
设备接入服务(IoTDA)是华为云物联网平台的核心服务,IoTDA 需要一款可靠的消息中间件,经过对比多款消息中间件的能力与特性,Apache Pulsar 凭借其多租户设计、计算与存储分离架构、支持 Key_Shared 模式消费等特性成为华为云物联网消息中间件的首选。本文介绍了 Pulsar 在华为云物联网的上线历程以及上线过程中遇到的问题和相应的解决方案。
华为云设备接入服务介绍
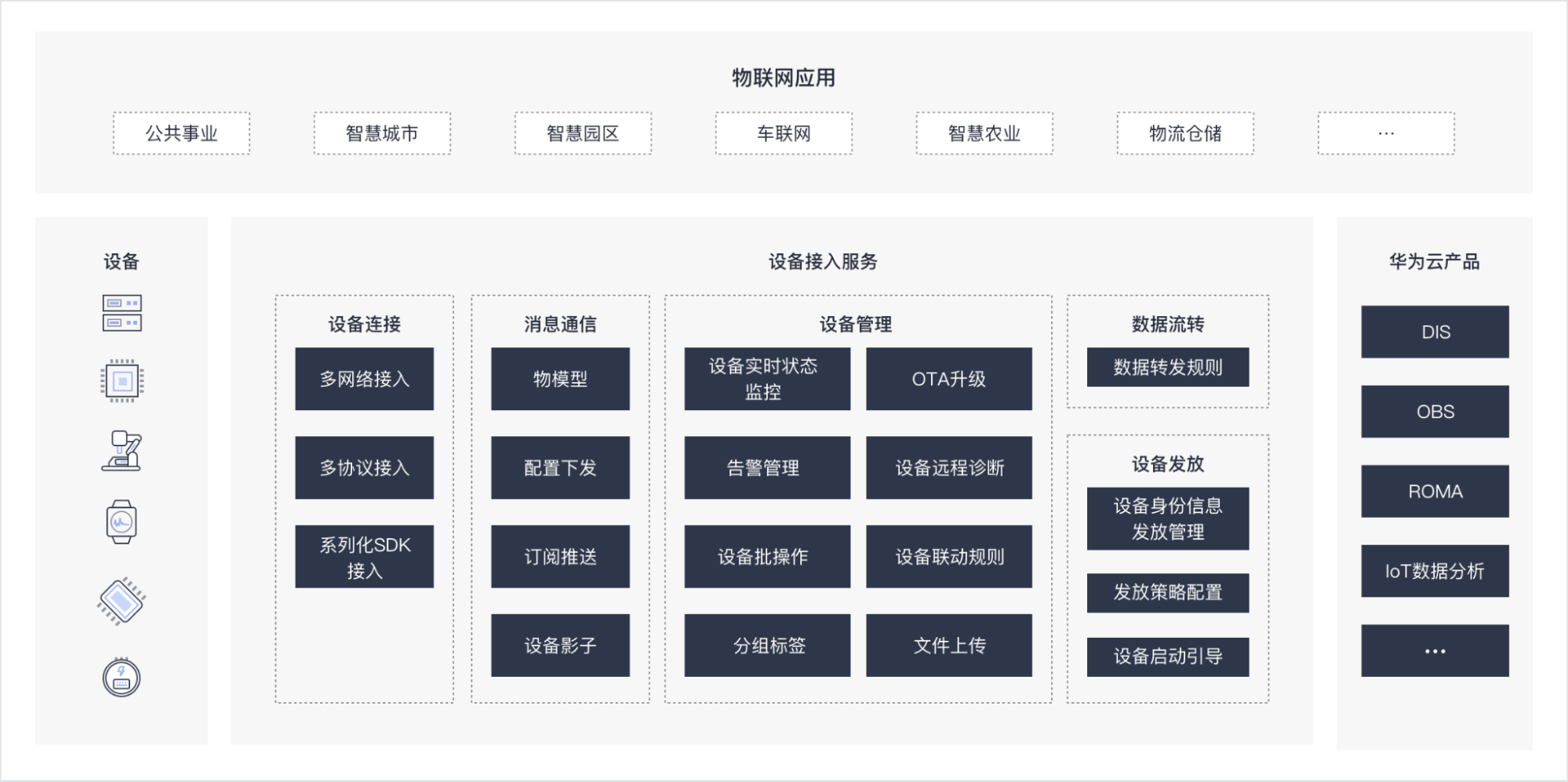
设备接入服务(IoTDA)具备海量设备连接上云、设备和云端双向消息通信、数据流转、批量设备管理、远程控制和监控、OTA 升级、设备联动规则等能力。下图为华为云物联网架构图,上层为物联网应用,包括车联网、智慧城市、智慧园区等。设备层通过直连网关、边缘网络连接到物联网平台。目前华为云物联网联接数超过 3 亿,IoT 平台竞争力中国第一。
数据流转指用户在物联网平台设置规则后,当设备行为满足规则条件时,平台会触发相应的规则动作来实现用户需求,例如对接到华为云其他服务,提供存储、计算、分析设备数据的全栈服务,如 DIS、Kafka、OBS、InfluxDb 等,也可以通过其他通信协议和客户的系统对接,如 HTTP、AMQP。在这些动作中,物联网平台主要做客户端或服务端。根据用户类别,可以将使用场景分为三类:
体量较大的客户一般会选择推送到消息中间件(如 Pulsar、Kafka)上,并在云上构建自己的业务系统进行消费处理。
中长尾客户通常会选择将数据推送到自己的数据库(如 MySQL)中进行处理,或由自己的 HTTP 服务器接收数据进行处理。
更轻量级的客户会选择通过 AMQP 协议创建简单的客户端进行连接。
原推送模块的痛点
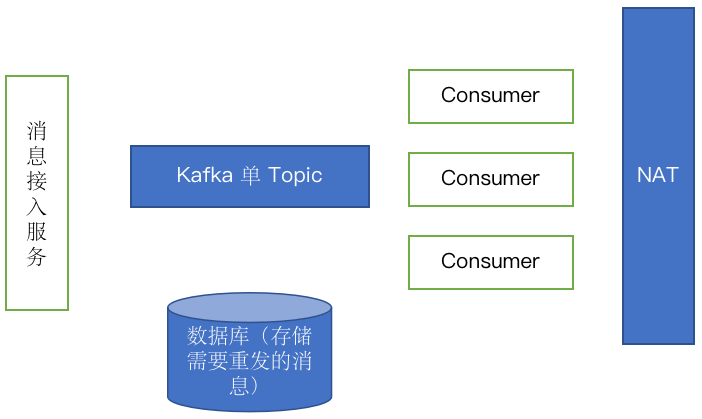
原推送模块采用 Apache Kafka 方案,这种运行模式本身有一些弊端,且扩容操作复杂,为开发和运维团队带来负担。此外,原推送模块支持客户端类型和服务端类型的推送,但不支持 AMQP 推送,其架构图如下。Consumer 不断从 Kafka 中拉取消息,并将发送失败的消息存入数据库,等待重试。这种运行模式带来了很多问题:
即使很多客户的服务器不可达,consumer 仍需要从 Kafka 拉取消息(因为 Kafka 只有一个 topic)并尝试发送。
无法根据单用户来配置消息的存储时间和大小。
有些客户的服务器能力差,无法控制将消息推送到单个客户的速率。
Topic 数量
2020 年 5 月,为提升产品的竞争力,我们计划让客户通过 AMQP 协议来接收流转数据。AMQP 协议的客户端接入更加复杂,而客户可能会将 AMQP 客户端集成在手机端,每天定时上线两小时,这种情况下,我们需要保证客户在使用时不会出现数据丢失,因此要求消息中间件支持多于规则数量的 topic(有些客户单规则下数据量大,单 topic 无法支撑)。目前,我们的规则数量已超过 3 万,预计很快会达到 5 万,并且还会继续增长。
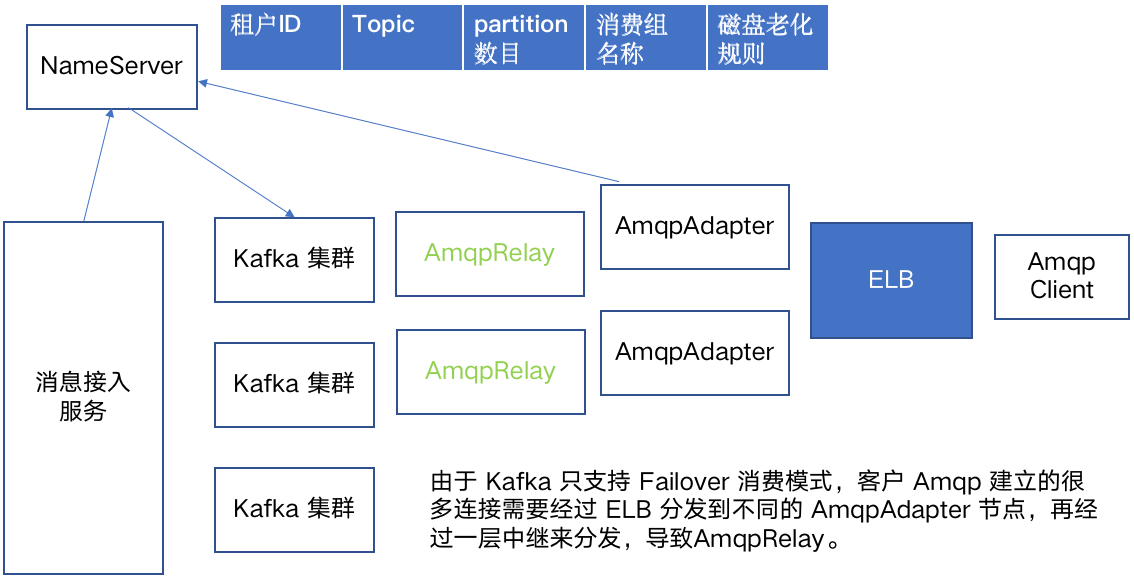
Kafka topic 在底层占用文件句柄,且共享 OS 缓存,无法支持量级较大的 topic,友商的 Kafka 最多可以支撑 1800 个 topic。我们要想支持规则数量级别的队列,就必须维护多个 Kafka 集群,上图是我们基于 Kafka 设计的方案。
基于 Kafka 方案的实现会非常复杂,我们不但要维护多个 Kafka 集群的生命周期,还要维护租户和 Kafka 集群之间的映射关系,因为 Kafka 不支持 Shared 消费模型,还需要两层中继。另外,如果某个 Kafka 集群上 topic 数量已达到上限,但由于流转数据过多,需要对 topic 进行扩容。在这种情况下,不迁移数据就无法对原有集群进行扩容。整体方案非常复杂,对开发和运维都是很大的挑战。
为什么选择 Pulsar
为了解决我们在 Kafka 方案中的问题,我们开始调研市面上流行的消息中间件,了解到 Apache Pulsar。Apache Pulsar 是云原生的分布式消息传递和流平台,原生支持诸多优秀特性,其独有 Key_Shared 模式和百万 topic 支持是我们迫切需要的特性。
Pulsar 支持 Key_Shared 模式。如果 Pulsar 的单个分片支持 3000 QPS,而客户的一个 AMQP 客户端只支持 300 QPS。这种情况下,最佳解决方案是使用 Pulsar 的共享模式,启用多客户端连接,即同时连接 10 个客户端来处理数据。如果使用 Failover 模式,则需要扩到 10 个 partition,造成资源的浪费。
