背景介绍
2016 年底,京东新一代容器引擎平台 JDOS2.0 上线,京东从 OpenStack 切换到 Kubernetes。到目前为止,JDOS2.0 集群 2w+Pod 稳定运行,业务按 IDC 分布分批迁移到新平台,目前已迁移 20%,计划 Q2 全部切换到 Kubernetes 上,业务研发人员逐渐适应从基于自动部署上线切换到以镜像为中心的上线方式。JDOS2.0 统一提供京东业务,大数据实时离线,机器学习(GPU)计算集群。从 OpenStack 切换到 Kubernetes,这中间又有哪些经验值得借鉴呢?
本文将为读者介绍京东商城研发基础平台部如何从 0 到 JDOS1.0 再到 JDOS2.0 的发展历程和经验总结,主要包括:
- 如何找准痛点作为基础平台系统业务切入点;
- 如何一边实践一边保持技术视野;
- 如何运维大规模容器平台;
- 如何把容器技术与软件定义数据中心结合。
集群建设历史
物理机时代(2004-2014)
在 2014 年之前,公司的应用直接部署在物理机上。在物理机时代,应用上线从申请资源到最终分配物理机时间平均为一周。应用混合部署在一起,没有隔离的应用混部难免互相影响。为减少负面影响,在混部的比例平均每台物理机低于 9 个不同应用的 Tomcat 实例,因此造成了物理机资源浪费严重,而且调度极不灵活。物理机失效导致的应用实例迁移时间以小时计,自动化的弹性伸缩也难于实现。为提升应用部署效率,公司开发了诸如编译打包、自动部署、日志收集、资源监控等多个配套工具系统。
容器化时代(2014-2016)
2014 年第三季度,公司首席架构师刘海锋带领基础平台团队对于集群建设进行重新设计规划,Docker 容器是主要的选型方案。当时 Docker 虽然已经逐渐兴起,但是功能略显单薄,而且缺乏生产环境,特别是大规模生产环境的实践。团队对于 Docker 进行了反复测试,特别是进行了大规模长时间的压力和稳定性测试。根据测试结果,对于 Docker 进行了定制开发,修复了 Device Mapper 导致 crash、Linux 内核等问题,并增加了外挂盘限速、容量管理、镜像构建层级合并等功能。
对于容器的集群管理,团队选择了 OpenStack+nova-docker 的架构,用管理虚拟机的方式管理容器,并定义为京东第一代容器引擎平台 JDOS1.0(JD DataCenter OS)。JDOS1.0 的主要工作是实现了基础设施容器化,应用上线统一使用容器代替原来的物理机。在应用的运维方面,兼用了之前的配套工具系统。研发上线申请计算资源由之前的一周缩短到分钟级,不管是 1 台容器还是 1 千台容器,在经过计算资源池化后可实现秒级供应。同时,应用容器之间的资源使用也得到了有效的隔离,平均部署应用密度提升 3 倍,物理机使用率提升 3 倍,带来极大的经济收益。
