对工程师来说人工智能(AI)是很酷炫的,就像宇宙飞船和科幻小说也很酷一样。机器学习和人工智能吸引了非常多的关注。一些 IT 巨头如 IBM 和 Intel ,已经实施了整套市场宣传,促使这些研究领域的实践日益增长。这继续很酷炫科幻吗?这些增长现在能合理地用于增强我们的应用吗?
学习排序技术把机器学习带进了搜索引擎的世界,这既不是魔术也不是小说。在新的较小的应用案例潮流的风口浪尖,允许一个现成的类库实现来满足用户预期。
什么是相关度工程?
搜索和探索非常适合应用机器学习技术。相关度工程是指识别文档集中针对这些文档的用户最重要的特征,并使用这些特征来优化搜索引擎,从而为每个用户的每次搜索返回最佳匹配文档的过程。简单重申下一个搜索引擎的工作过程:在索引阶段文档被解析成短语,这些短语随后会被插入到下图所示的索引中:
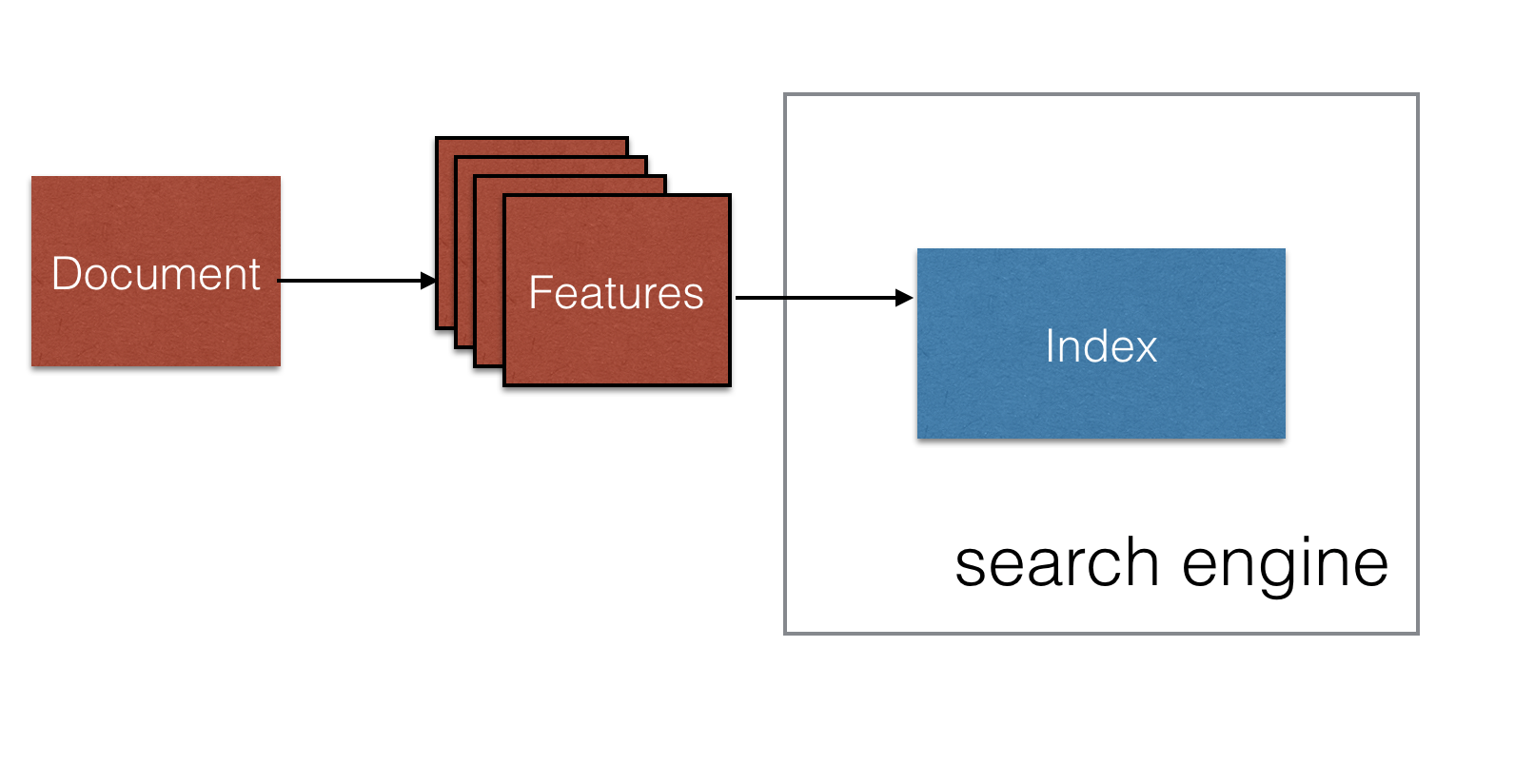
