1、 前言
volatile 关键字可能是 Java 开发人员“熟悉而又陌生”的一个关键字。本文将从 volatile 关键字的作用、开销和典型应用场景以及 Java 虚拟机对 volatile 关键字的实现这几个方面为读者全面深入剖析 volatile 关键字。
volatile 字面上有“挥发性的,不稳定的”意思,它是用于修饰可变共享变量(Mutable Shared Variable)的一个关键字。所谓“共享”是指一个变量能够被多个线程访问(包括读 / 写),所谓“可变”是指变量的值可以发生变化。换而言之,volatile 关键字用于修饰多个线程并发访问的同一个变量,这些线程中至少有一个线程会更新这个变量的值。我们称 volatile 修饰的变量为 volatile 变量。我们知道锁的作用包括保障原子性、保障可见性以及保障有序性。volatile 常被称为“轻量级锁”,其作用与锁有类似的地方——volatile 也能够保障原子性(仅保障 long/double 型变量访问操作的原子性)、保障可见性以及保障有序性。
本文所提及的“Java 虚拟机”如无特别说明,均特指 Oracle 公司的 HotSpot Java 虚拟机。
2. 保障 long/double 型变量访问操作的原子性
不可分割的操作被称为原子操作(Atomic Operation)。所谓不可分割(Indivisible)是指一个操作从其执行线程以外的其他线程看来,该操作要么已经完成要么尚未开始,也就是说其他线程不会看到该操作的中间结果。如果一个操作是原子操作,那么我们就称该操作具有原子性(Atomicity)。
Java 语言规范(Java Language Specification,JLS)规定,Java 语言中针对 long/double 型以外的任何变量(包括基础类型变量和引用型变量)进行的读、写操作都是原子操作,即 Java 语言规范本身并不规定针对 long/double 型变量进行读、写操作具有原子性。一个 long/double 型变量的读 / 写操作在 32 位 Java 虚拟机下可能会被分解为两个子步骤(比如先写低 32 位,再写高 32 位)来实现,这就导致一个线程对 long/double 型变量进行的写操作的中间结果可以被其他线程所观察到,即此时针对 long/double 型变量的访问操作不是原子操作。清单 1 所示的实验展示了这点。
清单 1 long/double 型变量写操作的原子性问题 Demo
/**
* 本 Demo 必须使用 32 位 Java 虚拟机才能看到非原子操作的效果. <br>
* 运行本 Demo 时也可以指定虚拟机参数“-client”
*
* @author Viscent Huang
*/
public class NonAtomicAssignmentDemo implements Runnable {
static long value = 0;
private final long valueToSet;
public NonAtomicAssignmentDemo(long valueToSet) {
this.valueToSet = valueToSet;
}
public static void main(String[] args) {
// 线程 updateThread1 将 data 更新为 0
Thread updateThread1 = new Thread(new NonAtomicAssignmentDemo(0L));
// 线程 updateThread2 将 data 更新为 -1
Thread updateThread2 = new Thread(new NonAtomicAssignmentDemo(-1L));
updateThread1.start();
updateThread2.start();
// 不进行实际输出的 OutputStream
final DummyOutputStream dos = new DummyOutputStream();
try (PrintStream dummyPrintSteam = new PrintStream(dos);) {
// 共享变量 value 的快照(即瞬间值)
long snapshot;
while (0 == (snapshot = value) || -1 == snapshot) {
// 不进行实际的输出,仅仅是为了阻止 JIT 编译器做循环不变表达式外提优化
dummyPrintSteam.print(snapshot);
}
System.err.printf("Unexpected data: %d(0x%016x)", snapshot, snapshot);
}
System.exit(0);
}
static class DummyOutputStream extends OutputStream {
@Override
public void write(int b) throws IOException {
// 不实际进行输出
}
}
@Override
public void run() {
for (;;) {
value = valueToSet;
}
}
}
使用 32 位(而不是 64 位)Java 虚拟机运行清单 1 所示的 Demo 我们可以看到该程序的输出是:
Unexpected data: 4294967295(0x00000000ffffffff)或者,
Unexpected data: -4294967296(0xffffffff00000000)可见,main 线程读取到共享变量 value 的值可能既不是 0(对应无符号 16 进制数 0x0000000000000000)也不是 -1(对应无符号 16 进制数 0xffffffffffffffff),而是其他两个线程更新 value 时的“中间结果”——4294967295(对应无符号 16 进制数 0x00000000ffffffff)或者 -4294967296(对应无符号 16 进制数 0xffffffff00000000),即一个线程对 value 变量的低(Lower)32 位(4 个字节)更新与另外一个线程对 value 变量的高(Higher)32 位(4 个字节)更新所“混合”出来的一个非预期的错误结果。因此,上述 Demo 对共享变量 value 的写操作并非一个原子操作。这是由于:Java 平台中,long/double 型变量会占用 64 位(8 个字节)的存储空间,而 32 位的 Java 虚拟机对这种变量的写操作可能会被分解为两个子步骤来实施,比如先写低 32 位,再写高 32 位。那么,多个线程试图共享同一个这样的变量时就可能出现一个线程在写高 32 位的时候,另外一个线程恰好正在写低 32 位,而此刻第三个线程读取这个变量时所读取到的变量值仅仅是其他两个线程更新这个变量的中间结果。
32 位虚拟机下,一个 long/double 型变量读操作同样也可能会被分解为两个子步骤来实现,比如先读取低 32 位到寄存器中,再读取高 32 位到寄存器中。这种实现同样也会导致与上述 Demo 所展示的相似的效果,即一个线程可以读取到其他线程对 long/double 型变量写操作的中间结果。因此,在这种 Java 虚拟机实现下,long/double 型变量读操作同样也不是原子操作。
上述 Demo 更多的是从系统(Java 虚拟机)层面展示原子性问题。那么,在业务层面我们是否也可能遇到类似上述的原子性问题呢?如清单 2 所示,假设线程 T1 通过执行 updateHostInfo 方法来更新主机信息(HostInfo),线程 T2 则通过执行 connectToHost 方法来读取主机信息,并据此与相应的主机建立网络连接。那么,updateHostInfo 方法中的操作(更新主机 IP 地址和端口号)必须是一个原子操作,即这个操作必须是“不可分割”的。否则,可能出现这样的情形:假设 hostInfo 的初始值表示的是 IP 地址为“192.168.1.101”、端口号为 8081 的主机,T1 执行 updateHostInfo 方法试图将 hostInfo 更新为 IP 地址为“192.168.1.100”、端口号为 8080 的主机的时候,T2 可能刚好执行 connectToHost 方法,那么此时由于 T1 可能刚刚执行完语句①而未开始语句②(即只更新完 IP 地址而尚未更新端口号),因此 T2 可能读取到 IP 地址为“192.168.1.100”、而端口号却仍然为 8081 的主机信息,即 T2 读取到了一个错误的主机信息(IP 地址为“192.168.1.100”的主机上面并没有开启侦听端口 8081,它开启的 8080)从而无法建立网络连接!这里的错误是由于 updateHostInfo 方法中的操作不是原子操作(不具备“不可分割”的特性)而使其他线程读取了脏数据(错误的主机信息)导致的。
清单 2 业务层面的原子操作问题 Demo
public class AtomicityExample {
private HostInfo hostInfo;
public void updateHostInfo(String ip, int port) {
// 以下操作不是原子操作
hostInfo.setIp(ip);// 语句①
hostInfo.setPort(port);// 语句②
}
public void connectToHost() {
String ip = hostInfo.getIp();
int port = hostInfo.getPort();
connectToHost(ip, port);
}
private void connectToHost(String ip, int port) {
// ...
