阿里巴巴是世界上最大的电子商务零售商。 我们在 2015 年的年销售额总计 3940 亿美元,超过 eBay 和亚马逊之和。阿里巴巴搜索(个性化搜索和推荐平台)是客户的关键入口,并承载了大部分在线收入,因此搜索基础架构团队需要不断探索新技术来改进产品。
在电子商务网站应用场景中,什么能造就一个强大的搜索引擎?答案就是尽可能的为每个用户提供实时相关和准确的结果。同样一个不容忽视的问题就是阿里巴巴的规模,当前很难找到能够适合我们的技术。
Apache Flink? 就是一种这样的技术,阿里巴巴正在使用基于 Flink 的系统 Blink 来为搜索基础架构的关键模块提供支持,最终为用户提供相关和准确的搜索结果。在这篇文章中,我将介绍 Flink 在阿里巴巴搜索中的应用,并介绍我们选择在搜索基础架构团队中使用 Flink 的原因。
我还将讨论如何改进 Flink 以满足我们对 Blink 的独特需求,以及我们如何与 data Artisans 和 Flink 社区合作,将这些更改贡献给 Flink 社区。一旦成功地将我们的修改合并到开源项目中,我们会将现有系统从 Blink 转移到 Apache Flink。
Part 1: Flink 在阿里巴巴搜索中的应用
文档创建
为用户提供世界级搜索引擎的第一步是创建可供搜索的文档。在阿里巴巴的应用场景中,文档是由数百万个商品列表和相关的商品数据组成。
因为商品数据存储在许多不同的地方,所以搜索文档创建也是一个很大的挑战,搜索基础架构团队将商品相关的所有信息汇总在一起并创建完整的搜索文档。一般来说,整个过程分为 3 个阶段:
- 将不同来源(例如 MySQL,分布式文件系统)的所有商品数据同步到一个 HBase 集群中。
- 使用业务逻辑将来自不同表的数据连接在一起,以创建最终的可搜索文档。这是一个 HBase 表,我们称之为’Result’表。
- 将此 HBase 表导出为文件作为更新集合。
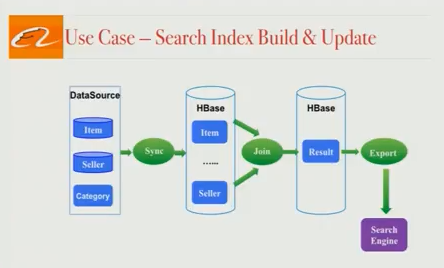
这 3 个阶段实际上是在经典的“lambda 架构”中的 2 个不同的 pipeline 上运行:全量构建 pipeline 和增量构建 pipeline。
- 在全量构建 pipeline 中,我们需要处理所有数据源,这通常是一个批处理作业。
- 在增量构建 pipeline 中,我们需要处理在批处理作业完成后发生的更新。例如,卖家可能修改商品价格或商品描述以及库存量的变化。这些信息需要尽可能快的反馈在搜索结果中。增量构建 pipeline 通常是一个流式作业。
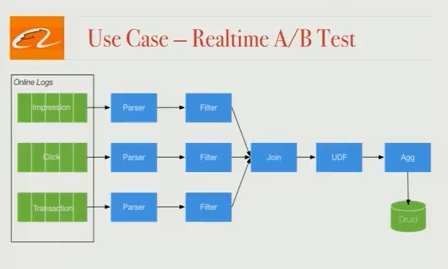
搜索算法实时 A/B 测试
我们的工程师会定期测试不同的搜索算法,并且需要尽可能快地评估出效果。现在这种评估每天运行一次,因为想实时分析效果,所以我们使用 Blink 构建了一个实时 A/B 测试框架。
在线日志(展示,点击,交易)由解析器和过滤器收集和处理,然后使用业务逻辑连接在一起。接下来聚合数据,将聚合结果推送到 Druid,在 Druid 内部,我们可以编写查询语句并对数据执行复杂的 OLAP 分析,并查看不同算法的效果。
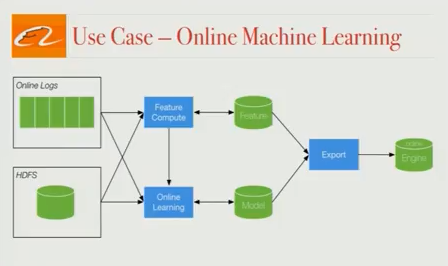
在线机器学习
在这部分中 Flink 有两个应用场景。首先,我们来讨论它在商品特征实时更新中的应用。阿里巴巴搜索排序中使用的一些商品特征包括商品 CTR,商品库存和商品点击总数。这些数据随时间而变化,如果可以使用最新的数据,我们就能为用户提供更相关的搜索结果排序。Flink pipeline 为我们提供在线特征更新,并大大提高了转化率。
