
在 Koverhoop,我们正在保险、医疗、房地产和离线分析领域建立一些大型项目。在我们其中一个多租户团体保险经纪平台 klient.ca,我们计划构建一个强大的搜索功能,希望能在用户输入内容的同时同步呈现搜索结果。下面是我们能够实现的效果,我将在这篇文章讨论这一功能的核心基础设施,包括如何完全自动化部署及如何快速完成构建工作。
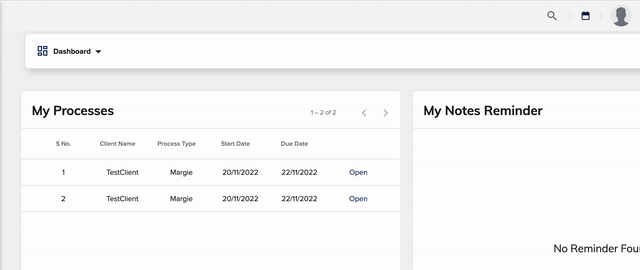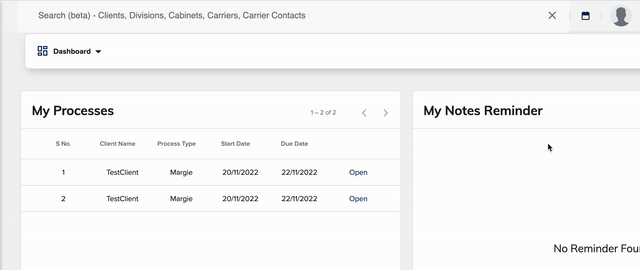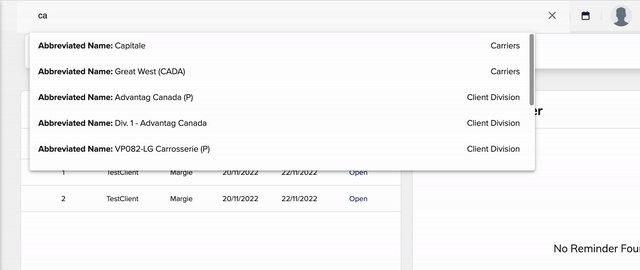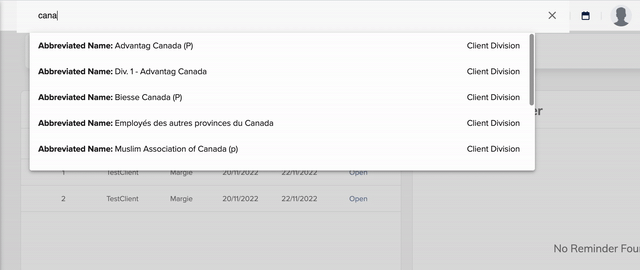
来自作者的动图: 搜索能力
这个系列文章分为两部分,我将分别讨论以下内容:
第 1 部分:了解用于支持此搜索能力的技术栈,并使用 Docker 和 Docker-compose 进行部署(本文)
第 2 部分:使用 Kubernetes 对这些服务进行可伸缩的生产部署(待发布)
问题定义和决策
为了构建一个快速、实时的搜索引擎,我们必须做出某些设计决策。我们使用 Postgres 作为主数据库,因此有以下选项可以使用:
直接在 Postgres 数据库中查询我们在搜索栏中键入的每个字符。😐
使用一个高效的搜索数据库,如 Elasticsearch。🤔
考虑到我们已经是一个多租户应用程序,同时被搜索的实体可能需要大量的关联操作(如果我们使用 Postgres)且预计规模也相当大,因此我们决定不使用以前直接查询数据库的方案。
因此,我们必须决定一种可靠、高效的方式,将数据从 Postgres 实时迁移到 Elasticsearch。接下来需要作出以下决定:
使用 Logstash 定期查询 Postgres 数据库并将数据发送到 Elasticsearch。😶
在我们的应用程序中使用 Elasticsearch 客户端,在 Postgres 和 Elasticsearch 中同时对数据进行 CRUD 操作。🧐
使用基于事件的流引擎,从 Postgres 的预写日志中提取事件,将它们导入到流处理服务器,并将其接收到 Elasticsearch。🤯
选项 1 因为不是实时的,所以很快就被排除了,而且即使我们以较短的间隔进行查询,也会给 Postgres 服务器带来明显的压力。对于其他两种选择,不同的公司做出的决定可能不一样。在我们的场景里如果选择选项 2,我们可以预见到一些问题:如果 Elasticsearch 在确认更新时速度很慢,这可能会减慢我们应用程序的速度,或者在不一致的情况下,我们要如何对单个或一组事件的插入进行重试?