}
public static class HostInfo {
private String ip;
private int port;
public HostInfo(String ip, int port) {
this.ip = ip;
this.port = port;
}
//...
}
}
当然,上述原子性问题都可以通过加锁解决。不过,Java 语言规范特别地规定针对 volatile 修饰的 long/double 型变量进行的读、写操作也具有原子性。换而言之,volatile 关键字能够保障 long/double 型变量访问操作的原子性。需要注意的是,volatile 对原子性的保障仅限于共享变量写和读操作本身。对共享变量进行的赋值操作实际上往往是一个复合操作,volatile 并不能保障这些赋值操作的原子性。例如,如下针对 volatile 变量 counter1 赋值语句:
volatile counter1 = counter2 + 1;如果 counter2 是一个局部变量,那么上述赋值语句实际上就是针对 counter1 的写操作,因此在 volatile 关键字的作用下上述赋值操作具有原子性。如果 counter2 也是一个共享变量,那么上述赋值语句就不具有原子性。这是由于此时上述语句实际上可以被分解为如下几个子操作(伪代码表示):
r1 = counter2; // 子操作①:将共享变量 counter2 的值加载到寄存器 r1
r1 = r1 + 1;// 子操作②:将寄存器 r1 的值增加 1
counter1 = r1;// 子操作③:将寄存器 r1 的值写入共享变量 counter1(内存)
volatile 关键字并不像锁那样具有排他性,在写操作方面,其对原子性的保障也仅仅作用于上述的子操作③(变量写操作)。因此,一个线程在执行到子操作③的时候,其他线程可能已经更新了共享变量 counter2 的值,这就使得子操作③的执行线程实际上是向共享变量 counter1 写入了一个旧值。
因此,对 volatile 变量的赋值操作其表达式右边不能包含任何共享变量(包括被赋值的 volatile 变量本身)。
依照 Java 语言规范,对 volatile 修饰的 long/double 型变量的进行的读操作也具有原子性。因此,我们说 volatile 能够保障 long/double 型变量访问操作的原子性。
3. 保障可见性
可见性(Visibility)是指一个线程(读线程)是否或者在什么情况下能够读取到其他线程(写线程)对共享变量所做的更新。由于软件、硬件的原因,一个线程(写线程)对共享变量进行更新之后,其他线程(读线程)再来读取该变量的时候,这些读线程可能无法读取到写线程对共享变量所做的更新,清单 3 展示了这点。
清单 3 可见性问题 Demo
public class VisibilityDemo {
public static void main(String[] args) throws InterruptedException {
CountingThread backgroundThread = new CountingThread();
backgroundThread.start();
Thread.sleep(1000);
backgroundThread.cancel();
backgroundThread.join();
System.out.printf("count:%s",backgroundThread.count);
}
}
class CountingThread extends Thread {
// 线程停止标志
private boolean ready = false;
public int count = 0;
@Override
public void run() {
while (!ready) {
count++;
}
}
public void cancel() {
ready = true;
}
}
该 Demo 中,我们为子线程 backgroundThread(类型为 CountingThread)设置了一个停止标记 ready。当 ready 值为 true 时,子线程通过使其 run 方法返回而实现线程的终止。然而,使用 Java 虚拟机的 server 模式运行上述 Demo,我们可以发现该 Demo 中的子线程并没有像我们预期的那样在 1 秒钟之后终止而是一直在运行!由此可见,主线程(main 线程)对共享变量 ready 所做的更新(将 ready 设置为 true)并没有被子线程 backgroundThread 所读取到。究其原因,这是 HotSpot 虚拟机的 C2 编译器(Just In Time 编译器)在将字节码动态编译为本地机器码的过程中执行循环不变量外提( Loop-invariant code motion)优化的结果:由于该 Demo 中的共享变量 ready 并没有采用 volatile 修饰,因此 C2 编译器会认为该变量并不会被多个线程访问(实际上有多个线程访问该变量),于是 C2 编译器为了提升代码执行效率而将 CountingThread.run() 中的 while 循环语句优化为与如下伪代码等效的机器码:
if(!ready){// 对变量 ready 的判断被提升到循环语句之外
while(true){
count++;
}
}
这种优化可以通过查看 C2 编译器所产生的汇编代码来确认,如图 1 所示。不幸的是,这种优化导致了死循环!
