
机器学习架构可能是现代系统中最复杂、最昂贵和最困难的领域了。技术的数量和所需硬件的数量都在为缩减人员、托管和延迟预算而竞争。不幸的是,随着以数据仓库、微服务和 NoSQL 数据库为中心的最先进的架构使用量的不断增加,该行业的趋势在这些方面只会变得更加糟糕。
针对这种不断增长的复杂性,PostgresML 是一种更简单的替代方案。在本文中,我们探讨了更优雅的架构的一些额外性能优势,并发现 PostgresML 在本地测试中比传统的 Python 微服务的性能高出了 8 倍,在 AWS EC2 上则高出了 40 倍。
候选架构
考虑到 Python 微服务的所有可能优势,我们的第一个基准测试是在同一台机器上运行 Python 和 Redis。我们的目标是避免任何额外的网络延迟,这使得它与 PostgresML 的对比更加公平。我们的第二个测试是在 AWS EC2 上进行的,Redis 和 Gunicorn 由网络分隔开;这个基准测试被证明是相对具有破坏性的。
这两个基准测试的完整源代码可以在Github上找到。
PostgresML
PostgresML 架构由以下部分组成:
带有 PostgresML v2.0 的 PostgreSQL 服务器
pgbench SQL 客户端
Python
Python 架构由以下部分组成:
接受并返回 JSON 的 Flask/Gunicorn 服务器
带有训练数据的 CSV 文件
带有使用 JSON 序列化推理数据集的 Redis 特征存储
ab HTTP 客户端
ML
这两种架构都托管了相同的 XGBoost 模型,并针对相同的数据集运行预测。相关详细信息,请参阅方法论部分。
结果
吞吐量
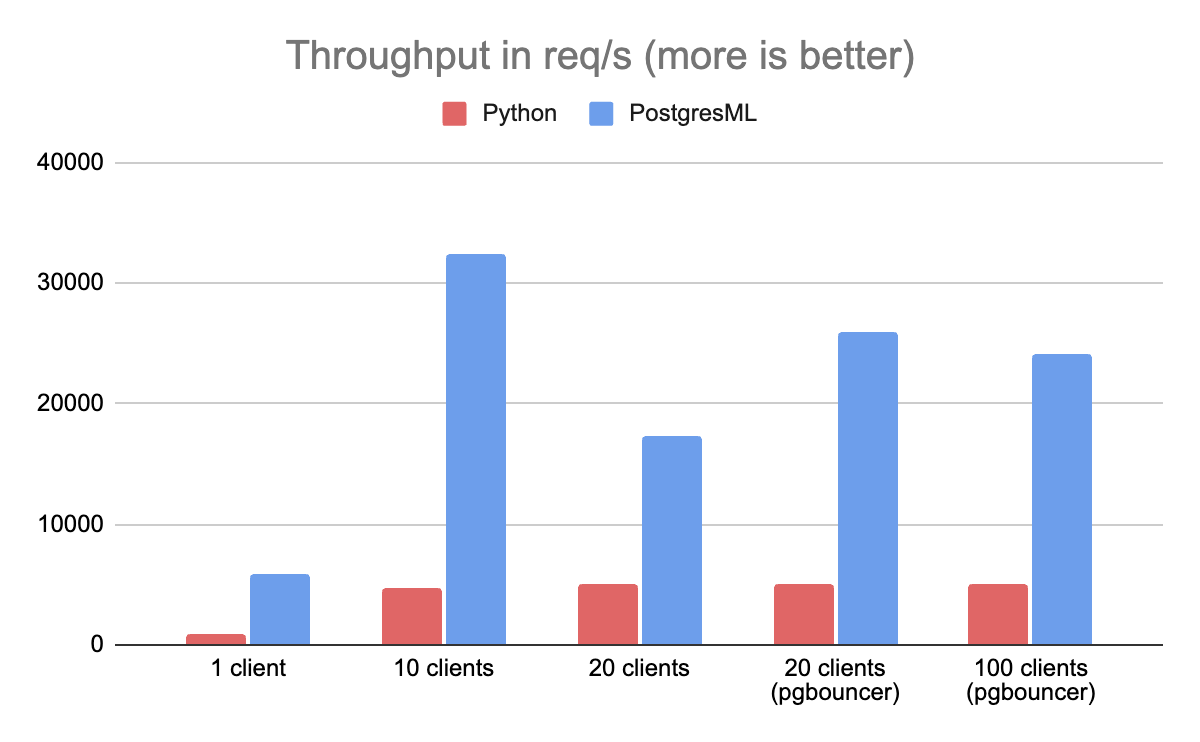
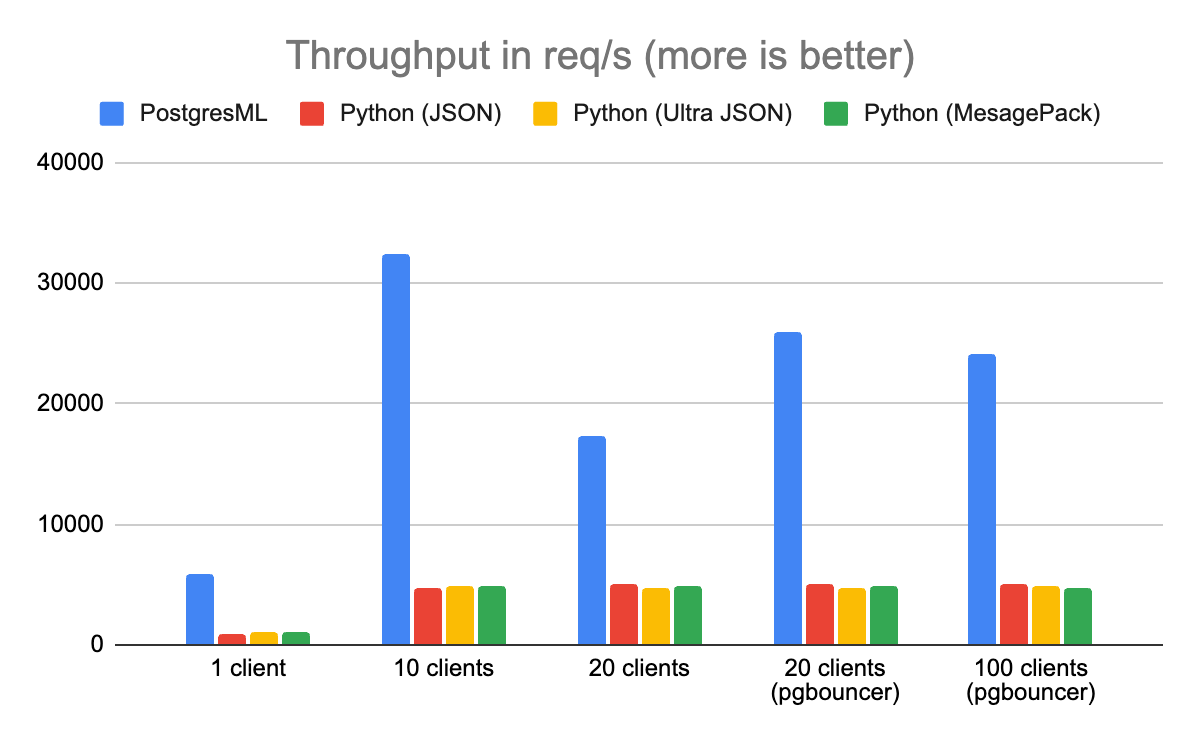
吞吐量(Throughput)被定义为架构每秒可以服务的 XGBoost 预测的数量。在这个基准测试中,PostgresML 的性能比运行在同一台机器上的 Python 和 Redis 要高 8 倍。
在 Python 中,大部分瓶颈来自于必须获取并反序列化 Redis 数据。由于这些特征是在外部存储的,因此它们需要通过 Python 传递到 XGBoost 中。XGBoost 本身是用 C++编写的,它的 Python 库只提供了一个便利的接口。来自 XGBoost 的预测必须再次通过 Python,序列化为 JSON,并通过 HTTP 发送到客户端。
这几乎是你可以为推理微服务所能做的最低限度的工作了。
另一方面,PostgresML 对数据和计算进行了配置。它从 Postgres 表中获取数据,该表已经采用了标准浮点格式,Rust 推理层通过指针将其转发给 XGBoost。