因此,我们决定构建一个基于事件队列的基础设施。还因为我们已经计划了一些适合基于事件的未来场景和服务,比如通知服务、数据仓库、微服务架构等。事不宜迟,让我们直接开始解决方案及所使用服务的基本介绍吧。
服务简介
为了实现基于事件的流基础设施,我们决定使用 Confluent Kafka 技术栈。
以下是我们整合的服务:
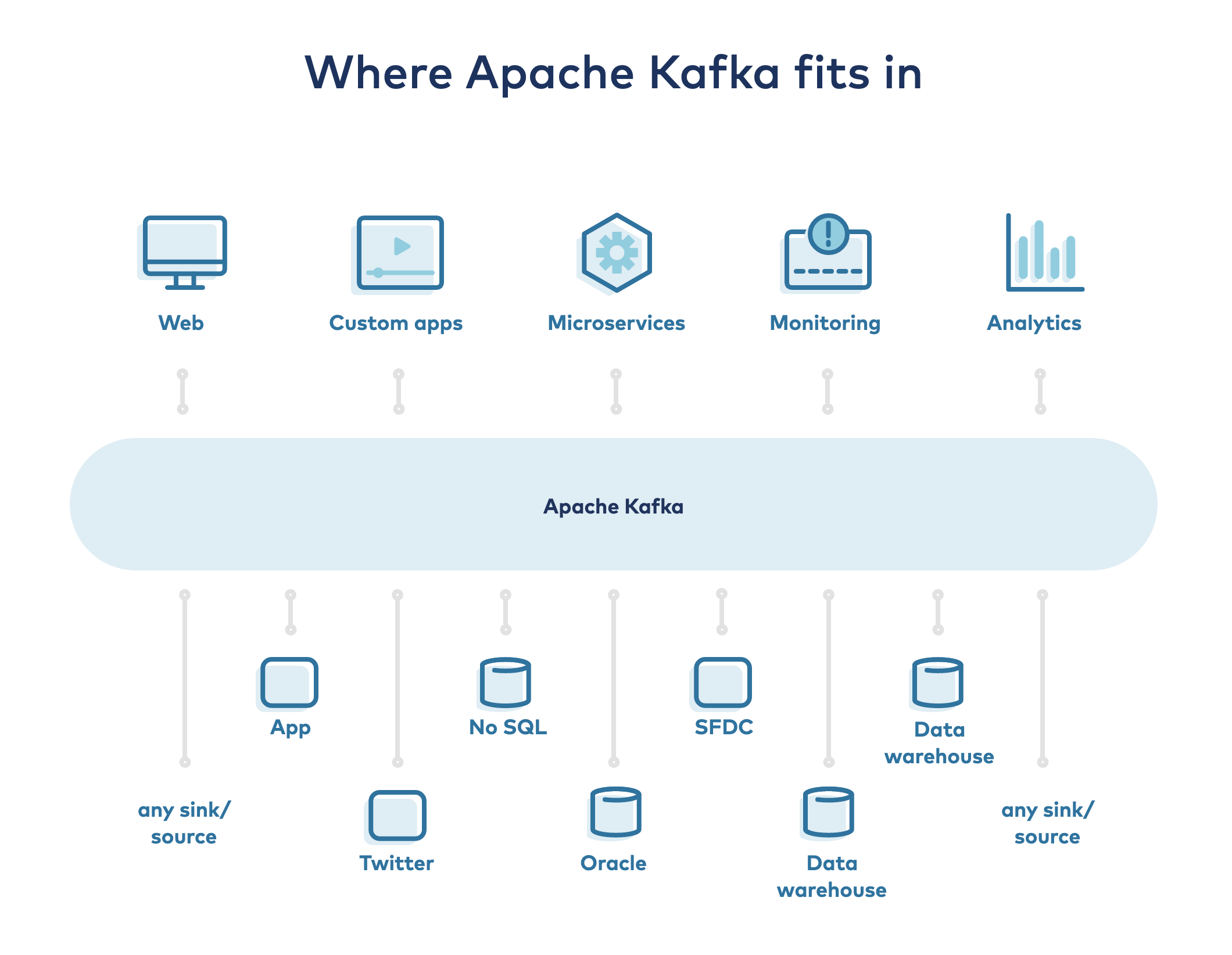
来源:Confluent 公司
Apache Kafka:Kafka 是 Confluent 平台的核心。它是一个基于开源的分布式事件流平台。它将是数据库事件(插入、更新和删除)的主存储区域。
Kafka Connect:我们使用 Kafka-Connect 从 Debezium 的 Postgres 连接器获取 Kafka 的数据,该连接器从 Postgres WAL 文件中获取事件。
在接收端,我们使用 ElasticSearch 连接器处理数据并将其加载到 ElasticSearch 中。Connect 既可以作为一个独立软件运行,也可以作为一个生产环境容错且可伸缩的服务运行。
ksqlDB:ksqlDB 允许在 Kafka 之上构建一个流处理应用程序。它在内部使用 Kafka-streams 并在事件进来时进行转换,我们使用它来丰富特定流的事件,其中包括已经在 Kafka 持久存在的其他表的事件,这些事件可能与搜索功能相关,例如 root 表中的tenant_id。
自作者的图片:基于 Apache Kafka 的 ksqlDB
使用 ksqlDB,只需编写 SQL 查询来过滤、聚合、关联和填充数据即可。例如,假设我们正在接收一个关于两个主题的事件流,其中包括与brands和brand_products相关的信息。考虑到这是一个多租户数据源,我们需要使用 tenant_id 来填充 brand_product,而 tenant_id目前只与brands相关联。然后,我们可以使用这些填充后的记录,并将它们以非标准化的形式保存在 Elasticsearch 中(以便进行搜索)。
我们可以使用一个主题来设置 KStream:
CREATE STREAM "brands"WITH ( kafka_topic = 'store.public.brands', value_format = 'avro');为了只使用其中几列并按 id 对数据流分区,我们可以创建一个名为 enriched_brands 的新数据流:
CREATE STREAM "enriched_brands"WITH ( kafka_topic = 'enriched_brands') AS SELECT CAST(brand.id AS VARCHAR) as "id", brand.tenant_id as "tenant_id", brand.name as "name" FROM "brands" brand PARTITION BY CAST(brand.id AS VARCHAR) EMIT CHANGES;然后可以通过 KTable 中的最新偏移量来实现事件集合。我们使用这个功能是为了将brand事件的当前状态与其他流关联起来。
CREATE TABLE "brands_table"AS SELECT id as "id", latest_by_offset(tenant_id) as "tenant_id" FROM "brands" group by id EMIT CHANGES; 现在我们添加了一个含有brand_id 字段的 brand_products 的新流,但没有tenant_id 字段。
CREATE STREAM "brand_products" WITH ( kafka_topic = 'store.public.brand_products', value_format = 'avro' );我们可以使用以下关联查询向 brand_products填充 tenant_id。
CREATE STREAM "enriched_brand_products" WITH ( kafka_topic = 'enriched_brand_products’ ) AS SELECT "brand"."id" as "brand_id", "brand"."tenant_id" as "tenant_id", CAST(brand_product.id AS VARCHAR) as "id", brand_product.name AS "name" FROM "brand_products" AS brand_product INNER JOIN "brands_table" "brand" ON brand_product.brand_id = "brand"."id" PARTITION BY CAST(brand_product.id AS VARCHAR) EMIT CHANGES;Schema 注册表:它在 Kafka 的上层,用于存储你在 Kafka 中提取的事件的元数据。它基于 AVRO 模式,并提供 REST 接口来存储和查询它们。它有助于确保一些 Schema 兼容性检查及其随时间发生的演变。