在搜索阶段,单个查询也被解析为短语。搜索引擎随后从倒排索引中检索这些短语,对匹配的文档做排序,抽取出跟这些文档最关联的文本,并返回排序后的结果给用户,如下所示:
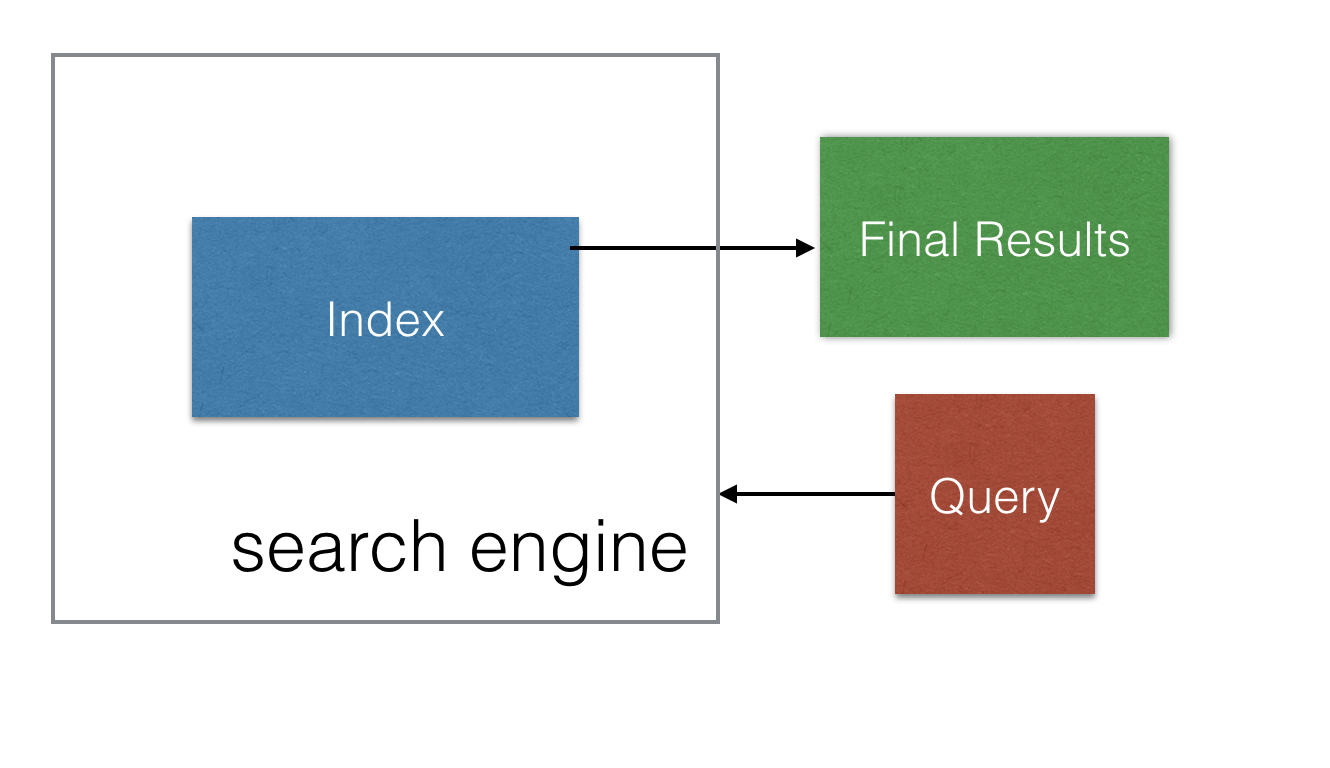
根据文本短语识别最佳特征,是一个基础性难题。所有的书籍和博士生都在研究求解该问题。(厚颜推荐下我们的书《相关度搜索》 6 !)现在考虑一个销售记录:
ID Title Price
1 Blue shoes $10
2 Dress shoes $15
3 Blue dress $20
4 Red dress $40
作为人类,我们直觉上知道在文档 2 里,‘dress’是一个描述鞋子的形容词,而在文档 3 和 4 中,‘dress’是一个名词,是类目中的一项。作为一个相关度工程师,我们可以构建一个信号量来猜测用户在搜索‘dress’时究竟希望是形容词还是名词。即使通过谨慎的手工分类,文本短语也是一个内容上的细微差别的不完美的呈现。
