
专题介绍
2009 年,Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab),并于 2010 年开源。2013 年,Spark 捐献给阿帕奇软件基金会(Apache Software Foundation),并于 2014 年成为 Apache 顶级项目。
如今,十年光景已过,Spark 成为了大大小小企业与研究机构的常用工具之一,依旧深受不少开发人员的喜爱。如果你是初入江湖且希望了解、学习 Spark 的“小虾米”,那么 InfoQ 与 FreeWheel 技术专家吴磊合作的专题系列文章——《深入浅出 Spark:原理详解与开发实践》一定适合你!
本文系专题系列第一篇。
自 Spark 问世以来,已有将近十年的光景。2009 年,Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab),并于 2010 年开源。2013 年,Spark 捐献给阿帕奇软件基金会(Apache Software Foundation),并于 2014 年成为 Apache 顶级项目。
2014,是个久远的年代,那个时候,大数据江湖群雄并起,门派林立。论内功,有少林派的 Hadoop,Hadoop 可谓德高望重、资历颇深,2006 年由当时的互联网老大哥 Yahoo!开源并迅速成为 Apache 顶级项目。所谓天下武功出少林,Hadoop 的三招绝学:HDFS(分布式文件系统)、YARN(分布式调度系统)、MapReduce(分布式计算引擎),为各门各派武功绝学的发展奠定了坚实基础。论阵法,有武当派的 Hive,Hive 可谓是开源分布式数据仓库的鼻祖。论剑法,有峨眉派的 Mahout,峨眉武功向来“一树开五花、五花八叶扶”,Mahout 在分布式系统之上提供主流的经典机器学习算法实现。论轻功,有昆仑派的 Storm,在当时,Storm 轻巧的分布式流处理框架几乎占据着互联网流计算场景的半壁江山。
Spark 师从 Hadoop,习得 MapReduce 内功心法,因天资聪慧、勤奋好学,年纪轻轻即独创内功绝学:Spark Core —— 基于内存的分布式计算引擎。青,出于蓝而胜于蓝;冰,水为之而寒于水。凭借扎实的内功,Spark 练就一身能为:
Spark SQL —— 分布式数据分析
Spark Streaming —— 分布式流处理
Spark MLlib —— 分布式机器学习
Spark GraphX —— 分布式图计算
自恃内功深厚、招式变幻莫测,Spark 初涉江湖便立下豪言壮语:One stack to rule them all —— 剑锋直指各大门派。小马乍行嫌路窄,大鹏展翅恨天低。各位看官不禁要问:Spark 何以傲视群雄?Spark 修行的内功心法 Spark Core,与老师 Hadoop 的 MapReduce 绝学相比,究竟有何独到之处?
Hadoop MapReduce