配置技术栈
我们使用 Docker 和 Docker-compose 来配置和部署服务。下面是准备用于构建服务所写的 docker-compose 文件,将运行 Postgres,Elasticsearch,和 Kafka 相关的服务。下面我还将解释提到的每一种服务。
Postgres 和 Elasticsearch
postgres: build: services/postgres container_name: oeso_postgres volumes: - database:/var/lib/postgresql/data env_file: - .env ports: - 5432:5432 networks: - project_network 用于 Postgres 的 Docker-compose 服务
elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:7.10.0 container_name: elasticsearch volumes: - ./services/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:ro - elasticsearch-database:/usr/share/elasticsearch/data env_file: - .env ports: - "9200:9200" - "9300:9300" networks: - project_network用于 Elasticsearch 的 Docker-compose 服务
为了从源数据库中流式的导出事件,我们需要启用逻辑解码以便从其日志中进行复制。在 Postgres 的例子中,这些日志被称为 Write-Ahead Logs (WAL) ,它们被写入一个文件中。我们需要一个逻辑解码插件,在我们的例子中,wal2json 用来提取关于持久数据库更改的易于阅读的信息,以便它可以被作为事件发送到 Kafka。
为了配置所需的扩展,你可以参考这个 Postgres Dockerfile文件。
对于 Elasticsearch 和 Postgres,我们需要在环境文件中指定一些必要的变量来设置它们,如用户名、密码等。
Zookeeper
zookeeper: image: confluentinc/cp-zookeeper:6.0.0 hostname: zookeeper container_name: zookeeper ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 networks: - project_network总的来说,Zookeeper 扮演 Kafka 这样的分布式平台的中心服务,它存储所有元数据,如 Kafka 节点状态,并持续跟踪主题或分区。
即便已经有了在无 zookeeper 的情况下运行 Kafka的替代计划,但是目前它还是管理集群所必须的。
Kafka Broker
broker: image: confluentinc/cp-enterprise-kafka:6.0.0 hostname: broker container_name: broker depends_on: - zookeeper ports: - "29092:29092" environment: KAFKA_BROKER_ID: 1 KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181" KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092 KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 networks: - project_network为了简单起见,我们将配置一个单节点 Kafka 集群。我将在本系列的第 2 部分中讨论关于多阶段集群的更多内容。
了解我们为 Kafka Broker 所做的一些配置尤其重要。
监听器(Listeners)
因为 Kafka 被设计成一个分布式平台,我们需要提供一些明确的方式来允许 Kafka Broker 彼此在内部通信,并基于您的网络结构与其他客户端进行外部通信。因此我们使用监听器来完成这个任务,监听器是主机、端口和协议的组合。
KAFKA_LISTENERS
这是一个可以由 KAFKA 绑定的网络端口列表,由主机、端口和协议组合成。默认情况下,它被设置为 0.0.0.0,即监听所有端口。
KAFKA_ADVERTISED_LISTENERS
