
由于 Uber 在用户中的知名度和规模不断扩大,它也受到了网络空间中金融犯罪分子的关注。欺诈行为的一种类型是勾结,即用户之间的合作欺诈行为。举例来说,用户串通起来,用盗取的信用卡进行虚假旅程,导致信用卡退单(由银行发起的信用卡消费退款)。本文展示了一种应用前沿的、名为关系图卷积网络(relational graph convolutional network,RGCN)[1] 的深度图学习模型,用于检测这种勾结的案例研究。
在欺诈检测 [2] [3] 中,图学习方法得到了广泛应用。例如,在 Uber Eats,已经开发出一种图学习技术,可以浮现最有可能吸引单个用户的美食 [4]。图学习是一种提高我们在 Uber 平台上食物和餐馆推荐的质量和相关性的方式。在检测勾结行为中也可采用类似技术。从图 1 可以看出,欺诈性用户往往是联系在一起并聚集在一起的,这有助于检测。本文概述了一种关系图学习模型的案例研究,该模型利用这些信息来检测勾结用户,并使用不同的连接类型来改进学习。其目的在于分享我们在这一案例研究中的发现,并将其扩展到解决其他相关欺诈检测。需要注意的是,在 Uber 的产品平台上并没有使用本文开发的模型。
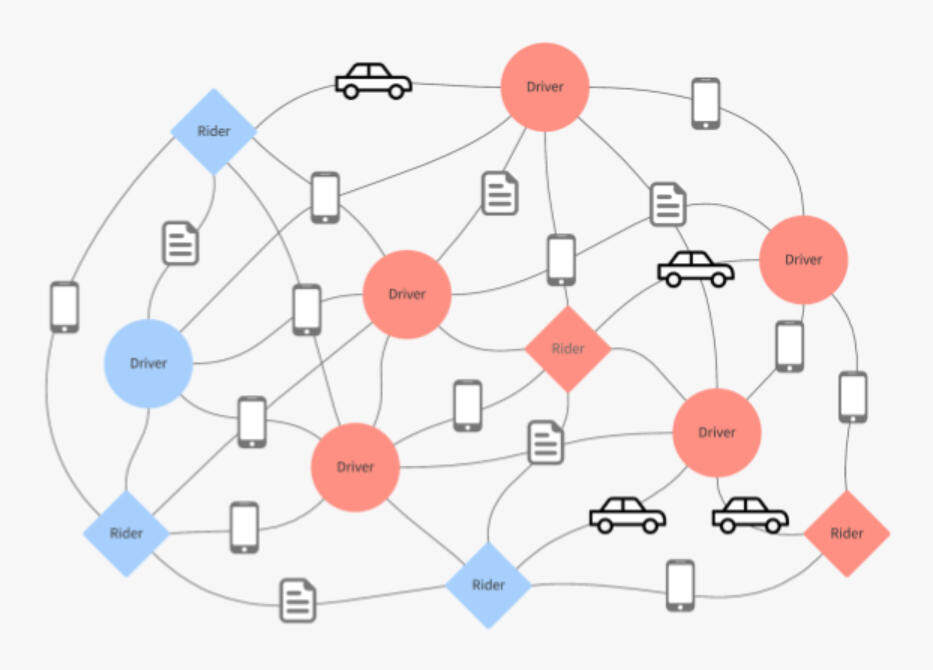
图 1:一个连接司机和乘客的图示。红色节点代表欺诈用户,蓝色节点代表合法用户。用户通过共享信息连接。
关系图学习
将 RGCN 模型应用于小样本数据,可以预测使用者是否存在欺诈行为。在用户图中,有两种类型的节点:通过共享信息,司机和乘客可以相互连接。每一个用户都可以被视为图中的一个节点,它由一个嵌入的向量表征。这种表征对用户及其邻近社区的属性进行编码,可方便地应用于机器学习任务,例如节点分类和边缘预测。例如,为了检测用户是否存在欺诈行为,我们不仅会使用该用户的特征,而且也会使用几个跳数内的邻近用户特征。该模型是基于对图进行操作的神经网络,专门为多关系图数据建模而开发。这种类型的图学习已经被证明能显著改善节点分类 [5]。
用户在平台上通过共享信息互相连接。结果表明,区分不同的连接类型能够放大欺诈检测的信号。所以,我们将连接类型用作图学习的一种特征。