欲探究竟,还需从头说起。在 Hadoop 出现以前,数据分析市场的参与者主要由以 IOE(IBM、Oracle、EMC)为代表的传统 IT 巨头构成,Share-nothing 架构的分布式计算框架大行其道。传统的 Share-nothing 架构凭借其预部署、高可用、高性能的特点在金融业、电信业大放异彩。然而,随着互联网行业飞速发展,瞬息万变的业务场景对于分布式计算框架的灵活性与扩展性要求越来越高,笨重的 Share-nothing 架构无法跟上行业发展的步伐。2006 年,Hadoop 应运而生,MapReduce 提供的分布式计算抽象,结合分布式文件系统 HDFS 与分布式调度系统 YARN,完美地诠释了“数据不动代码动”的新一代分布式计算思想。
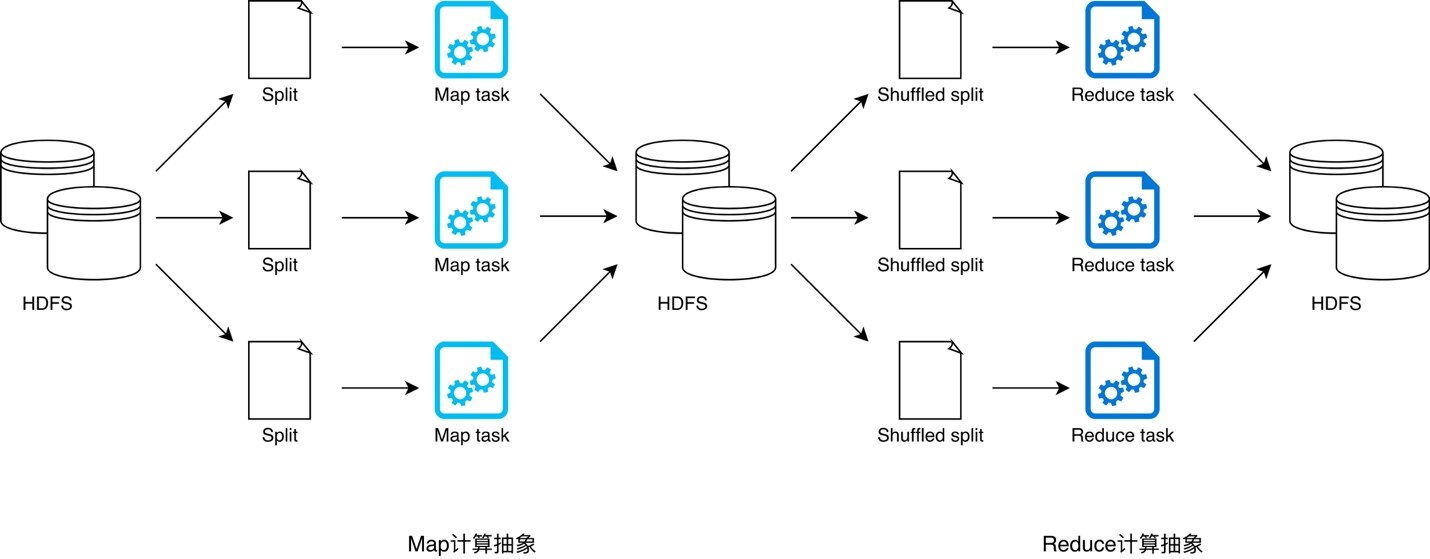
顾名思义,MapReduce 提供两类计算抽象,即 Map 和 Reduce。Map 抽象用于封装数据映射逻辑,开发者通过实现其提供的 map 接口来定义数据转换流程;Reduce 抽象用于封装数据聚合逻辑,开发者通过实现 reduce 接口来定义数据汇聚过程。Map 计算结束后,往往需要对数据进行分发才能启动 Reduce 计算逻辑来执行数据聚合任务,数据分发的过程称之为 Shuffle。MapReduce 提供的分布式任务调度让开发者专注于业务逻辑实现,而无需关心依赖管理、代码分发等分布式实现问题。在 MapReduce 框架下,为了完成端到端的计算作业,Hadoop 采用 YARN 来完成分布式资源调度从而充分利用廉价的硬件资源,采用 HDFS 作为计算抽象之间的数据接口来规避廉价磁盘引入的系统稳定性问题。
由此可见,Hadoop 的“三招一套”自成体系,MapReduce 搭配 YARN 与 HDFS,几乎可以实现任何分布式批处理任务。然而,近乎完美的组合也不是铁板一块,每一只木桶都有它的短板。HDFS 利用副本机制实现数据的高可用从而提升系统稳定性,但额外的分片副本带来更多的磁盘 I/O 和网络 I/O 开销,众所周知,I/O 开销会严重损耗端到端的执行性能。更糟的是,一个典型的批处理作业往往需要多次 Map、Reduce 迭代计算来实现业务逻辑,因此上图中的计算流程会被重复多次,直到最后一个 Reduce 任务输出预期的计算结果。我们来想象一下,完成这样的批处理作业,在整个计算过程中需要多少次落盘、读盘、发包、收包的操作?因此,随着 Hadoop 在互联网行业的应用越来越广泛,人们对其 MapReduce 框架的执行性能诟病也越来越多。
Spark Core
时势造英雄,Spark 这孩子不仅天资过人,学起东西来更是认真刻苦。当别人都在抱怨老师 Hadoop 的 MapReduce 心法有所欠缺时,他居然已经开始盘算如何站在老师的肩膀上推陈出新。在 Spark 拜师学艺三年后的 2009 年,这孩子提出了“基于内存的分布式计算引擎”—— Spark Core,此心法一出,整个武林为之哗然。Spark Core 最引入注目的地方莫过于“内存计算”,这一说法几乎镇住了当时所有的初学者,大家都认为 Spark Core 的全部计算都在内存中完成,人们兴奋地为之奔走相告。兴奋之余,大家开始潜心研读 Spark Core 内功心法,才打开心法的手抄本即发现一个全新的概念 —— RDD。
