
限流简介
什么是限流
在不同场景下限流的定义也各不相同,可以是每秒请求数、每秒事务处理数、网络流量。
通常我们所说的限流指的是限制到达系统并发请求数,使得系统能够正常的处理部分用户的请求,来保证系统的稳定性。
为什么限流
接口无法控制调用方的行为。热点业务突发请求、恶意请求攻击等会带来瞬时的请求量激增,导致服务占用大量的 CPU、内存等资源,使得其他正常的请求变慢或超时,甚至引起服务器宕机。
按照请求次数进行收费的接口需要根据客户支付的金额来限制客户可用的次数。
限流的行为
限流的行为指的就是在接口的请求数达到限流的条件时要触发的操作,一般可进行以下行为。
拒绝服务:把多出来的请求拒绝掉
服务降级:关闭或是把后端服务做降级处理。这样可以让服务有足够的资源来处理更多的请求
特权请求:资源不够了,我只能把有限的资源分给重要的用户
延时处理:一般会有一个队列来缓冲大量的请求,这个队列如果满了,那么就只能拒绝用户了,如果这个队列中的任务超时了,也要返回系统繁忙的错误了
弹性伸缩:用自动化运维的方式对相应的服务做自动化的伸缩
限流架构
单点限流
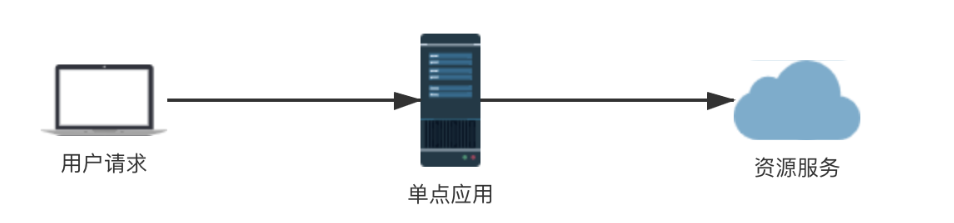
当我们的系统应用只部署在一个节点上来提供服务时,就可以采用单点限流的架构来对应用的接口进行限流,只要单点应用进行了限流,那么他所依赖的各种服务也得到了保护。
分布式限流
为了提供高性能的服务,往往我们的应用都是以集群结构部署在多个节点上的。这时候单点限流只能限制传入单个节点的请求,保护自身节点,无法保护应用依赖的各种服务资源。那么如果在集群中的每个节点上都进行单点限流是否可行呢?
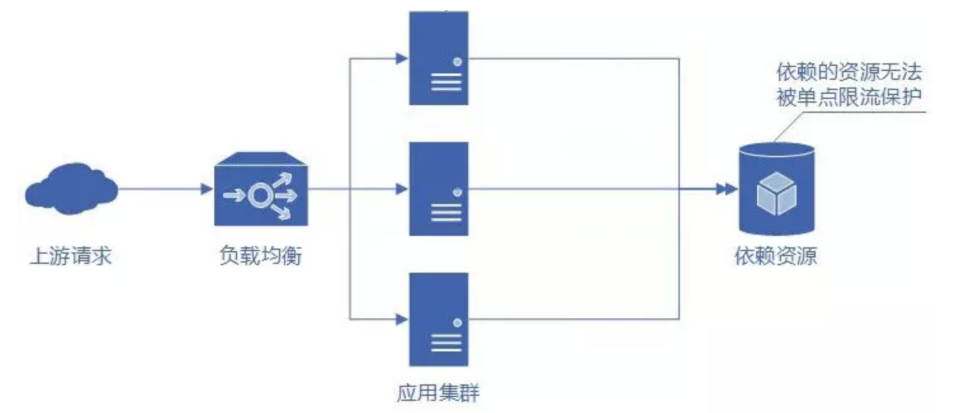
假设我们的应用集群中有三个节点,为了保护应用依赖的资源我们限制资源每秒最大请求数为 300 个,如果超过这个限制那么资源将因过载导致不再可用。这样分配到集群中的每个应用节点的每秒最大请求数为 100 个才可以满足保护资源的要求,超过 100 则拒绝服务提示业务繁忙。
假如某一秒内有 300 个请求打到应用集群,应用集群再去请求所依赖的资源服务,是满足资源服务每秒 300 个最大请求数的限制的,所以这些请求都能够得到处理并且正常返回。
但是,如果因为种种原因负载均衡调度器把这 300 个请求中的 50 个分配给了节点 1,50 个分配给了节点 2,剩余 200 个分配给了节点 3。因为我们之前限制每个节点的每秒最大请求数为 100,所以就会出现节点 1 的 50 个请求全部正常返回、节点 2 上的 50 个请求全部正常返回,而节点三上的 200 个请求只有 100 个正常返回,另外 100 个被拒绝服务。这种集群中每个节点都进行单点限流的方式显然不能满足我们的业务需要。
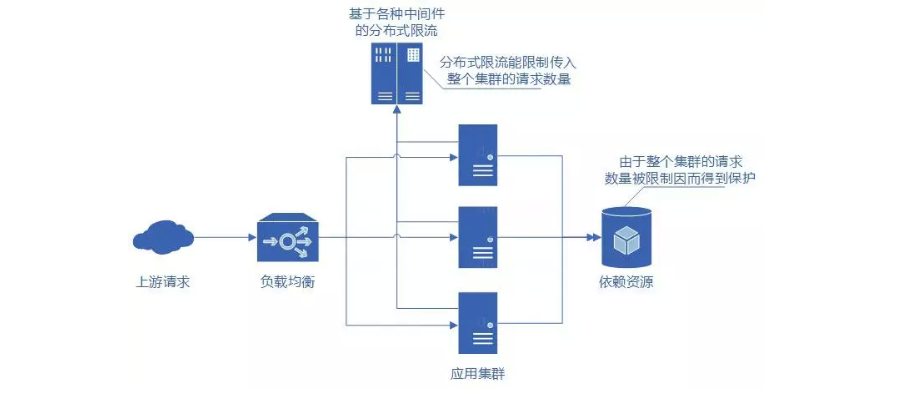
