随着移动智能设备的普及,对聊天机器人和智能个人助理的需求日益迫切。一种业界观点认为,由人工智能技术驱动的聊天机器人将成为未来的移动端界面,从根本上改变人机交互的体验。我们已经看到了 Amazon Echo 和 Google Home 等产品,它们在日常生活、电子商务、信息获取等领域有广泛的应用。但是实现真正的开放域智能聊天机器人(Socialbot,也称为聊天机器人(Chatbot)或闲聊机器人(Chitchat bot)),依然是人工智能研究领域一个尚待解决的问题,仍然需要工业界和研究领域去努力解决大量挑战。
过去几年中深度学习的发展,尤其是近一年内深度强化学习(Deep reinforcement learning,DRL)的推进,为解决开放域人机交互提供了以一种可能技术途径。强化学习的显著特征是智能体(Agent)从用户处得到反馈并给予用户奖励(Reward),通过学习给出有助于实现整体奖励最大化目标的响应。Alphago 的成功使人们看到了强化学习在序列决策上的巨大进步,这些进步进而推动了 DRL 在自动语音和自然语言理解领域的研究,探索解决自然语言理解及响应等开展对话中存在的挑战。基于深度强化学习的 Bot 具有扩展到当前尚无法涉足领域的能力,适用于开放域聊天机器人的场景。
本文介绍了加拿大蒙特利尔大学 Yoshua Bengio 研究组提出的 MILABOT 的模型、实验和最终系统。论文被 NIPS 2017 Demo 收录。MILABOT 使用深度学习组合了多种 NLP 模型,在 Amazon 于 2016 年组织的开放域 Socialbot 竞赛取得很好的成绩,优于任何非组合模型。MILABOT 的独到之处在于,首先它针对表达(utterance)响应的任务使用强化学习算法,大规模地组合了过去近十年中所有成功的 NLP 模型和算法,最小化了对手工定制规则和状态的需求。其次在训练参数化模型中,使用了 Amazon 竞赛提供的机会,在真实用户上训练和测试了当前最新机器学习算法的机会。训练后的系统在 A/B 测试中得到了显著改进的结果。
下面,我们介绍论文的主要思想和创新之处。
系统概览
早期的对话系统主要基于由专家人工制定的状态和规则。而现代对话系统通常使用组合学习的架构,将手工定制状态和规则组合到统计机器学习算法中。由于人类语言的复杂性,在构建在开放域对话机器人时,最大的挑战在于无法枚举所有可能的状态。
MILABOT 完全采用基于统计机器学习的方法,在处理和生成自然人类对话中做了尽可能少的假设。模型中每个组件的设计使用机器学习方法优化,通过强化学习对各个组件的输出进行优化。其灵感来自于组合机器学习系统,即由多个独立的统计模型组成更好的学习系统。例如,2009 年 Netflix 大奖赛胜出系统使用了数百个模型的组合,很好地预测了用户电影倾向。另一个例子是 IBM 的 Watson 在 2011 年赢得了 quiz 游戏 Jeopardy!。这些实例说明了组合学习的优越之处。
在 MILABOT 中,Dialogue Manger(DM)组合了一系列的响应模型,由 DM 担当强化学习中的智能体,其控制结构如图 1 所示。DM 将所有模型的响应(Response)以一定的策略组合在一起。在 MILABOT 的设计中,响应模型使用了多种策略,生成各种话题的响应,本文将详细介绍各种策略模型在设计上的考虑。

图 1 DM 的控制结构
如图 1 所示,DM 给出响应的过程分为三个步骤。首先,DM 调用各种响应模型,生成一组候选响应。如果候选集中具有优先响应,那么返回该优先响应。如果候选集中没有优先响应,那么系统使用策略模型给出规则,从候选响应集中选取一个响应。一旦置信值低于给定的阈值,那么系统会请求用户重复最后一个表达。
下面,我们分别介绍 MILABOT 所使用的各种响应模型,以及在生成响应的策略模型设计考虑。
响应模型
每个响应模型输入对话,并生成自然语言形式的响应。此外,响应模型还会输出一到多个标量,用于标识给出响应的置信度。MILABOT 组合使用了 22 种响应模型,这些响应模型使用了近十年来 NLP 领域一些突出的研究成果。模型可分为:
- 基于模板的模型,包括 Alicebot 、 Elizabot 和 Storybot 。
- 基于知识库的问答系统,包括 Evibot 、 BoWMovies 。
- 基于检索的神经网络,包括 VHRED models 、SkipThought Vector Models、Dual Encoder Models、Bag-of-words Retrieval Models。
- 基于检索的逻辑回归,包括 BoWEscapePlan 等。
- 基于搜索引擎的神经网络,包括 LSTMClassifierMSMarco 等。
- 基于生成的神经网络,包括 GRUQuestionGenerator 等。
论文所使用的模型介绍及训练情况,可参见详细报告。
模型选取策略
在多种响应模型生成候选响应集后,DM 使用策略模型确定选择策略,从候选集中确定将返回给用户的响应。DM 必须应能选出提升用户整体满意度的响应,这需要在响应的实时性和用户整体满意度两者间作权衡。此外,响应选取中也应该考虑在用户的即刻满意度和整体满意度间作权衡。论文使用了 Richard Sutton 和 Andrew Barto 提出的经典强化学习框架,将该问题看成是一种序贯决策问题(sequential decision making),形式化定义为:给定时序\(t=1,…,T\),在 t 时刻的对话为\(h_t\),智能体需要从一组 K 个响应\(a_t^1,…,a_t^K\) 中做出选取,并得到奖励\(r_t\)。当系统转移到下一个状态\(h_{t+1}\) 时,响应为\(a_{t+1}^1,…,a_{t+1}^K\),选取响应后得到奖励为\(r_{t+1}\)。强化学习的最终目标是最小化\(R = \sum_{t=1}^{T}\gamma ^tr^t\)。其中\(r\in (0,1]\) 是折现系数(discount factor)。构建强化学习模型中考虑的因素包括:
- 行为价值函数的参数化:行为价值函数(action-value function)由参数\(\theta\) 定义,\(Q_\theta (h_t,a_t^k)\in \mathbb{R},k = 1,…,K\)。学习的期望返回值实现参数最大化\(\pi _\theta (h_t) = \underset{k}{arg max}Q_\theta (h_t,a_t^k)\)。
- 随机策略的参数化:假定策略是随机的,那么随机分布服从动作的一个参数化分布
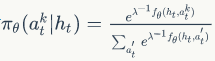 。其中,\(f_\theta (h_t,a_t^k) \) 是以\(\theta \) 为参数的打分函数(scoring function)。可使用贪心策略\(\pi _\theta ^{greedy}(h_t) = \underset{k}{arg max}\pi _\theta (a_t^k|h_t)\),选取具有最大概率的动作。
。其中,\(f_\theta (h_t,a_t^k) \) 是以\(\theta \) 为参数的打分函数(scoring function)。可使用贪心策略\(\pi _\theta ^{greedy}(h_t) = \underset{k}{arg max}\pi _\theta (a_t^k|h_t)\),选取具有最大概率的动作。

图 2 模型选择策略评分模型的计算图。计算基于行为价值函数和随机策略参数化。
论文将打分函数和行为价值函数参数化,构建了结构如图 2 所示的五层的神经网络。神经网络的第一层是输入层,该层使用的特征抽取自对话历史和生成响应,用于表示对话历史和候选响应。特征考虑了基于词嵌入、对话、POS 标签、Unigram 词重叠、Bigrapm 词重叠和一些特定于模型特征的组合,合计 1458 个(可参见详细报告)。第二层包含了 500 个隐含单元,通过对输入层特征应用线性转换及 ReLU 激活函数计算。第三层包含了 20 个隐含层,通过对前面的层应用线性转换计算得到。第四层包含了 5 个输出概率的单元,通过对前面的层应用线性转换并随后做 softmax 转换计算得到,并对应到 Amazon Mechanical Turk(AMT)给出的标签。第五层是最终输出层,给出一个单标量值。该层通过对第三层和第四层中的单元做线性转换计算得到。为了学习各层的参数,论文深入研究了五种不同的机器学习方法。
- 使用众包标签的有监督学习。该方法(称为“有监督 AMT”)是打分模型学习的首个过程,所得到的模型参数可用于其它方法的启动参数。该方法在众包标签数据上使用有监督的学习,给出对行为价值函数\(Q_\theta\) 的估计。训练所需的数据集由 AMT 采集,并使用人工给出对响应的打分(从 1 到 5)。研究团队从真实的 Alexa 用户会话中采集了 199,678 个标签,并分为训练数据集(137,549)、开发数据集(23,298)和测试数据集(38,831)。在训练模型中,团队使用对数似然优化打分模型参数\(\hat{\theta } = \underset{\theta}{arg max}\sum_{x,y}^{ }logP_\theta (y|x)\),估计表示 AMT 标签的神经网络第四层。模型参数优化使用一阶 SGD 方法。图 3 给出了对于五种不同的标签类(即对响应打分从最好到最差),使用几种不同策略时的性能对比。从图中结果可见,有监督 AMT 取得了比其它对比方法(随机、Alicebit、Evibot+Alicebot)更好的性能。