这个值同样是主机和端口的组合,客户端将使用它来连接 KAFKA Broker。因此,如果客户端在 docker 中,它可以使用 broker:9092连接到 broker,如果在 docker 外,则返回 localhost:9092来建立和 broker 的连接。我们还需要提到监听器名称,其才能被映射到恰当的协议以建立连接。
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
这里我们将用户定义的监听器名称映射到希望用于通信的协议;它可以是PLAINTEXT(未加密)或 SSL (加密的)。这些名字在 KAFKA_LISTENERS 和 KAFKA_ADVERTISED_LISTENERS 中被进一步与 host/ip 一起使用,以便使用恰当的协议。
由于我们只配置了单节点的 Kafka 集群,因此返回的或者说发送给任何客户端的推荐地址都将是自身这同一 broker。
Schema 注册(Schema-Registry)
schema-registry: image: confluentinc/cp-schema-registry:6.0.0 hostname: schema-registry container_name: schema-registry depends_on: - zookeeper - broker ports: - "8081:8081" environment: SCHEMA_REGISTRY_HOST_NAME: schema-registry SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: "zookeeper:2181" networks: - project_network对于单节点 schema 注册,我们指定用来连接 zookeeper 的字符串,Kafka 用它存储与 schema 相关的数据。
Kafka-Connect
connect: image: confluentinc/cp-kafka-connect:6.0.0 hostname: connect container_name: connect volumes: - "./producers/debezium-debezium-connector-postgresql/:/usr/share/confluent-hub-components/debezium-debezium-connector-postgresql/" - "./consumers/confluentinc-kafka-connect-elasticsearch/:/usr/share/confluent-hub-components/confluentinc-kafka-connect-elasticsearch/" depends_on: - zookeeper - broker - schema-registry ports: - "8083:8083" environment: CONNECT_BOOTSTRAP_SERVERS: "broker:9092" KAFKA_HEAP_OPTS: "-Xms256M -Xmx512M" CONNECT_REST_ADVERTISED_HOST_NAME: connect CONNECT_REST_PORT: 8083 CONNECT_GROUP_ID: compose-connect-group CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000 CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081 CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" CONNECT_ZOOKEEPER_CONNECT: "zookeeper:2181" CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-5.5.1.jar CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor" CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor" CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components" CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR networks: - project_network我们看到一些新的参数,比如:
CONNECT_BOOTSTRAP_SERVERS:一组主机和端口组合,用于建立到 Kafka 集群的初始连接
CONNECT_KEY_CONVERTER:用于将键(key)从
connect格式序列化为与 Kafka 兼容的格式。类似地,对于CONNECT_VALUE_CONVERTER,我们使用 AvroConverter 进行序列化。
映射大量 source 和 sink 连接器插件并在 CONNECT_PLUGIN_PATH 中指定它们是非常的重要。
ksqlDB
ksqldb-server: image: confluentinc/cp-ksqldb-server:6.0.0 hostname: ksqldb-server container_name: ksqldb-server depends_on: - broker - schema-registry ports: - "8088:8088" volumes: - "./producers/debezium-debezium-connector-postgresql/:/usr/share/kafka/plugins/debezium-debezium-connector-postgresql/" - "./consumers/confluentinc-kafka-connect-elasticsearch/:/usr/share/kafka/plugins/confluentinc-kafka-connect-elasticsearch/" environment: KSQL_LISTENERS: "http://0.0.0.0:8088" KSQL_BOOTSTRAP_SERVERS: "broker:9092" KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081" KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true" KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true" KSQL_KSQL_STREAMS_MAX_TASK_IDLE_MS: 2000 KSQL_CONNECT_GROUP_ID: "ksql-connect-cluster" KSQL_CONNECT_BOOTSTRAP_SERVERS: "broker:9092" KSQL_CONNECT_KEY_CONVERTER: "io.confluent.connect.avro.AvroConverter" KSQL_CONNECT_VALUE_CONVERTER: "io.confluent.connect.avro.AvroConverter" KSQL_CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081" KSQL_CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081" KSQL_CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE: "false" KSQL_CONNECT_CONFIG_STORAGE_TOPIC: "ksql-connect-configs" KSQL_CONNECT_OFFSET_STORAGE_TOPIC: "ksql-connect-offsets" KSQL_CONNECT_STATUS_STORAGE_TOPIC: "ksql-connect-statuses" KSQL_CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 KSQL_CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 KSQL_CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 KSQL_CONNECT_PLUGIN_PATH: "/usr/share/kafka/plugins" networks: - project_network如果不打算使用 Kafka-Connect,并且不需要独立于 ksql扩展 Kafka-Connect,那么可以为 ksql设置 embedded-connect配置,这将暴露来自 ksqldb-server的连接点。
除此之外,还有一个环境变量需要考虑:
KSQL_KSQL_STREAMS_MAX_TASK_IDLE_MS:在当前版本的 ksqlDB,对于流式表关联,关联的结果可能变成不确定的,即如果在流事件之前还没有创建或更新被关联的表中的实时事件,那您可能无法关联成功。当流中的某个事件在某个特定时间戳到达时,配置这个环境变量可以做一些等待让这个事件加载到表中。这提高了关联的可预测性,但可能会导致某些性能下降。在这里我们正在努力改善这一点。
实际上,如果你不能清楚地理解上面的内容,我建议你现在就使用这个配置,因为它很有效;它实际上需要另一篇文章来详细讨论时间同步,或者如果你仍然好奇,你可以观看这个由来自 Confluent 的 Matthias j. Sax 制作的视频。
