
医保基金场景中,欺诈、侵占、挪用、重复报销、制度衔接等违规现象一直是打击和监管的重点。尤其是《国家医疗保障局关于做好 2019 年医疗保障基金监管工作的通知》、《国家医疗保障局办公室关于开展医保基金监管“两试点一示范”工作的通知》等文件,不仅明确了引入第三方力量参与医保基金监督管理,也要求各地根据欺诈骗保行为特点变化完善监控规则、细化监控指标和智能监控知识库,提升智能监控效能。今年 3 月,中共中央、国务院于发布《关于深化我国医疗保障制度改革的意见》,以医疗保障制度改革为核心的新一轮医疗支付改革拉开序幕。其中,如何利用 AI、大数据等技术,解决医保风控中“监管智能精细化及全流程化”、“动态监测实时化”等问题,成为了克服原先医保管理因特征数据有限、大规模计算平台及手段缺乏等的核心关键。
目前,市面上已有多项针对医保场景的风控模型或风控产品,但因各公司海量用户数据积累度差异,算法选型、模型可解释性、跨平台能力各不相同,因此应用效果也有较大区别。平安医疗健康管理股份有限公司(以下简称“平安医保科技”)“大数据 AI 风控系统”的诞生和应用踩在了这一风口上,其充分利用 AI 技术识别医保数据中的异常,最终识别骗保、作弊、违规等行为。
为一探其中的技术原理和创新实践,了解其选型、架构背后的设计思路,InfoQ 对平安医保科技“大数据 AI 风控系统”研发团队负责人进行了专访,就该套系统中自主研发的核心创新技术、运作机制等内容进行深入挖掘及展示,从而为业界提供可供参考的研发及实践思路。
平安医保科技大数据 AI 风控系统的诞生及应用
医疗保险基金支出的持续性快速增长以及收入与支出间的极不对等,国家对骗保行为零容忍以及医保局打击力度的加大,医保基金风控体系及数据分析服务建设的增强,这一系列的大背景正催生大数据 AI 风控系统的诞生。
大数据 AI 风控系统需要着力优化和改善的是几个层面的“顽固性”问题:
全面性(对大量就诊单据全面审查);
时效性(需及时发现就医过程的违规欺诈及支出);
复杂性(甄别日趋隐蔽和复杂的欺诈行为);
宏观性(对海量数据中异常数据的高效精准识别);
专业性(专业人员人手及能力不足);
系统性(风控机制和流程未形成串联,风控结果和结论无系统性总结等);
准确性(审核准确率较低,漏网之鱼较多)。
但随着这几年的发展,风控系统还存在着诸多问题,例如在多场景、多数据源等场景下,模型就很难和多个医院都实现匹配,或因各医院所拥有的数据量参差不齐及样本数有限,因此风控系统的应用效果也就大打折扣。同时,风控系统过往对医疗领域的知识点也缺少全面收集。数据维度多元化,需要针对冒名顶替、虚假病历、违规用药等不同场景进行模型的设计,输出关键值。
基于宏观环境及医保风控现状,平安医保科技于 2019 年研发并上线了其自研的“大数据 AI 风控系统”。
该系统能够有效对诊疗行为进行全流程智能监控,解决传统事后人工审核带来的各种弊端。在整个就医流程中,针对事前预警、事中干预、事后智能化审核这三个层面,平安医保科技大数据 AI 风控系统具有一套完整的优化原理和运作机制:
事前预警:主要包含参保人黑名单、用户信用风险、剩余药量提醒等应用场景,其主要是基于平安画像系统的应用。
事中干预:主要针对医生处方检验、处方风险预警等场景。处方检验主要是基于医药知识库和 AI 技术,通过算法对处方的合理性打分,给出处方风险预警。
事后智能化审核:主要针对识别滥用、骗保风险等场景,它是基于平安的知识库、规则库的综合应用。
平安医保科技大数据 AI 风控系统核心技术创新及实践
在上述这套完整的运作机制中,相比传统的预先设定规则的智能审核系统,平安医保科技大数据 AI 风控系统更着重解决的是基于相关数据指标、在结构化和非结构化的数据中进行特征分类提取、风险性判定、推理预测等。因而对算法应用、模型的强解释性、高鲁棒性等提出了不同程度的高要求。
基于这一背景,平安医保科技大数据 AI 风控系统在算法设计、数据治理、系统架构等多个层面都进行了相应技术创新,以应对骗保场景的多样性。
(一)算法设计
平安医保科技大数据 AI 风控系统算法模块是多种算法的组合,由有监督学习、无监督学习、半监督学习和深度学习等核心模块构成,各算法模块相互作用,最终完成全面、精准的风险识别。
要提高风控识别的准确性,如对问题单据的精准识别,该系统的有监督学习模块将通过训练样本去训练以得到最优模型;而对于新的骗保场景,该系统通过无监督学习模块实现。通过有监督学习和无监督学习模型体系的结合,解决了动态发现、风险评级上的大部分技术瓶颈。
但医保风控场景中还会面临到一些难点,尤其是数据孤岛问题——即各医疗机构共享数据有限的情况下,需要引入半监督学习模块以实现算法模型训练和运行。平安医保科技大数据 AI 风控系统内置的半监督学习算法就通过在有监督的分类算法中加入无标记样本以增强分类效果,从而在不断接触新样本的过程中更新算法。
在算法设计层面,同时平安医保科技自研了多种算法。平安医保科技风控系统研发负责人表示,“自研的识别算法,目前业界并没有在医保领域的成熟应用,也没有可复制的案例”,基于这样的背景即开始了自研。通过自研的算法,可以完成对骗保风控场景的全覆盖。
当前,各个医疗机构出于数据安全、数据隐私保护等原因,只能对外提供部分数据供 AI 算法使用。算法模型在不同地域应用也存在自适应安装使用等问题。这种情况下,完整的算法模型是通过在各个医疗机构内部调试后,整合公开数据、算法模型参数等完成的。这个过程则需要应用联邦学习模型,通过打通数据,联合各级、各地、各个领域的数据,可以更精准、更全面地实现控费。同时,基于联邦学习算法解决各个医疗机构数据孤岛,算法模型需要自适应的问题。
此外,平安医保科技在该套风控系统中还基于反馈机制,设计了自优化算法。自优化算法可以根据反馈数据的变化,自动调节算法参数,使算法模型效果达到实时最优。
(二)数据治理
医保基金场景中数据量大、数据复杂等特点带来的一个直接问题就是人工对码成本极高。针对此问题,平安医保科技大数据 AI 风控系统在数据治理的过程中,使用了标准相似度模型、自研度量学习相似度模型、自研深度学习相似度模型等多种技术的集成,创新实现了数据标准化技术。
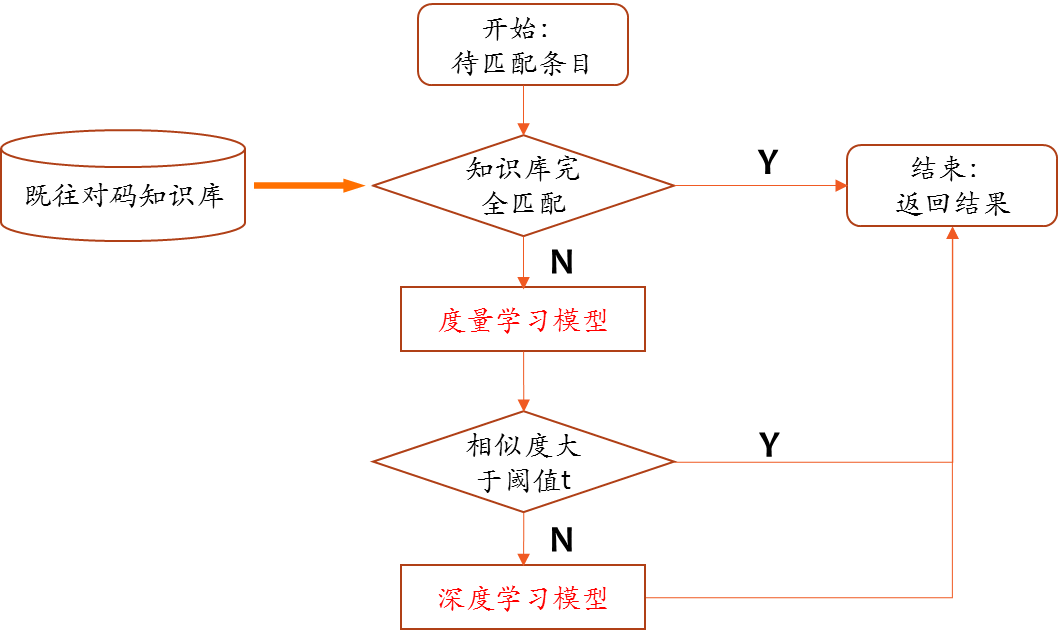
