大家晚上好,我是 TalkingData 数据科学部的路瑶,很荣幸能和在座这么多位朋友聚在一起,今年的 7 月 -9 月,来自全球 70 多个国家和地区的约 2000 名选手,在全球影响力最大的算法竞赛平台上竞技,今天我们一起来回顾这场比赛。
在具体开始讲算法大赛之前,我想让大家跟我一起探讨这几个问题。
首先数据科学、人工智能、机器学习能做什么?其实这个问题相信大家已经有了一定了解,可以下棋、聊天、开车,甚至可以看病。从事数据科学的这些人有什么样的特质?在解决这些非常有挑战的问题的时候用的又是哪些方法?其实数据科学家之间经常也是喜欢过过招,那么又是在平台上面去表现的呢?相信通过我今天的分享大家会对这几个话题有更多的了解。
数据算法平台
我想先介绍一下数据算法平台,其实做数据算法竞赛的平台有很多,在国际影响力最大的一家非 Kaggle 莫属了,在 Kaggle 算法众包平台了举办了超过 1200 场比赛,他们为来自于工业界、政府、学术的各种各样的问题提供了数据科学的解决方案。注册在 Kaggle 上面的用户,现在已经超过 60 万,他们来自于全球 194 个国家,来自于各种各样的各行各业的背景,一般来说他们会是自己这个领域的专家。Kaggle 平台因为赛制的科学和开放的态度,也成为了很多重要数据科学竞赛的支持平台,比如说 KDD CUP,就多次在这个平台上举办。
在这样的平台里面会涌现很有名的竞赛和人物,同时也是现在非常火热方法最开始崭露头角的地方。比如在 2012 年由一家著名的制药公司 - 德国默克制药 - 支持的比赛,内容是新药发现,获得冠军的队伍的主要成员来自于多伦多大学,这支队伍的大部分队员可能大家并不熟悉,但是他们的教练我相信很多从事数据科学的人都不陌生,就是 Geoffrey Hinton。

这位大神的头像出来之后相信大家都猜到他们用的是什么方法了,是 Deep Learning,他们用这个方法获得了冠军赢得了其他选手。
这个比赛是在 2012 年,当时 Deep Learning 在业内有相当高的热度,但是没有像现在这么广泛的关注。这项比赛也是推动 Deep Learning 走向聚光灯下的功臣。
TalkingData Mobile User Demographics
TalkingData 为什么在这样的平台上举办比赛呢?我们希望借助开放的平台把我们的数据开放出去,开放给全世界最优秀的数据科学家,让他们用最聪明的办法解决最有挑战性的问题。
请允许我花一点时间介绍一下合作伙伴 Turi,这是一家机器学习公司,CEO Carlos Guestrin 教授是大规模机器学习,特别是大规模图计算的领军人物之一。这个公司有一个著名产品是 GraphLab,如果有做图计算的话,应该对这个产品不陌生。这家公司被苹果收购,基于这个团队现在建立了机器学习的部门。
7 月 13 号,Turi 举办了数据科学峰会,在峰会上面许多最优秀的数据科学家,比如说 Jeff Dean, Jure Leskovec 等等都参加了峰会。我们的比赛就在这样的峰会上面正式拉开了帷幕。
这个比赛的一开始,大概也就是三天的时间我们报名队伍就超过了 200,之后差不多一个月的时间报名队伍过千。具体是什么样的话题能够引起这么多数据科学家的兴趣呢?请看这张图。
本次比赛题目是通过行为习惯对移动用户人口属性进行预测,这个话题相信很多朋友都并不陌生,在许多实际业务场景里面,比方说广告投放、推荐系统、线下一些品牌的选址等等,我们都希望能知道用户的人口属性信息,特别是像年龄、性别一些基本的信息。很遗憾的是在现实中这些数据经常是缺失的,一个解决办法是通过行为数据把这个年龄性别预测出来。我们这次的比赛就是这样的挑战。
我们提供了大约 20 万用户的数据,分成了 12 个组,比如男性 22 到 25 岁,女性 30 到 35 岁等等。同时提供了用户行为属性,比如在什么样的时间点出现在什么样的地理位置上,他用的是什么品牌的手机,机型是什么,安装或者使用了什么 APP。选手要通过这些信息去推测用户是分在哪一个组里面。
我们的评估方式是什么呢?选手需要算出用户在不同分组上的概率,现实中一个用户只能在一个分组。理想状态下如果能算出这个概率是 1,其他是 0 的话,这个答案就是没有任何概率损失的。 一般来说,提交的答案中,某个用户会有或大或小的概率属于多个组别,这个时候就有概率上的损失,这个损失的高低代表答案的水平。我们的优化函数或者说评估指标就是下面的 Loss Function。

最终的比赛经过账号排重之后,有1689支队伍,1961个选手参加了比赛,一共有24000多次提交,这个数量是很高的。很值得一提的是有2811个 Kernels。Kernels 是什么呢?