我们可以使用基于各种中间件的分布式限流来解决集群结构下应用限流不准确的问题。将限流的配置以及通过整个集群的请求数都保存在中间件中,然后通过计算来判断是否达到限流行为的触发条件。分布式限流可以统一地限制整个集群的流量,整个集群的请求数得到了限制,那么集群所依赖的资源服务也就得到了保障。
限流算法
固定窗口计数器
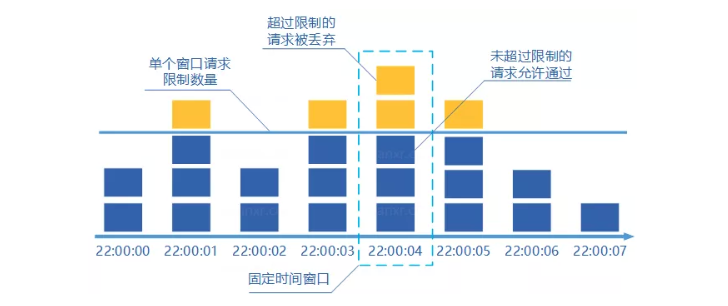
将时间按照设定的周期划分为多个窗口
在当前时间窗口内每来一次请求就将计数器加一
如果计数器超过了限制数量,则拒绝服务
当时间到达下一个窗口时,计数器的值重置
这种算法很好实现,但是会出现限流不准确的问题,例如:
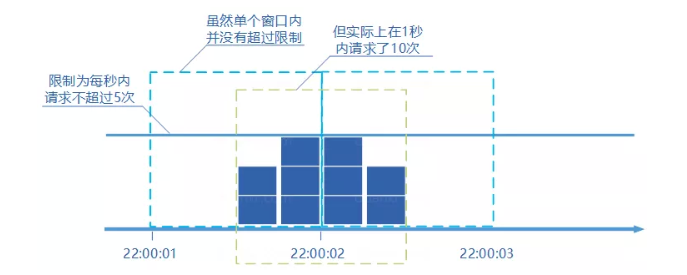
假设限制每秒通过 5 个请求,时间窗口的大小为 1 秒,当前时间窗口周期内的后半秒正常通过了 5 个请求,下一个时间窗口周期内的前半秒正常通过了 5 个请求,在这两个窗口内都没有超过限制。但是在这两个窗口的中间那一秒实际上通过了 10 个请求,显然不满足每秒 5 个请求的限制。
滑动窗口计数器
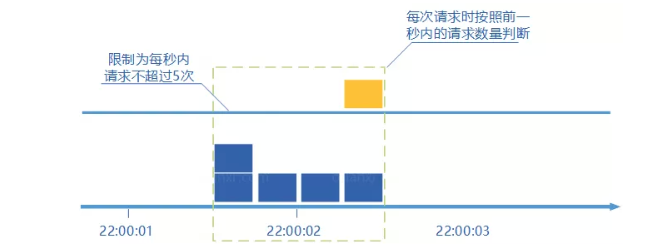
将设定的时间周期设为滑动窗口的大小,记录每次请求的时刻
当有新的请求到来时将窗口滑到该请求来临的时刻
判断窗口内的请求数是否超过了限制,超过限制则拒绝服务,否则请求通过
丢弃滑动窗口以外的请求
这种算法解决了固定窗口计数器出现的通过请求数是限制数两倍的缺陷,但是实现起来较为复杂,并且需要记录窗口周期内的请求,如果限流阈值设置过大,窗口周期内记录的请求就会很多,就会比较占用内存
漏桶算法
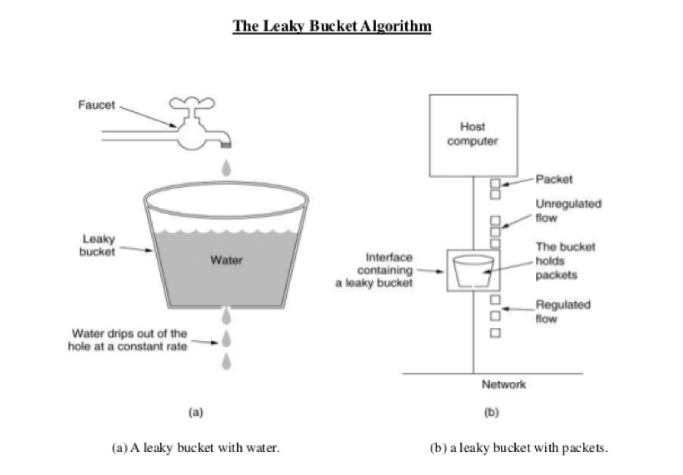
将进来的请求流量视为水滴先放入桶内
水从桶的底部以固定的速率匀速流出,相当于在匀速处理请求
当漏桶内的水满时(超过了限流阈值)则拒绝服务
这个算法可以比较平滑均匀的限制请求,Nginx 中的 limit_req 模块的底层实现就是用的这种算法,具体可参考【NGINX 和 NGINX Plus 的速率限制】(https://www.nginx.com/blog/rate-limiting-nginx)
但是漏桶算法也有一定的缺陷,因为水从桶的底部以固定的速率匀速流出,当有在服务器可承受范围内的瞬时突发请求进来,这些请求会被先放入桶内,然后再匀速的进行处理,这样就会造成部分请求的延迟。所以他无法应对在限流阈值范围内的突发请求。
令牌桶算法
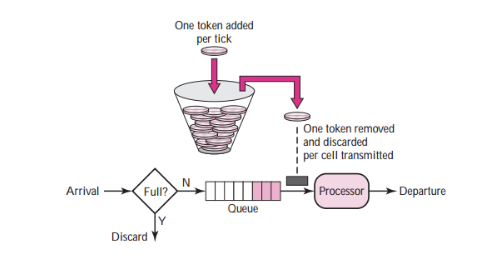
按照一定的速率生产令牌并放入令牌桶中
如果桶中令牌已满,则丢弃令牌
请求过来时先到桶中拿令牌,拿到令牌则放行通过,否则拒绝请求
这种算法能够把请求均匀的分配在时间区间内,又能接受服务可承受范围内的突发请求。所以令牌桶算法在业内使用也非常广泛。接下来会详细介绍该算法的实现。
令牌桶算法实现
我们采用 Redis + Lua 脚本的方式来实现令牌桶算法,在 Redis 中使用 Lua 脚本有诸多好处,例如:
减少网络开销:本来多次网络请求的操作,可以用一个请求完成,原先多次请求的逻辑放在 Redis 服务器上完成。使用脚本,减少了网络往返时延。
原子操作:Redis 会将整个脚本作为一个整体执行,中间不会被其他进程或者进程的命令插入。
复用:客户端发送的脚本会永久存储在 Redis 中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑。
复用:客户端发送的脚本会永久存储在 Redis 中,意味着其他客户端可以复用这一脚本而不需要使用代码完成同样的逻辑。
这其中最重要的方法就是原子操作。将 Redis 的多条命令写成一个 Lua 脚本,然后调用脚本执行操作,相当于只有一条执行脚本的命令,所以整个 Lua 脚本中的操作都是原子性的。
在 Redis 中使用 Lua 脚本主要涉及 Script Load、Eval、Evalsha 三个命令:
Eval ${lua_script} 可以直接执行 Lua 脚本。
Script Load ${lua_script} 命令是将脚本载入 Redis,载入成功后会返回一个脚本的 sha1 值,一旦载入则永久存储在 Redis 中,后续可以通过 Evalsha ${sha1} 来直接调用此脚本。我们采用先 Load 脚本得到 Sha1 值,再调用这个 sha1 值来执行脚本的方式可以减少像eval ${lua_script} 命令这样每次都向 Redis 中发送一长串 Lua 脚本带来的网络开销。
使用 Redis 中的 Hash 数据结构来存储限流配置,每个 Hash 表的 Key 为限流的粒度,可以是接口 Uri、客户端 IP、应用 uuid 或者他们的组合形式。每个 Hash 表为一个令牌桶,Hash 表中包含如下字段:
last_time最近一次请求的时间戳,毫秒级别。curr_permits当前桶内剩余令牌数量,单位为:个。bucket_cap桶的容量,即桶内可容纳最大令牌数量,代表限流时间周期内允许通过的最大请求数。period限流的时间周期,单位为:秒。rate令牌产生的速率,单位:个/秒,rate = bucket_cap / period
在上面的令牌桶算法描述中生产令牌的方式是按照一定的速率生产令牌并放入令牌桶中,这种方式需要一个线程不停地按照一定的速率生产令牌并更新相应的桶,如果被限流的接口(每个桶)令牌生产的速率都不一样,那么就需要开多个线程,很浪费资源。
为了提高系统的性能,减少限流层的资源消耗,我们将令牌的生产方式改为:每次请求进来时一次性生产上一次请求到本次请求这一段时间内的令牌。随意每次请求生成的令牌数就是 (curr_time -last_time) / 1000 * rate,注意:这里两次时间戳的差值单位是毫秒,而令牌产生速率的单位是 个/秒,所以要除以 1000,把时间戳的差值的单位也换算成秒。
令牌桶算法的实现逻辑为:

假如我们的限流策略是一分钟内最多能通过 600 个请求,那么相应的令牌产生速率为 600 / 60 = 10 (个/秒) 。那么当限流策略刚刚配置好这一时刻就有突发的 10 个请求进来,此时令牌桶内还没来的及生产令牌,所以请求拿不到令牌就会被拒绝,这显然不符合我们要求。
为了解决这一问题,我们在限流策略刚刚配置好后的第一个请求来临时将当前可用令牌的值设置为桶的最大容量 600,将最近一次请求时间设置为本次请求来临时一分钟后的时间戳,减去出本次请求需要的令牌后更新桶。这样,在这一分钟以内,有下一次请求进来时,从 Hash 表内取出配置计算当前时间就会小于最近一次请求的时间,随后计算生成的令牌就会是一个小于 0 的负数。所以在更新桶这一步,要根据生成的令牌是否为负数来决定是否更新最后一次请求时间的值。
用 Lua 脚本实现上述逻辑:
local key = KEYS[1] -- 要进行限流的Key,可以是 urilocal consume_permits = tonumber(ARGV[1]) -- 请求消耗的令牌数,每个请求消耗一个local curr_time = tonumber(ARGV[2]) -- 当前时间local limiter_info = redis.pcall("HMGET", key, "last_time", "curr_permits", "bucket_cap", "rate", "period")if not limiter_info[3] then return -1endlocal last_time = tonumber(limiter_info[1]) or 0local curr_permits = tonumber(limiter_info[2]) or 0local bucket_cap = tonumber(limiter_info[3]) or 0local rate = tonumber(limiter_info[4]) or 0local period = tonumber(limiter_info[5]) or 0local total_permits = bucket_caplocal is_update_time = trueif last_time > 0 then local new_permits = math.floor((curr_time-last_time)/1000 * rate) if new_permits <= 0 then new_permits = 0 is_update_time = false end total_permits = new_permits + curr_permits if total_permits > bucket_cap then total_permits = bucket_cap endelse last_time = curr_time + period * 1000endlocal res = 1if total_permits >= consume_permits then total_permits = total_permits - consume_permitselse res = 0endif is_update_time then redis.pcall("HMSET", key, "curr_permits", total_permits, "last_time", curr_time)else redis.pcall("HSET", key, "curr_permits", total_permits)endreturn res上述脚本在调用时接收三个参数,分别为:限流的 key、请求消耗的令牌数、 当前时间戳(毫秒级别)。
在我们的业务代码中,先调用 Redis 的 SCRIPT LOAD 命令将上述脚本 Load 到 Redis 中并将该命令返回的脚本 sha1 值保存。
在后续的请求进来时,调用 Redis 的 EVALSHA 命令执行限流逻辑,根据返回值判断是否对本次请求触发限流行为。假如限流的 key 为每次请求的 uri,每次请求消耗 1 个令牌,那么执行 Evalsha 命令进行限流判断的具体操作为:EVALSHA ${sha1} 1 ${uri} 1 ${当前时间戳} (第一个数字 1 代表脚本可接收的参数中有 1 个 Key,第二个数字 1 代表本次请求消耗一个令牌);执行完这条命令后如果返回值是 1 代表桶中令牌够用,请求通过;如果返回值为 0 代表桶中令牌不够,触发限流;如果返回值为 -1 代表本次请求的 uri 未配置限流策略,可根据自己的实际业务场景判断是通过还是拒绝。
总结
本文主要介绍了四种限流的算法,分别为:固定窗口计数器算法、滑动窗口计数算法、漏桶算法、令牌桶算法。
固定窗口计数算法简单易实现,其缺陷是可能在中间的某一秒内通过的请求数是限流阈值的两倍,该算法仅适用于对限流准确度要求不高的应用场景。
滑动窗口计数算法解决了固定窗口计数算法的缺陷,但是该算法较难实现,因为要记录每次请求所以可能出现比较占用内存比较多的情况。
漏桶算法可以做到均匀平滑的限制请求,Ngixn 热 limit_req 模块也是采用此种算法。因为匀速处理请求的缘故所以该算法应对限流阈值内的突发请求无法及时处理。
令牌桶算法解决了以上三个算法的所有缺陷,是一种相对比较完美的限流算法,也是限流场景中应用最为广泛的算法。使用 Redis + Lua 脚本的方式可以简单的实现。
参考链接
https://www.nginx.com/blog/rate-limiting-nginx/
https://www.infoq.cn/article/qg2tx8fyw5vt-f3hh673
https://segmentfault.com/a/1190000019676878
https://en.wikipedia.org/wiki/Token_bucket
本文转载自:360 技术(ID:qihoo_tech)
原文链接:限流算法实践




