系列导读:《无痛的增强学习入门》系列文章旨在为大家介绍增强学习相关的入门知识,为大家后续的深入学习打下基础。其中包括增强学习的基本思想,MDP 框架,几种基本的学习算法介绍,以及一些简单的实际案例。
作为机器学习中十分重要的一支,增强学习在这些年取得了十分令人惊喜的成绩,这也使得越来越多的人加入到学习增强学习的队伍当中。增强学习的知识和内容与经典监督学习、非监督学习相比并不容易,而且可解释的小例子比较少,本系列将向各位读者简单介绍其中的基本知识,并以一个小例子贯穿其中。
在第一篇中,我们以蛇棋为例,主要介绍了增强学习的核心流程,那就是 Agent 与 Environment 的交互。
在第二篇中,我们曾简单介绍了计算最优策略的方法——先得到同一状态下不同行动的价值估计,再根据这些价值估计计算出最优的策略选择。
在第三篇中,详细介绍了采用这个战术实现的算法——策略迭代法(Policy Iteration)。
4 价值迭代
4.1 N 轮策略迭代
上一节我们介绍了策略的迭代的算法,它可以解决蛇棋的策略规划问题,帮助我们更好地完成游戏。从算法中可以看出,算法的主要时间都花费在策略评估上,对于一个简单的问题来说,这部分时间还算好,但是对于复杂的问题来说,这个步骤的时间实在有些多了。一个最直接的想法就是——我们能不能缩短这部分的时间?比方说,我们大概估计出当前策略下每个状态的价值函数就好,这样已经可以帮助我们找出最优的策略了,再做更精细的评估实际上并不必要?这就是这一节的主角——价值迭代法的思想来源。
回到前面的代码中,为了测量算法的用时,我们将在代码中注入一些计时的功能:
from contextlib import contextmanager
import time
@contextmanager
def timer(name):
start = time.time()
yield
end = time.time()
print '{} COST:{}'.format(name, end - start)
然后将策略迭代的代码进行改进:
def policy_iteration(self):
iteration = 0
while True:
iteration += 1
with timer('Timer PolicyEval'):
self.policy_evaluation()
with timer('Timer PolicyImprove'):
ret = self.policy_improvement()
if not ret:
break
对于有 10 个梯子的问题,下面我们固定随机数,代码将变为:
def policy_iteration_demo():
np.random.seed(0)
env = Snake(10, [3,6])
agent = TableAgent(env.state_transition_table(), env.reward_table())
agent.policy_iteration()
print 'return_pi={}'.format(eval(env,agent))
print agent.policy
可以得到以下的时间消耗记录:
policy evaluation proceed 94 iters.
Timer PolicyEval COST:0.139311790466
Timer PolicyImprove COST:0.00118112564087
policy evaluation proceed 62 iters.
Timer PolicyEval COST:0.0768580436707
Timer PolicyImprove COST:0.000974178314209
policy evaluation proceed 46 iters.
Timer PolicyEval COST:0.0550677776337
Timer PolicyImprove COST:0.00197505950928
Iter 3 rounds converge
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
从时间记录可以看出,PolicyEval 的时间远大于 PolicyImprove,所以策略评估确实是花时间最大的地方。那么我们就从这里改起,首先限制策略评估的迭代轮数,上面的测试中,策略迭代进行了 94 轮,我们把它降低至 50 轮可以么?
将策略评估限制在 50 轮,我们得到了如下的输出(有省略)
policy evaluation proceed 46 iters.
Timer PolicyEval COST:0.0480210781097
Timer PolicyImprove COST:0.00193190574646
Iter 3 rounds converge
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
继续激进一点,把迭代轮数改到 10 呢?
policy evaluation proceed 11 iters.
Timer PolicyEval COST:0.011638879776
Timer PolicyImprove COST:0.00103783607483
Iter 4 rounds converge
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
那么剩下的就是最最激进的,把迭代轮数改到 1 呢?
policy evaluation proceed 2 iters.
Timer PolicyEval COST:0.00178599357605
Timer PolicyImprove COST:0.00106501579285
Iter 7 rounds converge
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
我们发现,随着策略评估的迭代轮数不断降低,算法的总迭代数在升高。当策略评估的迭代轮数在 94 时,算法总迭代数为 3;而策略评估的迭代轮数在 1 时,算法总迭代数变成了 7,但依然不影响它称为这些实验中最快的算法。
实际上,我们就可以把迭代轮数为 1 的策略评估称为价值迭代。为什么呢?在策略迭代问题中,每一轮算法过后,策略不一定是最优的,但价值一定是当前策略下的收敛值;而对于价值迭代来说,每一轮算法过后,价值都不一定能够收敛,同时策略在随着价值的更新而更新,但是价值一旦收敛,策略也随之收敛。所以此时我们关注的重点在于价值的计算上。我们希望一次性计算好价值函数,这样就能一步到位计算处最优策略来。
4.2 从动态规划的角度谈价值迭代
实际上上面的解释还是不够清晰。策略迭代对大家来说还是比较容易理解的,因为它的思想很清晰。而价值迭代算法看上去似乎是一个“贪心”算法,让人很不放心。一个最直接的问题就是:为什么策略和价值可以在都不完美的情况下不断改进达到最优?想要回答好这个问题,我们需要从“贪心”的对立面——动态规划去解释。
前面我们一直站在了策略的角度做分析,并且把价值迭代法定义为一轮迭代的策略迭代法,那么对于一轮迭代的算法,它的形式能否做一个改变呢?我们知道策略评估这一步完成了下面的计算:
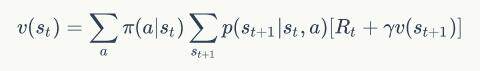
而接下来的一步完成了策略改进的计算:
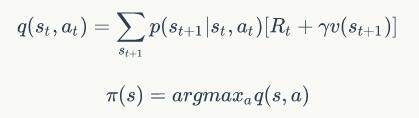
我们能不能将这三个步骤结合起来,成为一个关于价值函数的更新步骤呢?