图 1 C2 编译器循环不变量外提优化所产生的汇编代码
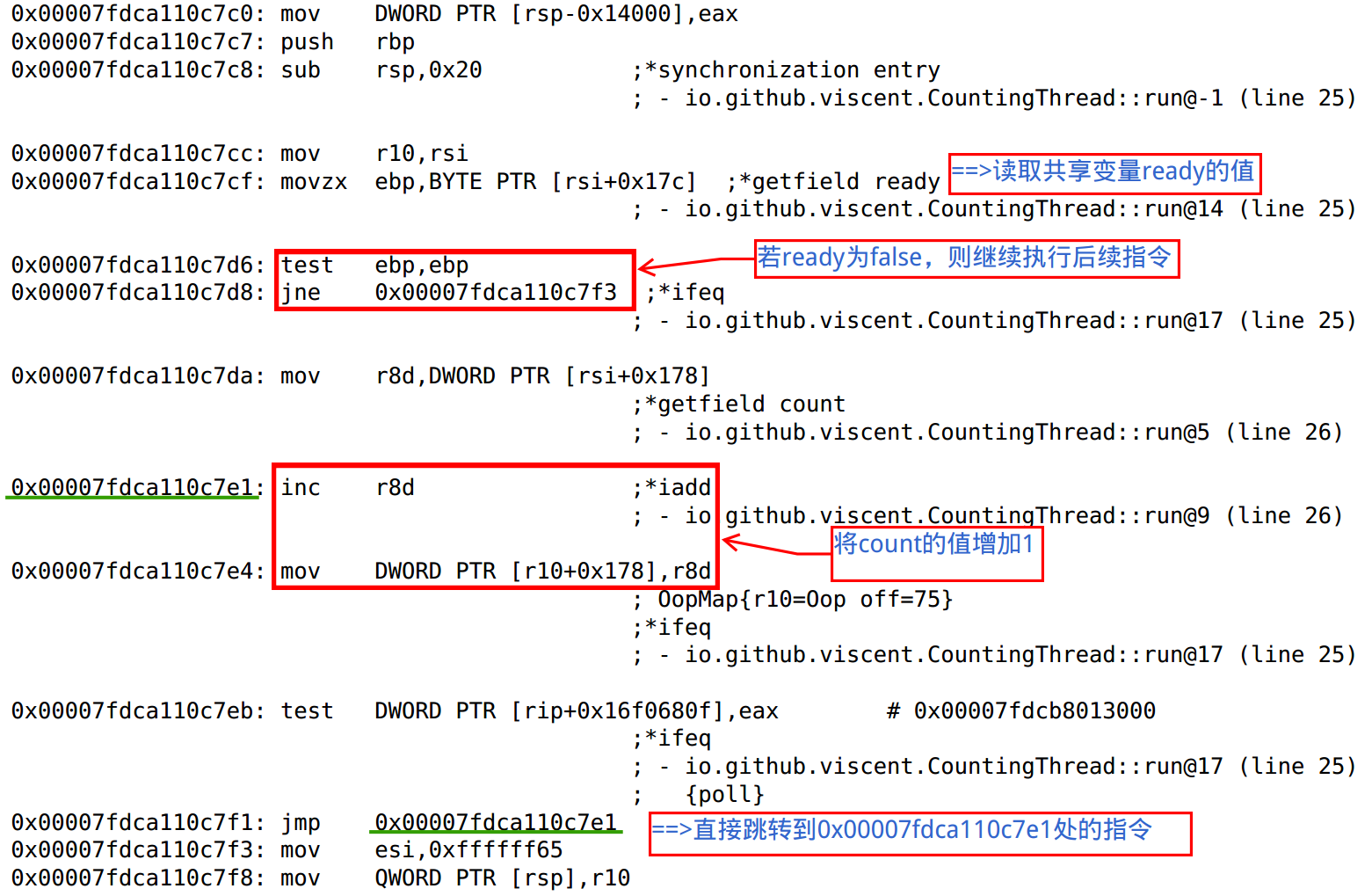
如果我们采用 volatile 修饰上述 Demo 中的 ready 变量,那么 C2 编译器便会“意识”到 ready 是一个共享变量,因此就不会对 CountingThread.run() 中的 while 循环语句执行循环不变量外提优化从而避免了死循环。
当然,硬件的因素也可能导致可见性问题。处理器为了提高内存写操作的效率而引入的硬件部件写缓冲器(Store Buffer)和无效化队列(Invalidate Queue)都可能导致一个线程对共享变量所做的更新无法被后续线程所读取到。
Java 语言规范规定,对于同一个 volatile 变量,一个线程(写线程)对该变量进行更新,其他线程(读线程)随后对该变量进行读取,这些线程总是可以读取到写线程对该变量所做的更新。换而言之,写线程更新一个 volatile 变量,读线程随后来读取该变量,那么这些读线程能够读取到写线程对该变量所做的更新这一点是有保障的(而不是碰运气!)。不过,由于 volatile 并不具有锁那样的排他性,因此 volatile 并不能够保障读线程所读取到变量值是共享变量的最新值:读线程在读取一个 volatile 变量的那一刻,其他线程(写线程)可能又恰好更新了该变量,因此读线程所读取到共享变量值仅仅是一个相对新值,即其他线程更新过的值(不一定是最新值)。
4. 小结
以上我们介绍了 volatile 关键字对 long/double 型变量访问操作的原子性保障以及对可见性的保障。接下来我们将介绍 volatile 对有序性的保障,并通过介绍 Java 内存模型中的 Happens-before 关系这一概念来深入理解 volatile 对可见性和有序性的保障。
5. 保障有序性
一个处理器上的线程所执行的一组操作在其他处理器上的线程看来可能是乱序的(Out-of-order),即这些线程对这组操作中的各个操作的感知顺序(观察到的顺序)与程序顺序(目标代码中指定的顺序)不一致。
下面我们看一个乱序实验,如清单 4 所示。
清单 4 JIT 编译器指令重排序 Demo
/**
* 再现 JIT 指令重排序的 Demo
*
* @author Viscent Huang
*/
@ConcurrencyTest(iterations = 200000)
public class JITReorderingDemo {
private int externalData = 1;
private Helper helper;
@Actor
public void createHelper() {
helper = new Helper(externalData);
}
@Observer({
@Expect(desc = "Helper is null", expected = -1),
@Expect(desc = "Helper is not null,but it is not initialized",
expected = 0),
@Expect(desc = "Only 1 field of Helper instance was initialized",
expected = 1),
@Expect(desc = "Only 2 fields of Helper instance were initialized",
expected = 2),
@Expect(desc = "Only 3 fields of Helper instance were initialized",
expected = 3),
@Expect(desc = "Helper instance was fully initialized", expected = 4) })
public int consume() {
int sum = 0;
/*
* 由于我们未对共享变量 helper 进行任何处理(比如采用 volatile 关键字修饰该变量),
* 因此,这里可能存在可见性问题,即当前线程读取到的变量值可能为 null。
*/
final Helper observedHelper = helper;
if (null == observedHelper) {
sum = -1;
} else {
sum = observedHelper.payloadA + observedHelper.payloadB
+ observedHelper.payloadC + observedHelper.payloadD;
}
return sum;
}
static class Helper {
int payloadA;
int payloadB;
int payloadC;
int payloadD;
public Helper(int externalData) {
this.payloadA = externalData;
this.payloadB = externalData;
this.payloadC = externalData;
this.payloadD = externalData;
}
}
public static void main(String[] args) throws InstantiationException,
IllegalAccessException {
// 调用测试工具运行测试代码
TestRunner.runTest(JITReorderingDemo.class);
}
}
清单 4 中的程序非常简单(读者可以忽略其中的注解,因为那是给测试工具用的):createHelper 方法会将实例变量 helper 更新为一个新创建的 Helper 实例;consume 方法会读取 helper 所引用的 Helper 实例,并计算该实例的所有字段(payloadA~payloadD)的值之和作为其返回值。该程序的 main 方法调用测试工具 TestRunner 的 runTest 方法的作用是让测试工具安排一些线程并发地执行 createHelper 方法和 consume 方法,并统计 consume 方法多次执行的返回值。由于 createHelper 方法创建 Helper 实例的时候使用的构造器参数 externalData 值为 1,因此这样看来 consume 方法的返回值似乎“理所当然”地应该是 4。然而,事实却并不总是如此。使用如下命令以 server 模式并设置 Java 虚拟机参数“-XX:-UseCompressedOops”运行清单 4 所示的程序 [1]:
java -server -XX:-UseCompressedOops JITReorderingDemo我们可以看到类似如下的输出 [2]:
expected:-1 occurrences:8 ==>Helper is null
expected:0 occurrences:2 ==>Helper is not null,but it is not initialized
expected:1 occurrences:0 ==>Only 1 field of Helper instance was initialized
expected:2 occurrences:1 ==>Only 2 fields of Helper instance were initialized
expected:3 occurrences:4 ==>Only 3 fields of Helper instance were initialized
expected:4 occurrences:199985 ==>Helper instance was fully initialized
上面的输出中,expected 后面的数字表示 consume 方法的返回值,相应的 occurrences 表示出现相应返回值的次数。
不难看出这次程序运行时,有几次 consume 方法的返回值并不为 4:有的为 3(出现 4 次)、有的为 2(出现 1 次),甚至还有的为 0(出现 2 次)!这说明 consume 方法的执行线程有时候读取到了一个未初始化完毕(或者正在初始化)的 Helper 实例:Helper 实例不为 null,但是其部分实例字段的字段值仍然为其默认值而非 Helper 类的构造器中指定的初始值。下面我们分析其中的原因。
我们知道,createHelper 方法中的唯一一条语句:
helper = new Helper(externalData);可以分解为以下几个子操作(伪代码表示):
objRef = allocate(Helper.class);// 子操作①:分配 Helper 实例所需的内存空间,并获得一个指向该空间的引用
inovkeConstructor(objRef);// 子操作②:调用 Helper 类的构造器初始化 objRef 引用指向的 Helper 实例
helper = objRef;// 子操作③:将 Helper 实例引用 objRef 赋值给实例变量 helper
通过查看 Java 字节码不难发现 createHelper 方法中指定的程序顺序就是上述的先初始化 Helper 实例(子操作②)再将相应的实例的引用赋值给实例变量 helper(子操作③)。然而,consume 方法的执行线程却观察到了未初始化完毕的 Helper 实例,这说明该线程对 createHelper 方法所执行的操作的感知顺序与该方法所指定的程序顺序不一致,即产生了乱序。
查看上述程序运行过程中 JIT 编译器动态生成的汇编代码(相当于机器码),如图 2 所示,我们可以发现 JIT 编译器编译字节码的时候并不是每次都按照上述源代码顺序(这里同时也是程序顺序)生成相应的机器码(汇编代码):JIT 编译器将子操作③相应的指令重排到子操作②相应的指令之前,即 JIT 编译器在初始化 Helper 实例之前可能已经将对该实例的引用写入 helper 实例变量。这就导致了其他线程(consume 方法的执行线程)看到 helper 实例变量(不为 null)的时候,该实例变量所引用的对象可能还没有被初始化或者未初始化完毕(即相应构造器中的代码未执行结束)。这就解释了为什么我们在运行上述程序的时候,consume 方法的返回值有时候并不是 4。
图 2 JIT 编译器重排序 Demo 中的汇编代码片段

虽然乱序有利于充分发挥处理器的指令执行效率,但是正如上述实验所展示的,它也可能导致程序正确性的问题。所以,为了保障程序的正确性,有时候我们需要确保线程对一组操作的感知顺序与这组操作的程序顺序保持一致,即保障这组操作的有序性。上述实验中,为了确保 consume 方法的执行线程看到的 Helper 实例总是初始化完毕的,我们需要确保 createHelper 方法所执行的操作的有序性。为此,我们只需要用 volatile 关键字来修饰实例变量 helper 即可,而无需借助锁。这里,volatile 关键字所起的作用是通过禁止子操作②被 JIT 编译器以及处理器重排序(指令重排序、内存重排序)到子操作③之后,从而保障了有序性。
Java 语言规范规定,对于访问(读、写)同一个 volatile 变量的多个线程而言,一个线程(写线程)在写 volatile 变量前所执行的内存读、写操作在随后读取该 volatile 变量的其他线程(读线程)看来是有序的。设 X、Y 是普通(非 volatile)共享变量,其初始值均为 0,V 是 volatile 变量,其初始值为 false,r1、r2 是局部变量,线程 T1 和 T2 先后访问 V,如图 3 所示。那么,T1 对 V 的更新以及更新 V 前所执行的操作在 T2 看来是有序的:在 T2 看来 T1 对 X、Y 和 V 的写操作就像是完全依照程序顺序执行的。换而言之,如果 T2 读取到 V 的值为 true,那么该线程所读取到的 X 和 Y 的值必然为分别为 1 和 2。相反,如果 V 不是 volatile 变量,那么上述这种保证就不存在,即 T2 读取到 V 的值为 true 时,T2 所读取到 X 和 Y 的值可能并非 1 和 2。
图 3 volatile 关键字的有序性保障示例代码

上述例子中,我们假设只有一个线程更新 V(另外一个线程读取 V),如果有更多的线程并发更新 V,那么由于 volatile 并不具有排他性,因此在 T2 读取 V 的时候 T1 之外的其他线程可能已经又更新了共享变量 X、Y,这就使得 T2 在其读取到 V 的值为 true 的情况下,其读取到 X 和 Y 的值可能不是 1 和 2。不过,这种现象是数据竞争的结果,这与 volatile 能够保障有序性本身并不矛盾。
6. Happens-before 关系
了解 Java 内存模型(Java Memory Model)中的定义的 Happens-before 关系(Happens-before Relationship)这一概念有助于我们进一步理解 volatile 变量对可见性和有序性的保障。
Java 内存模型定义了一些动作(Action)。这些动作包括变量的读 / 写、锁的申请(lock)与释放(unlock)以及线程的启动(Thread.start() 调用)和加入(Thread.join() 调用)等。如果动作 A 和动作 B 之间存在 Happens-before 关系,那么动作 A 的执行结果对动作 B 可见。反之,如果动作 A 和动作 B 之间不存在 Happens-before 关系,那么动作 A 的执行结果对 B 来说不一定是可见的。下文我们用“→”来表示 Happens-before 关系,例如“A→B”表示动作 A 与动作 B 存在 Happens-before 关系。
Java 内存模型中的 volatile 变量规则(Volatile Variable Rule)规定,对一个 volatile 变量的写操作 happens-before 后续(Subsequent)每一个针对该变量的读操作。这里有两点需要注意:首先,针对同一个 volatile 变量的写、读操作之间才有 happens-before 关系,不同 volatile 变量之间的写、读操作并无 happens-before 关系;其次,针对同一个 volatile 变量的写、读操作必须具有时间上的先后关系,即一个线程先写另外一个线程再来读这样这两个动作之间才能够有 happens-before 关系。因此,对于图 2 可有 wV→rV,即动作 wV(写 volatile 变量 V)的结果对 rV(读 volatile 变量 V)可见。
Java 内存模型中程序顺序规则(Program Order Rule)规定同一个线程中的每一个动作都 happens-before 该线程中程序顺序上排在该动作之后的每一个动作。因此,对于图 3 可有如下的 happens-before 关系:
wX→wY (hb1)
wY→wV(hb2)
rV→rX (hb3)
rX→rY(hb4)
Happens-before 关系具有传递性,即如果 A→B,B→C,那么就有 A→C。因此,由 hb1 和 hb2 可得出以下 happens-before 关系:
wX→wV(hb5)再根据 volatile 变量规则,可有 happens-before 关系:
wV→rV(hb6)进一步根据 happens-before 关系的传递性由 hb5 和 hb6 可得出以下 happens-before 关系:
wX→rV(hb7)同样根据 happens-before 关系的传递性由 hb7 和 hb3 可得出以下 happens-before 关系:
wX→rX(hb8)同理,我们也可以推断出以下 happens-before 关系:
wY→rY(hb9)由此可见,线程 T1 对普通共享变量 X 和 Y 所做的更新对线程 T2 来说都是可见的。这种可见性是在 volatile 变量规则、程序顺序规则以及 happens-before 关系的传递性的共同作用下得以保障的。因此,我们说 volatile 关键字不仅仅保障写线程对 volatile 变量所做的更新的可见性(hb6),它还保障了写线程在写 volatile 变量前对其他非 volatile 变量所做的更新的可见性(hb8 和 hb9)。
理解了 Happens-before 关系这一概念之后,我们可以思考这样一个问题:volatile 关键字对可见性和有序性的保障是否适用于数组呢?例如,对于 volatile 修饰的一个 int 数组 vArr,线程 A 执行“vArr[0]=1;”,接着,线程 B 再来读取 vArr 的第 1 个元素,那么此时线程 B 所读取到元素值是否一定是“1”呢(这里我们假设只有线程 A 和线程 B 这两个线程访问 vArr)?答案是“不一定”:此时线程 A 和线程 B 从 volatile 关键字的角度来看都只是读线程(读取 volatile 变量 vArr),即这两个线程之间并不存在 Happens-before 关系,因此线程 A 对 vArr 第 1 个元素的更新对线程 B 来说不一定是可见的。这个例子中,要保障对数组元素的更新的可见性,我们可以使用 java.util.concurrent.atomic.AtomicIntegerArray 类。
7. 小结
上面介绍了 volatile 对有序性的保障,并通过介绍 Java 内存模型中的 Happens-before 关系这一概念来进一步介绍 volatile 对可见性和有序性的保障。通过前面的介绍,我们知道 volatile 关键字的作用包括保障 long/double 型变量访问操作的原子性、保障可见性和保障有序性。接下来将介绍 Java 虚拟机对 volatile 关键字的实现,volatile 关键字的开销以及 volatile 的典型应用场景。
8. Java 虚拟机对 volatile 的实现
本节会涉及较多的术语,如表 1 所示。
表 1 本节术语
术语
解释
写线程
对 volatile 变量执行写操作的线程被称为写线程。
读线程
对 volatile 变量执行读操作的线程被称为读线程。一个线程可以既是读线程又是写线程。
高速缓存(Cache)
处理器借以访问主内存(RAM)的小容量高速存取部件。高速缓存可理解为由硬件实现的散列表(Hash Table)。处理器并不是直接访问主内存,处理器对主内存的读、写操作都是通过高速缓存进行的。
缓存条目(Cache Entry)
高速缓存内部存储单元。相当于散列表中的条目。
缓存行(Cache Line)
高速缓存与主内存之间的数据交换(传输)的最小单元。
缓存一致性协议(Cache Coherence Protocol)
处理器用于确保通过高速缓存访问主内存达到与直接访问主内存等效(性能差异除外)的一套协议。
无效化队列(Invalidate/Probe/Coherence Queue)
处理器用于暂存无效化消息(Invalidation Message)的存储部件。无效化消息的作用是一个处理器修改了某个共享变量之后借以通知其他处理器其对共享变量的更新,以便其他处理器能够将其高速缓存中的相应缓存行置为无效。
写缓存器(Store/Write Buffer)
处理器内部用于暂存写入高速缓存(以写入主内存)数据的容量极小的存储部件。
内存屏障(Memory Barrier/Fence)
对作用于内存读、写操作的一类特殊处理器指令的统称。
程序顺序(Program Order)
目标代码中指定的一组内存操作的顺序。
感知顺序(Perceived Order)
一个处理器对其他处理器上执行的一组内存操作所观察到的顺序。
Java 虚拟机对 long/double 型变量访问操作的原子性保障是通过使用原子指令(本身就具有原子性的处理器指令)实现的。下面通过一个实验来进一步介绍这点,该实验所需的 Java 代码如清单 6 所示。
清单 6 Java 虚拟机对 volatile 语义的实现实验 Java 代码
public class AtomicJVMImpl {
static long normalLong = 0L;
static volatile long volatileLong = 0L;
public static void main(String[] args) {
long v1 = 0, v2 = 0;
for (int i = 0; i < 100100; i++) {
normalWrite(i);
volatileWrite(i);
v1 = normalRead() + i;
v2 = volatileRead();
}
System.out.println(v1 + "," + v2);
}
public static void normalWrite(long value) {
normalLong = value;
}
public static void volatileWrite(long value) {
volatileLong = value;
}
public static long volatileRead() {
return volatileLong;
}
public static long normalRead() {
return normalLong;
}
}
32 位 Java 虚拟机(JIT 编译器)执行(动态编译)normalWrite 方法中的普通 long/double 型变量写操作时使用的机器码(x86 汇编语言表示)如图 4 所示。
图 4 32 位 Java 虚拟机 x86 处理器下对普通 long/double 型变量写操作的实现
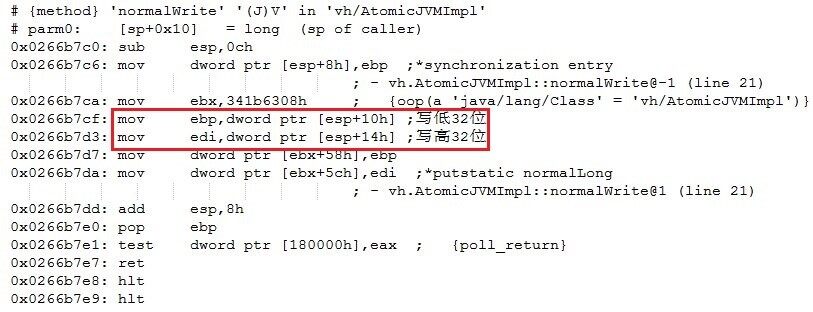
可见,32 位 Java 虚拟机在 x86 处理器平台下对普通 long/double 型变量(这里是 long 型变量)的写操作是通过两个子操作——先写低 32 位再写高 32 位实现的。32 位 Java 虚拟机在某些处理器平台下可能仍然使用一条指令(比如在 ARM 处理器平台下使用 strd 指令)来实现普通 long/double 型变量的写操作,但是这条指令可能不是原子指令,因此在 Java 语言这一层次来观察,此时的普通 long/double 型变量写操作同样也不是原子操作。32 位 Java 虚拟机(JIT 编译器)在 x86 处理器平台下实现 volatileWrite 方法中的 volatile long/double 型变量写操作时使用的是一个原子指令(vmovsd),如图 5 所示。
图 5 32 位 Java 虚拟机 x86 处理器下对 volatile long/double 型变量写操作的实现
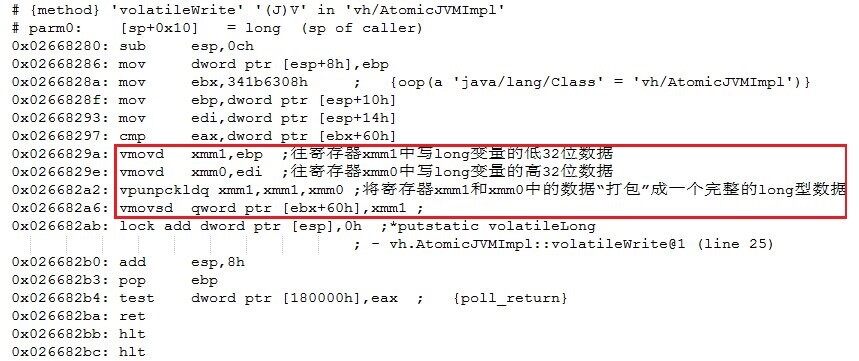
类似的,Java 虚拟机对 long/double 型变量读操作的原子性保障也是通过使用原子指令实现的。例如,32 位 Java 虚拟机在 x86 平台下会使用 vmovsd 这个原子指令来实现 volatile 修饰的 long/double 型变量的读操作,而对普通 long/double 型变量的读操作则是使用 2 条 mov 指令实现。
Java 虚拟机对可见性和有序性的保障则是通过使用内存屏障实现的。
处理器在其执行内存写操作的时候,往往是先将数据写入其写缓冲器中,而不是直接写入高速缓存。由于一个处理器上的写缓冲器中的内容无法被其他处理器所读取,因此写线程必须确保其对 volatile 变量所做的更新以及其更新 volatile 变量前对其他共享变量所做的更新(以下统称为对共享变量所做的更新)到达该处理器的高速缓存(而不是仍然停留在写缓冲器中)。这样,写线程的这些更新通过缓存一致性协议被其他处理器上的线程所读取才成为可能。为此,Java 虚拟机(JIT 编译器)会在 volatile 变量写操作之后插入一个 StoreLoad 内存屏障。这个内存屏障的其中一个作用就是将其执行处理器的写缓冲器中的当前内容写入高速缓存。
由于无效化队列的存在,处理器从其高速缓存中读取到的共享变量值可能是过时的。因此,为了确保读线程能够读取到写线程对共享变量所做的更新(包括 volatile 变量),读线程的执行处理器必须在读取 volatile 变量前确保无效化队列中内容被应用到该处理器的高速缓存中,即根据无效化队列中的内容将该处理器中相应的缓存行设置为无效,从而使写线程对共享变量所做的更新能够被反映到该处理器的高速缓存上。为此,Java 虚拟机(JIT 编译器)会在 volatile 变量读操作前插入一个 LoadLoad 内存屏障。有的处理器(例如 x86 处理器和 ARM 处理器)并没有引入无效化队列,因此在这些处理器上上述 LoadLoad 内存屏障就不再被需要。
可见,volatile 关键字对可见性的保障是通过 Java 虚拟机(JIT 编译器)在写线程和读线程中配对地使用内存屏障实现的,如图 6 所示。
图 6 Java 虚拟机(JIT 编译器)为实现 volatile 语义而插入的内存屏障

volatile 关键字对有序性的保障也是通过 Java 虚拟机(JIT 编译器)在写线程和读线程中配对地使用内存屏障实现的。为了使写线程对共享变量所做的更新在读线程看来是有序的(即感知顺序与程序顺序保持一致),Java 虚拟机首先必须保证写线程程序顺序上排在写 volatile 变量之前的对其他共享变量的更新先于对 volatile 变量的更新反映到该线程所在的处理器的高速缓存上。换而言之,Java 虚拟机必须确保程序顺序上排在 volatile 变量写操作之前的其他写操作不能够被编译器 / 处理器通过指令重排序和(或)内存重排序被重排序到该 volatile 变量写操作之后。为此,Java 虚拟机(JIT 编译器)会在 volatile 变量写操作之前插入 LoadStore+StoreStore 内存屏障,这个组合内存屏障禁止了 volatile 变量写操作与该操作之前的任何读、写操作之间的重排序(包括指令重排序和内存重排序)。其次,Java 虚拟机(JIT 编译器)必须确保读线程在读取完写线程对 volatile 变量所做的更新之后才开始读取写线程在更新该 volatile 变量前对其他共享变量所做的更新。换而言之,Java 虚拟机必须确保程序顺序上排在 volatile 变量读操作之后的其他共享变量的读、写操作不能够被编译器 / 处理器通过指令重排序和(或)内存重排序被重排序到该 volatile 变量读操作之前。为此,Java 虚拟机(JIT 编译器)会在 volatile 变量读操作之后插入一个 LoadLoad+LoadStore 内存屏障,这个组合内存屏障禁止了 volatile 变量读操作与该操作之后的任何读、写操作之间的重排序(包括指令重排序和内存重排序)。可见,Java 虚拟机是通过使写线程和读线程配对地使用内存屏障来实现 volatile 对有序性的保障的,如图 6 所示。
图 7 和图 8 展示了 Java 虚拟机(32 位)在 ARM 处理器平台下对清单 1 中的 volatileWrite、volatileRead 方法进行 JIT 编译时插入的内存屏障情况。
图 7 Java 虚拟机在 ARM 处理器平台下在 volatile 变量写操作前后插入的内存屏障
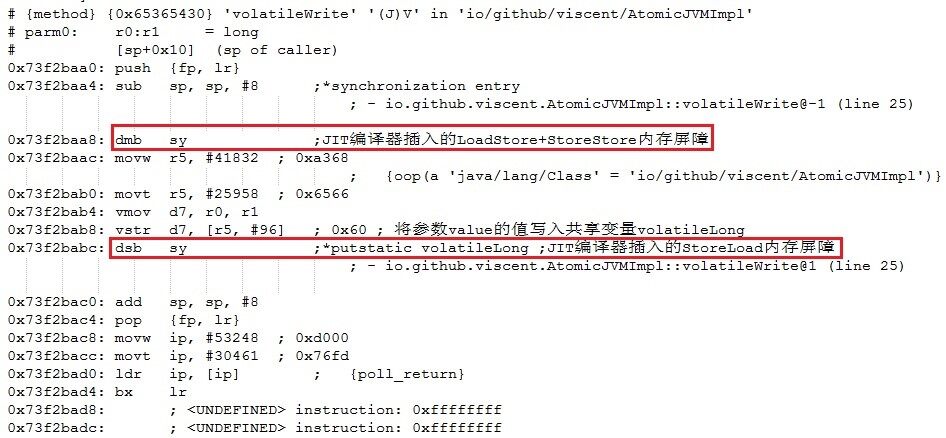
图 7 中,JIT 编译器在 volatile 写操作(“vstr d7, [r5, #96]”指令)前插入的“dmb sy”指令相当于 LoadStore+StoreStore 内存屏障。JIT 编译器在 volatile 写操作后插入的“dsb sy”指令相当于 StoreLoad 内存屏障。
图 8 Java 虚拟机在 ARM 处理器平台下在 volatile 变量读操作后插入的内存屏障
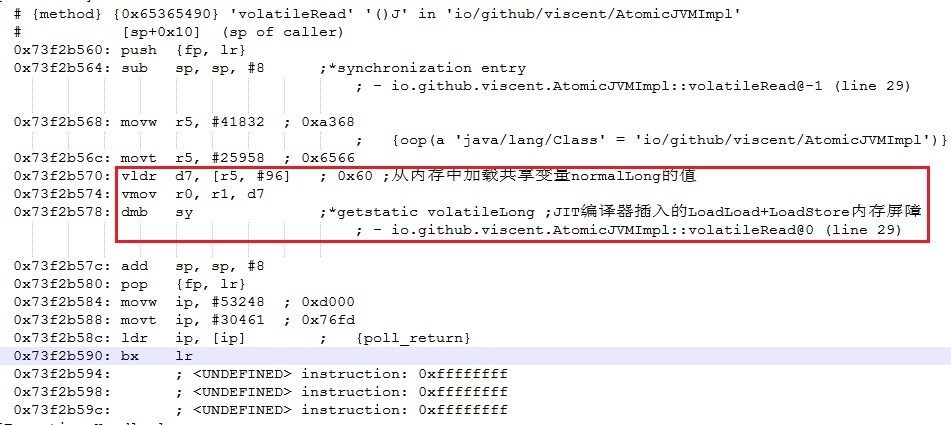
图 8 中,JIT 编译器在 volatile 读操作(“vldr d7, [r5, #96]”指令)后插入的“dmb sy”指令相当于 LoadStore+LoadLoad 内存屏障。由于 ARM 处理器并没有使用无效化队列,因此 JIT 编译器在 volatile 读操作前并不需要插入 LoadLoad 内存屏障。
9. volatile 的开销
上一节我们讲到 Java 虚拟机(JIT 编译器)会在 volatile 变量写操作之后插入一个 StoreLoad 内存屏障。StoreLoad 内存屏障是一个全能型内存屏障,它是内存屏障中功能最强大开销也最大的一个内存屏障。该内存屏障除了能够将写缓冲器中条目写入高速缓存之外,还能够将无效化队列中的内容应用到高速缓存中。而这两个操作的开销较大,在某些处理器上(例如 ARM 处理器)该内存屏障可能还会导致处理器流水线(Pipeline)停顿。由于 Java 虚拟机并不需要在普通变量写操作之后插入内存屏障,而临界区中的写操作除了有内存屏障的开销之外,还有锁的申请与释放的开销,因此 volatile 变量写操作的开销介于普通变量写操作和临界区中的写操作之间。
如果处理器引入了无效化队列,那么 Java 虚拟机需要在 volatile 变量读操作前插入一个 LoadLoad 内存屏障。另外,Java 虚拟机(JIT 编译器)在 volatile 变量读操作之后插入的 LoadLoad+LoadStore 内存屏障会阻止处理器执行某些优化(比如重排序和预先加载数据)。而临界区中的读操作不仅仅有内存屏障的开销,还有锁的申请与释放的开销。因此,volatile 变量读操作的开销介于普通变量读操作和临界区中的读操作之间。
普通共享变量的值可能会被 JIT 编译器缓存到寄存器中,即对于任意一个线程,该线程第一次读取某个普通共享变量是一次内存读操作(比如 x86 处理器上的 mov 指令),随后重复读取这个共享变量则是从寄存器中读取。根据 volatile 关键字的语义,volatile 变量是不能够被缓存到寄存器中,即每个 volatile 变量读操作都是一次内存读操作,同一个线程即使是连续多次读取同一个 volatile 变量,这当中的每次读取操作都是从内存中读取的。因此,从整体上看,volatile 变量的读取开销要比普通共享变量的开销要大。
10. volatile 的典型应用场景
10.1、 间接保障复合操作的原子性与可见性
对于清单 2 中的可见性和原子性问题,虽然我们可以通过对 updateHostInfo 方法和 connectToHost 方法进行加锁来加以解决,但是借助 volatile 关键字我们既可以保障可见性和原子性又可以避免锁的开销,如清单 7 所示。
清单 7 使用 volatile 间接保障复合操作的原子性与可见性实例
public class AtomicityExample1 {
private volatile HostInfo hostInfo;
public void updateHostInfo(String ip, int port) {
HostInfo newHostInfo = new HostInfo(ip, port);
this.hostInfo = newHostInfo;
}
public void connectToHost() {
String ip = hostInfo.getIp();
int port = hostInfo.getPort();
connectToHost(ip, port);
}
private void connectToHost(String ip, int port) {
// ...