RDD
RDD(Resilient Distributed Datasets),全称是“弹性分布式数据集”。全称本身并没能很好地解释 RDD 到底是什么,本质上,RDD 是 Spark 用于对分布式数据进行抽象的数据模型。简言之,RDD 是一种抽象的数据模型,这种数据模型用于囊括、封装所有内存中和磁盘中的分布式数据实体。对于大部分 Spark 初学者来说,大家都有一个共同的疑惑:Spark 为什么要提出这么一个新概念?与其正面回答这个问题,不如我们来反思另一个问题:Hadoop 老师的 MapReduce 框架,到底欠缺了什么?有哪些可以改进的地方?前文书咱们提到:MapReduce 计算模型采用 HDFS 作为算子(Map 或 Reduce)之间的数据接口,所有算子的临时计算结果都以文件的形式存储到 HDFS 以供下游算子消费。下游算子从 HDFS 读取文件并将其转化为键值对(江湖人称 KV),用 Map 或 Reduce 封装的计算逻辑处理后,再次以文件的形式存储到 HDFS。不难发现,问题就出在数据接口上。HDFS 引发的计算效率问题我们不再赘述,那么,有没有比 HDFS 更好的数据接口呢?如果能够将所有中间环节的数据文件以某种统一的方式归纳、抽象出来,那么所有 map 与 reduce 算子是不是就可以更流畅地衔接在一起,从而不再需要 HDFS 了呢?—— Spark 提出的 RDD 数据模型,恰好能够实现如上设想。
为了弄清楚 RDD 的基本构成和特性,我们从它的 5 大核心属性说起。
对于 RDD 数据模型的抽象,我们只需关注前两个属性,即 dependencies 和 compute。任何一个 RDD 都不是凭空产生的,每个 RDD 都是基于一定的“计算规则”从某个“数据源”转换而来。dependencies 指定了生成该 RDD 所需的“数据源”,术语叫作依赖或父 RDD;compute 描述了从父 RDD 经过怎样的“计算规则”得到当前的 RDD。这两个属性看似简单,实则大有智慧。
与 MapReduce 以算子(Map 和 Reduce)为第一视角、以外部数据为衔接的设计方式不同,Spark Core 中 RDD 的设计以数据作为第一视角,不再强调算子的重要性,算子仅仅是 RDD 数据转换的一种计算规则,map 算子和 reduce 算子纷纷被弱化、稀释在 Spark 提供的茫茫算子集合之中。dependencies 与 compute 两个核心属性实际上抽象出了“从哪个数据源经过怎样的计算规则和转换,从而得到当前的数据集”。父与子的关系是相对的,将思维延伸,如果当前 RDD 还有子 RDD,那么从当前 RDD 的视角看过去,子 RDD 的 dependencies 与 compute 则描述了“从当前 RDD 出发,再经过怎样的计算规则与转换,可以获得新的数据集”。