图 3 使用不同的策略时,响应 AMT 标签类的频率情况。
- 有监督的奖励学习。使用学习得到的奖励函数去学习模型的参数。给定某一时刻的对话历史,以及相应的响应集,可以将某一时刻的奖励建模为一个线性回归模型,预测响应的打分。学习的目标是使得打分分值最大化。模型参数优化使用 mini-batch SGD。为增加效率,在组合模型学习中使用了 Bagging 方法。在训练模型时为避免过拟合,模型在初始化时使用了有监督 AMT 打分模型的参数,并以最小化平方误差为目标做进一步优化。
- 离策略(Off-policy)强化学习。一种策略参数化方法就是假定行为具有的离散概率分布,这样可以直接使用系统和真实用户间的对话记录学习随机策略。MILABOT 使用了一种重新加权的强化学习算法进行学习,模型的初始化参数同样使用了有监督 AMT 训练的模型参数。训练中使用的数据集是在一段时间内测试系统和真实用户间的 5000 条对话记录,策略参数使用 SGD 在训练集进行优化,并用开发集确定模型的超参数和 Early-stop。
- 使用学习到的奖励函数,做离策略强化学习。该方法类似于有监督的奖励学习,在用于训练的奖励模型上使用离策略强化学习算法。首先,该方法使用经良好调优的行为价值函数,对某一时刻的对话给出更准确的打分预测。然后,将回归模型组合离策略强化学习中,使用 mini-batch SGD 训练模型参数。训练中使用的数据集同样使用离策略强化学习中的数据集。
- 使用 Markov 决策过程(MDP)的 Q-learning。上述方法都是在方差和偏差间取得权衡。有监督 AMT 方法使用了大量的训练集,可以给出最小的方差,但是引入了大量的偏差。另一方面,离策略强化学习在训练中仅使用了数千条对话即学习到的打分情况,因此方差很大。但是由于它直接优化目标函数,因此给出的偏差很小。面对此问题,MILABOT 团队提出了一种新的方法,称为“抽象话语”(Abstract Discourse)MDP。抽象话语 MDP 通过近似 Markov 决策过程(MDP)中学习策略,意在降低方差的同时给出合理的偏差。

图 4 抽象话语 MDP 的有向概率图模型。
抽象话语 MDP 的有向概率图模型如图 4 所示。对于某一时刻 t,\(z_k\) 是表示对话抽象状态的离散变量,\(h_t\) 表示对话历史,\(a_t\) 表示系统所采取的动作(即选定的响应),\(y_t\) 表示抽样 AMT 标签,\(r_t\) 表示抽样奖励。其中,\(z_t\) 的状态被定义为一个离散值的三元组,包括对话行为状态(接受、拒绝、请求、提问等)、情感状态(正向、负向、中立)和表达状态(真、假)。模型的训练可以直接使用模拟数据,训练方法使用具有经验池(experience replay)的 Q-learning,策略参数化为行为价值函数。各种策略在 AMT 上的评估情况如表 1 所示。
表 1 策略在 AMT 上打分均值和标准偏差的评估情况,置信区间为 90%

实验评估
团队使用A/B 测试,检验DM 在选取策略模型上的有效性。测试在Amazon 竞赛环境中开展,当Alexa 用户与系统对话时,会自动指定一个随机策略,随后记录对话内容和打分情况。A/B 测试可以检验不同策略在同一系统环境下的对比情况,其中考虑了不同时间段用户的不同情况。团队的测试分三个阶段开展。
第一阶段测试了五种不同的策略生成方法,并与启发式的基线方法Evibot+Alicebot 做了对比。第二个阶段测试主要针对离策略和Q-learning 强化学习方法。第三阶段测试使用优化参数的模型和训练集,进一步测试了离策略和Q-learning。测试结果如表2 所示。
表2 95% 置信区间下的A/B 测试结果。“*”标识了95% 的统计显著性。

从测试结果可见,离策略和Q-learning 表现出比其它策略更优的结果。从平均情况来看,Q-leaning 给出的打分最好。总而言之,实验表明了组合方法的有效性。MILABOT 通过将多个NLP 模型给出的响应组合在一起,并使用策略模型选取打分最优的响应,并可不断改进策略学习。
结论
论文提出了一种新的大规模基于组合学习的对话系统MILABOT,并在Amazon Alexa 大奖赛中进行了验证。MILABOT 使用了大量的机器学习方法,包括深度学习和强化学习。其中,团队提出了一种新颖的强化学习方法。通过使用A/B 测试与已有强化学习方法的对比,在真实Alexa 用户数据上取得了更优的对话效果。
论文对进一步工作提出了两个方向。一个方向是实现个性化,使聊天机器人能提供更好的用户体验。实现的技术途径可能涉及对每个用户学习嵌入向量。另一个方向是基于文本的评估,以消除语音识别错误对聊天机器人的影响因素。
查看英文原文: A Deep Reinforcement Learning Chatbot
感谢蔡芳芳对本文的审校。