当基准测试达到 20 个客户端时,发生了一件有趣的事情:PostgresML 的吞吐量开始快速下降。这可能会让一些人感到惊讶,但对于 Postgres 的爱好者来说,这是一个已知问题:Postgres 并不擅长处理比 CPU 线程更多的并发活动连接。为了缓解这一问题,我们在数据库之前引入了 PgBouncer(一个 Postgres 代理和池化器),吞吐量也随之增加了,并且在达到 100 个客户端时继续保持不变。
值得注意的是,基准测试机只有 16 个可用 CPU 线程(8 核)。如果有更多的内核可用,瓶颈只会在有更多的客户端时出现。Postgres 服务器的一般建议是为每个可用 CPU 内核打开大约 2 个连接,尽管较新版本的 PostgreSQL 已经逐渐消除了这一限制。
为什么吞吐量很重要
吞吐量能让你事半功倍,用更少的资源做更多的事情。如果你能够使用一台机器每秒处理 30000 个查询,但现在只使用 1000 个查询,那么你不太可能需要在短时间内进行升级。另一方面,如果系统只能处理 5000 个请求,那么在不久的将来,你将会进行一项昂贵且可能会是压力很大的升级。
延迟
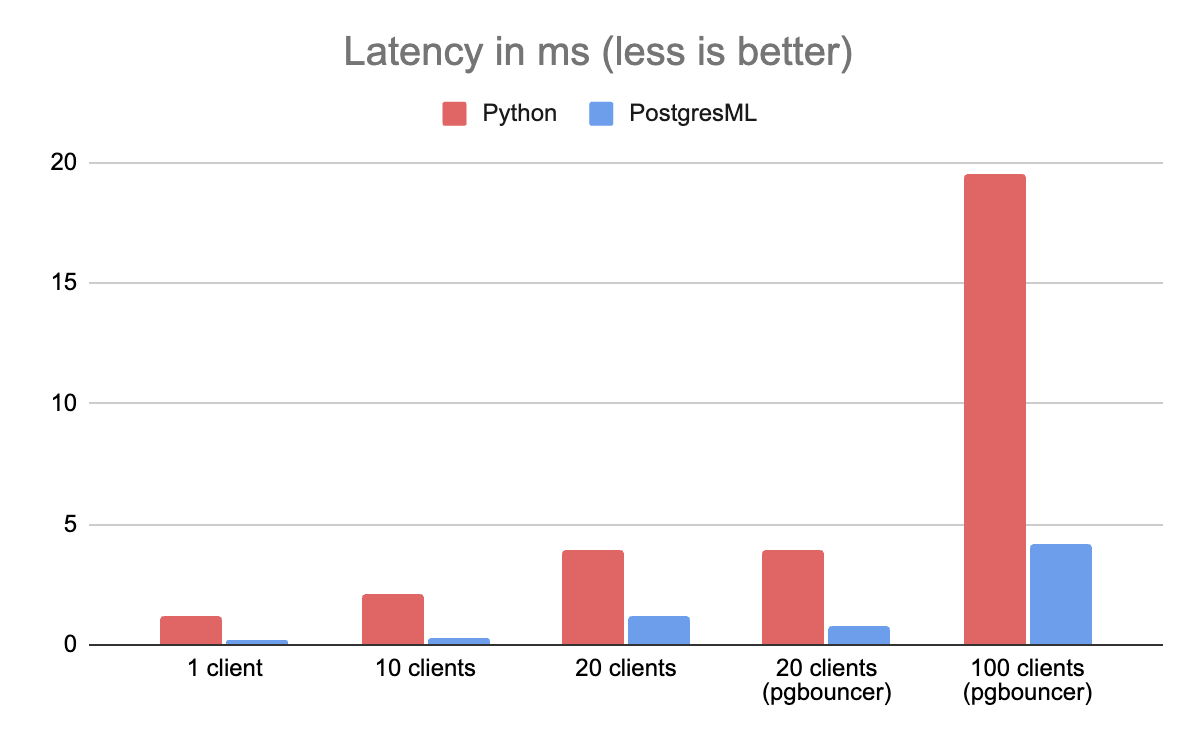
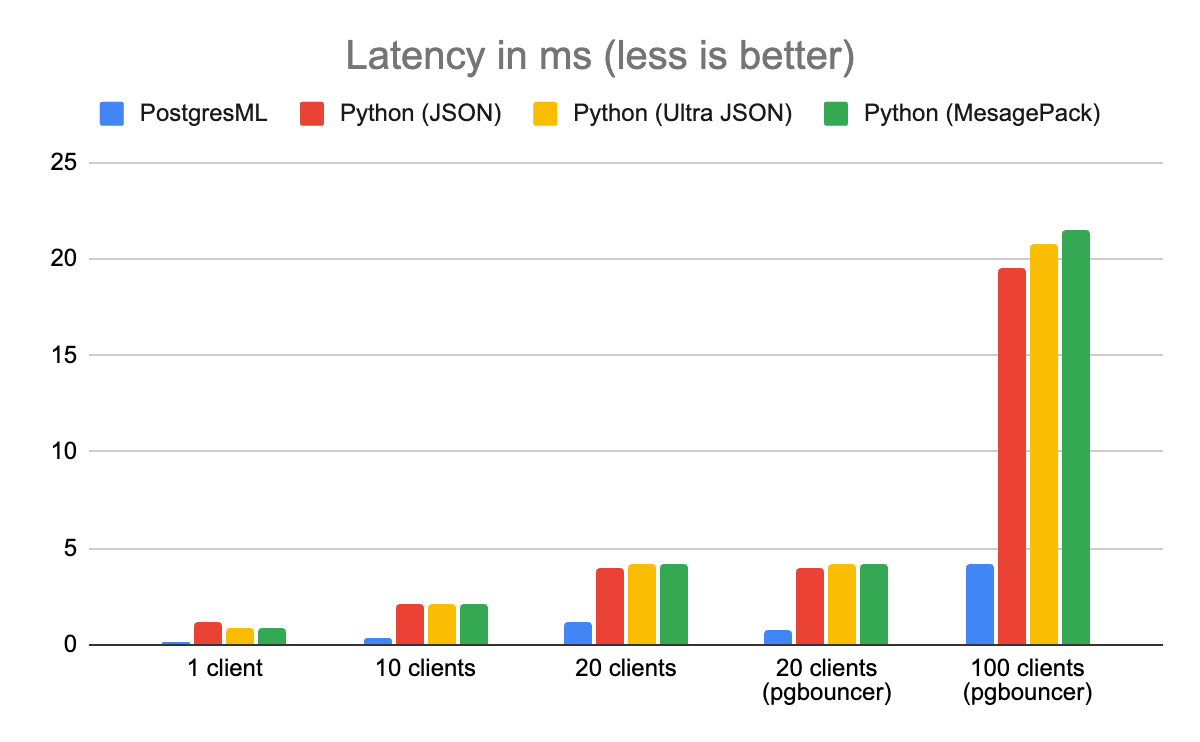
延迟(Latency)被定义为返回单个 XGBoost 预测所需的时间。由于大多数系统的资源是有限的,吞吐量直接影响延迟(反之亦然)。如果有许多活动请求,则在队列中等待的客户端就需要更长的时间才能得到服务,并且整体系统延迟会增加。