要更好地理解如何为图用户数据进行建模并检测勾结行为,了解 RGCN 的基础知识是很有帮助的。图卷积网络(Graph convolutional network,GCN)在编码来自结构化邻域的特征时,证明了效率很高 [6],在链接到源节点的边缘时,它们分配的权重相同。而 RGCN 则根据边缘的类型和方向有特定关系的转换。这样,对每个节点计算的消息都会增加边缘类型信息。图 2 展示了 RGCN 模型的示意图。该模型的输入包括节点特征和边缘类型。节点特征被传递到 RGCN 层,通过聚合从所链接的邻居中学到的表征转换成对学习表征的向量。从相连邻居获得的信息由边缘类型加权。具体地说,该模型通过加权和归一化累积邻近节点的信息,把这些信息传递给目标节点,以便学习 RGCN 层的隐层表征,然后把这些信息传递给激活函数(例如 ReLU)。RGCN 层通过消息传递和图卷积的方式来提取高级节点表征。将 Softmax 层作为输出层,将交叉熵作为损失函数,RGCN 模型能够学会节点的分数。
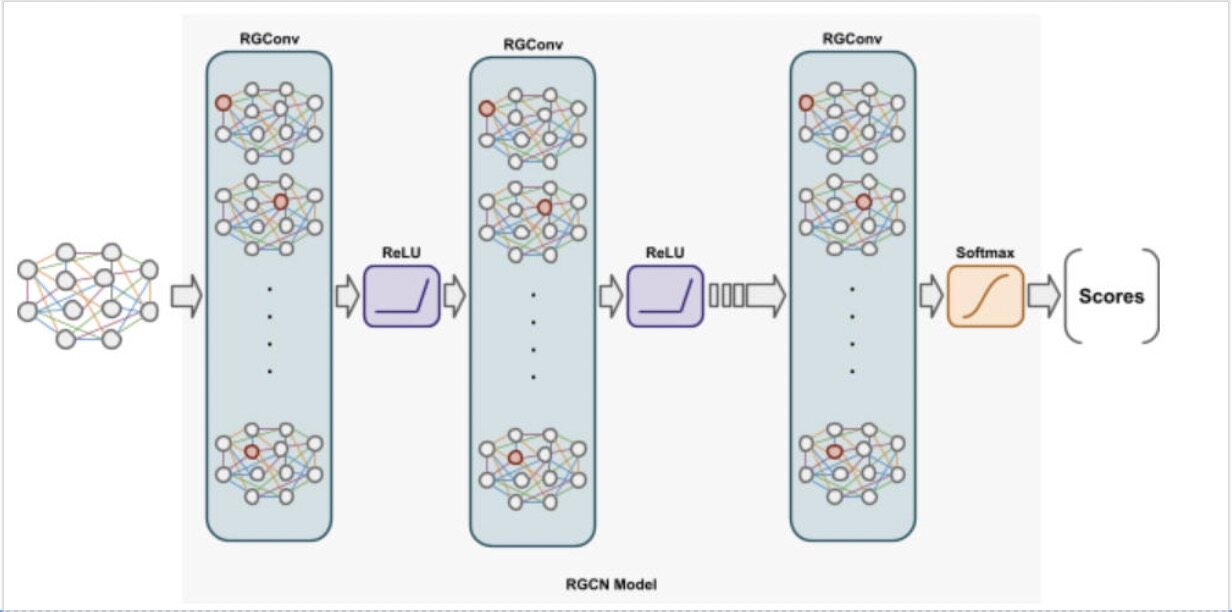
图 2:RGCN 的建模流程:将用户的节点特征和边缘类型的输入传递给多个 RGCN 层,从而生成节点分数。边缘的颜色代表不同的边缘类型。
邻近节点的变换特征向量取决于特定的边缘变换,这些变换记录了一条边缘的类型和方向。对于第 l+1 层的节点,还可以通过第 l 层中相应的表征告知它们,这是将单个自连接作为一个特殊的边缘类型添加到每个节点上的结果。可以用第 l+1 层计算的信息来表征为:
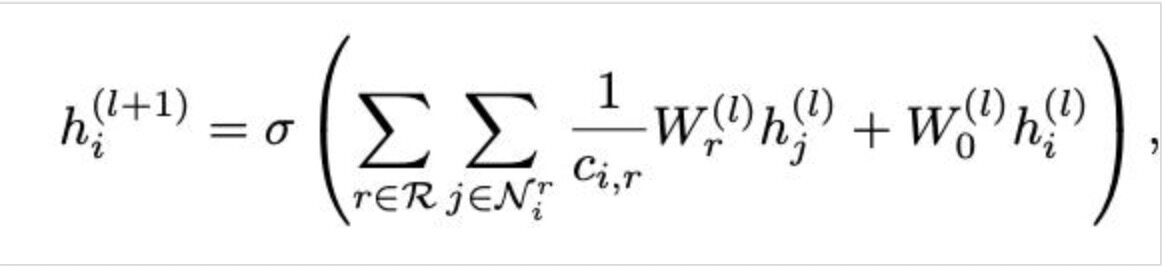

用于欺诈的 RGCN
Uber 拥有多种风险模型和多个检查点,用于发现欺诈用户。要更好地为这些风险模型服务,一种想法是将欺诈分数作为下游风险模型的特征。RGCN 模型为每个用户输出欺诈分数,表示用户的风险。欺诈分数的学习流程如图 3 所示。图中每个节点的隐层表征被学习,通过最小化二值交叉熵(binary cross entropy)损失来预测一个用户是否是欺诈性的。一个用户可以是司机、乘客或两者都是,因此我们将输出两个分数:一个是司机,一个是乘客。将这两个分数作为两个特征被注入到下游的风险模型中。
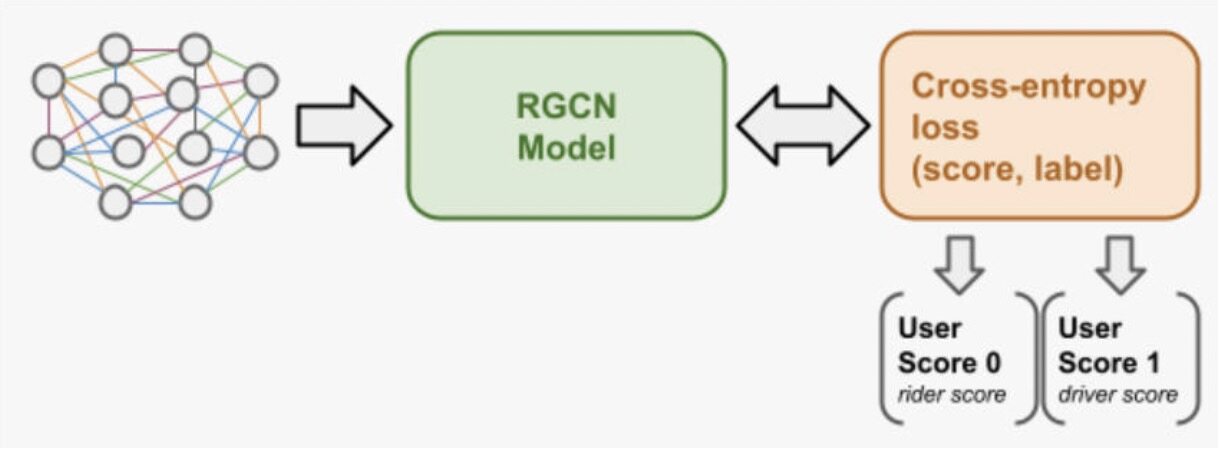
图 2:欺诈分数建模流程:分数是通过二值交叉熵损失来学习的。模型的输出是两个分数,一个是司机的分数,一个是乘客的分数。
我们采用两种输入来源:节点特征(面向用户的)和边缘类型。司机 - 乘客的内存图是用 DGL 库 [7] 构建的。欺诈的标签是指用户在某个时间范围内,是否存在信用卡退单行为。我们通过特征工程的方法来帮助模型学习。例如,一个司机 - 乘客图有两种类型的节点:司机和乘客。每一种节点类型,司机或乘客可能具有不同的特征。针对这一问题,我们采用零填充来保证输入的特征向量大小相等;其次,我们专门定义了边缘类型,并在模型训练期间为每种类型学习不同的权重。
为了评估 RGCN 模型的性能和欺诈分数的效用,我们对历史数据进行了 4 个月的训练,直到一个特定的分割日期。然后,我们根据分割日期之后 6 周的数据,对模型进行了性能测试。具体来说,我们为用户输出了欺诈分数,并计算了准确率、召回率 和 AUC。在实验过程中,我们观察到,通过在现有的生产模型中增加两个欺诈分数特征,准确率提高了 15%,而误报率的增加却很小。在下游模型的 200 个特征中,这两种欺诈的分数分别位于第 4 位和第 39 位。
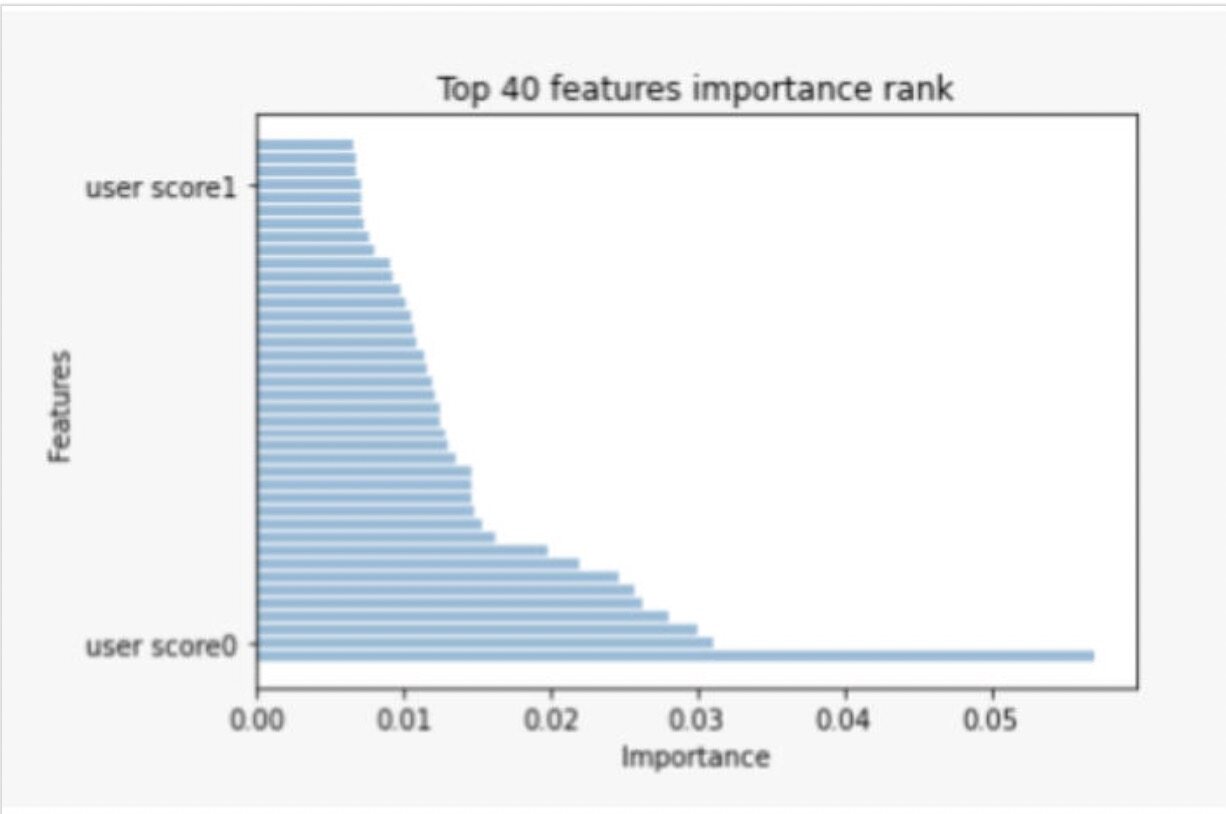
图 4:下游风险模型所使用的特征重要性:从 RGCN 学到的用户分数 1 和用户分数 0 分别排在第 4 和第 39 位。
数据管道
数据获取
此前一篇关于 Uber Eats 的美食发现的博文 [4] 中,解释了我们如何利用离线图生态系统来生成一个城市级别的用户 - 餐厅图。对于这一用例,我们的需求是建立一个巨大的图,而非一些更小的城市级图。我们通过重用许多组件,如 Spark 上的 Cypher,可以生成多关系的用户图。获取框架将源 Hive 表转换为节点表和关系表。节点表捕获用户特征,而关系表捕获用户之间不同类型的边。
图划分