其次,每年的特定日子(如光棍节),有些商品折扣力度很大,有时甚至高达50%。因此,用户行为也会发生很大的变化。交易量巨大,通常比我们在平时看到的高出很多倍。以前训练的模型在这个场景作用有限,因此我们使用日志和Flink 流式作业构建了在线机器学习模型,这个模型会将实时用户行为数据反馈到系统中。结果在这些不常见但非常重要的营销节日的转换率有了很大的提升。
Part 2: 选择一个框架来解决问题
选择 Flink 应用到搜索基础架构中,我们在四个方面做过评估。 Flink 在四个方面都满足我们的要求。
- 敏捷: 我们期望能够为整个(2 个 pipeline)搜索基础架构流程维护一套代码,因此需要一个高级的 API 来满足我们的业务逻辑。
- 一致性: 卖方或商品数据库发生的变化必须反馈在最终搜索结果中,因此搜索基础架构团队需要至少处理一次(at-least-once)的语义(对于公司中的一些其他 Flink 用例,要求正好一次(exactly-once)语义)。
- 低延迟: 当商品库存量发生变化时,必须尽快在搜索结果中得到体现。例如我们不想给售罄的商品给出很高的搜索排名。
- 成本: 阿里巴巴需要处理大量数据,以我们的集群规模,效率提高可以显著的降低成本。因此我们需要一个高性能、高吞吐量的框架。
一般来说,有两种方法来将批处理和流式处理统一起来。一种方法是将批处理作为基本出发点,在批处理框架上支持流式处理。这可能不符合真正意义上低延迟,因为用微批量处理(micro-batching)模拟流式处理需要一些固定的开销。因此,当试图减少延迟时,开销的比例也会相应增加。在我们的规模上,为每个微批量处理器调度 1000 个任务,需要重新建立连接并重新加载状态。因此在某种程度上,微批处理方法代价太高将变得没有意义。
Flink 从另一个角度来解决这个问题,即将流式处理作为基本出发点,在流式处理框架上支持批量处理,将批处理作为流式处理的一种特殊情况。使用这种方法,不会丢掉我们在批处理模式(批处理模式下流是有限的)下做出的优化,你仍然可以做一些批量处理上的优化。
Part 3: Blink 是什么?
Blink 是 Flink 的一个分支版本,我们做了一定的改进以满足阿里巴巴的一些特定需求。因此,Blink 在几个不同的集群上运行,每个集群有大约 1000 台机器,大规模集群的性能对我们来说非常重要。
Blink 的改进主要包括两个方面:
- Table API 更完整,因此我们可以使用相同的 SQL 进行批处理和流式处理。
- 更强大的 YARN 模式,但仍然 100%兼容 Flink 的 API 和更广泛的生态系统。
Table API
我们首先添加了对用户自定义函数 UDF 的支持,方便在 Flink 中实现独特的业务逻辑。我们还添加了一个流对流的 join 的功能,由于 Flink 对于状态比较好的支持,所以实现起来比较容易。我们添加了几个聚合函数以及滑动窗口的支持,最有趣的一个是 distinct_count。
(编辑注: FLIP-11 涵盖了与上述功能相关的一系列 Table API 和 SQL 改进,对该主题感兴趣的可以阅读)

接下来,我们将介绍运行时改进,可以分为四个不同的类别。
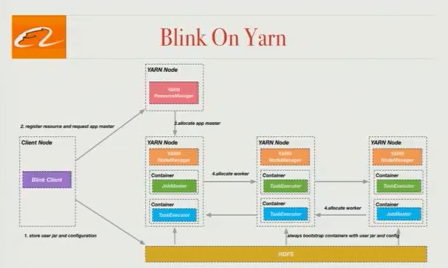
Yarn 上的 Blink
当我们开始项目时,Flink 支持 2 种集群模式:standalone 模式和 YARN 上的 Flink。在 YARN 模式中,作业不能动态请求和释放资源,而是需要预先分配所有需要的资源。不同的作业可能共享相同的 JVM 进程,这有利于资源利用和资源隔离。
Blink 中每个作业都有自己的 JobMaster,以根据作业需要请求和释放资源。并且不同的作业不能在同一个 Java 进程中运行,这将在作业和任务之间得到最佳隔离。阿里巴巴团队目前正在与 Flink 社区合作,将这项工作贡献给开放源代码,改进工作在 FLIP-6 (除了 YARN 之外还扩展到其他集群管理器)中得到了体现。
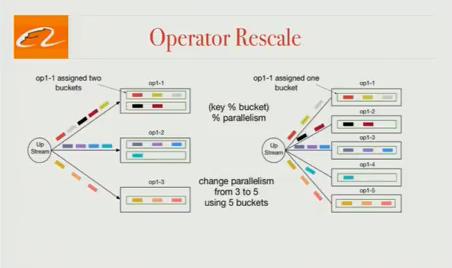
Operator 缩放
在生产环境中,我们的客户端可能需要改变 Operator 的并行性,但同时他们不想失去当前状态。当我们开始使用 Blink 时,Flink 不支持在保持状态的同时改变 Operator 的并行性。Blink 引入了“bucket”的概念作为状态管理的基本单位。有比任务更多的 bucket,并且每个任务将被分配多个 bucket。当并行性改变时,我们将重新分配任务的 bucket。 使用这种方法,可以改变 Operator 的并行性并维持状态。
(编者注:Flink 社区同时在 Flink 1.2 版本中解决了的这个问题 - 该功能在最新版本的主分支中可用。Flink 的“key groups”概念在很大程度上等同于上面提到的“bucket”,但是实现时使用的数据结构略有不同。更多信息,请在 Jira 查看 FLIR-3755 )
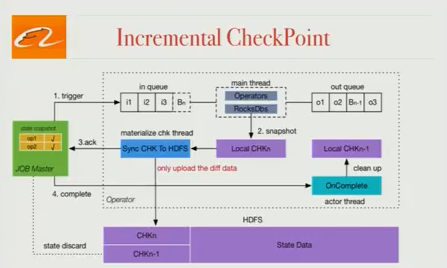
增量 Checkpoint
在 Flink 中,Checkpoint 操作分为两个阶段:在本地获取状态快照,然后将状态快照保存到 HDFS(或另一个存储系统),并且每个快照的整个状态存储在 HDFS 中。我们的状态数据太大了,这种方法是不可行的,所以 Blink 只存储修改的状态在 HDFS 中,这能够大大提高 Checkpoint 的效率。这种修改使我们能够在生产环境中使用很大的状态数据。
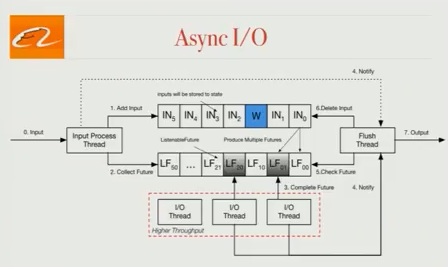
异步 I/O
我们的 job 在生产环境中很大瓶颈在访问外部存储器上,如 HBase。为了解决这个问题,我们引入了异步 I/O,我们将致力于为社区做出贡献,并在 FLIP-12 中有详细描述。
(编辑笔记:data Artisans 认为 FLIP-12 足够强大,可以在不久的将来在某个时间拥有自己的独立写入。所以我们只是简单地介绍一下这里的想法,如果你想了解更多,可以查看 FLIP writeup )
Part 4: 阿里巴巴的 Flink 未来计划是什么?
我们将继续优化我们的流式 job,特别是更好地处理临时倾斜(temporary skew)和慢节点(slow machines),同时不会对反压机制(backpressure)和故障快速恢复造成影响。正如在 Flink Forward 大会上大家讨论的,我们认为 Flink 作为批处理框架以及流式处理框架有着巨大潜力。我们正在努力利用 Flink 的批处理能力,希望在几个月内在生产环境中使用 Flink 批处理模式。
会议的另一个热门话题是流式 SQL,我们将继续在 Flink 中添加更多的 SQL 支持和 Table API 的支持。阿里巴巴的业务持续增长,这意味着我们的 job 会越来越大,确保我们可以扩展到更大的集群变得越来越重要。
非常重要的是,我们期待与社区继续合作,以便将我们的工作贡献回开源社区,以便所有 Flink 用户都能从我们加入 Blink 的工作中受益。我们期待着在 2017 年 Flink Forward 大会上向您介绍我们的进展情况。
查看英文原文: Blink: How Alibaba Uses Apache Flink?
感谢杜小芳对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