在这个基准测试中,PostgresML 的表现也比 Python 好 8 倍。你会注意到,同样的问题在有 20 个客户端时也会发生,使用 PgBouncer 进行相同的缓解措施会减少其影响。与此同时,Python 的延迟继续大幅增加。
在描述架构的性能时,延迟是一个很好的度量指标。换句话说,如果我要使用这项服务,我最多会只能在这么长的时间内得到一个预测,而不管还有多少其他客户也正在使用它。
为什么延迟很重要
延迟在机器学习服务中很重要,因为它们通常作为主应用程序的附加部分来运行,有时必须在同一 HTTP 请求期间多次访问。
让我们以电子商务网站为例。典型的店面希望同时展示多个个性化模型。这类模型的示例可能包括针对重复购买的“再次购买”建议(二分分类),或“你所在地区的热门商品”(购买历史的地理聚类)或“像你这样的客户还购买了该商品”(最近邻模型)。
所有这些模型都很重要,因为随着时间的推移,它们已被证明在推动购买方面非常成功。如果推理延迟很高,那么模型就会开始争夺非常昂贵的空间、头版和结算,而企业不得不放弃其中的一些,或者更有可能是遭受页面加载缓慢的影响。没有人喜欢在订购食品杂货或晚餐时使用运行缓慢的程序。
内存利用率
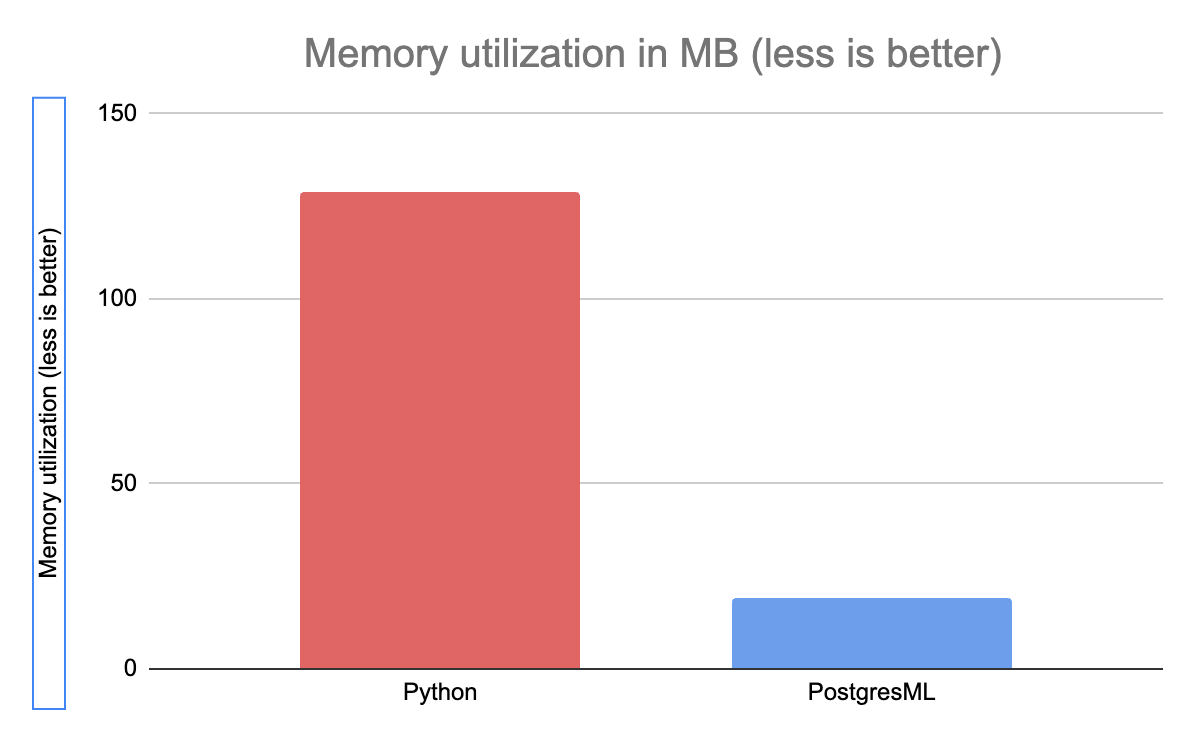