}
public static class HostInfo {
private String ip;
private int port;
public HostInfo(String ip, int port) {
this.ip = ip;
this.port = port;
}
public String getIp() {
return ip;
}
public int getPort() {
return port;
}
// ...
}
}
清单 7 中的 updateHostInfo 方法运用了不可变对象(Immutable Object)模式:它在更新主机 IP 地址和端口号的时候并不调用 HostInfo 类的相应 set 方法,而是先创建新的 HostInfo 实例,再将该实例(的引用)赋值给实例变量 hostInfo,由此实现了主机信息的更新。由于这个赋值操作本身就是一个原子操作,因此我们只需要再使这个赋值操作的结果对其他线程可见即可保障线程安全。为此,我们只需要将实例变量 hostInfo 声明为 volatile 变量即可。
10.2、 保障对象的安全发布
volatile 的一个典型应用就是用于正确地实现基于双重检查锁定(Double checked locking)法的单例类(Singleton),如清单 3 所示。用双重检查锁定法来实现单例类的目的在于既能够实现延迟加载(Lazy Load,以减少不必要的开销)又能够尽量减少锁的开销。清单 8 中,采用 volatile 来修饰静态变量 instance 目的有两个:保障可见性和保障有序性。尽管对 instance 变量的赋值是在一个临界区中进行的,但是第 1 次检查的 if 语句并没有处于临界区之中。也就是说,语句③对 instance 的写操作与语句①对 instance 的读操作这两个操作之间并不存在 happens-before 关系,因此,语句③的执行结果对语句①来说不一定是可见的。为了确保语句③对 instance 的写操作的结果对语句①(第 1 次检查)可见,我们只需要采用 volatile 来修饰 instance 即可。从有序性的角度来看,在没有采用 volatile 修饰 instance 的情况下,语句①的执行线程即使读取到 instance 不为 null(其他线程执行语句③的结果),那么由于重排序(JIT 重排序和 / 活内存重排序)的作用,instance 所引用的对象仍然可能是未初始化完毕的,这就可能导致程序的正确性问题。采用 volatile 修饰 instance 之后,在 volatile 保障有序性的作用下,语句①的执行线程一旦看到 instance 不为 null,那么 instance 所引用的对象必然是初始化完毕的。此时,我们称 instance 所引用的对象被安全地发布。
清单 8 使用 volatile 正确实现基于双重检查锁定法的单例类
public class DCLSingleton {
private static volatile DCLSingleton instance;
// 省略其他字段
// 私有构造器
private DCLSingleton() {
}
public DCLSingleton getInstance() {
if (null == instance) {// 语句①: 第 1 次检查,不加锁
synchronized (DCLSingleton.class) {
if (null == instance) {// 语句②: 第 2 次检查,加锁
instance = new DCLSingleton();// 语句③:实例化
}
}
}
return instance;
}
// 省略其他 public 方法
}
11. 总结
volatile 关键字的作用包括保障 long/double 型变量访问操作的原子性、保障可见性以及保障有序性。Java 虚拟机在实现 volatile 关键字的语义时通常会借助一些特殊的处理器指令(原子指令和内存屏障)。volatile 变量访问的开销介于普通变量访问和在临界区中进行的变量访问之间。volatile 的典型运用场景包括间接保障复合操作的原子性、保障对象的安全发布等。
12. 参考资料
1、 黄文海.Java 多线程编程实战指南(核心篇). 电子工业出版社,2017
2、 黄文海.Java 多线程编程实战指南(设计模式篇). 电子工业出版社,2015
3、 Brian Goetz 等.Java Concurrency In Practice.Addison-Wesley Professional,2006
4、 Java 语言规范第 17 章: https://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html
5、 Managing volatility: https://www.ibm.com/developerworks/library/j-jtp06197/index.html
6、 Java 多线程编程模式实战指南(二):Immutable Object 模式: http://www.infoq.com/cn/articles/java-multithreaded-programming-mode-immutable-object
7、 Java Memory Model From a Programmer’s Point-of-View: https://dzone.com/articles/java-memory-model-programer’s
8、 The JSR-133 Cookbook for Compiler Writers: http://gee.cs.oswego.edu/dl/jmm/cookbook.html
9、 Memory Barriers: a Hardware View for Software Hackers: http://www.rdrop.com/users/paulmck/scalability/paper/whymb.2010.07.23a.pdf
10、Memory Barriers and JVM Concurrency: https://www.infoq.com/articles/memory_barriers_jvm_concurrency
[1] 虚拟机参数“-XX:-UseCompressedOops”: https://docs.oracle.com/javase/8/docs/technotes/guides/vm/performance-enhancements-7.html#compressedOop。
[2] 这个输出相应的执行环境信息——操作系统:Linux(x86_64 系统),JDK 版本:JDK 1.8.0_40,处理器型号:Intel i5-3210M。