Kaggle 是提供开发环境的,可以在上面写 Python,R 的代码。很多选手愿意把自己数据解读、数据可视化以及一些工具的使用、特征工程的方法去分享出来。我们这个比赛的分享气氛非常好,一共有这么多 Kernels,应该说在 Kaggle 历届的比赛中是分享气氛最浓的比赛之一。
这次比赛是由中国在 Kaggle 举办的最大的一次比赛,特别是吸引了很多顶级的 Kaggler 的参与。这里要介绍一下,Kaggle 平台建立了一个大榜,把所有的选手参加过所有的比赛以及综合考虑所有的成绩打了分,在 Kaggle 上有一个大的榜单。根据这个榜单,前 10 名的 Kaggle 里面有 7 名参加我们的比赛,前 20 名中有 14 名。还有很多虽然在现在的排名不高,但是他们是在 Kaggle 上面传诵良久的大神,已经沉寂了很久但是还是被我们比赛吸引了,这是让我们欣喜的一点。
最后有 70 多个国家提交了结果,大家猜一下选手最多的是来自于哪个国家?
最多的是美国。
第二是印度。第三是才中国含台湾、香港地区。
第四是俄罗斯。第五是英国。再后面是一些欧洲国家。
我觉得特别有意义的是,除了数据科学的强国之外,我们还收到了来自东南亚、南美、非洲等等许多国家提交的结果,是真正意义上的全球算法大赛。
Kaggle 竞赛作品方法解析
下面我们进入下一个话题,数据科学家的魔法。
选手们是用什么样的方法呢?我把它总结了五个方面,首先要解读数据,然后要做特征工程,做模型的调优,包括单独的模型和集成后的模型,要避免过拟和,还要选择更好的工具。
数据解读是重要的第一步。这次为了还原工业界数据是什么样的,也是参考了 Kaggle 和 Turi 的建议,并没有把集成和整理的特别干净的数据给选手。而是尽可能还原日志的形式,一个用户会在不同的条目里面都有信息。特别是我们的手机的品牌和型号用的是中文,这个时候选手需要把数据集成起来,去深入了解数据。
Kernels 里面涌现了大量的优秀的可视化的作品,这里我举几个例子,更多内容可以参考我之前发过的公众号文章(点击文章尾部“阅读原文”查看),第一次全球算法大赛战报。
我们先来一起看看这张图,图中显示的是在中国的数据,实际上数据是全世界都有的,我拿中国为例。右上角可以选择想看哪个内容,是年龄、性别还是机型,可以看到在中国,大部分设备集中在中东部——特别是东南沿海,设备的数量呈现相对较为密集的分布。那么这些地方的人用什么设备呢,从下图看出,西南边境地区有一定数量的 vivo,小米,然而在东部地区绿做一片的华为和三星两个大户,在那里却用户较少。
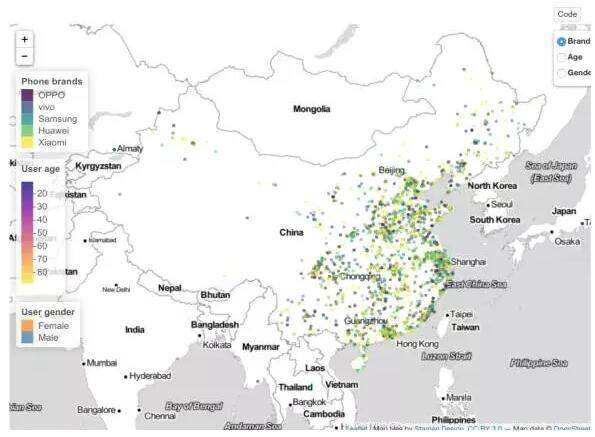
有很多的选手在讨论中国不同地区的发展状况,其中有一位选手给了非常丰富详细而且准确的介绍,只看内容的话会以为他是中国人,通过了解是一位法国人 。
我们再来看一张图。
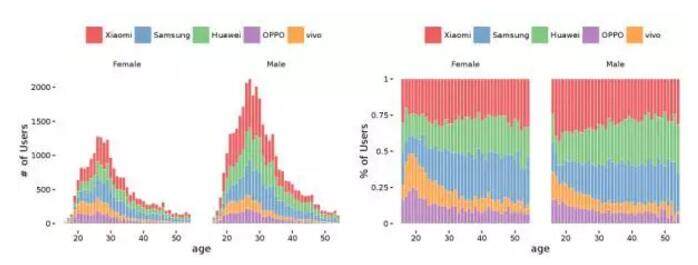
这是不同的品牌年龄上面的分布,左边是数量分布,右边是比例。左边的图是女性用户,右边的图是男性用户。比如说小米在不同的年龄段的差异不是很明显,但是三星很明显的是年龄大的用户会更喜欢。