机器学习排序起源
来自 Wikipedia 的定义:
学习排序或机器学习排序(MLR)是指应用机器学习为信息检索系统构建排序模型。通常通过一个二次排序函数实现。
这表示,并非使用一个机器学习模型替代搜索引擎,我们通过一个额外的步骤来扩展下流程。在查询到达索引后,该查询的最佳结果会被导入模型,并在返回用户前重新排序,如下图示:
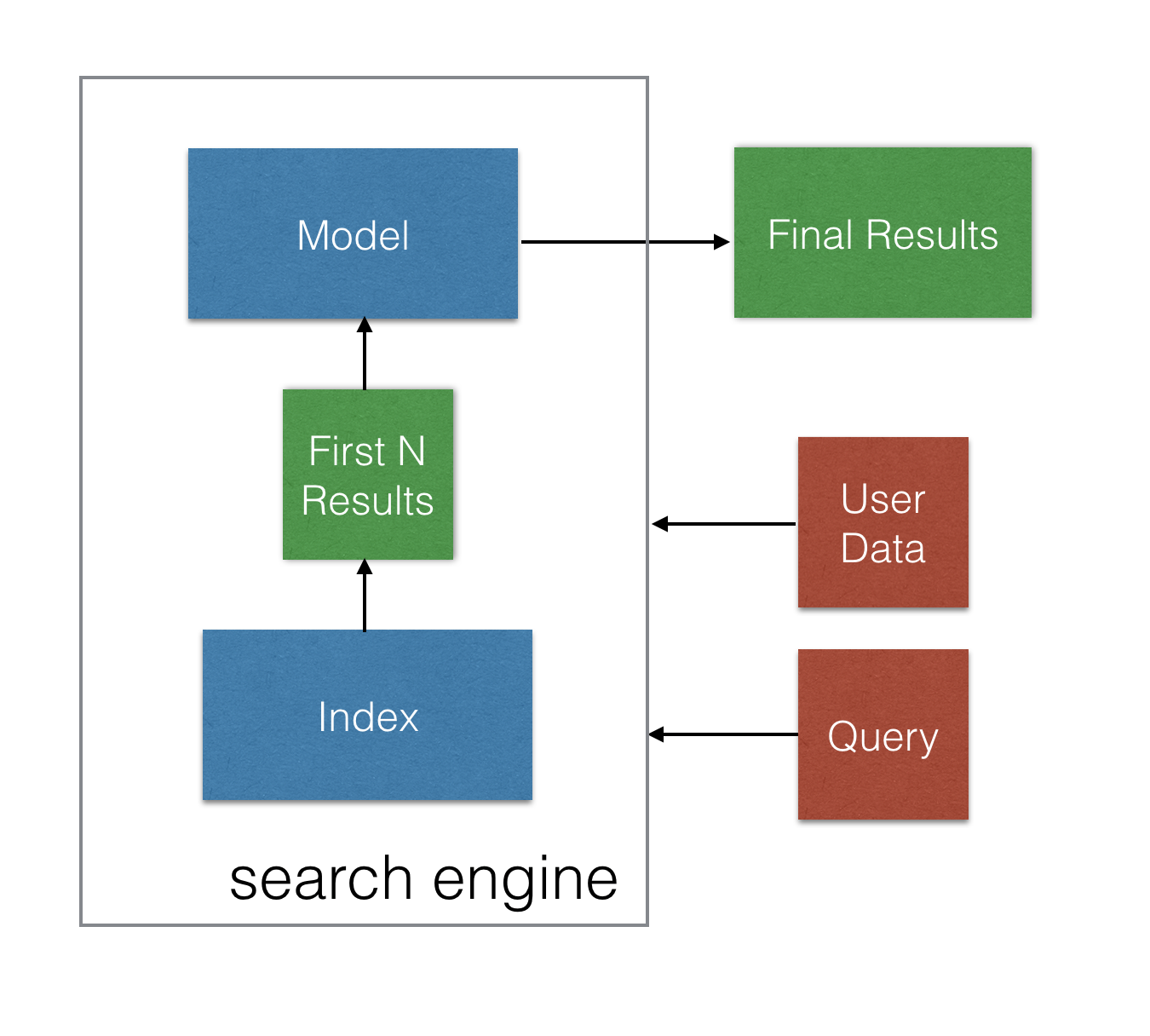
为什么要分两部分完成?为什么不能使用模型完全替代搜索引擎?
搜索引擎通常有两个评价标准:召回率,即相关文档在结果集中返回的比例;精准率,即结果集中相关文档的比例。作为相关度工程师,为文档构建信号量,让搜素引擎返回所有重要结果,与优先返回最佳文档相比通常没那么难。直觉上,通常可能会通过简单地返回更多文档来提升召回率。但是对于一个普通用户,如果更好的结果不在列表的最开头,那就并没有什么提升。
机器学习如何介入到这个过程?回到我们的 Wikipedia 定义:
机器学习是计算机科学的一个分支领域,让计算机能够在未明确编程的前提下学习。源于模式识别研究和人工智能方面的计算学习理论的发展,机器学习重在挖掘研究和构建能从数据中学习并作出决策的算法。
机器学习不是魔法,相比于人类理解词汇也并不智能。对于实践中的工程问题,需要提供一个训练数据集:我们想让机器去学习的数值模式的数值得分。事实证明,构建一个精确的训练数据集并不容易,并且对于很多现实中的应用,构建训练数据成本极高,即使使用优化算法。因此,如果搜索引擎在召回率方面已经挺好的了,就无需再收集数据来训练模型了;只需要在排序方面训练模型,或者在结果集中对文档重排序即可。
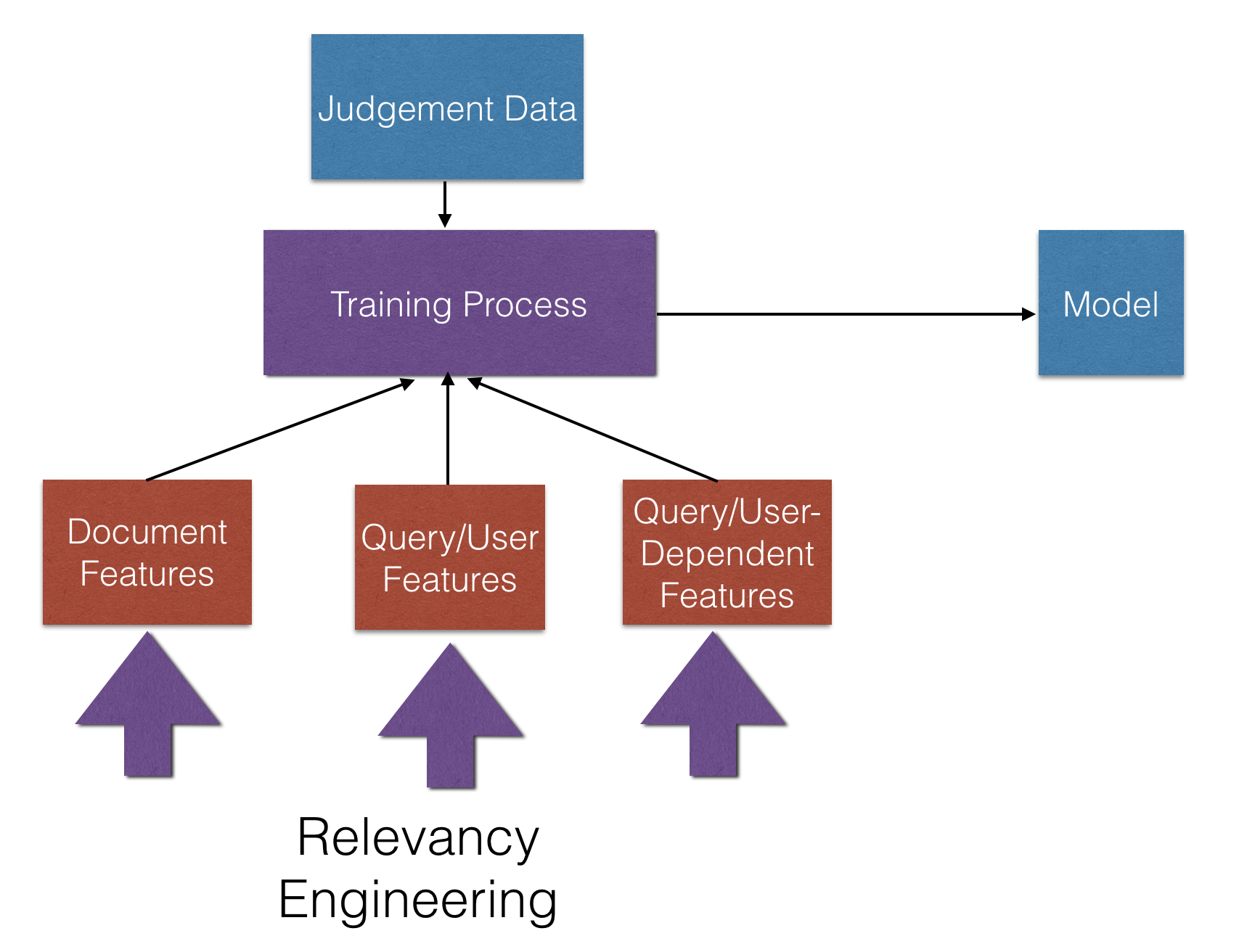
另一个缩小重排序范围的原因是性能问题。构建和评估模型都是计算密集型的。因为训练模型时要求每个特征都是一个文档或者文档和用户关系的数值表示,它必须每次都能用于计算。因为用户期望搜索结果在秒级或毫秒级返回,对1000 到2000 个文档同时做二次排序,要比对每次搜索的数万甚至数百万文档二次排序代价低。
后续内容
本文是机器学习排序系列文章的第二篇,如果想亲自动手尝试,可以试试我们开发的 Elasticsearch 的 LTR 插件!敬请关注本系列的更多文章:
- 模型:何谓相关度模型?选择模型时如何考量?
- 应用:将 LTR 应用到搜索、推荐系统、个性化及更多场景
- 思考:应用 LTR 时有哪些技术和非技术因素需要考量?
查看英文原文: http://opensourceconnections.com/blog/2017/02/24/what-is-learning-to-rank/
感谢冬雨对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