我们采用多 IDC 部署方式,使用统一的全局 API 开放对接到上线系统,支撑业务跨 IDC 部署。单个 OpenStack 集群最大是 1 万台物理计算节点,最小是 4K 台计算节点,第一代容器引擎平台成功地支撑了 2015 和 2016 年的 618 和双十一的促销活动。至 2016 年 11 月,已经有 15W+ 的容器在稳定运行。
在完成的第一代容器引擎落地实践中,团队推动了业务从物理机上迁移到容器中来。在 JDOS1.0 中,我们使用的 IaaS 的方式,即使用管理虚拟机的方式来管理容器,因此应用的部署仍然严重依赖于物理机时代的编译打包、自动部署等工具系统。但是 JDOS1.0 的实践是非常有意义的,其意义在于完成了业务应用的容器化,将容器的网络、存储都逐渐磨合成熟,而这些都为我们后面基于 1.0 的经验,开发一个全新的应用容器引擎打下了坚实的基础。
新一代应用容器引擎(JDOS 2.0)
1.0 的痛点
JDOS1.0 解决了应用容器化的问题,但是依然存在很多不足。
首先是编译打包、自动部署等工具脱胎于物理机时代,与容器的开箱即用理念格格不入,容器启动之后仍然需要配套工具系统为其分发配置、部署应用等等,应用启动的速度受到了制约。
其次,线上线下环境仍然存在不一致的情况,应用运行的操作环境,依赖的软件栈在线下自测时仍然需要进行单独搭建。线上线下环境不一致也造成了一些线上问题难于在线下复现,更无法达到镜像的“一次构建,随处运行”的理想状态。
再次,容器的体量太重,应用需要依赖工具系统进行部署,导致业务的迁移仍然需要工具系统人工运维去实现,难以在通用的平台层实现灵活的扩容缩容与高可用。
另外,容器的调度方式较为单一,只能简单根据物理机剩余资源是否满足要求来进行筛选调度,在提升应用的性能和平台的使用率方面存在天花板,无法做更进一步提升。
平台架构
鉴于以上不足,在当 JDOS1.0 从一千、两千的容器规模,逐渐增长到六万、十万的规模时,我们就已经启动了新一代容器引擎平台 (JDOS 2.0) 研发。JDOS 2.0 的目标不仅仅是一个基础设施的管理平台,更是一个直面应用的容器引擎。JDOS 2.0 在原 1.0 的基础上,围绕 Kubernetes,整合了 JDOS 1.0 的存储、网络,打通了从源码到镜像,再到上线部署的 CI/CD 全流程,提供从日志、监控、排障、终端、编排等一站式的功能。JDOS 2.0 的平台架构如下图所示。
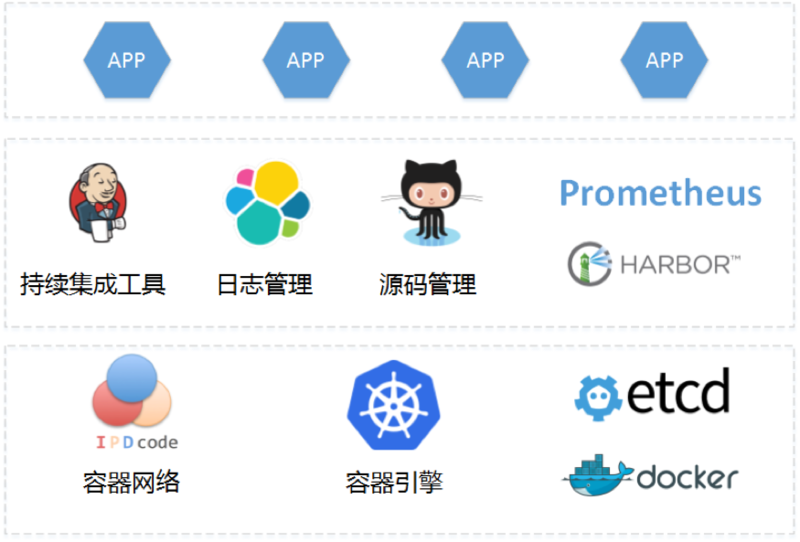
功能
选型
容器工具
Docker
容器网络
Cane
容器引擎
Kubernetes
镜像中心
Harbor
持续集成工具
Jenkins
日志管理
Logstash + Elastic Search
监控管理
Prometheus
在 JDOS 2.0 中,我们定义了系统与应用两个级别。一个系统包含若干个应用,一个应用包含若干个提供相同服务的容器实例。一般来说,一个大的部门可以申请一个或者多个系统,系统级别直接对应于 Kubernetes 中的 namespace,同一个系统下的所有容器实例会在同一个 Kubernetes 的 namespace 中。应用不仅仅提供了容器实例数量的管理,还包括版本管理、域名解析、负载均衡、配置文件等服务。