众所周知,Python 比其他更优化的语言使用更多的内存,在这种情况下,它使用的内存是 PostgresML 的 7 倍。
PostgresML 是 Postgres 扩展,它与数据库服务器共享 RAM。Postgres 在只获取和分配它所需的内存方面非常高效:它重用 shared_buffers 和操作系统(OS)页面缓存来存储行以进行推理,并且只需要很少甚至根本不需要分配内存来服务查询。
同时,Python 必须为它从 Redis 接收到的每个特征以及它返回的每个 HTTP 响应分配内存。这个基准测试并未测量 Redis 的内存利用率,这是运行传统机器学习微服务的额外成本,而且通常是相当大的成本。
训练
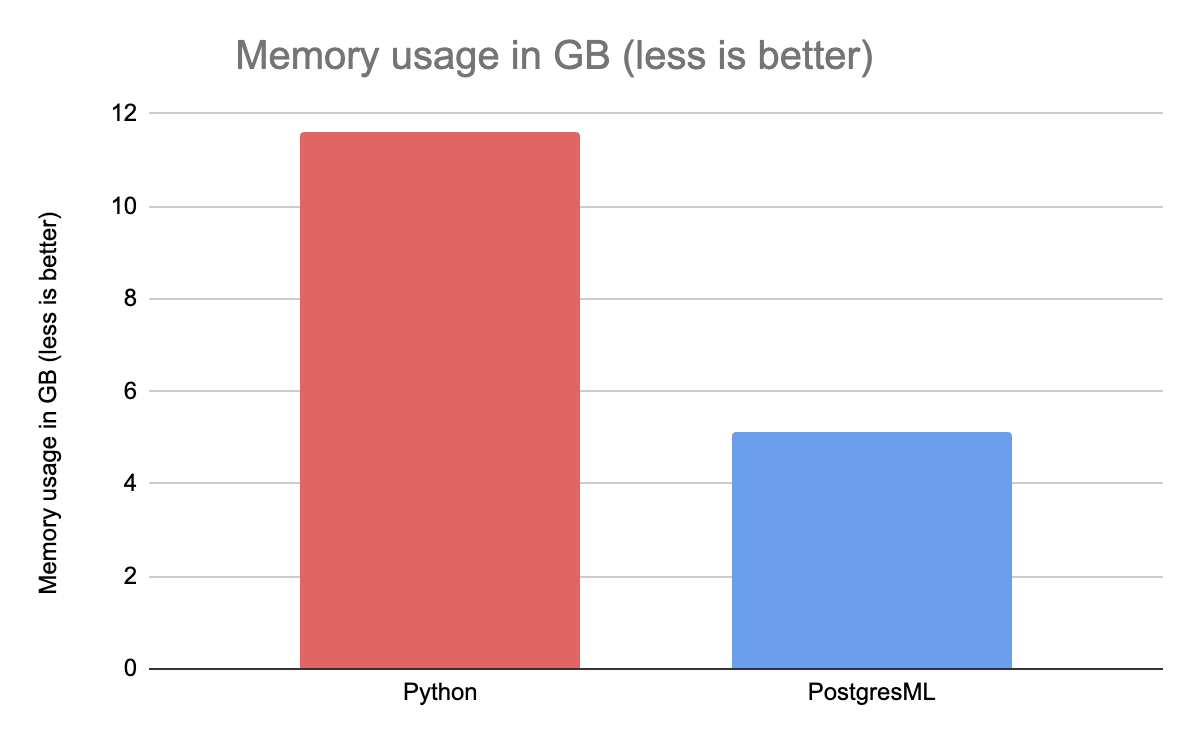
由于 Python 经常使用 Pandas 来加载和预处理数据,因此它尤其需要更多的内存。甚至在将数据传递到 XGBoost 之前,我们已经达到了 8GB RSS(驻留集大小);在实际的拟合过程中,内存利用率几乎达到了 12GB。这个测试是 Python 的另一个最佳案例场景,因为数据已经被预处理过了,只是将其传递给了算法而已。
同时,PostresML 喜欢与 Postgres 服务器共享 RAM,只分配 XGBoost 所需的内存即可。数据集的大小非常大,但我们仅使用 5GB 的 RAM 就能成功地训练相同的模型。因此,在使用相同硬件的情况下,PostgresML 允许的数据集上的训练模型至少是 Python 的两倍。
为什么内存利用率很重要
这是另一个事半功倍的例子。FAANG 和研究型大学之外的大多数机器学习算法都要求数据集能够装入单个机器的内存中。分布式训练并不是我们所希望的,而且从简单的线性回归中仍然可以提取很多价值。
使用更少的 RAM 可以在更大、更完整的数据集上训练更大、更好的模型。如果你碰巧遭受了大量机器学习计算费用的困扰,那么在你的财年结束时,使用更少的 RAM 可能能给你带来惊喜。
UltraJSON/MessagePack/Serializer X 呢?
我们花了很多时间来讨论序列化,因此回顾该领域之前的工作是有意义的。
JSON 是对用户最友好的格式,但它肯定不是最快的。例如,MessagePack 和 Ultra JSON 有时在读取和存储二进制信息方面更快、更高效。那么,在这个基准测试中使用它们会比使用 Python 的内置 json 模块更好吗?
答案是:并非如此。
(反)序列化的时间很重要,但首先最终需要进行(反)序列化就是瓶颈。从远程系统(例如 Redis 这样的特征存储)中取出数据,通过网络套接字发送数据,将其解析为 Python 对象(需要内存分配),然后再将其转换为 XGBoost 的二进制类型,这会在系统中造成不必要的延迟。
PostgresML 对 Postgres 的特征进行了一次内存拷贝。没有网络,没有(反)序列化,没有不必要的延迟。
现实情况如何呢?