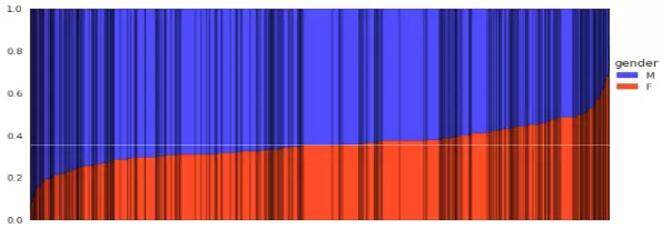
下面的这张图也很有意思,这是不同的机型在性别上面的分布,蓝色表示男性的比例,红色表示女性的比例,每一个黑线隔开的条是机型,条越宽说明用这个机型的总人数是越多的。仔细看会发现有条白线,这是表示如果是男女比例平衡的时候会在什么样的位置上。对于大部分的机型来说,真正男女完全平衡没有性别倾向的机型是很少的,大部分或多或少有一些倾向。尤其是在图的两侧有密集的黑线,是表示总用户数量虽然不多,但是有明显性别倾向的机型。
良好的数据解读可以给这些数据科学家很好的直觉以及对数据的认知,是成功的第一步。在下一步,是很多数据科学家都会花许多时间去做的特征工程。特征工程的重要性就不用多说了,在具体介绍他们做特征工程之前,再来看一下这个数据是什么样子的。
这个表格介绍了本次比赛的数据结构。
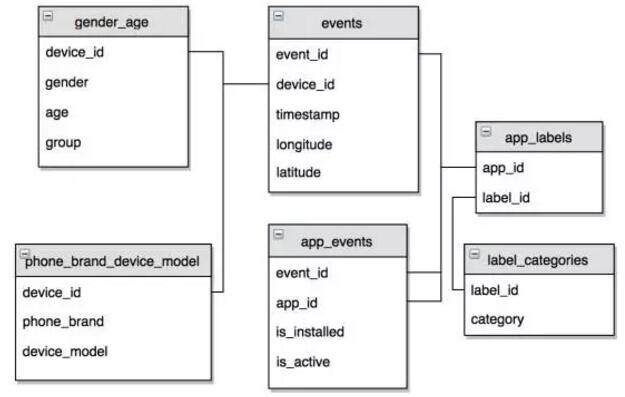
首先是年龄性别分组,每个用户用一个 ID 来表示。一个用户的行为是在一系列的 Events 里面,每一个 Event 里面的信息是包括这一个 ID 在什么样的时间点出现在什么样的经纬度上,APP 安装了哪些、使用了哪些,还包括用的是什么品牌和机型的手机。APP 的 ID、用户 ID 包括经纬度都做了严格和科学的脱敏。
APP 看到的是脱敏后的 ID,选手对 APP 本身没有什么概念,为了让选手更好地解读数据,我们给了一些标签,比如说是社交、游戏等等,总共有 1000 多个标签在里面。
我们看一下选手提取了的有什么特征,比如用户是在什么时间活跃,在休息日还是工作日,是白天还是晚上。数据还包括海外数据,有时差的问题。用户有了轨迹,他们的分布是什么样子的,是聚集在某一块,还是说聚集在几个点,他们之间有多远。甚至是说这个人是不是经常在世界各地去飞。同时,常出现的位置是在中国的东南沿海还是在西北,这些地点又有什么样的特性。
另外这些 APP 安装了一些、使用了一些,有一些是安装了但是好长时间没有用,这又能给我们提供什么样的信息。这些特征的取值是很有学问的,是取 0-1 值还是更加具体的权重。刚才所说的有 1000 多个 APP 的标签,有一些用户 APP 多一些,有一些 APP 少一些,有些 APP 本身有一个标签,也有一些有很多标签,这些标签又能够构建出什么特征。
最后介绍一个有想象力的做法 。当预测出结果之后,结果是不是可以作为特征反馈到模型里面。比如预测年龄和性别的分组,性别相对是好预测的,准确率高一些。预测之后把性别特征返回来是不是可以提高年龄的预测,年龄准确率会低一些,但是一些特殊的年龄段特征比较明显。如果把这些找出来之后再返回到模型里面,是不是也能提高整体的结果。
当然类似的方法还有很多了,通过这些介绍,大家可以看到特征工程考验的不仅仅是数据科学家,在数据方法上、处理方法上面的技巧,还考验这个人的常识、专业领域的知识、是不是有很好的直觉、是不是有很好的想象力。
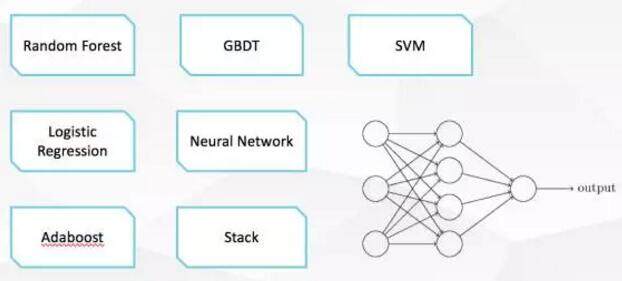
做完特征工程之后就到了调模型的环节了,我这里列出了在这次竞赛中提及比较多的模型,有些是集成的方法。一般数据科学家最花时间的除了特征工程就是调参数,在单一模型调参的时候,最简单的初始参数怎么选?是给一个随机值,还是给一个特别的值,这对于收敛速度有可能会有很大的影响。在模型集成上面学问就更多了,比如说我先用神经网络举例子,我们知道在神经网络里面要设计神经元,要知道每一层有多少个、有多少层,在模型集成里面也需要有类似的思想。这些模型分成几层,谁和谁是并联、谁和谁是串联关系的,如果是串联关系的,下一层是处理上一层什么样的信息,是直接处理结果,还是处理误差或者是什么。模型调节是非常考验数据科学家经验和技巧的部分。
有了好的模型、有了好的特征,提交了结果,在排名上很靠前,是不是这个事就搞定了,就可以拿到奖金了?这真的不一定。因为还有一个大的敌人叫做过拟合,这是非常注意的一个问题。一个过拟合的方法在特定的数据集里面会表现得非常好,但是这个数据集稍微一变,模型性能就迅速下降。在参加 Kaggle 比赛的时候,这个更加要注意。
Kaggle 里面分测试集和训练集,训练集是把所有的信息都显示了,利用这些信息在测试集里做预测。选手可以看到的一个榜单,是公开榜单,而另外有一个只有管理员身份可以看到私密榜单。最终比赛成绩是私密榜单所决定的,公开的榜单只是给选手成绩的参考。
公开榜单是怎么生成的呢?是测试集大约 1/4 到 1/3 很小部分的数据,Kaggle 不限制次数可以不停提交,在公开榜单排得很高,有可能在私密网站排名很惨。要解决这个问题怎么办呢?Kaggle 的老同志说永远要做 cross validation。
最后,选的好的工具也是很重要的,我们在比赛里面涌现的工具也非常多,只简单介绍两个。一是 Keras。赛题设置和比赛方法是非常适合深度学习的。Keras 是用 Python 写的适合做深度学习开发的高层工具,封装了许多的模型库,所以你可以像搭积木一样很快地搭出神经网络的原型。它可以在 Tensorflow 和 Theano 上面运行,并行化做得也不错,可以在 CPU 或 GPU 上运行。在这次竞赛里面表现得也很好。
另外一个,Xgboost,应该是 Kaggle 的老朋友了,XGboost 处女秀是在 2014 年的 Higgs Boson 信号识别比赛里面拿到了冠军,在此之后许多比赛都会有人提到这个方法。它本身在算法的调优和并行化上做的都非常优秀,可以在 Spark、Hadoop 等不同平台上去运行。
最后再来回顾一下这次比赛中总结的几个方法,要去做数据解读、特征工程、调模型、避免过拟合,最后要选择合适的工具。在比赛中,来自于工业界的选手这次表现得非常优秀,排名前几名都是工业界的选手并且保持很长时间。我们猜测正是因为他们在这几方面,特别在模型调优和特征构建上面比学生选手会拥有更多的经验,当然同时他们也有更好的计算资源。
最后一个问题,这些数据科学家是什么样的人?