不仅仅是公司各个业务的应用,大部分的 JDOS 2.0 组件 (Gitlab/Jenkins/Harbor/Logstash/Elastic Search/Prometheus) 也实现了容器化,在 Kubernetes 平台上进行部署。
开发者一站式解决方案
JDOS 2.0 实现了以镜像为核心的持续集成和持续部署。
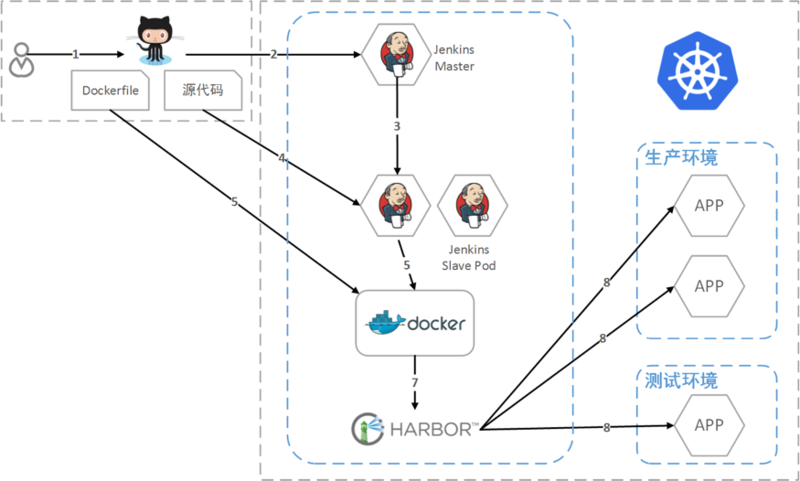
- 开发者提交代码到源码管理库
- 触发 Jenkins Master 生成构建任务
- Jenkins Master 使用 Kubernetes 生成 Jenkins Slave Pod
- Jenkins Slave 拉取源码进行编译打包
- 将打包好的文件和 Dockerfile 发送到构建节点
- 在构建节点中构建生成镜像
- 将镜像推送到镜像中心 Harbor
- 根据需要在不同环境生产 / 更新应用容器
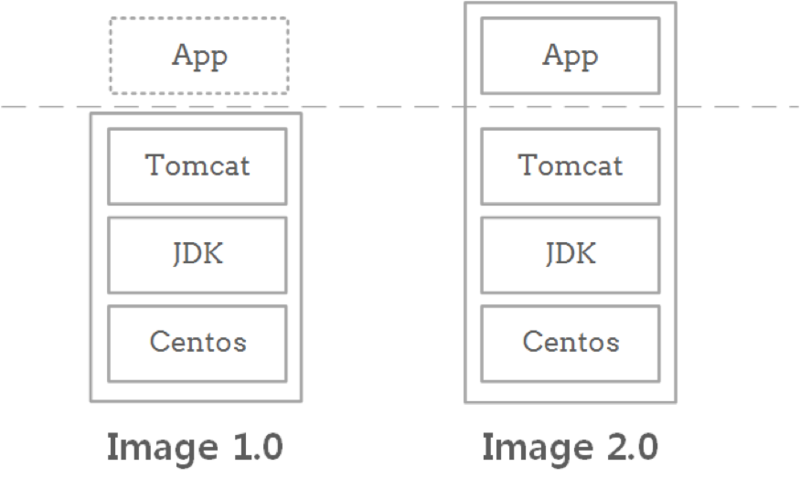
在 JDOS 1.0,容器的镜像主要包含了操作系统和应用的运行时软件栈。APP 的部署仍然依赖于以往运维的自动部署等工具。在 2.0 中,我们将应用的部署在镜像的构建过程中完成,镜像包含了 APP 在内的完整软件栈,真正实现了开箱即用。
网络与外部服务负载均衡
JDOS 2.0 继承了 JDOS 1.0 的方案,采用 OpenStack-Neutron 的 VLAN 模式,该方案实现了容器之间的高效通信,非常适合公司内部的集群环境。每个 Pod 占用 Neutron 中的一个 port,拥有独立的 IP。基于 CNI 标准,我们开发了新的项目 Cane,用于将 Kubelet 和 Neutron 集成起来。
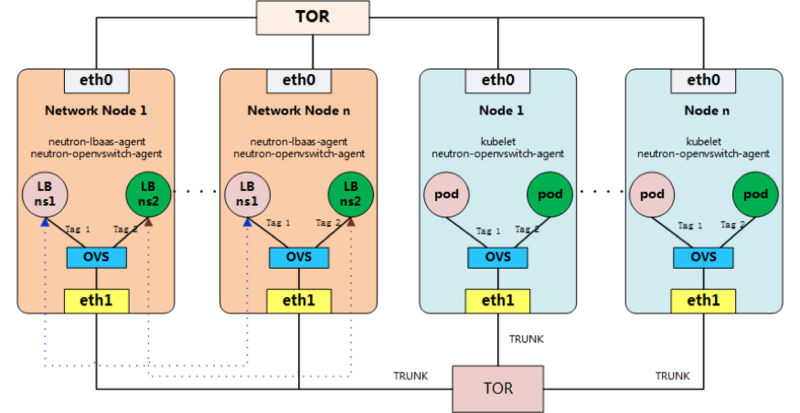
同时,Cane 负责 Kubernetes 中 service 中的 LoadBalancer 的创建。当有 LoadBalancer 类型的 service 创建 / 删除 / 修改时,Cane 将对应的调用 Neutron 中创建 / 删除 / 修改 LBaaS 的服务接口,从而实现外部服务负载均衡的管理。另外,Cane 项目中的 Hades( https://github.com/ipdcode/hades 京东开源在 GitHub 上) 组件为容器提供了内部的 DNS 解析服务。
灵活调度
JDOS 2.0 接入了包括大数据、Web 应用、深度学习等多种类型的应用,并为每种应用根据类型采用了不同的资源限制方式,并打上了 Kubernetes 的不同标签。基于多样的标签,我们实现了更为多样和灵活的调度方式,并在部分 IDC 实验性地混合部署了在线任务和离线任务。相较于 1.0,整体资源利用率提升了约 30%。

推广与展望
有了 1.0 的大规模稳定运营作为基础,业务对于使用容器已经给予了相当的信任和支持,但是平台化的容器和基础设施化的容器对于应用的要求也不尽相同。比如,平台化的应用容器 IP 并不是固定的,因为当一个容器失效,平台会自动启动另一个容器来替代,新的容器 IP 可能与原 IP 不同。这就要求服务发现不能再以容器 IP 作为主要标识,而是需要采用域名,负载均衡或者服务自注册等方式。因此,在 JDOS2.0 推广过程中,我们也推动了业务方主要关注应用服务,减少对单个容器等细节的操作,以此自研了全新智能域名解析服务和基于 DPDK 高性能负载均衡服务,与 Kubernetes 有效地配合支持。
近两年,随着大数据、人工智能等研发规模的扩大,消耗的计算资源也随之增大。因此,我们将大数据、深度学习等离线计算服务也迁移进入 JDOS2.0。目前是主要采用单独划分区域的方式,各自的服务仍然使用相对独立的计算资源,但是已经纳入 JDOS2.0 平台进行统一管理,并通过机器学习方法,提升计算资源使用效率。
灵活的标签给予了集群调度无限的可能。未来我们将丰富调度算法,并配以节能的相关技术,提高集群整体的 ROI,从而为打造一个低能耗、高性能的绿色数据中心打下基础。
回望与总结
Kubernetes 方案与 OpenStack 方案相比,架构更为简洁。OpenStack 整体运营成本较高,因为牵涉多个项目,每个项目各自有多个不同的组件,组件之间通过 RPC(一般使用 MQ)进行通讯。为提高可用性和性能,还需要考虑各个组件的扩展和备份等。这些都加剧了整体方案的复杂性,问题的排查和定位难度也相应提升,对于运维人员的要求也相应提高。
与之相比,Kubernetes 的组件较少,功能清晰。其核心理念(对于资源和任务的理解)、灵活的设计(标签)和声明式的 API 是对 Google 多年来 Borg 系统的最好总结,而其提供的丰富的功能,使得我们可以投入更多精力在平台的整个生态上,比如网络性能的提升、容器的精准调度上,而不是平台本身。尤其是,副本控制的功能受到了业务线上应用运维工程师的追捧,应用的扩容缩容和高可用实现了秒级完成。JDOS 2.0 目前已经接入了约 20% 的应用,部署有 2 个集群,目前日常运行的容器有 20000 个,仍在逐步推广中。
真诚感谢 Kubernetes 社区和相关开源项目的贡献者,目前京东已经加入 CNCF 组织,并在社区排名达到 TOP30。
作者介绍
鲍永成,京东基础平台部技术总监,带领基础平台部集群技术团队从 2014 年上线京东容器引擎平台 JDOS1.0 到现在的 JDOS2.0,作为坚实的统一计算运行平台承载京东全部业务稳定运行。目前主要工作方向是 JDOS2.0 研发和京东第一代软件定义数据中心建设。
感谢孟夕对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