为了确保数据标准化核心模块的精确性,平安医保科技大数据风控系统研发团队会定期分析生产数据,拉取自动对码出错的数据和人工纠正的结果,迭代优化提高模型。通过这一系列的系统和训练模型的调优,整个风控系统的准确性得到了较大提升,映射模型的训练和迭代优化完成度也较高。但同时因为系统较为复杂,随之带来计算量大的重要问题。为解决这一问题,平安医保科技团队还自研了“召回 - 精排”系统。
(三)系统架构
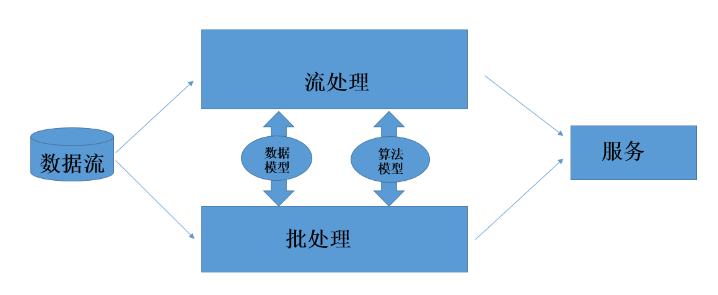
平安风控系统的整体架构基于 Lambda 设计而成,支持 Hadoop、Spark 的协同工作,实现了快速的小批量数据分析和大批量数据分析的均衡,保证了实时性、可扩展型等目标。
其中,平安医保科技自研并应用了 AI 大数据模型共享架构设计。本架构设计结合了规则、统计、算法等多种分析方法,实现了稳定、快速、节省资源等多个目标,同时具备高可扩展性和可移植性。
同时,针对数据模型和算法模型实时同步问题,平安医保科技在实时系统和大数据系统之间使用了模型通道,实现了实时流式系统和大批量处理系统中模型的互通,在原有系统的基础上,达到了兼顾大数据和实时的需求。
(四)知识体系
目前,平安医保科技大数据 AI 风控系统包含庞大的系统全面的知识库和实体信用画像库。知识库在实际应用场景中将发挥重要的作用。例如,通过特征工程识别和衍生出有用的特征,再加上支持了多维度异常识别,因此可以促进达到更好的算法效果。基于涵盖诊疗规则、药品规则和医保规则等多种规范在内的核心知识库,利用自动分析算法,更好地实现事前控制、事中预警和事后审核的医保全流程监管。
平安医保科技大数据 AI 风控系统应用
目前,平安医保科技大数据 AI 风控系统已实现在全国 12 个省 / 市的落地应用,为各省 / 市医保局提供医保风控的大数据采集、存储、处理、分析和服务的整体解决方案。
以某地医保局为例,此前其面临传统规则引擎准确率低、覆盖面窄等问题,同时通过人工审核和识别的过程费时费力。针对这一痛点,平安医保科技团队为其部署了大数据模型分析系统,依托线上人工审核、线下人工稽核的方式,按季度为其推送 AI 风控审核结果。
到目前为止,平安医保科技大数据 AI 风控系统审核了 12 个省 / 市结算明细数据,数据以职工 / 居民就诊数据为主,兼有新农合数据,共计审核 391 亿元医疗费用、5447 万人次就诊(主要是门诊慢性病和住院、部分城市也审核普通门诊),准确率大于 75%。
此外,以某地 AI 大数据风控项目为例,经过平安医保科技大数据 AI 风控系统对门诊慢性病和住院总费用的审核,共审核出异常费用达 4498 万元,异常疑点数 7145 条。同时,对同一批数据审核后,人工验证异常费用 2750 万元,人工异常疑点数 3479 条。
接下来,平安医保科技大数据 AI 风控系统计划在识别准确性、模型可解释性、模型运行性能、整体产品易用性等维度,逐步引入创新技术进行继续提升,并将风险识别的覆盖率提升到 100%。在具体实践上,该风控系统还将着重对产品算法模型的自适应、自优化、可解释性等进行更深度的优化。




