
AutoML 是一种术语,描述了在真实世界场景中执行机器学习的自动化端到端过程。这是一种人工智能驱动的系统,其重点是自动地分析数据,并以最小的努力提供可操作的洞察力。目的是在重复和耗时的活动中减少数据科学家的负担。换言之,它允许我们把机器学习应用到真实世界的应用中,即使你并不是这方面的专家。
机器学习的目标是利用模型来建立模型表现形式,然后用这些模型来判断新的价值。在训练中,机器学习算法改进了模型,类似于人类幼儿通过监督下的教育和接触的混合学习来习得基本语言的方式。
它是一个将机器学习过程的每个步骤都计算机化的平台,从管理原始数据集到安装一个有用的机器学习模型。
AutoML 的用途
寻找一种适用于数据集的模型:每一种数据集都有多种方法,比如逻辑回归、决策树等等,而确定数据集的最佳策略可能是一个耗时的过程,需要大量的研究和定制。
超参数优化:每一种机器学习技术都包含代表每个变量权重的参数。大多数机器学习模型,除了参数外,还有超参数,通常都包含 dropout 和模型特定的参数,比如随机森林中的树的数量。开发者在训练阶段开始之前确定其值。由于超参数不同于模型参数,训练过程中没有通过数据学习,因此它们通常在训练阶段是恒定的。对超参数的最佳选择可以得到最准确的模型,但是需要有一种策略来决定理想的组合。
特征选择:特征工程是一个确定最佳变量集以及最佳编码的过程,用于训练过程的输入。最燃最好的特征通常依赖于所用的模型,但特征对于模型的构建是必不可少的。另外,采用的特征的数量会影响模型的开发和评分的时间,并有可能减缓整个过程。它用机械化的审查程序来确定哪种特征组合最有效。
AutoML 的重要性
无需人工干预:它可以将每个步骤计算机化,减少人工干预。
易于使用:它简化了机器学习方法的使用。
最大限度地利用资源:它使得任何商业或企业不需要投入额外的时间和金钱来寻找所有的专业人员,就能获得更高的投资回报。
通用:通过 AutoML,金融、营销、零售、交通和医疗保健等组织可以很容易地从人工智能和机器学习中获益。
有利于数据科学家:科学家们将能够更加专注于具有挑战性的问题,而非训练模型或做其他活动。
工作原理
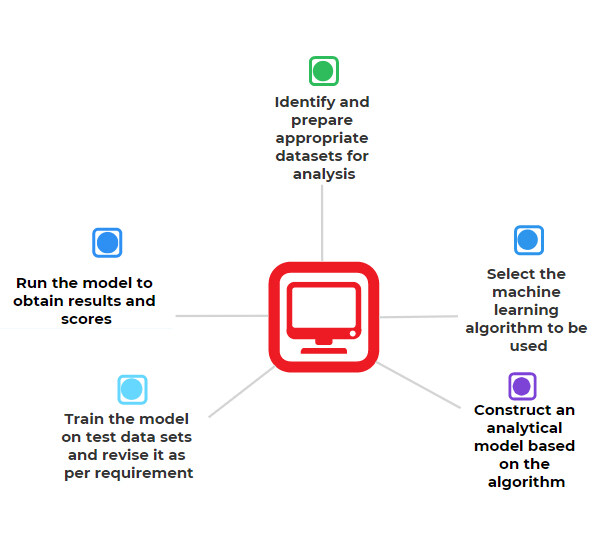
在将一个机器学习模型付诸实施的过程中,分为几个阶段。
传统的机器学习需要以下步骤:
从多种来源收集数据,并把它们合并到一个媒介中。
为了直接使用数据进行测试,需要做一些处理。包括清除重复、处理丢失值和检测泄漏。
机器学习过程的下一个阶段是特征工程,它试图将分类和序数值转换成数字特征。
为了选择合适的模型,以及决定哪一种模型在数据集中性能最好,需要进行额外的研究。这一阶段需要训练、分析和评估它的最佳性能。
超参数调优也用于通过微调参数来改进性能。
最终基于先前未知值生成预测结果。机器学习为教授使用机器学习模型的提问提供答案。
使用 AutoML 就可以减少这些步骤。AutoML 侧重于第一阶段的数据采集和最后一步的预测。正如名称所示,所有其他的中间阶段都是计算机化的。它使用组合值作为输入,并生成预测值作为输出。其生成的优化模型可用于预测。
AutoML 在现实生活中的应用
金融欺诈的检测:它有可能提高欺诈检测算法的准确性和精确度。
图像识别:可用来识别人脸。
网络安全:可用于网络安全方面的风险评估、监测和测试。
恶意软件:恶意软件和垃圾邮件是它可以用来创造适应性强的网络威胁的例子。
娱乐:可作为内容选择引擎。
客户服务:它可以用来分析聊天机器人的情绪,并提高客户服务团队的效率。
营销:它可以被用来通过预测分析来提高参与率。还可以利用它来提高社交媒体行为营销举措的效果。
医疗保健研究和开发:它可以评估大数据量并得出结论。
热门 AutoML 平台
Google Cloud AutoML:这是一个在云端中自动化机器学习的平台。它可以让你快速地创建自己独特的机器学习模型。
SMAC:SMAC 是改善算法参数的一个强大工具。对于机器学习算法的超参数调整相当有用。
Auto-Keras:这是一款由得克萨斯州农工大学和其他社区成员合作创建的免费开源代码库。该库被认为是提供自动搜索超参数和深度学习架构的方法。
Auto-sklearn:它基于 scikit-learn ML。为每个数据收集找到最佳方法,然后调整超参数。
数据科学家工作的未来
在我们讨论自动化是否会扼杀工作机会之前,有必要理解数据科学和机器学习的区别。
数据学家运用工程学、统计学和人类学的专业知识,从业务角度理解数据,并提供可靠的洞察力和预测。与此同时,机器学习算法有助于组织模式的识别。但是,它们在数据驱动过程中的功能局限于对未来事件产生预测。它们还不能完全了解具体数据对公司及其关系的意义。
事实上,低层次任务的某些方面可能会被计算机化,这会导致失去某些工作,降低总体收入。不过,请注意,AutoML 的主要目标是使科学家摆脱繁琐费时的工作。
AutoML 只是使科学家更容易关注复杂的问题。这也带来了巨大的需求。但是,如前所述,机器学习技术缺乏人的好奇心和动力来建立和验证研究。目前只有数据科学家才能这样做。
计算机将无法取代人类的决策和认知。从长远来看,技术的进步会增加这种情况发生的可能性,但是我们永远不知道未来会发生什么。
作者介绍:
Gunjan,有抱负的数据科学家,技术博客作家。
原文链接:




