
自网易云音乐机器学习平台上线以来,就承担了音乐内部推荐、搜索、直播、社交、算法工程等各个业务团队机器学习场景的需求, 这其中也遇到了很大的挑战,尤其是在分布式存储这块上,团队花费大量时间、精力,解决其中的核心问题。本文是网易数帆存储团队与网易云音乐机器学习平台与框架团队联合创作,向各位看官描述下,在机器学习场景,如何利用 Ceph 作为统一化的分布式存储,并基于此进行的相关的优化。

一、业务背景
随着互联网业务的飞速发展,大数据场景下的数据挖掘、算法模型,为业务发展提供精准的个性化能力,在这个过程中,ML Infrastructure 再度被人提起,以支持数以千亿计的个性化请求。其中,分布式存储在 ML Infrastructure 充当十分重要的角色,并且在不同场景中,为保证 ML Infrasturecture 的顺畅运行,面临不同挑战。
以网易云音乐(以下简称云音乐)为例,考虑到算法业务飞速发展,我们在 2019 年开始筹建的 Goblin 机器学习平台以降本增效为目标,整合了公司的相关资源,通过引入 K8s 系统提供弹性计算能力,引入 CephFS 提供共享分布式存储,为各部门的业务工程师们提供统一的 ML Infrastructure。我们基于 CephFS 实现核心功能如下:
为开发环境提供弹性存储。算法、工程人员在计算平台上申请存储资源存储代码、模型、训练样本,同时可以将相同的卷挂载到调试环境进行调试,而无需数据拷贝;特别是分布式开发调试,在引入 CephFS 之前,模型调试,特别是分布式训练的调试是十分痛苦的,需要将模型、样本数据分发到不同机器,训练结束还需要从各个开发机上将日志,模型等收集到开发机进行分析;引入 CephFS 之后,只需要为分布式训练任务挂载相同的数据卷,就可以直接进行调试,而训练过程中产生的日志、模型在开发机上都是即时可见的,这极大节省调试时间;
简化数据治理。在模型开发流程中,有很大一部分时间在进行数据治理;比如大量视频进行抽帧;引入 CephFS,可以将这些治理好的数据,直接作为数据卷挂载到训练任务,避免了繁琐的数据分发流程,并可以实现数据治理和训练分离,并行处理;
极大简化调度系统。在 ML Pipeline 中,算法人员在模型开发调试结束后,可以直接将模型所在数据卷配置到调度系统进行调度,极大简化模型上线流程。
二、痛点分析
CephFS 为机器学习平台提供了弹性的、可共享的、支持多读多写的存储系统,但开源 CephFS 在性能和安全性上还不能完全满足真实场景需求:
数据安全性是机器学习平台重中之重功能,虽然 CephFS 支持多副本存储,但当出现误删等行为时,CephFS 就无能为力了;为防止此类事故发生,要求 CephFS 有回收站功能;
集群有大量存储服务器,如果这些服务器均采用纯机械盘,那么性能可能不太够,如果均采用纯 SSD,那么成本可能会比较高,因此期望使用 SSD 做日志盘,机械盘做数据盘这一混部逻辑,并基于此做相应的性能优化;
作为统一开发环境,便随着大量的代码编译、日志读写、样本下载,这要求 CephFS 既能有较高的吞吐量,又能快速处理大量小文件。
针对以上关键性问题,云音乐 Goblin 机器学习团队和网易数帆(以下简称数帆)存储团队进行了多次探讨与沟通,开始共建基于 CephFS 的 ML Dev&Ops 实践。
三、深度优化实践
改进一:设计并实现基于 CephFS 的防误删系统
当前 CephFS 原生系统是没有回收站这一功能的,这也就意味着一旦用户删除了文件,那么就再也无法找回该文件了。
众所周知,数据是一个企业和团队最有价值的无形核心资产,有价值的数据一旦遭到损坏,对一个企业和团队来说很可能是灭顶之灾。2020 年,某上市公司的数据遭员工删除,导致其股价大跌,市值蒸发几十亿港元,更严重的是,合作伙伴对其信任降到了冰点,其后续业绩也遭到了巨大打击。
因此,如何保障数据的可靠性是一个关键问题。但是,CephFS 这一开源明星存储产品恰恰缺少了这一环。同时,云音乐 Goblin 平台项目组也多次反馈他们有误操作后导致文件丢失的经历。于是,防误删功能作为数帆存储团队与云音乐共建项目中的重点被提上了日程。经过团队的攻坚,最终实现了回收站这一防误删功能。
新开发的回收站在 CephFS 中初始化了 trashbin 目录,并将用户的 unlink/rmdir 请求通过后端转换成了 rename 请求,rename 的目的地就是 trashbin 目录。保证了业务使用习惯的一致性和无感。 回收站保持逾期定期清理的机制。恢复上,通过构建回收站内相关文件的目录树,然后 rename 回收站内的文件至目标位置来进行恢复。该问题的难点在于如何在分布式场景下保证文件系统的目录树。
改进二:混合存储系统的性能优化
通过长时间观察分析云音乐 Goblin 平台集群的 io 状态,我们发现该集群的 IO 模型存在短时间的压力突增情况。
同时,对于用户来说,其最关注的就是成本以及 AI 任务训练时长(存储 IO 时延敏感)。所以基于此我们与 Goblin 平台深入合作,并基于目前现状:对于公司内外部用户,如果是追求性能的用户,数帆存储团队这边提供的是全闪存盘的存储系统;如果是追求成本的用户,数帆存储团队这边提供的是全机械盘的存储系统。因此欠缺一种兼具成本与性能的存储系统方案,为此我们研发了这套基于 CephFS 的成本与性能领先业界水平的混合存储系统。该系统架构如下:
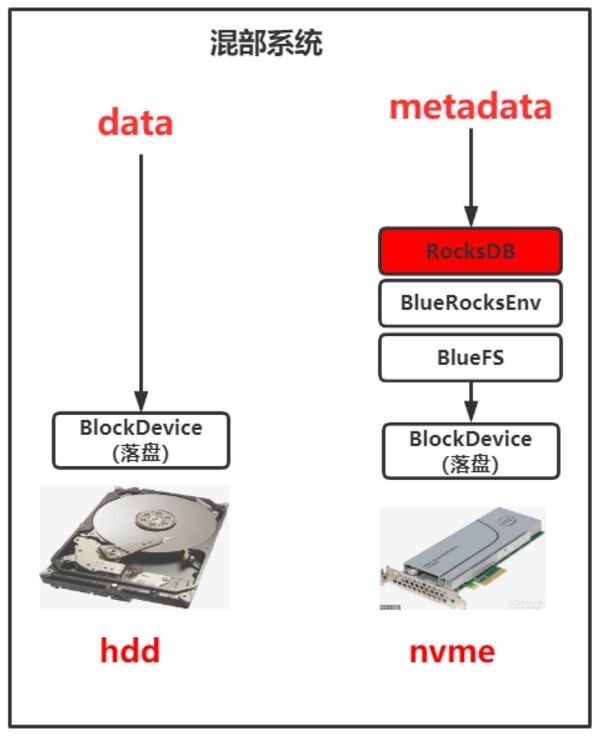
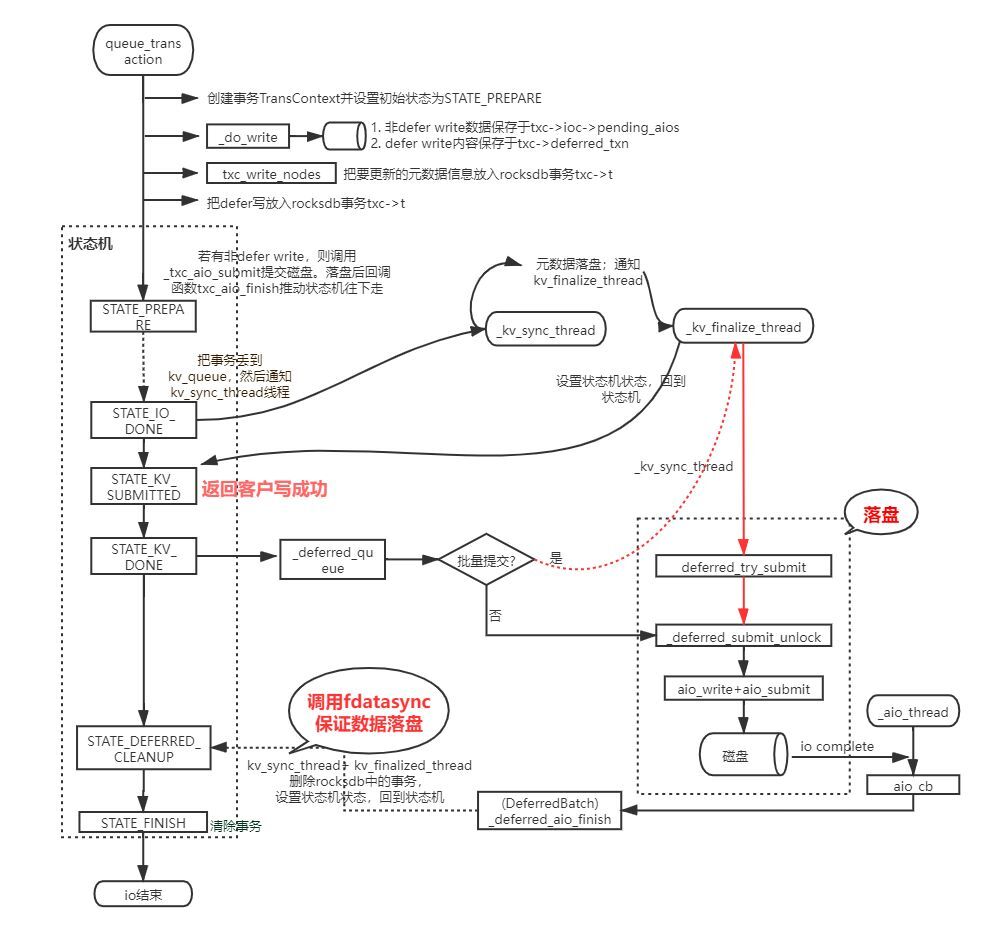
该架构也算是业界较常用的架构之一,但是有一个问题制约该混部架构的发展,即直接基于 Ceph 社区原生代码使用该架构,性能只比纯机械盘的集群好一倍不到。因此,数帆存储团队对 Ceph 代码进行了深度分析与改造,最终攻克了影响性能的两个关键瓶颈点:重耗时模块影响上下文以及重耗时模块在 IO 核心路径,如下图标红所示:
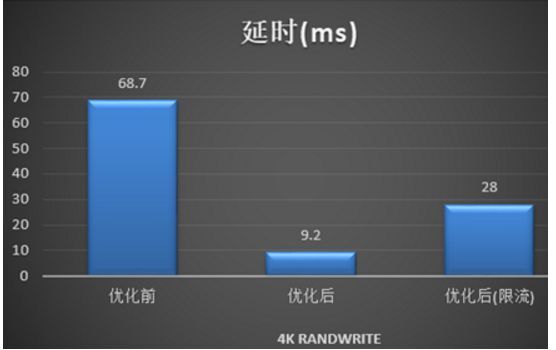
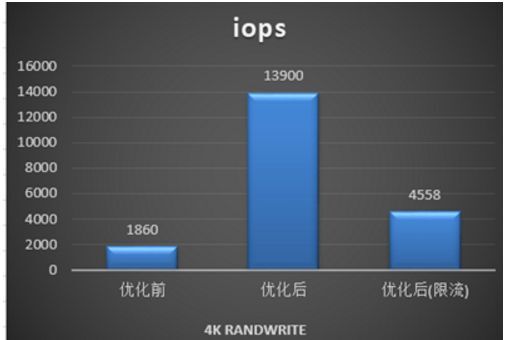
经过数帆存储团队的性能优化之后,该混部系统性能相较于社区原生版本有了显著提升,在资源充足的情况下,IO 时延以及 IOPS 等性能指标有七八倍的提升,当资源不足且达到限流后,性能也有一倍以上的提升。具体性能指标如下:
改进三:设计并实现了基于 CephFS 的全方位性能优化
CephFS 作为基本的分布式存储,简单易用。但是在很多场景下存在着性能问题。比如业务代码、数据管理、源码编译造成的卡顿、延迟过高;比如用户删除大目录耗时非常久,有时候甚至要达到数天;又比如因多用户分布式写模型导致的共享卡顿问题。这些问题严重影响着用户的使用体验。因此,数帆存储团队对性能问题进行了深入研究与改进,除了上面提到的在混合盘场景下的性能优化,我们在 CephFS 元数据访问以及大文件删除等多方面都进行了性能优化。
在大目录删除方面
我们开发了大目录异步删除功能:用户在日常业务中,经常会遇到需要删除大目录情况。这些目录一般包含几千万个文件,总容量在数个 TB 级别。现在用户的常规方式是使用 Linux 下的 rm -rf 命令,整个过程耗时非常久,有时甚至超过 24 小时,严重影响使用体验。因此,用户希望能提供一种快速删除指定目录的功能,且可以接受使用定制化接口。基于此,我们开发了大目录异步删除功能,这样使得大目录的删除对用户来说可以秒级完成。
在大文件 IO 方面
我们优化了大文件写性能,最终使得写带宽可以提升一倍以上,写延时可以下降一倍以上,具体性能指标如下:
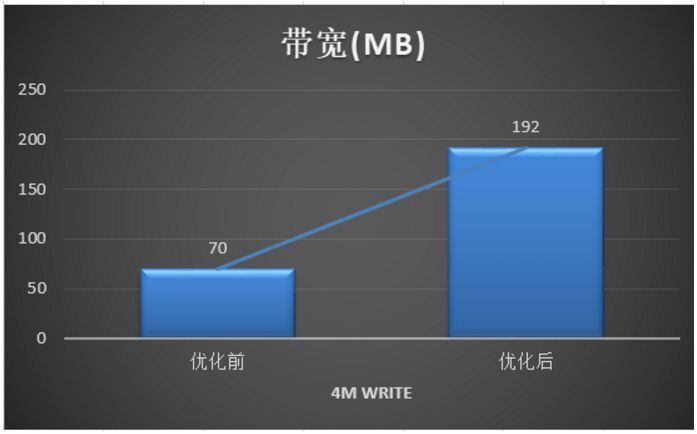
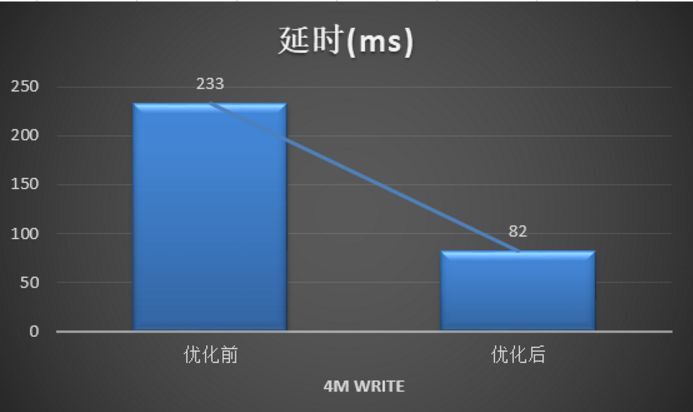
在优化用户开发环境 git 和 make 编译等都很慢方面
用户在容器源码目录中使用 git status 非常慢,耗时数十秒以上,同时,使用 make 编译等操作也异常慢。
基于该问题,杭州存储组对该问题进行了细致分析:通过 strace 跟踪简单的 git status 命令发现,流程中包含了大量的 stat, lstat, fstat, getdents 等元数据操作,单个 syscall 的请求时延一般在百 us 级别,但是数千个(对于 Ceph 源码项目,大概有 4K 个)请求叠加之后,造成了达到秒级的时延,用户感受明显。横向对比本地文件系统(xfs,ext4),通常每个 syscall 的请求时延要低一个数量级(十 us 级别),因此整体速度快很多。
进一步分析发现,延时主要消耗在 FUSE 的内核模块与用户态交互上 ,即使在元数据全缓存的情况下,每个 syscall 耗时依然比内核态文件系统高了一个数量级。接下来数帆存储团队通过把用户态服务转化为内核服务后,性能得到了数十倍的提升,解决了用户卡顿的这一体验。
元数据请求时延方面
经数帆存储团队分析发现,用户的很多请求时延较高原因是 open,stat 等元数据请求时延较高,因此,基于该问题我们采用了多元数据节点的方案,最终使得元数据的平均访问时延可以下降一倍以上,下图分别是优化前和优化后的元数据访问时延:
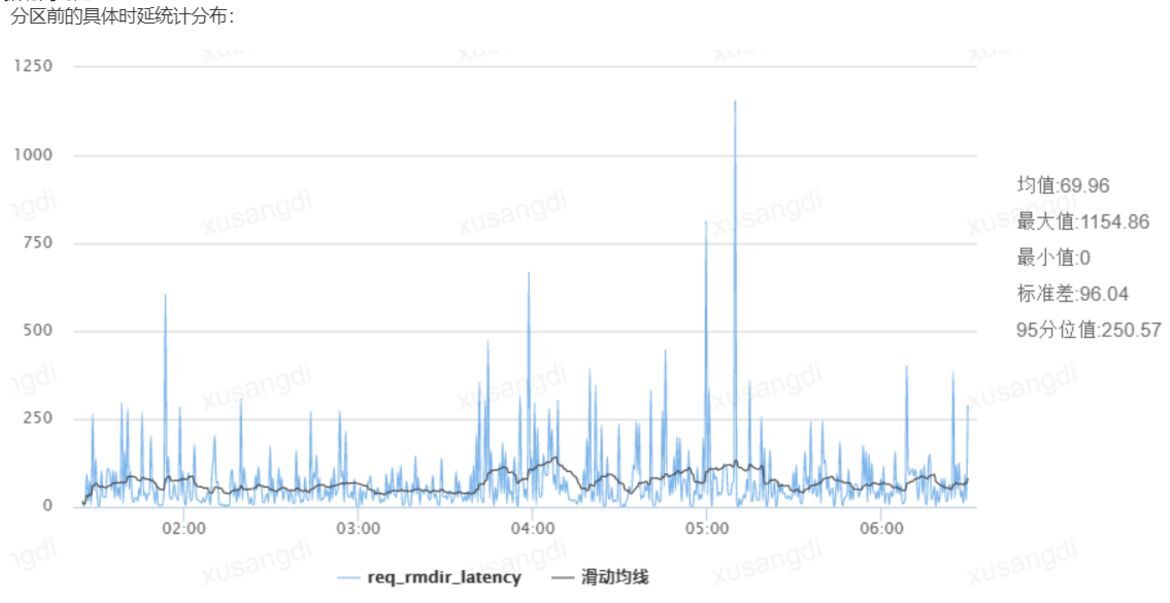
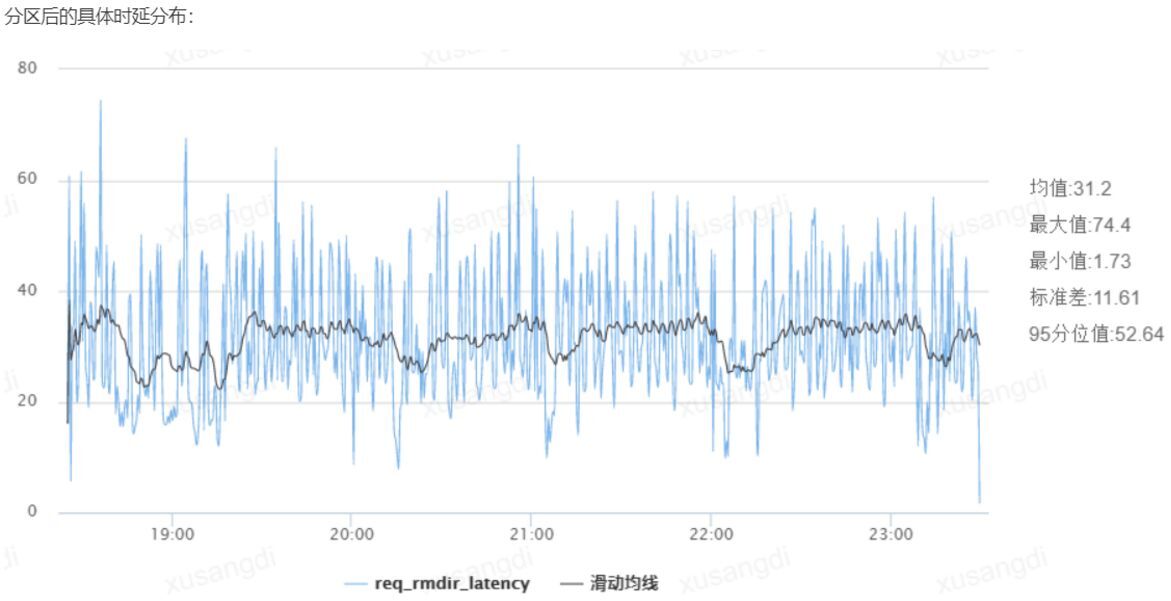
四、业务应用效果
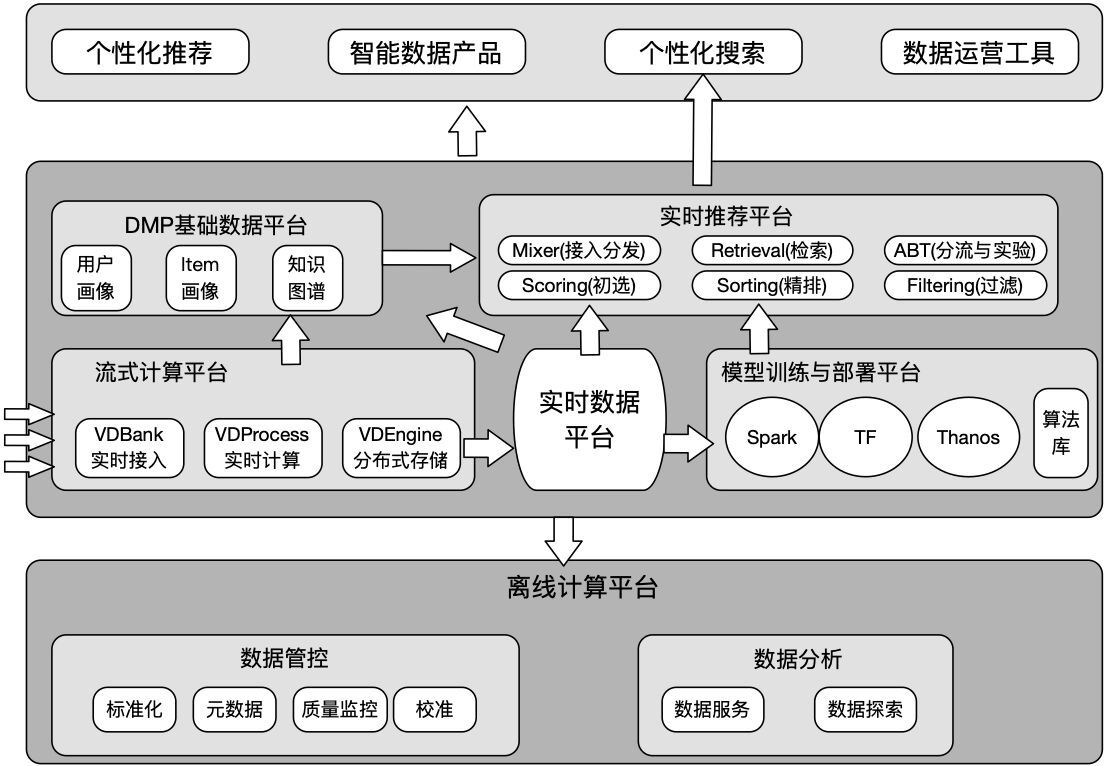
如上图为网易云音乐整体数据架构,而云音乐机器学习平台 Goblin 作为其中一个重要的组件服务于网易云音乐内部包括推荐、搜索、直播、社交、播客等核心业务场景,提供包括开发镜像环境定制、模型代码开发、模型服务开发、模型任务调度、模型相关文件线上服务推送等在内机器学习端对端开发流程,如下图所示:CephFS 作为其核心分布式存储,提供平台统一的文件存储、访问、共享的功能,具体使用场景包括:
统一集成开发环境:通过自定义镜像提供涉及到算法生命周期中的模型开发、线上服务开发等核心过程,Ceph 与用户以及所属团队绑定提供数据存取功能,通过优化 Ceph 小文件性能,能很好地支持大型项目编译、版本管理等功能;
开发与调度共享文件存储:通过用户以及所属团队与 CephFS 的用户卷的绑定,支持一键调度开发任务,保证运行环境、运行代码、数据的一致性;
大规模分布式任务中,不同角色的容器可挂载统一 Ceph 卷,达到运行日志、代码、数据的统一管理。
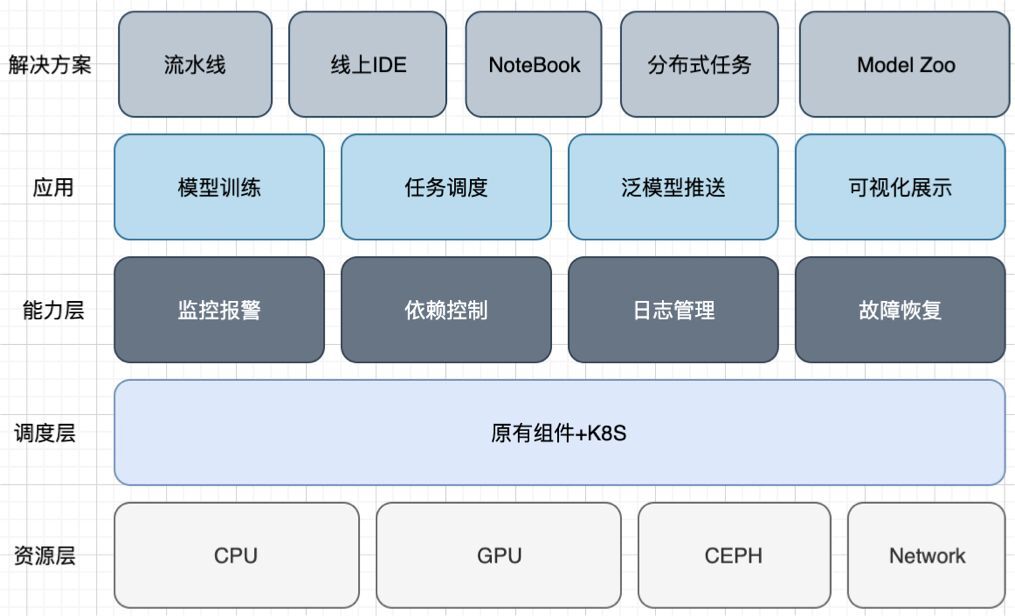
目前网易云音乐 Goblinlab 机器学习平台,平均每天处理 2000+个线上调度任务,存储池容量 1PB+, 数百个存储卷;每日平均 IOPS 数万,带宽 GB+ 。经过优化,累积节省模型训练时间上千小时。除此之外, CephFS 混合盘场景的使用在降本增效方面具有重要价值,按照当前 ML 集群 PB 级别的存储量,可以为业务节省数十万的成本。
更多 Ceph 相关文章见网易数帆存储团队《聊聊Ceph(分布式存储)》