ksqldb-cli: image: confluentinc/cp-ksqldb-cli:6.0.0 container_name: ksqldb-cli depends_on: - broker - ksqldb-server entrypoint: /bin/sh tty: true networks: - project_network在测试或开发环境中,使用 ksqldb-cli服务来尝试和测试流非常方便。即使在生产环境中,如果您想探索事件流或 Ktables,或者手动创建或过滤流,也可以这样做。尽管如此,还是建议您使用 ksql 或 kafka 客户端或其 REST 端点自动创建流、表或主题,这些我们将在下面进行讨论。
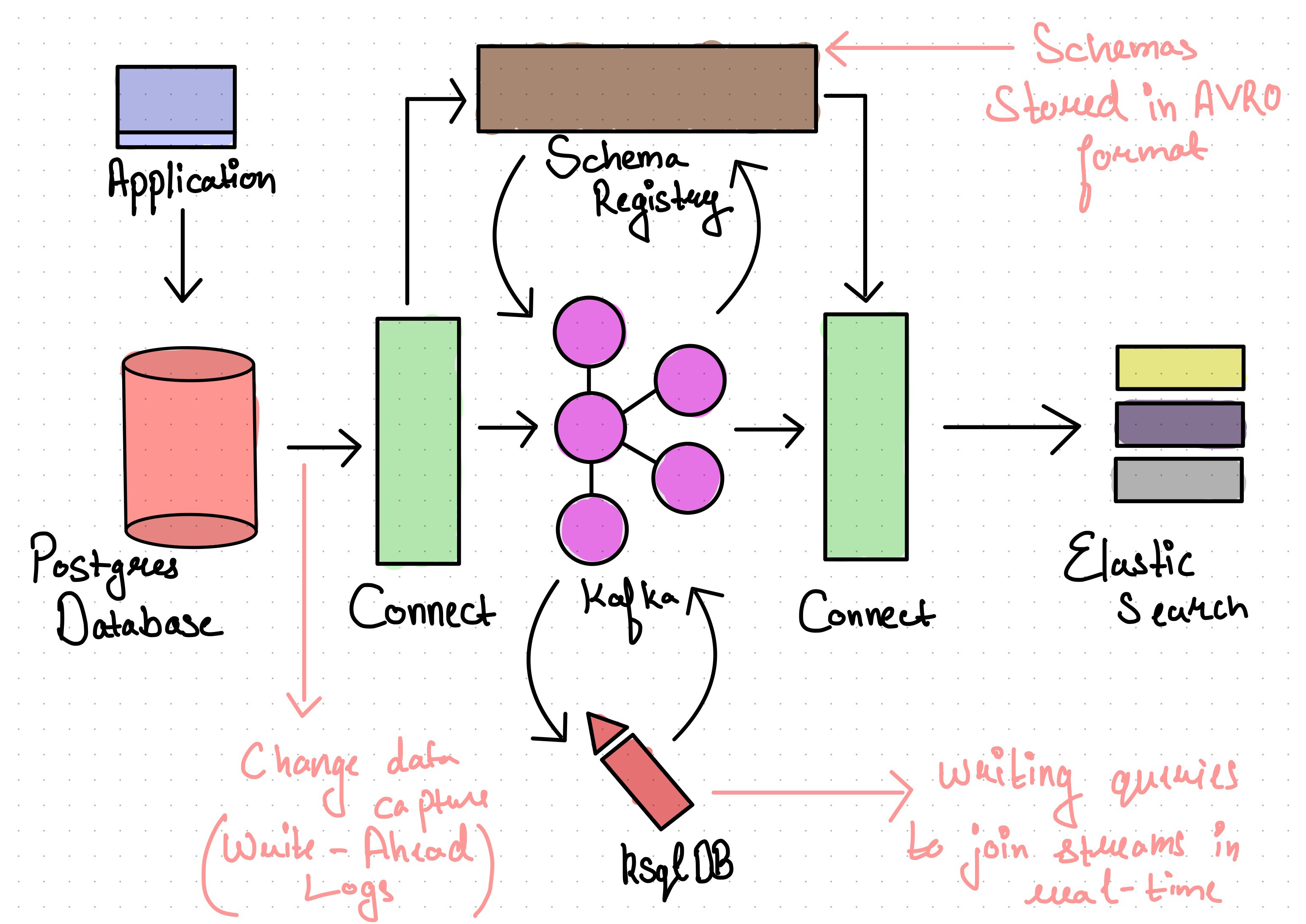
图片由作者提供:目前为止对我们的架构进行的更详细观察
初始化数据
流
streams-init: build: jobs/streams-init container_name: streams-init depends_on: - zookeeper - broker - schema-registry - ksqldb-server - ksqldb-cli - postgres - elasticsearch - connect env_file: - .env environment: ZOOKEEPER_HOSTS: "zookeeper:2181" KAFKA_TOPICS: "brands, brand_products" networks: - project_network这个服务的目的是进行流初始化和 Kafka 内部配置,以及我们正在使用的其他服务。在部署时,我们不希望在服务器上手动创建主题、流、连接等。因此,我们使用为每个服务提供的 REST 服务,并编写 shell 脚本来自动化这个过程。
我们的配置脚本如下所示:
#!/bin/bash# Setup ENV variables in connectors json filessed -i "s/POSTGRES_USER/${POSTGRES_USER}/g" connectors/postgres.jsonsed -i "s/POSTGRES_PASSWORD/${POSTGRES_PASSWORD}/g" connectors/postgres.jsonsed -i "s/POSTGRES_DB/${POSTGRES_DB}/g" connectors/postgres.jsonsed -i "s/ELASTIC_PASSWORD/${ELASTIC_PASSWORD}/g" connectors/elasticsearch.json# Simply wait until original kafka container and zookeeper are started.export WAIT_HOSTS=zookeeper:2181,broker:9092,schema-registry:8081,ksqldb-server:8088,elasticsearch:9200,connect:8083export WAIT_HOSTS_TIMEOUT=300/wait# Parse string of kafka topics into an array# https://stackoverflow.com/a/10586169/4587961kafkatopicsArrayString="$KAFKA_TOPICS"IFS=', ' read -r -a kafkaTopicsArray <<< "$kafkatopicsArrayString"# A separate variable for zookeeper hosts.zookeeperHostsValue=$ZOOKEEPER_HOSTS# Terminate all queriescurl -s -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "SHOW QUERIES;"}' | \ jq '.[].queries[].id' | \ xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "TERMINATE 'foo';"}' # Drop All Tablescurl -s -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "SHOW TABLES;"}' | \ jq '.[].tables[].name' | \ xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "DROP TABLE \"foo\";"}'# Drop All Streamscurl -s -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "SHOW STREAMS;"}' | \ jq '.