图的大尺寸使得分布式训练和预测成为必要。初始图被划分成一些更小的图,这样它就可以放入工作机器的内存中。我们只对最近使用过 Uber 平台的用户的 x-hop 子图感兴趣。这些最近的“种子用户”随后被随机分配到一个分区号(0 到 n)。每个种子用户的 x-hop 子图也被拉入同一个分区中。一个用户可能是多个分区的一部分,或者不在任何分区中的休眠用户。每一个分区对应着一个训练 / 预测工作机器。
通过扩展 Cypher 语言,我们为图的创建添加了一个分区子句。以下查询示例将自动生成多个由分区列划分的图。每个分区将包含种子用户和他们的单跳邻居。

超级节点
图生成过程的一大挑战是如何处理超级节点,即具有极高连接量的节点。这个问题可以分为两个阶段来处理。第一,在创建关系表的同时,对具有高连接度的实体进行过滤。举例来说,两个用户通过 1000 个共享实体进行连接,会产生 10002 个用户 - 用户关系。但是,我们将技术作为一个节点特征加进来。第二,在图的划分阶段,有些用户在他们的子图上表现出了具有非常高程度的不同关系。这样会增大分区大小的差异,有些分区甚至很大。基于阈值,我们将这类用户限制为他们的前几跳。这类离群值的情况可以用规则加以追踪。
训练与批量预测
数据管线和训练管道如图 5 所示。从 Apache Hive 表中获得数据,并将包含节点和边缘信息的 Parquet 文件作为 HDFS 输入,这是管道的第一步。每一个节点和边都由一个时间戳进行版本化。具有节点和边的最新属性的图被保留下来,使用 Cypher 格式存储在 HDFS 中,并给定一个特定的日期。在使用 Apache Spark 执行引擎中的 Cypher 查询语言将图划分到模型中。图的分区被直接送入 DGL 训练和批量预测应用程序。生成的分数存储在 Hive 中,用于操作和离线分析。
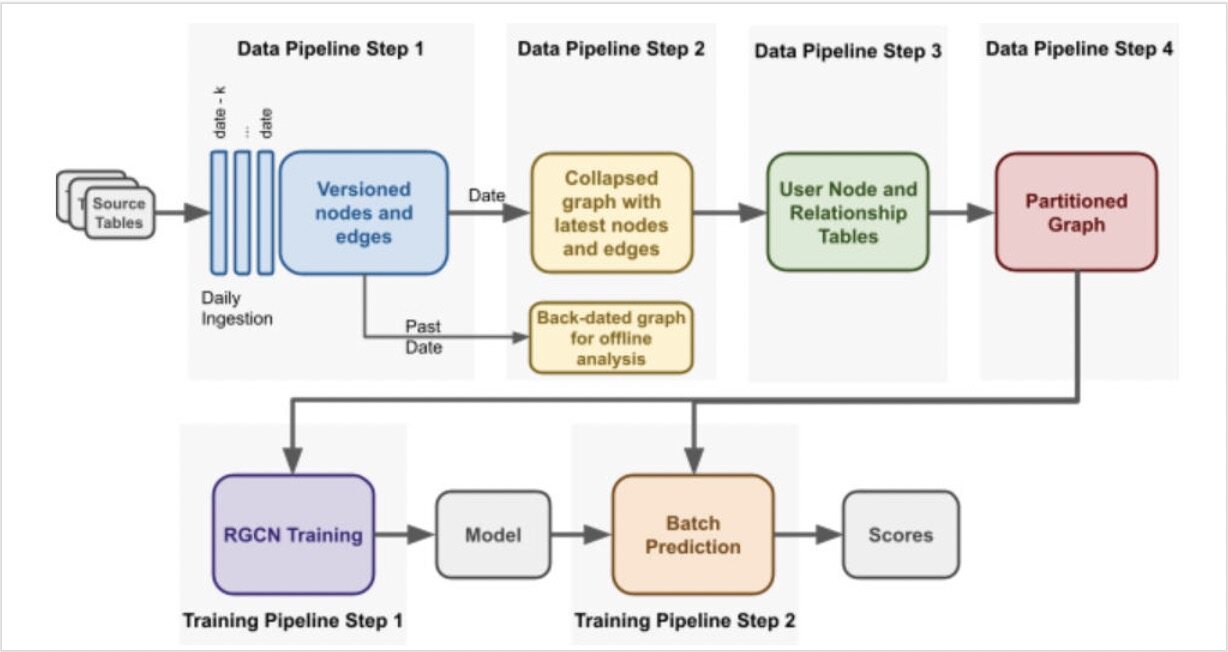
图 5:用于学习欺诈分数的数据管道(上行)和用于改进欺诈检测的训练管道(下行)
未来方向
图学习在学术界和工业界都受到广泛关注。它提供了一种令人信服的欺诈检测方法。尽管图学习已经极大地提高了检测质量和相关性,但是还需要进一步的工作来提高系统的可扩展性和实时性。特别是,我们正在探索一种更有效的方式来存储大规模的图,并进行分布式训练和实时服务。此外,由于司机 - 乘客图是密集连接的,为了使信息传递更加有效,我们将探索基于注意力的图模型,它利用掩蔽的自注意力层,赋予邻域不同节点不同的重要性。例如,图注意力网络 [8] [9] 与我们的应用相关。