Pulsar 可扩展至百万级 topic。我们可以将一个规则对应于一个 Pulsar topic。AMQP 客户端上线时,即可从上一次消费到的位置开始读取,保证不丢消息。
Pulsar 是基于云上的多租户设计,而 Kafka 更偏向于在系统和系统之间对接,单租户、高吞吐。Pulsar 考虑了基于 K8s 的部署,整体部署易实现;Pulsar 的计算与存储分离,扩容操作简单,扩容时 topic 中断时间短,重试可实现业务无中断;并且支持共享订阅类型,更灵活。我们从不同维度对 Pulsar 和 Kafka 做了对比,结果如下:
Pulsar 不仅能够解决 Kafka 方案的不足,其不丢消息的特性更是完美契合了我们的需求,所以我们决定试用 Pulsar。
初版设计
最初设计时,我们想在客户端类型和服务端类型都使用 Key_Shared 消费模式。下图为客户端类型(以 HTTP 为例)的设计,客户每配置一条数据流转规则,我们就在 Pulsar 中创建一个 topic,consumer 消费 topic,再经过 NAT 网关推送到客户的 HTTP 服务器。
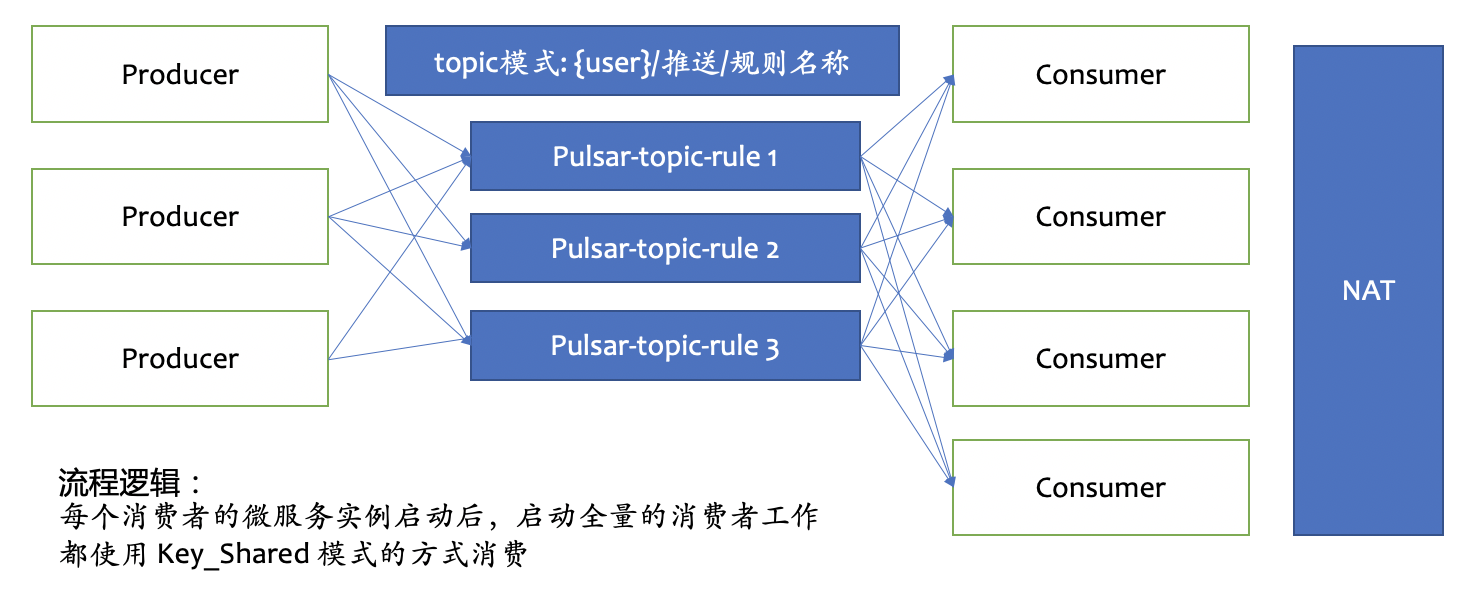
服务端类型(以 AMQP 为例)推送的设计如下图。如果没有连接到 AMQP 客户端,即使启动 consumer 拉取到数据,也无法进行下一步处理,所以当客户端通过负载均衡组件连接到对应的 consumer 微服务实例后,该实例才会启动对应 topic 的 consumer 进行消费。一个 AMQP 的连接对应一个 consumer。
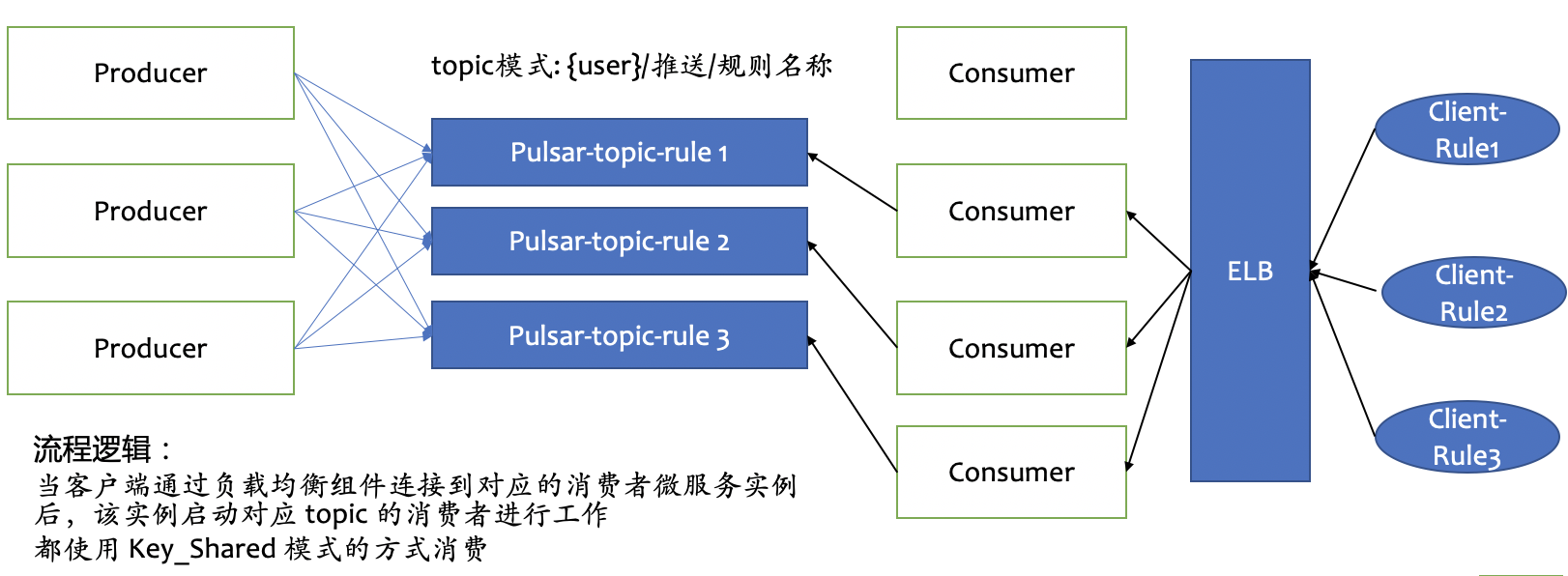
Pulsar 集群内 topic 单 partition 吞吐量有限,当单个客户的规则数据量超过吞吐量时,比如当 topic 的性能规格在 3000 左右,而客户的预估业务量为 5000 时,我们需要为 topic 扩容 partition。为了避免重启 producer/consumer,我们将 autoUpdatePartition 参数设置为 true,使 producer/consumer 可以动态感知到 partition 的变化。
初版设计在测试中遇到的问题
在对初版设计方案进行测试时,我们发现这一方案存在一些问题,主要体现在以下三个方面:
客户端类型推送使用上述设计,微服务实例和 consumer 之间形成了网状关系。假设我们有 1 万个客户规则和 4 个微服务实例,则会有 4 万个消费-订阅关系。单个微服务实例在内存中同时有 1 万个 consumer,consumer 接收队列大小是吞吐量和内存消耗的关键,但不易配置。若配置偏大,则在异常场景下,consumer 发送不出 HTTP 消息,会造成大量消息积压在 consumer 中,导致 consumer 内存溢出。假设有 1000 个 consumer,网络忽然断开 5 分钟,则这 5 分钟内的消息都会积压在接收队列中;若配置偏小,consumer 与服务器之间通信的效率较低,影响系统性能。
在 Pulsar 或生产消费服务滚动升级的场景中,频繁请求 topic 元数据对集群压力较大(请求个数为实例个数与 topic 数量的乘积)。
autoUpdatePartition对系统资源影响大。如果每个 topic 都开启autoUpdatePartition,按照默认设置,每个 topic 每分钟发送一次 ZooKeeper 请求。
我们在 Pulsar 社区反馈了这个问题,StreamNative 团队同学给了大力支持和帮助,建议我们对客户进行分组后再根据需要设置 autoUpdatePartition 参数。有了社区的支持,我们决定做相应改进后开始策划上线方案。
上线方案
我们的客户大致分为两种,一种是在业务忙时有大量数据上行的推送繁忙用户,其特点是一个分片可能满足不了诉求,用户数量少;另一种是业务比较稳定,数据量中等,其特点是一个分片足够,用户数量多。
我们根据建议对用户进行分组,单独部署推送繁忙用户的工作负载,合设业务量中等的用户。目前,我们根据客户的业务容量,通过 SRE 在配置中心手动分组,未来会根据实时统计数据自动分组。对业务进行分组不仅可以大大减少 topic 和 consumer 之间的组合数量,也降低了重启时请求元数据的次数。另外,两类用户客户端参数在分组后也不完全相同,首先,autoUpdatePartition 仅在繁忙用户 topic 中开启;其次,两组工作负载的接收队列大小不同。

部署
我们采用容器化部署方式为两类用户部署:使用 deployment 方式部署 broker,StatefulSet 方式部署 BookKeeper 和 ZooKeeper。部署场景包括云端部署和边缘部署,不同的部署方式对可靠性、性能要求不同,我们设置的部署参数如下:
在部署时,我们发现:
topic 之间 EnsembleSize 和 Write Quorum Size(Qw)参数相同时,写入性能最好。
云端消息量大,如果副本数量为 2,则要冗余 100% 部署,副本数量为 3 时只需冗余 50%。
Pulsar 调优方案
上述方案已在半年前顺利上线,并且我们还在测试环境中测试了 5 万 topic,10 万消息每秒的场景,测试期间遇到了一些问题,并根据具体情况采取了调优方案,详情参阅 Pulsar 5 万 topic 调优。本节重点介绍延迟、端口和改进建议。
降低生产/消费延迟
通过使用测试工具,我们发现消息的整体端到端延迟较大。
为了方便定位问题,我们开发了单 topic debug 特性。在海量消息场景下,无论是测试环境还是生产环境,都不会轻易在 broker 开启全局 debug。我们在配置中心增加了一个配置,只为配置列表中的 topic 打印详细的 debug 信息。在单 topic debug 特性的配合下, 我们很快发现消息的最大延迟出现在 producer 发送消息后与服务端接收到消息之间,可能的原因是 netty 线程数配置偏小。
但增加 netty 线程数并没有完全解决这一问题,我们发现单 jvm 实例仍会出现性能瓶颈,上文提到按用户的数据量大小分组后,小用户组需要服务大约四万个 topic,由于需要启动相同数量级的 consumer,导致启动慢(进而导致升级时中断时间长)、内存队列不足、调度复杂等。我们最后决定再对小用户组进行哈希分组,每个实例负责约 1 万个 consumer,顺利解决了生产消费延迟大的问题。
采用 8080 端口连接 broker
我们采用 8080 端口而非 6650 端口连接 broker,原因主要有两点:
日志详细,而且大部分发向 8080 的请求是元数据请求,有助于排查问题,易监控。比如,jetty 的 requestLog 很容易监测到创建 topic 失败、创建 producer 超时等事件。
可以隔离数据请求和元数据请求,避免在 6650 端口繁忙时影响创建 topic、删除 topic 等操作。
和 6650 端口相比,8080 端口效率性能较差。在 5 万 topic 量级下,升级 producer/consumer 或 broker 时,需要创建大量的 producer/consumer,对 8080 端口产生大量请求,如 partitions、lookup 请求。我们通过增加 Pulsar 中 jetty 线程数,顺利解决了这一问题。
改进建议
Pulsar 在运维和应对问题方面能力稍有欠缺,我们希望 Pulsar 能在以下几个方面有所改进:
自动调整客户端参数,如发送队列大小、接收队列大小等,这样使用万级 topic 时会更加流畅。
在遇到到不可恢复的错误(如操作 ZooKeeper 失败)时,暴露 API 接口,使我们可以轻松对接到云上的告警平台。
在运行期间通过日志追踪单个 topic,支持运维人员使用 kibana 工具结合业务日志快速定位、解决问题。
采样追踪 Pulsar 内部生产、消费、存储的关键节点,并将数据导出到 APM 系统(如 Skywalking),更易剖析优化性能。
在负载均衡策略中考虑 topic 数量。
BookKeeper 监控时只监控了 data 盘的使用率,没有监控 journal 盘的使用率。
结语
从初次接触 Pulsar 到设计上线,我们一共用了三四个月的时间。上线后,Pulsar 一直运行稳定、性能良好,帮助我们实现了预期目标。Pulsar 大大简化了华为云物联网平台数据接入服务的整体架构,平稳低延迟地支撑着我们的新业务,因此我们可以专注于提升业务竞争力。由于 Pulsar 的优秀性能,我们也将其应用于数据分析服务,并且希望可以在业务中使用 Pulsar Functions,进一步提升产品竞争力。
作者简介
张俭,华为云 IoT 高级工程师。关注云原生、IoT、消息中间件、APM。