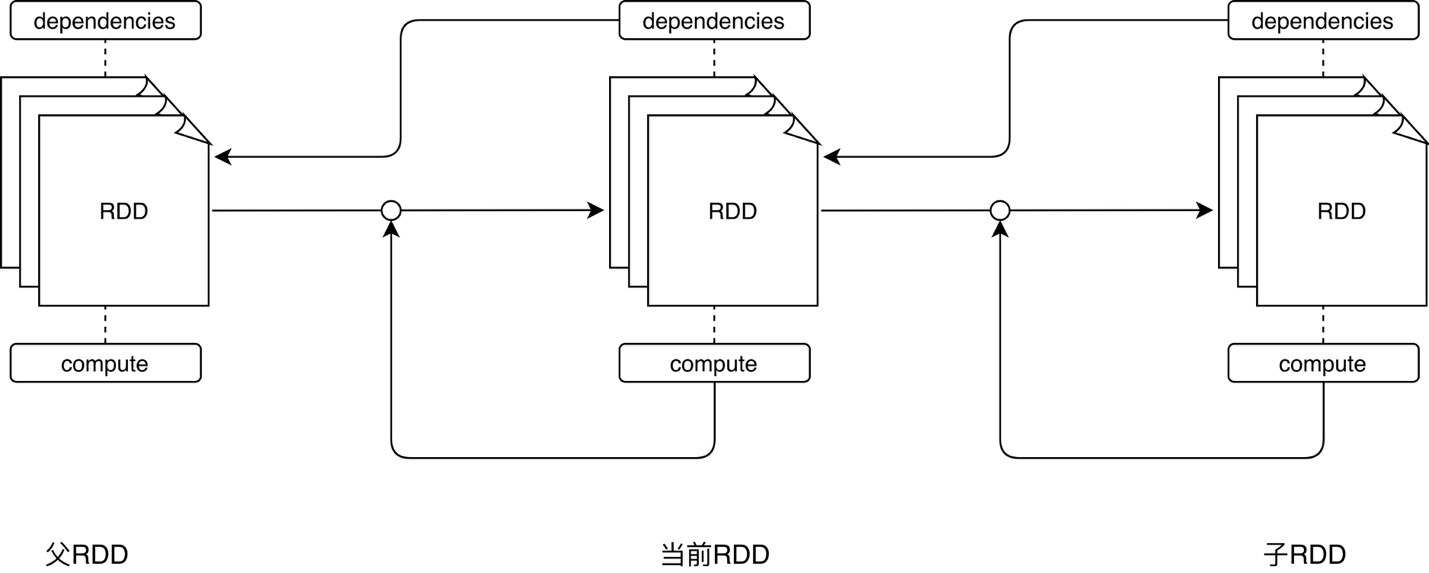
不难发现,所有 RDD 根据 dependencies 中指定的依赖关系和 compute 定义的计算逻辑构成了一条从起点到终点的数据转换路径。这条路径在 Spark 中有个专门的术语,叫作 Lineage —— 血统。Spark Core 依赖血统进行依赖管理、阶段划分、任务分发、失败重试,任意一个 Spark 计算作业都可以析构为一个 Spark Core 血统。关于血统,到后文书再展开讨论,我们继续介绍 RDD 抽象的另外 3 个属性,即 partitions、partitioner 和 preferredLocations。相比 dependencies 和 compute 属性,这 3 个属性更“务实”一些。
在分布式计算中,一个 RDD 抽象可以对应多个数据分片实体,所有数据分片构成了完整的 RDD 数据集。partitions 属性记录了 RDD 的每一个数据分片,方便开发者灵活地访问数据集。partitioner 则描述了 RDD 划分数据分片的规则和逻辑,采用不同的 partitioner 对 RDD 进行划分,能够以不同的方式得到不同数量的数据分片。因此,partitioner 的选取,直接决定了 partitions 属性的分布。preferredLocations —— 位置偏好,该属性与 partitions 属性一一对应,定义了每一个数据分片的物理位置偏好。具体来说,每个数据分片可以有以下几种不同的位置偏好:
本地内存:数据分片已存储在当前计算节点的内存中,可就地访问
本地磁盘:数据分片在当前计算节点的磁盘中有副本,可就地访问
本机架磁盘:当前节点没有分片副本,但是同机架其他机器的磁盘中有副本
其他机架磁盘:当前机架所有节点都没有副本,但其他机架的机器上有副本
无所谓:当前数据分片没有位置偏好
根据“数据不动代码动”的原则,Spark Core 优先尊重数据分片的本地位置偏好,尽可能地将计算任务分发到本地计算节点去处理。显而易见,本地计算的优势来源于网络开销的大幅减少,进而从整体上提升执行性能。
RDD 的 5 大属性从“虚”与“实”两个角度刻画了对数据模型的抽象,任何数据集,无论格式、无论形态,都可以被 RDD 抽象、封装。前面提到,任意分布式计算作业都可以抽象为血统,而血统由不同 RDD 抽象的依次转换构成,因此,任意的分布式作业都可以由 RDD 抽象之间的转换来实现。理论上,如果计算节点内存足够大,那么所有关于 RDD 的转换操作都可以放到内存中来执行,这便是“内存计算”的由来。
土豆工坊
从理论出发学习、理解新概念总是枯燥而乏味,通过生活化的类比来更好地理解 RDD 的构成和内存计算的由来也许会更轻松一些。假设有个生产桶装薯片的工坊,这个工坊规模小、工艺也比较原始。为了充分利用每一颗土豆、降低生产成本,工坊使用 3 条流水线来同时生产 3 种不同尺寸的桶装薯片,分别是小号、中号、大号桶装薯片。3 条流水线可以同时加工 3 颗土豆,每条流水线的作业流程都是一样的,即土豆的清洗、切片、烘焙、分发、装桶,其中分发环节用于区分小号、中号、大号 3 种薯片。所有小号薯片都会分发给第一条流水线,中号薯片分发给第二条流水线,不消说,大号薯片都分发给第三条流水线。看得出来,这家工坊工艺虽然简单,倒是也蛮有章法。桶装薯片的制作流程,与 Spark 分布式计算的执行过程颇为神似。
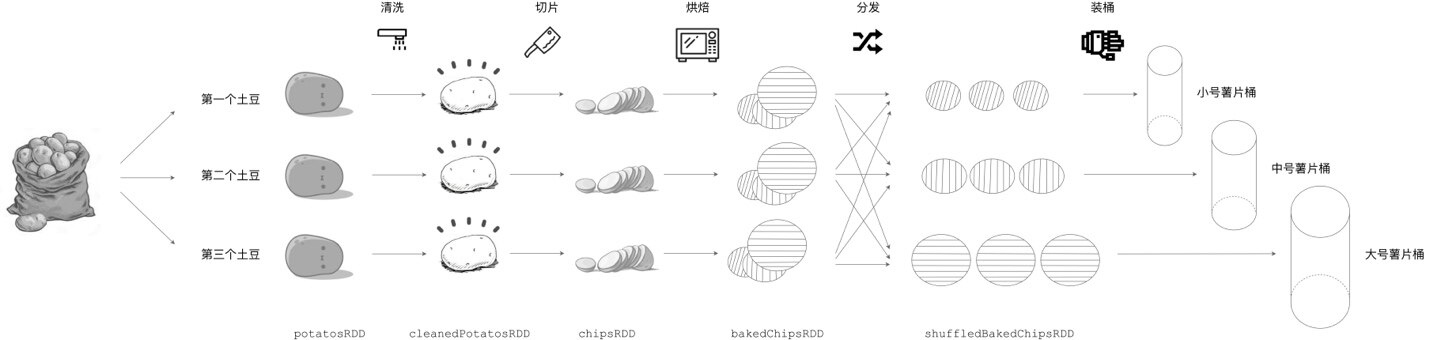
我们先从食材的视角审视薯片的加工流程,首先,3 颗土豆作为原始素材被送上流水线。流水线的第一道工序是清洗,原来带泥的土豆经过清洗变成了一颗颗“干净的土豆”。第二道工序是切片,土豆经过切片操作后,变成了一枚枚大小不一、薄薄的薯片,当然,这些薯片都还是生的,等到烘烤之后方能食用。第三道工序正是用来烘焙,生薯片在经过烘烤后,变成了可以食用的零食。到目前为止,所有流水线上都生产出了 “原味”的薯片,不过,薯片的尺寸参差不齐,如果现在就装桶的话,一来用户体验较差,二来桶的利用效率也低,不利于节约成本。因此,流水线上增加了分发的环节,分发操作先把不同尺寸的薯片区分开,然后根据预定规则把不同尺寸的薯片发送到对应的流水线上。每条流水线都执行同样的分发操作,即先区分大小号,然后再转发薯片。分发步骤完成后,每条流水线的薯片尺寸大小相当,最后通过机械手把薯片封装到对应尺寸的桶里,从而完成一次完整的薯片加工流程。
横看成岭侧成峰,我们再从流水线的视角,重新审视这个过程。从头至尾,除了分发环节,3 条流水线没有任何交集。在分发环节之前,每条流水线都是专心致志、各顾各地开展工作 —— 把土豆食材加载到流水线上、清洗、切片、烘焙;在分发环节完成后,3 条流水线也是各自装桶,互不影响。流水线式的作业方式提供了较强的容错能力,如果某个加工环节出错,流水线只需要重新加载一颗新的土豆食材就能够恢复生产。例如,假设第一条流水线在烘焙阶段不小心把薯片烤糊了,此时只需要在流水线的源头重新加载一颗新的土豆,所有加工流程会自动重新开始,不会影响最终的装桶操作。另外,3 条流水线提供了同时处理 3 颗土豆的能力,因此土豆工坊的并发能力为 3,每次可以同时装载并加工 3 颗土豆,大幅地提升了生产效率。
那么,用土豆工坊薯片加工的流程类比 Spark 分布式计算,会有哪些有趣的发现呢?仔细对比,每一种食材形态,如刚从地里挖出来的土豆食材、清洗后的“干净土豆”、生薯片、烤熟的薯片、分发后的薯片,不就是 Spark 中的 RDD 抽象吗?每个 RDD 都有 dependencies 和 compute 属性,对应地,每一种食材形态的 dependencies 就是流水线上前一个步骤的食材形态,而其 compute 属性就是从前一种食材形态转换到当前这种食材形态的加工方法。