这个比赛一共的时间差不多有 2 个月,在这个期间我每天都会看榜单,看他们在论坛里讨论的问题。这些数据科学家的形象也给我留下了深刻的印象,最大的印象是他们真的非常开放,而且互相帮助的意愿很强。有很多新手说这个中文读不出来怎么办,这个方法卡在了某一个成绩上应该怎么办,什么方法应该怎么用等等,都会得到满意的解答。同时这些人是非常聪明,并且有想象力,而且他们愿意去解决实际的问题。特别是面对像我们这样数据比较稀疏,也还算是比较 Dirty 的数据,里面还有中文,他们表现出非常兴奋的态度。
在这个过程当中,大家关于不同观点、方法也有过很激烈的争论。一共在论坛里面差不多有 2000 多条讨论,数量好像不是很多,但是有大量的大篇幅详尽的讨论,在讨论过程中表现的礼貌和理智也给人留下了很深刻的印象。
这些数据科学家们非常勤奋,像我之前提到 2 千多人、2 万多次提交,特别是排在前面的数据科学家们有超过 100 次的提交,比赛只有不到 2 个月,提交次数会超过 100 多次。每次看榜单,每次可以看到几个小时之前提交的,一般是八九个小时之前,一般不会超过 48 个小时一定会有提交。也正是这些最勤奋的人得到了最好的结果。
在这次比赛中,TalkingData 为全世界的数据科学家提供了来自于工业界的数据,也提供了有价值的业务问题。同时我们也对这些科学家的专业,以及科学精神表达了敬意。于是也收获了全世界最优秀科学家的 Mind and Heart,最后谢谢大家来参加我的分享,也欢迎更多的数据科学家参与到我们的团队中。
Q&A
Q1:能不能讲一下冠军的思路?
路瑶:几位优秀选手的方案我也是这周才拿到的,代码还没有仔细看。接下来两周的时间我们会和选手们电话交流。不过现在可以简单说下思路。
本次比赛的评估方式是非常适合深度学习的,很多选手也都是用的这个思路。像我刚才提到的,排名靠前的几位选手用 Keras 搭建神经网络 +XGboost 做集成。
有些方案并没有做特别多的特征工程,而是尽量使用原始的信息,也有的方案在像我们刚才提到的,对特征进行了进一步的提取 。在我们提供的数据中,应用列表是最有预测效果的数据。
大家知道深度学习本身理论并不完善,深度神经网络的调参非常 tricky,很多技巧都很靠经验,所以也很难说到底哪种方法就一定能提高成绩。
Q2:请问数据竞赛常用算法?分布式算法充电给点建议?
路瑶:这次比赛数据量并不大,配置好一点的笔记本就能做,对分布式要求不高,本次比赛在分布式方法上目前没有看到特别突出的方法。 分布式计算这个话题很大,一时不知道从哪说起,XGboost 可以在 GPU 上计算,在分布式上做了很突出的优化,感兴趣的朋友可以多了解一下。
Q3:关于 TalkingData 这次活动的地址提供一下,想详细了解一下
路瑶:活动地址 https://www.kaggle.com/c/talkingdata-mobile-user-demographics。
Q4:老师您说赛题很适合用深度学习方法,请问具体怎么用到深度学习的呢,是用来学习特征,还是用的 RNN 之类的算法呢
路瑶:这个问题参考前面两个问题的答案。
Q5:最后一个问题 TalkingData 的机器学习 / 数据挖掘这块,都是用 spark 在做吗?
路瑶:spark 是很重要的工具,不过不限于 spark。
讲师介绍
路瑶,TalkingData 数据科学家。前阿里巴巴算法专家,瑞士洛桑联邦理工大学访问学者,清华大学自动化系硕士。2016 年加入 TalkingData 任数据科学家,负责图算法、时间序列分析等方向。TalkingData 全球算法大赛技术负责人。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