通过 ocalhost 进行测试很方便,但这不是最现实的基准测试。在生产部署中,客户端和服务器位于不同的机器上,而在 Python+Redis 架构中,特征存储又是在另一个网络跳转点上。
为了演示这一点,我们启动了 3 个 EC2 实例并再次运行基准测试。这一次,PostgresML 比 Python 和 Redis 的表现要好 40 倍。
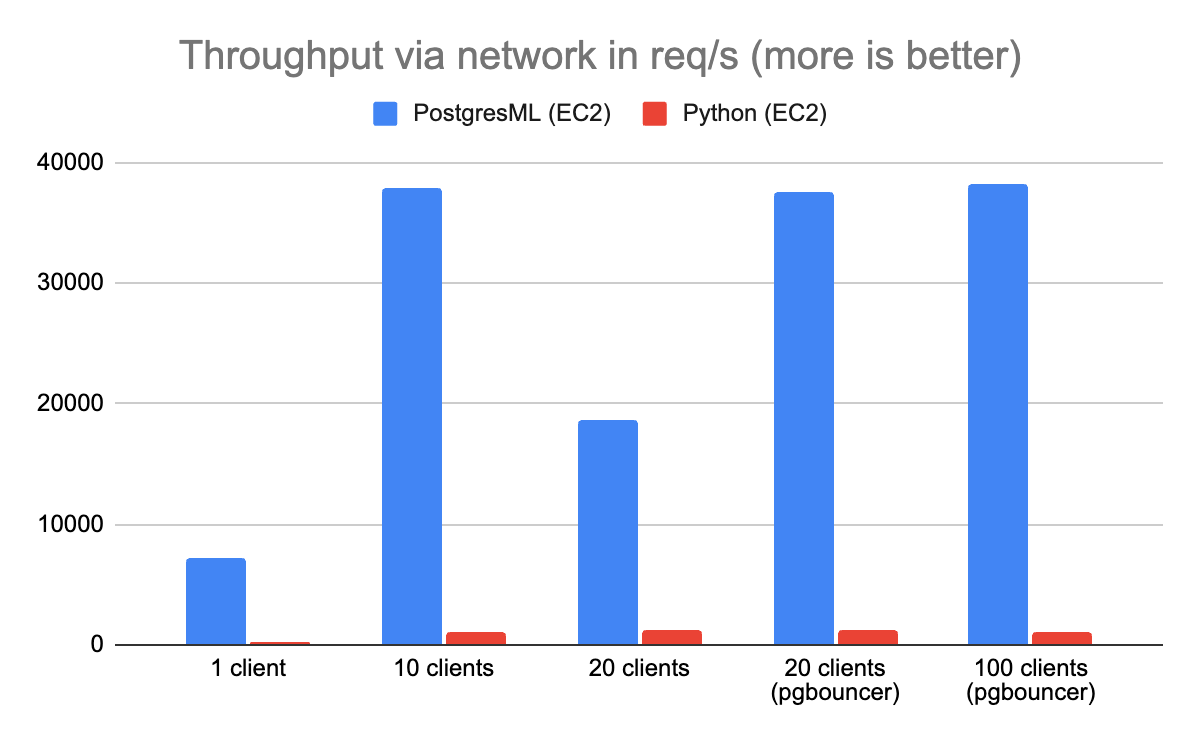
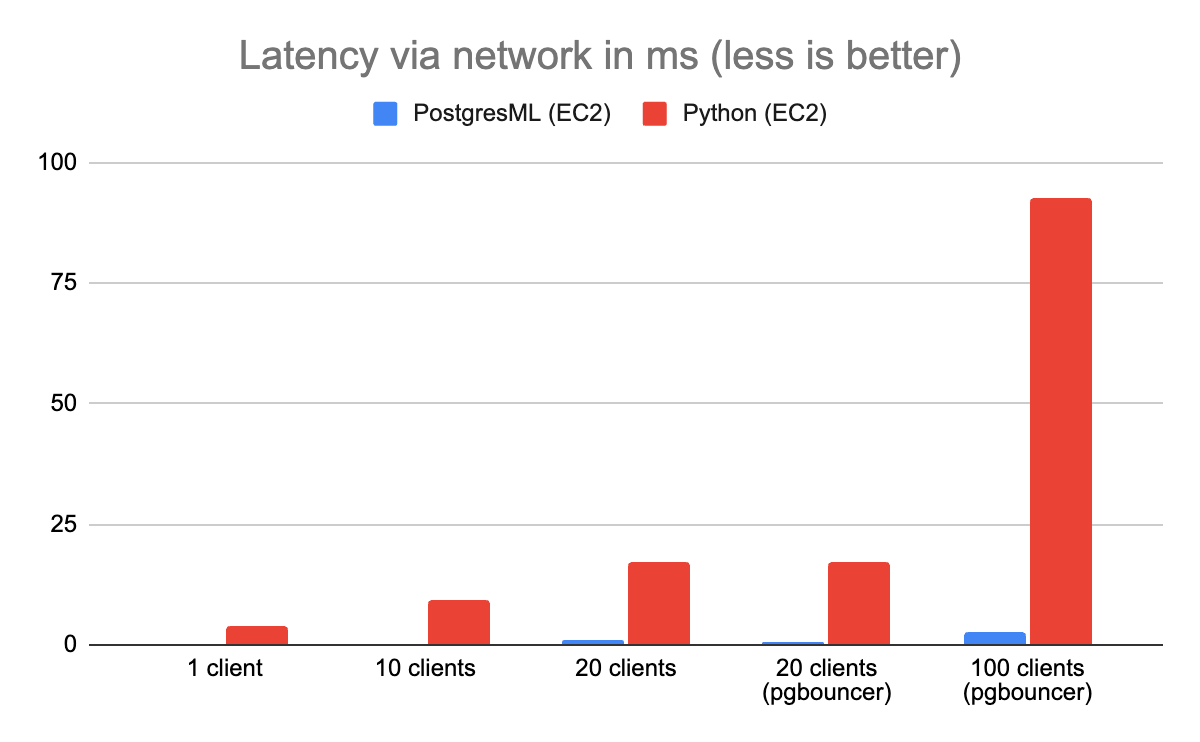
Redis 和 Gunicorn 之间的网络差距让事情变得非常非常糟糕……。从远程特征存储中获取数据增加了 Python 架构无法避免的请求毫秒数。在一个资源有限的系统中,额外的延迟造成了争用。大多数 Gunicorn 线程只是在网络上等待,成千上万的请求被卡在了队列中。
PostgresML 没有这个问题,因为特征和 Rust 推理层位于同一个系统上。这种架构选择消除了等式中的网络延迟和(反)序列化。
你会注意到我们前面讨论的并发性问题在有 20 个连接时影响了 Postgres,我们再次使用 PgBouncer 来挽救局面。一旦你知道了如何去做,扩展 Postgres 并不像听起来那么困难。
方法论
硬件
第一个基准测试中的客户端和服务器都位于同一台机器上。Redis 也是本地的。该机器是一台 8 核、16 线程的 AMD Ryzen 7 5800X,配备了 32GB RAM、1TB NVMe SSD,并运行有 Ubuntu 22.04。
AWS EC2 基准测试分别使用了一个托管了 Gunicorn 和 PostgresML 的c5.4xlarge 实例,以及两个 c5.5large 客户端和 Redis 实例。它们位于同一 VPC 中。
配置
Gunicorn 运行时有 5 个进程(Worker),每个进程有 2 个线程(Thread)。Postgres 分别为 1 个、5 个和 20 个客户端使用 1、5 和 20 个连接。PgBouncer 的 default_pool_size 设为 10,因此 20 和 100 个客户端最多能使用 10 个 Postgres 连接。
XGBoost 在推理过程中允许使用 2 个线程,在训练过程中使用所有可用的 CPU 内核(16 个线程)。
ab 和 pgbench 都使用了所有的可用资源,但都是非常轻量级的;这些请求分别是单个 JSON 对象和单个查询。这两个客户端都使用了持久连接, ab 通过使用 HTTP Keep-Alives 实现, pgbench 则通过在基准测试期间一直保持 Postgres 连接打开。
ML
数据
我们使用了来自 Kaggle 的飞行状态预测( Flight Status Prediction )数据集。经过一些后置处理,它最终变成了大约 2GB 的浮点特征。我们并没有使用所有的列,因为其中一些列是多余的,例如机场名称和机场标识符,它们指的是同一个东西。
模型
我们的 XGBoost 模型使用默认超参和 25 个估计量(也称为增强轮)进行训练。
用于训练和推理的数据可在此处获取。存储在 Redis 特征存储中数据可在此处获取。这只是一个子集,因为用单个 Python 进程(2800 万行)将整个数据集加载到 Redis 需要花费数小时。与此同时,Postgres COPY 只需要大约一分钟。
对 PostgresML 模型进行如下的训练:
SELECT * FROM pgml.train( project_name => 'r2', algorithm => 'xgboost', hyperparams => '{ "n_estimators": 25 }');它的准确性很差(Python 版本也是如此),可能是因为我们遗漏了任何类型的天气信息,后者最有可能会导致机场的延误。
源代码
基准源代码可以在Github上找到。
反馈
非常感谢所有支持这一努力的人。我们希望听到来自更广泛的 ML 和工程社区关于应用程序和其他真实世界场景的反馈,以帮助我们确定工作的优先级。 你可以通过在我们的Github上为我们加注星标来表示你的支持。
项目 Github 地址:https://github.com/postgresml/postgresml
原文链接:
https://postgresml.org/blog/postgresml-is-8x-faster-than-python-http-microservices/#throughput
声明:本文为 InfoQ 翻译,未经许可禁止转载。