例如,对于烤熟的薯片(图中 bakedChipsRDD)来说,它的 dependencies 就是上一步的“已切好的生薯片”(chipsRDD),而它的 compute 属性,就是“烘焙”这一工艺方法。在土豆工坊的制作流程中,从头至尾会产生 6 个 RDD,即 potatosRDD、cleanedPotatosRDD、chipsRDD、bakedChipsRDD 和 shuffledBakedChipsRDD,分别对应不同的食材形态。注意,RDD 是对数据模型的抽象,它的 partitions 属性会对应多个数据分片实体。例如,对于原始食材 potatosRDD,它的 partitions 属性对应的是图中的 3 颗带泥土豆,每颗土豆代表一个“数据分片”。
同理,chipsRDD 的 partitions 属性包含的是从 3 颗土豆切出来的所有“生薯片”,每一枚生薯片都有一个 preferredLocation 用来标记自己所在的流水线,所有生薯片的 preferredLocation 集合构成了 chipsRDD 的 preferredLocations 属性。不难发现,如果我们把土豆工坊中的流水线看成是分布式计算节点,流水线上每一种食材形态的转换,都可以在计算节点中按序完成。特别地,如果节点内存足够大,那么所有上述转换,都可以在内存中完成。随着纳米工艺的飞速发展,在不远的将来,也许内存的价格会像现在的磁盘一样便宜。正是基于这样的判断,Spark 提出了“内存计算”的概念。

Show me the code
Linus Torvalds 他老人家常说:“Talk is cheap. Show me the code.”。在本篇的最后,我们通过代码示例来直观地感受一下 RDD 的转换过程。学习一门新的编程语言,我们通常从“Hello World”开始;学习分布式开发,我们得从“Word Count”说起。在开始之前,我们准备一个纯文本文件,内容非常简单,只有 3 行文本,如下图所示。

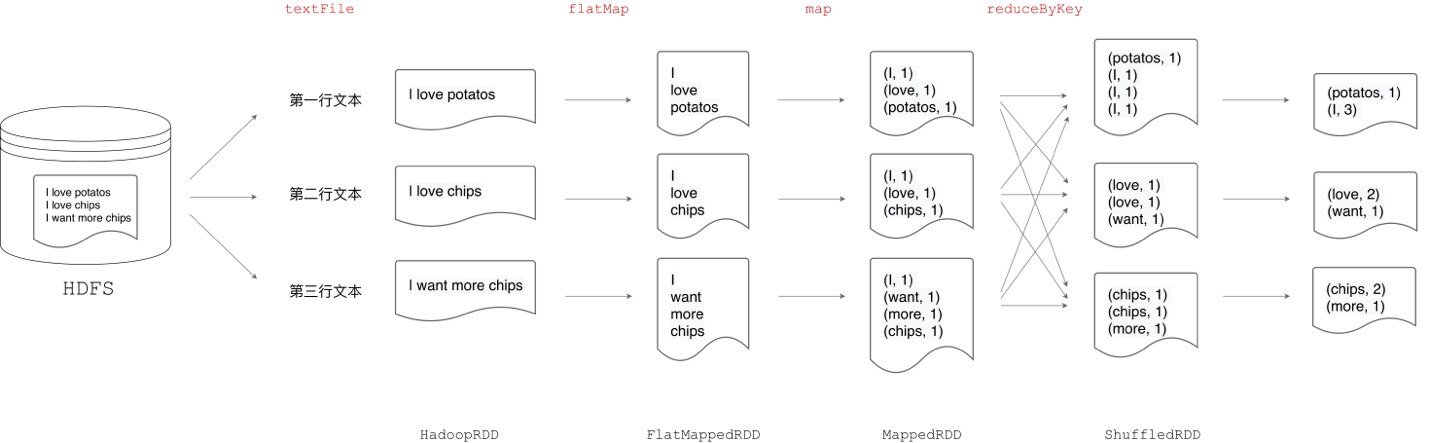
“Word Count”任务的目标是拆分文本中的单词并对所有单词计数,对于上图中的文本内容,我们期望的结果是 I 的计数是 3,chips 的计数为 2,等等。在用代码来实现这个任务之前,我们先来思考一下:解决这个问题,都需要哪些步骤。首先,我们需要将文件内容读取到计算节点内存,同时对数据进行分片;对于每个数据分片,我们要将句子分割为一个个的单词,同样的单词可能存在于多个不同的分片中(如单词 I),因此需要对单词进行分发,从而使得同样的单词只存在于一个分片之中;最后,在所有分片上计算每个单词的计数。对于这样一个分词计数任务,如果采用 Hadoop MapReduce 框架来实现,往往需要用 Java 来实现 Map、Reduce 抽象,编写上百行代码。得益于 Spark RDD 数据模型的设计及其提供的丰富算子,无论是用 Java、Scala 还是 Python,只消几行代码,即可实现“Word Count”任务。

结合刚刚分析的“解题步骤”,我们首先通过 textFile 算子将文件内容加载到内存,同时对数据进行分片。然后,用 flatMap 和 map 算子实现分词和计 1 的操作。这里计 1 的目的有二,一来是将数据转换为(键, 值)对的形式从而调用 pairRDD 相关算子;二来为 Map 端聚合计算打下基础。关于 pairRDD、性能优化,我们在后文书会详细展开,此处先行略过。最后,通过 reduceByKey 算子完成单词的分发和计数。在这份代码中,我们仅用 5 行 Scala code 就实现了“Word Count”分布式计算作业。在算子的驱动下,不同形态 RDD 之间的依赖关系与转换过程一目了然。那么,如果把这段代码放到土豆工坊的流水线上,会是怎样的流程呢?
Postscript
本篇是《Spark 分布式计算科普专栏》的第一篇,笔者学浅才疏、疏漏难免。如果您有任何疑问,或是觉得文章中的描述有所遗漏或不妥,欢迎在评论区留言、讨论。掌握一门技术,书本中的知识往往只占两成,三成靠讨论,五成靠实践。更多的讨论能激发更多的观点、视角与洞察,也只有这样,对于一门技术的认知与理解才能更深入、牢固。在本篇博文中,我们从分布式计算发展历史的角度,审视了 Spark、RDD 以及内存计算的由来;以 RDD 的 5 大核心属性展开,讲解 RDD 的构成、依赖关系、转换过程,并结合“土豆工坊”的生活化示例来类比 RDD 转换和 Spark 分布式内存计算的工作流程。
最后,我们用一个简单的代码示例 —— Word Count 来直观地体会 Spark 算子与 RDD 的转换逻辑。细心的读者可能早已发现,文中多次提及“后文书再展开”,Spark 是一个精妙而复杂的分布式计算引擎,在本篇博文中我们不得不对 Spark 中的许多概念都进行了“前置引用”。换句话说,有些概念还没来得及解释(如 Lineage —— 血统),就已经被引入到了本篇博文中。这样的叙述方法也许会给一些读者带来困惑,毕竟,用一个还未说清的概念,去解释另一个新概念,总是感觉没那么牢靠。常言道:“出来混,迟早是要还的”。在后续的专栏文章中,我们会继续对 Spark 的核心概念与原理进行探讨,尽可能地还原 Spark 分布式内存计算引擎的全貌。
作者简介
吴磊,Spark Summit China 2017 讲师、World AI Conference 2020 讲师,曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。现担任 Comcast Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地与推广。热爱技术分享,热衷于从生活的视角解读技术,曾于《IBM developerWorks》和《程序员》杂志发表多篇技术文章,并在极客时间发表了两个专栏《零基础入门Spark》和《Spark 性能调优实战》,内容深入浅出、风趣幽默。