[].streams[].name' | \ xargs -Ifoo curl -X "POST" "http://ksqldb-server:8088/ksql" \ -H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \ -d '{"ksql": "DROP STREAM \"foo\";"}' # Create kafka topic for each topic item from split array of topics.for newTopic in "${kafkaTopicsArray[@]}"; do # https://kafka.apache.org/quickstart curl -X DELETE http://elasticsearch:9200/enriched_$newTopic --user elastic:${ELASTIC_PASSWORD} curl -X DELETE http://schema-registry:8081/subjects/store.public.$newTopic-value kafka-topics --create --topic "store.public.$newTopic" --partitions 1 --replication-factor 1 --if-not-exists --zookeeper "$zookeeperHostsValue" curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" --data @schemas/$newTopic.json http://schema-registry:8081/subjects/store.public.$newTopic-value/versionsdonecurl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d { "ksql": "CREATE STREAM \\"brands\\" WITH (kafka_topic = \'store.public.brands\', value_format = \'avro\');", "streamsProperties": {} }'curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d { "ksql": "CREATE STREAM \\"enriched_brands\\" WITH ( kafka_topic = \'enriched_brands\' ) AS SELECT CAST(brand.id AS VARCHAR) as \\"id\\", brand.tenant_id as \\"tenant_id\\", brand.name as \\"name\\" from \\"brands\\" brand partition by CAST(brand.id AS VARCHAR) EMIT CHANGES;", "streamsProperties": {} }'curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d { "ksql": "CREATE STREAM \\"brand_products\\" WITH ( kafka_topic = \'store.public.brand_products\', value_format = \'avro\' );", "streamsProperties": {} }'curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d { "ksql": "CREATE TABLE \\"brands_table\\" AS SELECT id as \\"id\\", latest_by_offset(tenant_id) as \\"tenant_id\\" FROM \\"brands\\" group by id EMIT CHANGES;", "streamsProperties": {} }'curl -X "POST" "http://ksqldb-server:8088/ksql" -H "Accept: application/vnd.ksql.v1+json" -d { "ksql": "CREATE STREAM \\"enriched_brand_products\\" WITH ( kafka_topic = \'enriched_brand_products\' ) AS SELECT \\"brand\\".\\"id\\" as \\"brand_id\\", \\"brand\\".