参考文献
《用图卷积网络对关系型数据进行建模》(Modeling Relational Data with Graph Convolutional Networks),Michael Schlichtkrull、Thomas N. Kipf、Peter Bloem、Rianne van den、Ivan Titov、Max Welling,ESWC 2018。
《异构图神经网络在恶意账户检测中的应用》(Heterogeneous Graph Neural Network),Ziqi Liu、Chaochao Chen 等人,CIKM 2018。
《Web 级推荐系统中的图卷积神经网络》(Graph Convolutional Neural Networks for Web-Scale Recommender Systems),Rex Ying、Ruining He、Kaifeng Chen、Pong Eksombatchai、William L. Hamilton、Jure Leskovec,KDD 2018。
《Uber Eats 的美食发现:利用图学习为推荐赋能》(Food Discovery with Uber Eats: Using Graph Learning to Power Recommendations),Ankit Jain、Isaac Liu、Ankur Sarda、Piero Molino。
《欺诈检测:基于图的异常检测方法的系统文献综述》(Fraud detection: A systematic literature review of graph-based anomaly detection approaches),Tahereh Pourhabibi、Kok-Leong Ong、Booi H.Kam、Yee Ling Boo,Decision Support Systems 2020。
《基于图卷积网络的半监督分类》(Semi-Supervised Classification with Graph Convolutional Networks),Thomas N. Kipf、Max Welling,ICLR 2017。
《Deep Graph Library:面向图的高效可扩展深度学习》(Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs),Minjie Wang、Lingfan Yu,ICLR 2019。
《图注意力网络》(Graph attention networks),Petar Velickovi、Guillem Cucurull、Arantxa Casanova、Adriana Romero、Pietro Lio、Yoshua Bengio,ICLR 2018。
《图注意网络的自适应结构指纹》(Adaptive structural fingerprints for graph attention networks),Kai Zhang、Yaokang Zhu、Jun Wang、Jie Zhang,ICLR 2020。
作者介绍:
Xinyu Hu,Uber 人工智能参与团队研究科学家。致力于机器学习、因果推理和图学习的交叉项目。拥有哥伦比亚大学生物统计学博士学位。
Chengliang Yang,Uber 风险工程团队机器学习工程师。致力于建立基于机器学习的解决方案,以识别 Uber 平台上的欺诈行为。拥有佛罗里达大学计算机科学博士学位,专业为机器学习。
Lawrence Murray,Uber 人工智能研究科学家经理,从事概率编程和贝叶斯推理的蒙特卡洛方法。拥有爱丁堡大学的信息学博士学位。
Ankur Sarda,Uber 风险工程团队软件工程师,致力于 Uber 的图应用。
Ankit Jain,Uber 人工智能的前研究科学家。
Piero Molino,斯坦福大学 Hazy 研究小组成员,研究科学家。Uber 人工智能的前创始成员,创建了 Ludwig,从事应用项目(COTA、Uber Eats 的图学习,Uber 的对话系统),并发表了关于自然语言处理、对话、可视化、图学习、强化学习和计算机世界的研究论文。
原文链接:




