,虽然我们简化了 DTO,改为使用消息进行通信,但在读路径上我们仍然需要 DTO。还是以社交媒体为例。在修改昵称时,消息的格式可能是{"rename": "LazyDr"}。但是当呈现个人资料时,我们还需要额外的信息,如活动。这种信息缺口使得我们有必要在读路径上做大量的处理来获取 DTO。
CQS(命令查询分离)
CQS 的出现就是为了解决以上读写分离的痛点。
读取时,客户端需要 DTO,所以后端可以在读路径上做一些专门针对读取的优化,比如从原来的域对象预先生成 DTO,并将 DTO 存储在专门的数据库中以供读取。
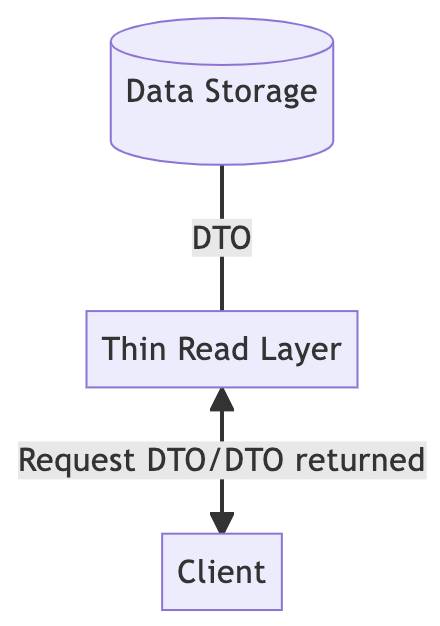
这样一来,在读路径上,应用服务的实现变得更加简单。应用服务会成为一个很薄的读取层,只负责分页、排序等工作。发出请求后,客户端很容易从数据库中检索到 DTO。
那么问题来了,谁来生成这些预建的 DTO 呢?这是写路径的职责。
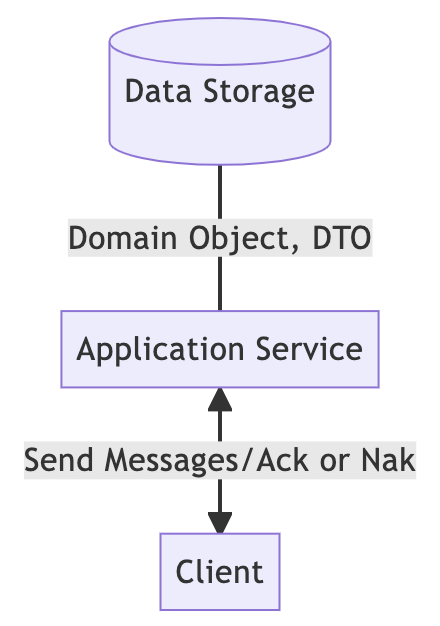
虽然这幅图与之前看到的例子类似,但实际上,除了持久化域对象,应用服务还必须持久化 DTO。换句话说,大部分的业务逻辑都压在了写路径上,它还需要准备各种读视图。
至此,我们已经解决了遇到的大部分问题,但扩展性问题仍然没有得到解决。现在,我们进一步明确下扩展性,主要包括两个方面:流量:写入量增加。扩展:功能需求增加,例如需要各种不同的读视图。
继续以社交媒体为例,它有一个个人资料的展示,但可能有另一个按照时间线的展示。CQRS 为什么写路径要负责准备读视图?写应该专注于持久化,各种读视图不应该在写路径上处理。但是,读路径上只有读,谁该准备那些读视图?