我们将后两个公式合并起来,可以得到:
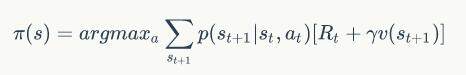
由于最优策略的存在,实际上策略最终的选择是单一的,也就是说对于每一个状态,最优策略会采取某一种行动,这种行动不会比其他行动差。所以我们可以认为:
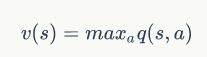
也就是说:
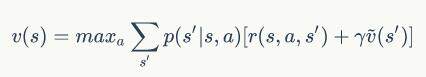
经过这样的转换,我们终于将视角转换到了价值函数上。可以看到公式的左右两边都出现了价值函数,其中等号左边的价值函数是迭代更新后的价值函数,等号右边的价值函数是上一轮的价值函数。这时,这个公式就展示出动态规划的“气质”了。
动态规划类的问题相信很多人在学习算法的时候都接触过。计算机算法的一个主体思想就是分解问题,将问题划分成一个个小问题,然后用小规模下的解决方案解决小规模的问题。动态规划的思路也基本相同,它有两个核心的特点:最优子结构和重复子结构。
所谓的最优子结构,就是说一个子问题的最优解是可以得到的。对应蛇棋的问题,我们可以考虑“从某个位置出发行走一步能够获得的最大奖励”这个问题,由于只走一步,这个问题很容易计算。
所谓的重复子结构,就是说一个更大的问题是由一些小问题组成的,而求解不同的大问题时可能会用上同一个子问题,这样子问题被重复利用,从而减少了计算量。对应蛇棋的问题,我们进一步考虑“从某个位置出发行走两步能够获得的最大奖励”这个问题,这时的问题就可以利用上前面的子问题,于是计算公式就变成了:
”某个位置走两步的最大奖励“=max([这一步的奖励 + 从到达位置出发走一步最大奖励 for 走法 in 可能的走法])
上面这个公式就用到了最优子结构的性质,而求解完所有位置也就会用到重复子结构的性质。同样地,由于打折率的存在,价值函数的绝对值存在上界,价值函数在这样更新中最终会得到收敛。
4.3 价值迭代的实现
价值迭代的代码如下所示:
def value_iteration(self):
iteration = 0
while True:
iteration += 1
new_value_pi = np.zeros_like(self.value_pi)
for i in range(1, self.state_num): # for each state
value_sas = []
for j in range(0, self.act_num): # for each act
value_sa = np.dot(self.table[j, i, :], self.reward + self.gamma * self.value_pi)
value_sas.append(value_sa)
new_value_pi[i] = max(value_sas)
diff = np.sqrt(np.sum(np.power(self.value_pi - new_value_pi, 2)))
if diff < 1e-6:
break
else:
self.value_pi = new_value_pi
print 'Iter {} rounds converge'.format(iteration)
for i in range(1, self.state_num):
for j in range(0, self.act_num):
self.value_q[i,j] = np.dot(self.table[j,i,:], self.reward + self.gamma * self.value_pi)
max_act = np.argmax(self.value_q[i,:])
self.policy[i] = max_act
使用和上一节策略迭代同样的实验,它也能得到同样的结果,那么它的时间呢?
Iter 3 rounds converge
Timer PolicyIter COST:0.190360069275
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
Iter 94 rounds converge
Timer ValueIter COST:0.0884821414948
return_pi=84
[0 1 1 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0
0 0 0 0 1 1 1 1 0 0 0 0 1 1 1 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 1 1 0 0 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0]
可以看出价值迭代还是会比常规的策略迭代快一些,但是它并没有本节中的一轮策略迭代快。一轮策略迭代的时间为:0.023058891296。这是为什么呢?我们还能不能让时间更快?让我们在下一节解答这个问题。
作者介绍
冯超,毕业于中国科学院大学,猿辅导研究团队视觉研究负责人,小猿搜题拍照搜题负责人之一。2017 年独立撰写《深度学习轻松学:核心算法与视觉实践》一书(书籍链接),以轻松幽默的语言深入详细地介绍了深度学习的基本结构,模型优化和参数设置细节,视觉领域应用等内容。自 2016 年起在知乎开设了自己的专栏:《无痛的机器学习》,发表机器学习与深度学习相关文章,收到了不错的反响,并被多家媒体转载。曾多次参与社区技术分享活动。