\\"tenant_id\\" as \\"tenant_id\\", CAST(brand_product.id AS VARCHAR) as \\"id\\", brand_product.name AS \\"name\\" FROM \\"brand_products\\" AS brand_product INNER JOIN \\"brands_table\\" \\"brand\\" ON brand_product.brand_id = \\"brand\\".\\"id\\" partition by CAST(brand_product.id AS VARCHAR) EMIT CHANGES;", "streamsProperties": {} }'curl -X DELETE http://connect:8083/connectors/enriched_writercurl -X "POST" -H "Content-Type: application/json" --data @connectors/elasticsearch.json http://connect:8083/connectorscurl -X DELETE http://connect:8083/connectors/event_readercurl -X "POST" -H "Content-Type: application/json" --data @connectors/postgres.json http://connect:80这就是我们目前的工作方式:
在运行任何任务之前,我们确保所有的服务都准备好了;
我们需要确保主题在 Kafka 上已存在,或者我们创建新的主题;
即使有 schema 更新,我们的数据流也应该是可用的;
当底层数据 srouce 或 sink 的密码或版本更改,需要再次创建连接。
共享这个配置脚本的目的只是为了演示一种自动化这些 pipeline 的方法。完全相同的配置可能并不适合您,但是自动化工作流和避免在任何环境中的进行手工部署的想法始终是一样的。
为了让这个数据基础设施能够真正快速地运行起来,请参考 Github 仓库:
在你的终端中克隆代码库并执行以下操作:
cp default.env .envdocker-compose up -d
在 Postgres 数据库 store中创建 brands 和 brand_products 表:
CREATE TABLE brands ( id serial PRIMARY KEY, name VARCHAR (50), tenant_id INTEGER);CREATE TABLE brand_products ( id serial PRIMARY KEY, brand_id INTEGER, name VARCHAR(50));在brands表中插入一些记录:
INSERT INTO brands VALUES(1, 'Brand Name 1', 1);INSERT INTO brands VALUES(2, 'Brand Name 2', 1);INSERT INTO brands VALUES(3, 'Brand Name 3', 2);INSERT INTO brands VALUES(4, 'Brand Name 4', 2);然后brand_products表中的一些记录:
INSERT INTO brand_products VALUES(1, 1, 'Product Name 1');INSERT INTO brand_products VALUES(2, 2, 'Product Name 2');INSERT INTO brand_products VALUES(3, 3, 'Product Name 3');INSERT INTO brand_products VALUES(4, 4, 'Product Name 4');INSERT INTO brand_products VALUES(5, 1, 'Product Name 5');在 Elasticsearch 的中查看填充了tenant_id 的brand_products :
curl localhost:9200/enriched_brand_products/_search --user elastic:your_password我将持续为上述代码库做出贡献:添加在 Kubernetes 部署多节点 Kafka 基础设施的配置,编写更多连接器,使用期望的服务实现即插即用架构的框架。请在这里自由的提交贡献,或让我知道在你在当前配置中所遇到的任何数据工程问题。
下一步
我希望这篇文章能给你一个关于部署和运行完整 Kafka 技术栈的清晰思路,这是一个构建实时流处理应用程序的基础且有效的示例。
根据产品或公司的自身特点,部署过程根据需要可能会有所不同。我还计划在本系列的下一部分中就这样一个系统在可伸缩性方面进行探讨,那将是关于在相同使用场景下如何在 Kubernetes 上部署这样的基础设施的讨论。