因此,完整的解决方案是这样的:
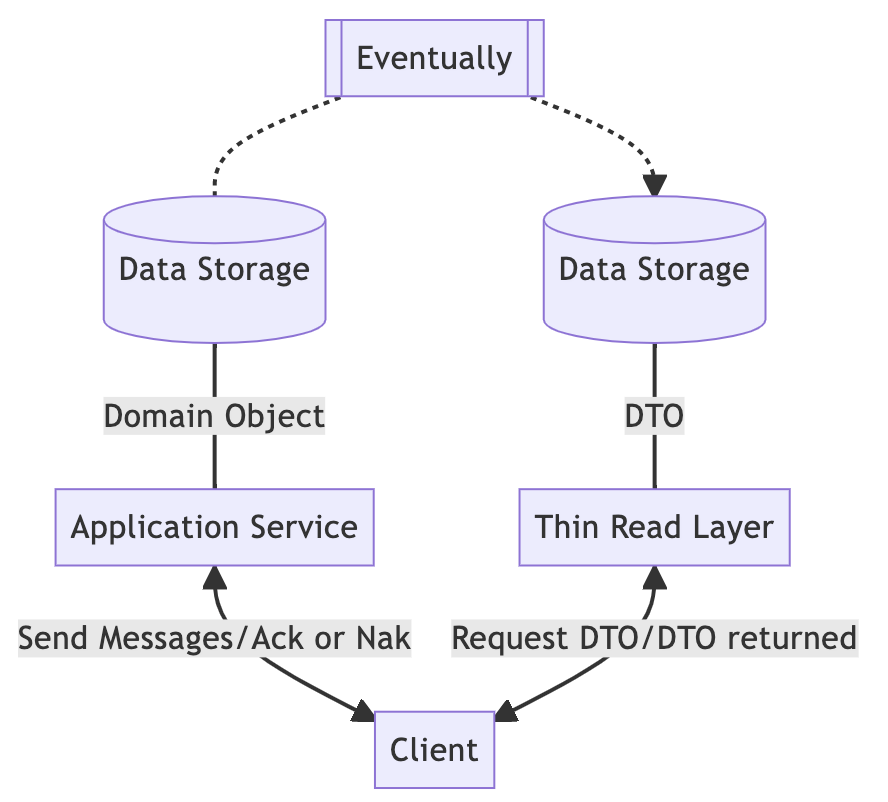
左边的写路径和右边的读路径已经在 CQS 部分介绍过了。唯一的区别是增加了 Eventually,负责将写路径使用的数据库转换为读路径使用的数据库。一旦涉及到数据同步,就可能遇到数据一致性问题,所以这里列出了几种实现最终一致性的方法,按耗时从短到长排序如下:
后台线程:典型代表是 Redis。在数据写入主节点后,Redis 会立即在后台将数据发送到的副本中。
消息队列加工作者。这是异步数据复制的一种常见做法。在写入数据库时,会创建一个事件并发送到消息队列,然后由工作者处理。
提取 - 转换 - 加载:这个时间间隔最长,从几分钟到几小时不等。使用 map-reduce 或其他方法将结果写到另一边。
无论采用哪种方法,单一真相来源都是必须的。也就是说,如果在转换过程中发生任何故障,系统必须能够恢复未完成的工作。因此,数据必须唯一而且可靠。
通常,数据有两种类型:
状态:状态指你此刻看到的东西,比如说写在银行存折上的余额。
事件:事件是修改每个状态的动作,例如银行存折上的每一条交易记录。
实际上,我们已经有了可以作为事件存储的消息。对于写路径,按顺序存储消息非常有效。借助这些消息,很容易根据需要创建出不同的读视图。这种方法也被称为事件源。
但仅有事件还很难有效地利用。为了获得最终结果,每一次转换都必须从头到尾运行,以重建读视图。因此,最好是采用一种混合方法。在写路径上,将状态和事件都保留,转换过程可以根据实际情况选择数据源。
总结一下 CQRS 中数据的整个生命周期:
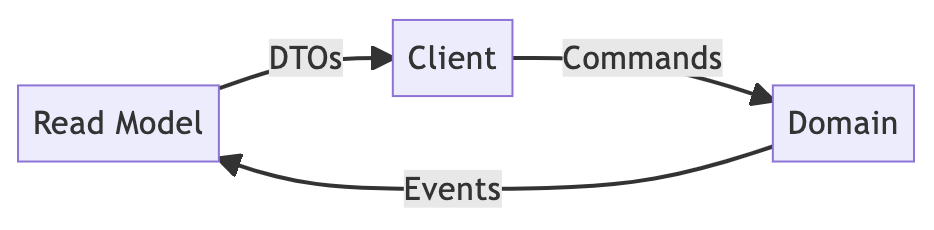
数据从客户端开始,以命令格式进入后端。根据业务逻辑,它被转换为域对象并存储在数据库中。这些域对象被转换为各种读视图,并根据要求存储在不同的专用读数据库中。最后,客户端以 DTO 的形式获取这些读视图。
小结
有许多书籍和文章以各种方式介绍了 DDD 和 CQRS。在我看来,这些模式限制了我们在进行 DDD 设计时的想象力,如实体、价值对象、聚合等。这使得大多数开发人员觉得,DDD 离自己很远,很难实现,也很难实施。事实上,DDD 的概念并不复杂;相反,DDD 是为了封装业务逻辑,促进功能需求的扩展。
CQRS 就更简单了。在这篇文章中,我们从系统演进的过程出发,介绍了整个系统的设计过程和需要解决的问题,最后自然地得出 CQRS 的结论。
系统设计中没有银弹。每一次演进都是为了解决一些特定的问题。然而,它可能会带来新的问题。以本文的设计过程为例,CQRS 似乎解决了所有提到的问题,“贫血模型”和可扩展性不足,但也带来了新的问题,如数据一致性。每一种技术选择都有它的权衡,只要了解每个选项背后的所有威胁因素,就可以选出相对可以接受的方法。
即使你选择了 CQRS,在实践中,实现最终的一致性仍然有三种方法可以选择。系统设计是不断选择的结果。
这篇文章的目的是告诉你,DDD 没有那么可怕,CQRS 也没有那么复杂,只是一个决定而已。
查看英文原文:
https://medium.com/interviewnoodle/shift-from-monolith-to-cqrs-a34bab75617e




