
背景介绍
本文以抖音中最为复杂的功能,也是最重要的功能之一的交互区为例,和大家分享一下此次重构过程中的思考和方法,主要侧重在架构、结构方面。
交互区简介
交互区是指播放页面中可以操作的区域,简单理解就是除视频播放器外附着的功能,如下图红色区域中的作者名称、描述文案、头像、点赞、评论、分享按钮、蒙层、弹出面板等等,几乎是用户看到、用到最多的功能,也是最主要的流量入口。
发现问题
不要急于改代码,先梳理清楚功能、问题、代码,建立全局观,找到问题根本原因。
现状
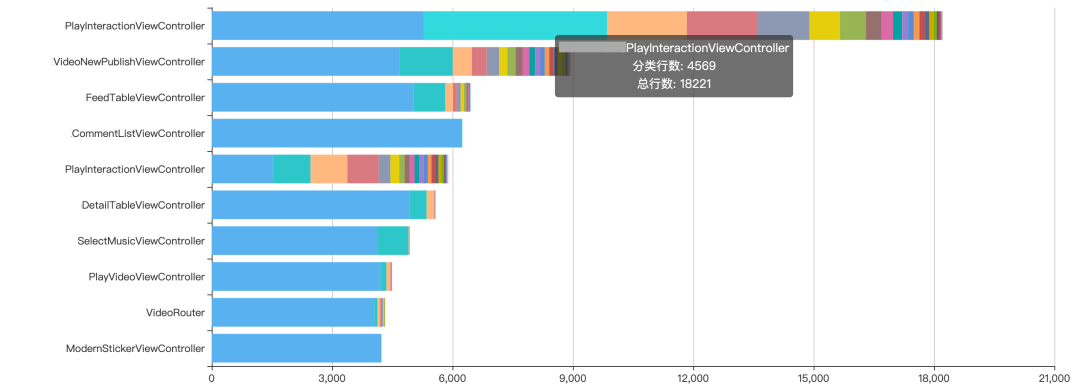
上图是代码量排行,排在首位的就是交互区的 ViewController,遥遥领先其他类,数据来源自研的代码量化系统,这是一个辅助业务发现架构、设计、代码问题的工具。
可进一步查看版本变化:
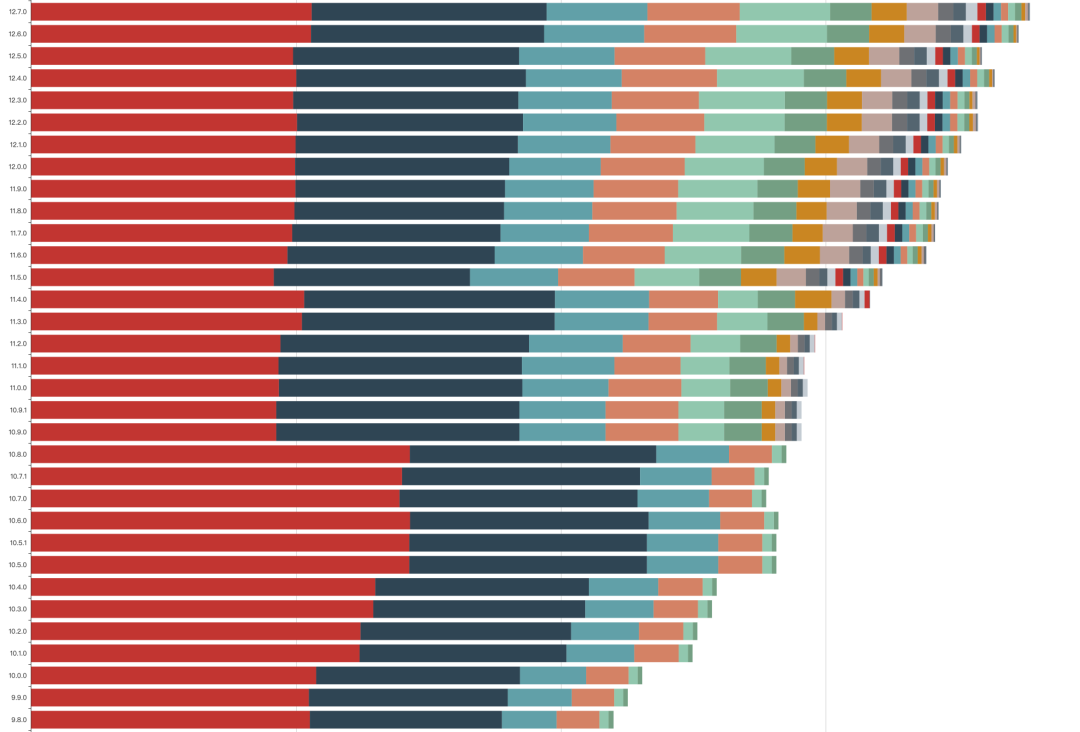
每周 1 版,在不到 1 年的时间,代码量翻倍,个别版本代码量减少,是局部在做优化,大趋势仍是快速增长。
除此之外:
可读性差:ViewController 代码量 1.8+万行,是抖音中最大的类,超过第 2 大的类一倍有余,另外交互区使用了 VIPER 结构(iOS 常用的结构:MVC、MVVM、MVP、VIPER),加上 IPER 另外 4 层,总代码规模超过了 3 万行,这样规模的代码,很难记清某个功能在哪,某个业务逻辑是什么样的,为了修改一处,需要读懂全部代码,非常不友好
扩展性差:新增、修改每个功能需要改动 VIPER 结构中的 5 个类,明明业务逻辑独立的功能,却需要大量耦合已有功能,修改已有代码,甚至引起连锁问题,修一个问题,结果又出了一个新问题
维护人员多:统计 commit 历史,每个月都有数个业务线、数十人提交代码,改动时相互的影响、冲突不断
理清业务
作者是抖音基础技术组,负责业务架构工作,交互区业务完全不了解,需要重新梳理。
事实上已经没有一个人了解所有业务,包括产品经理,也没有一个完整的需求文档查阅,需要根据代码、功能页面、操作来梳理清楚业务逻辑,不确定的再找相关开发、产品同学,省略中间过程,总计梳理了 10+个业务线,100+子功能,梳理这些功能的目的是:
按重要性分清主次,核心功能优先保障,分配更多的时间开发、测试
子功能之间的布局、交互是有一定的规律的,这些规律可以指导重构的设计
判断产品演化趋势,设计既要满足当下、也要有一定的前瞻性
自测时需要用,避免遗漏
理清代码
所有业务功能、问题最终都要落在代码上,理清代码才能真正理清问题,解决也从代码中体现,梳理如下:
代码量:VC 1.8 万行、总代码量超过 3 万行
接口:对外暴露了超过 200 个方法、100 个属性
依赖关系:VIPER 结构使用的不理想,Presenter 中直接依赖了 VC,互相耦合
内聚、耦合:一个子功能,代码散落在各处,并和其他子功能产生过多耦合
无用代码:大量无用的代码、不知道做什么的代码
View 层级:所有的子功能 View 都放在 VC 的直接子 View 中,也就是说 VC 有 100+个 subView,实际仅需要显示 10 个左右的子功能,其他的通过设置了 hidden 隐藏,但是创建并参与布局,会严重消耗性能
ABTest(分组对照试验):有几十个 ABTest,最长时间可以追溯到数年前,这些 ABTest 在自测、测试都难以全面覆盖
简单概括就是,需要完整的读完代码,重点是类之间的依赖关系,可以画类图结合着理解。
每一行代码都是有原因的,即便感觉没用,删一行可能就是一个线上事故。
趋势
抖音产品特性决定,视频播放页面占据绝大部分流量,各业务线都想要播放页面的导流,随着业务发展,不断向多样性、复杂性演化。
从播放页面的形态上看,已经经过多次探索、尝试,目前的播放页面模式相对稳定,业务主要以导流形式的入口扩展。
曾经尝试过的方式
ViewController 拆分 Category
将 ViewController 拆分为多个 Category,按 View 构造、布局、更新、业务线逻辑将代码拆分到 Category。这个方式可以解决部分问题,但有限,当功能非常复杂时就无法很好的支撑了,主要问题有:
拆分了 ViewController,但是 IPER 层没有拆分,拆分的不彻底,职责还是相互耦合
Category 之间互相访问需要的属性、内部方法时,需要暴露在头文件中,而这些是应该隐藏的
无法支持批量调用,如 ViewDidLoad 时机,需要各个 Category 方法定义不同方法(同名会被覆盖),逐个调用
左侧和底部的子功能放在一个 UIStackView 中
这个思路方向大体正确了,但是在尝试大半年后失败,删掉了代码。
正确的点在于:抽象了子功能之间的关系,利用 UIStackView 做布局。
失败的点在于:
局部重构:仅仅是局部重构,没有深入的分析整体功能、逻辑,没有彻底解决问题,Masonry 布局代码和 UIStackView 使用方式都放在 ViewController 中,不同功能的 view 很容易耦合,劣化依然存在,很快又然难以维护,这类似破窗效应
实施方案不完善:布局需要实现 2 套代码,开发、测试同学非常容易忽略,线上经常出问题
UIStackView crash:概率性 crash,崩在系统库中,大半年时间也没有找到原因
其他
还有一些提出 MVP、MVVM 等结构的方案,有的浅尝辄止、有的通过不了技术评审、有的不了了之。
关键问题
上面仅列举部分问题,如果按人头收集,那将数不胜数,但这些基本都是表象问题,找到问题的本质、原因,解决关键问题,才能彻底解决问题,很多表象问题也会被顺带解决。
经常提到的内聚、耦合、封装、分层等等思想感觉很好,用时却又没有真正解决问题,下面扩展两点,辅助分析、解决问题:
复杂度
“变量”与“常量”
复杂度
复杂功能难以维护的原因的是因为复杂。
是的,很直接,相对的,设计、重构等手法都是让事情变得简单,但变简单的过程并不简单,从 2 个角度切入来拆解:
量
关系
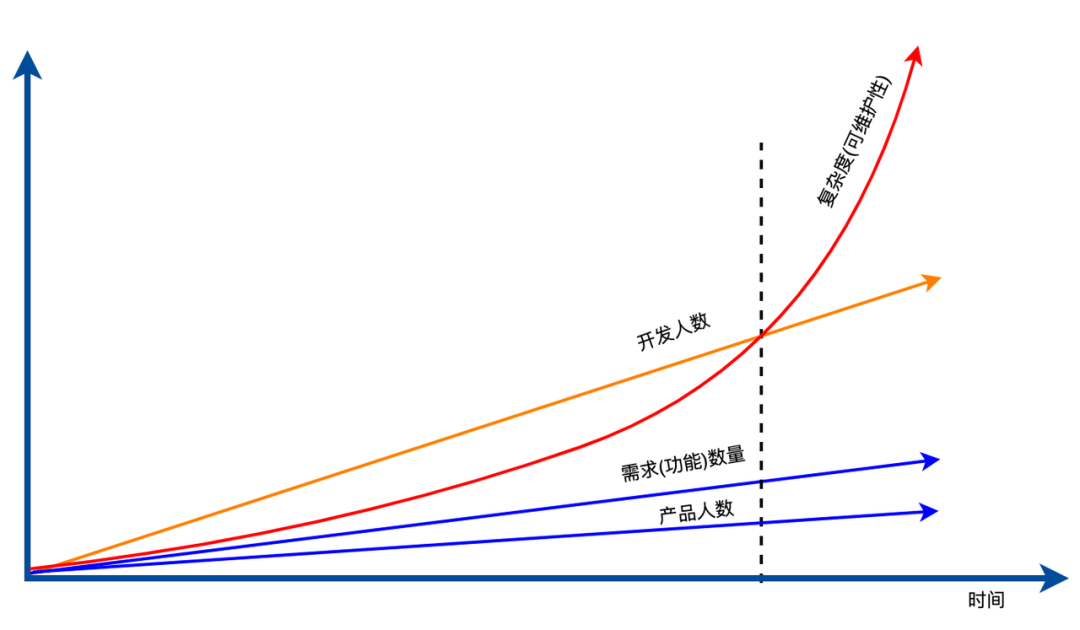
量:量是显性的,功能不断增加,相应的需要更多人来开发、维护,需要写更多代码,也就越来越难维护,这些是显而易见的。
关系:关系是隐性的,功能之间产生耦合即为发生关系,假设 2 个功能之间有依赖,关系数量记为 1,那 3 者之间关系数量为 3,4 者之间关系数量为 6,这是一个指数增加的,当数量足够大时,复杂度会很夸张,关系并不容易看出来,因此很容易产生让人意想不到的变化。
功能的数量大体可以认为是随产品人数线性增长的,即复杂度也是线性增长,随着开发人数同步增长是可以继续维护的。如果关系数量指数级增长,那么很快就无法维护了。
“变量”与“常量”
“变量”是指相比上几个版本,哪些代码变了,与之对应的“常量”即哪些代码没变,目的是:
从过去的变化中找到规律,以适应未来的变化。
平常提到的封装、内聚、解耦等概念,都是静态的,即某一个时间点合理,不意味着未来也合理,期望改进可以在更长的时间范围内合理,称之为动态,找到代码中的“变量”与“常量”是比较有效的手段,相应的代码也有不同的优化趋向:
对于“变量”,需要保证职责内聚、单一,易扩展
对于“常量”,需要封装,减少干扰,对使用者透明
回到交互区重构场景,发现新加的子功能,基本都加在固定的 3 个区域中,布局是上下撑开,这里的变指的就是新加的子功能,不变指的是加的位置和其他子功能的位置关系、逻辑关系,那么变化的部分,可以提供一个灵活的扩展机制来支持,不变的部分中,业务无关的下沉为底层框架,业务相关的封装为独立模块,这样整体的结构也就出来了。
“变量”与“常量”同样可以检验重构效果,比如模块间常常通过抽象出的协议进行通信,如果通信方法都是具体业务的,那每个同学都可能往里添加各自的方法,这个“变量”就会失去控制,难以维护。
设计方案
梳理问题的过程中,已经在不断的在思考什么样的方式可以解决问题,大致雏形已经有了,这部分更多的是将设计方案系统化。
思路
通过上述梳理功能发现 UI 设计和产品的规律:
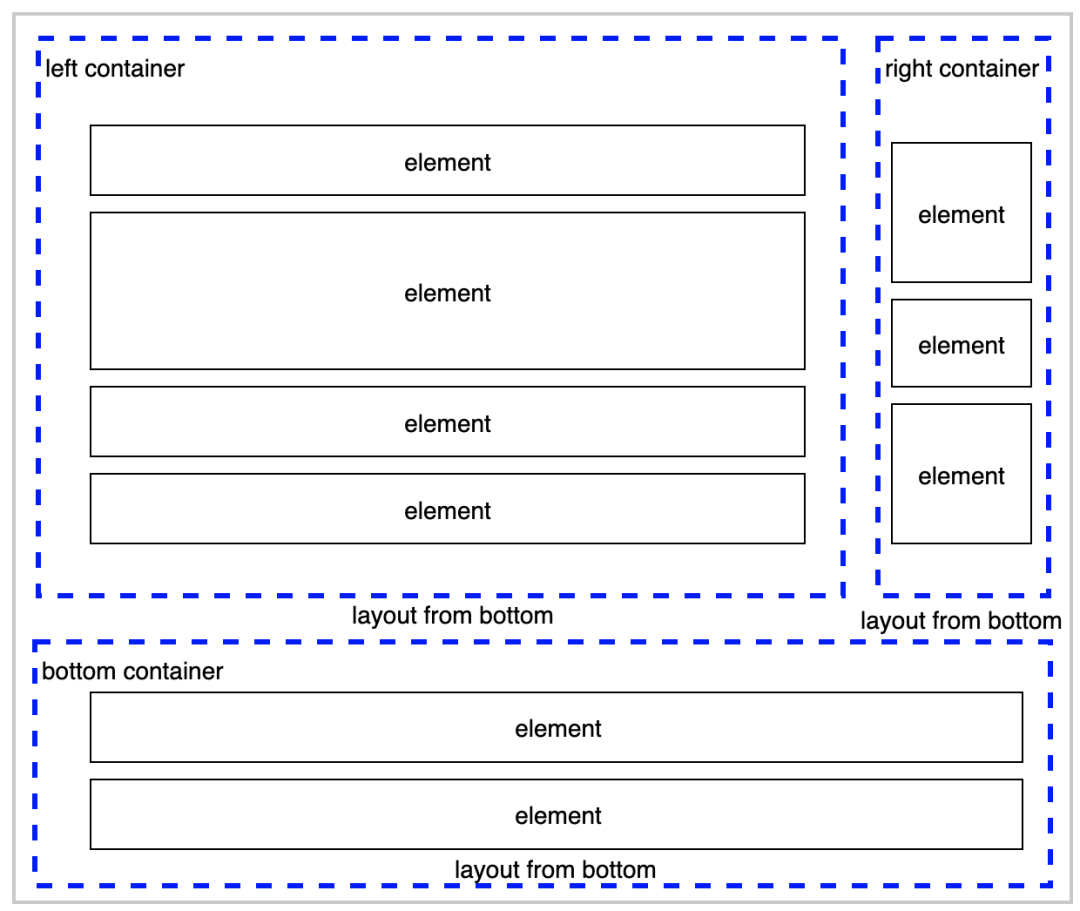
整体可分为 3 个区域,左侧、右侧、底部,每个子功能都可以归到 3 个区域中,按需显示,数据驱动
左侧区域中的作者名称、描述、音乐信息是自底向上挨个排列
右侧主要是按钮类型,头像、点赞、评论,排列方式和左侧规律相同
底部可能有个警告、热点,只显示 1 个或者不显示
为了统一概念,将 3 个区域定义为容器、容器中放置的子功能定义为元素,容器边界和能力可以放宽一些,支持弱类型实例化,这样就能支持物理隔离元素代码,形成一个可插拔的机制。
元素将 View、布局、业务逻辑代码都内聚在一起,元素和交互区、元素和元素之间不直接依赖,职责内聚,便于维护。
众多的接口可以抽象归类,大体可分为 UI 生命周期调用、播放器生命周期调用,将业务性的接口抽象,分发到具体的元素中处理逻辑。
架构设计
下图是期望达到的最终目标形态,实施过程会分为多步,确定最终形态,避免实施时偏离目标。
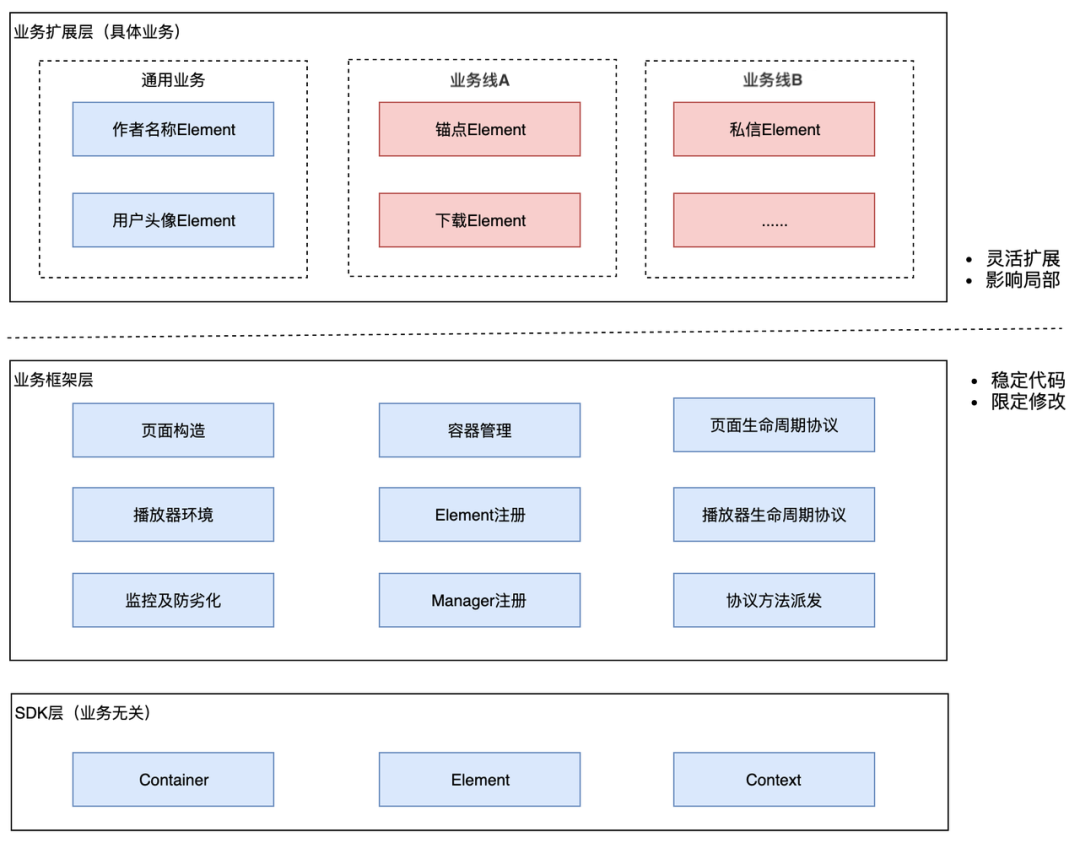
整体指导原则:简单、适用、可演化。
SDK 层:抽象出和业务完全无关的 SDK 层,SDK 负责管理 Element、Element 间通信
业务框架层:将通用业务、共性代码等低频率修改代码独立出来,形成框架层,这层代码是可由专人维护,业务线同学无法修改
业务扩展层:各业务线具体的子功能在此层实现,提供灵活的注册、插拔能力,Element 间无耦合,代码影响限定在 Element 内部
SDK 层
Container
所有的 Element 都通过 Container 来管理,包括 2 部分:
对 Element 的创建、持有
持有了一个 UIStackView,Element 创建的 View 都加入到此 UIStackView 中
使用 UIStackView 是为了实现自底向上的流式布局。
Element
子功能的 UI、逻辑、操作等所有代码封装的集合体,定义为 Element,借鉴了网页中的 Element 概念,对外的行为可抽象为:
View:最终显示的 View,lazy 的形式构造
布局:自适应撑开,Container 中的 UIStackView 可以支持
事件:通用的事件,处理 handler 即可,view 内部也可自行添加事件
更新:传入模型,内部根据模型内容,赋值到 view 中
View
View 在 BaseElement 中的定义如下:
@interface BaseElement : NSObject <BaseElementProtocol>@property (nonatomic, strong, nullable) UIView *view;@property (nonatomic, assign) BOOL appear;- (void)viewDidLoad;@endBaseElement 是抽象基类,公开 view 属性形式上看 view 属性、viewDidLoad 方法,和 UIViewController 使用方式的非常类似,设计意图是想靠向 UIViewController,以便让大家更快的接受和理解
appear 表示 element 是否显示,appear 为 YES 时,view 被自动创建,viewDidLoad 方法被调用,相关的子 view、布局等业务代码在 viewDidLoad 方法中复写,和 UIViewController 使用类似
appear 和 hidden 的区别在于,hidden 只是视觉看不到了,内存并没有释放掉,而低频次使用的 view 没必要常驻内存,因此 appear 为 NO 时,会移除 view 并释放内存
布局
UIStackView 的 axis 设置了 UILayoutConstraintAxisVertical,布局时自底向上的流式排列
容器内的元素自下向上布局,最底部的元素参照容器底部约束,依次布局,容器高度参照最上面的元素位置
元素内部自动撑开,可直接设置固定高度,也可以用 autolayout 撑开
事件
@protocol BaseElementProtocol <NSObject>@optional- (void)tapHandler:(UITapGestureRecognizer *)sender;@end实现协议方法,自动添加手势,支持点击事件
也可以自行添加事件,如按钮,使用原生的 addTarget 点击体验更好
更新
data 属性赋值,触发更新,通过 setter 形式实现。
@property (nonatomic, strong, nullable) id data;赋值时会调用 setData 方法。
- (void)setData:(id)data { _data = data; [self processAppear:self.appear];}数据流图
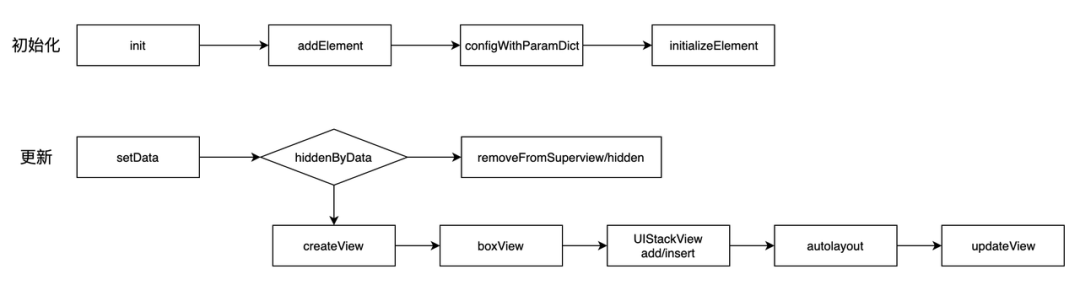
Element 的生命周期、更新时的数据流向示意图,这里就不细讲了。
动画特效
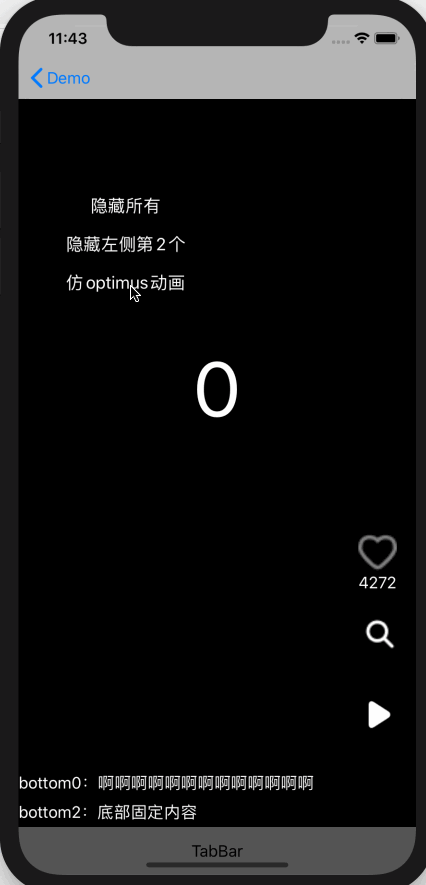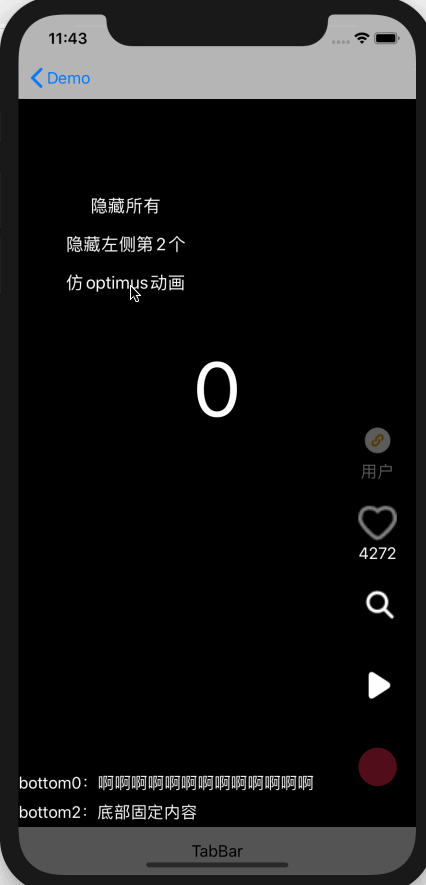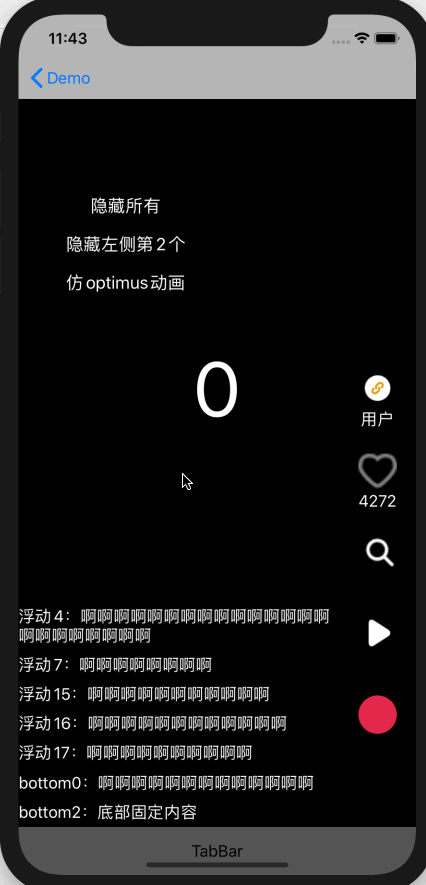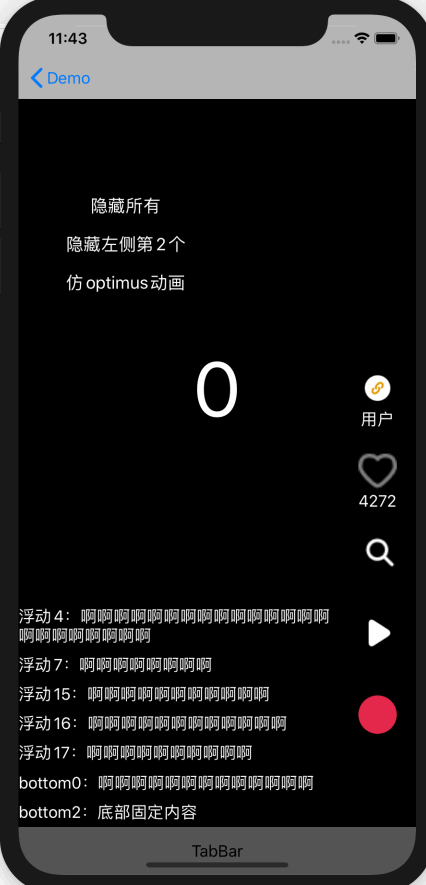
图中是实际需要支持的业务场景,目前是 ABTest 阶段,老代码实现方式主要问题:
对每处 view 都用 GET_AB_TEST_CASE(videoPlayerInteractionOptimization)判断处理了,代码中共有 32 处判断
每个 View 使用 Transform 动画隐藏
这个实现方式非常分散,加新 view 时很容易被遗漏,Element 支持更优的方式:
左侧所有子功能都在一个容器中,因此隐藏容器即可,不需要操作每个子功能
右侧单独隐藏头像、音乐单独处理即可

扩展性
Element 之间无依赖,可以做到每个 Element 物理隔离,代码放在各自的业务组件中,业务组件依赖交互区业务框架层即可,独立的 Element 通过 runtime 形式,使用注册的方式提供给交互区,框架会将字符串的类实例化,让其正常工作。
[self.container addElementByClassName:@"PlayInteractionAuthorElement"];[self.container addElementByClassName:@"PlayInteractionRateElement"];[self.container addElementByClassName:@"PlayInteractionDescriptionElement"];业务框架层
容器管理
SDK 中仅提供了容器的抽象定义和实现,在业务场景中,需要结合具体业务场景,进一步定义容器的范围和职责。
上面梳理了功能中将整个页面分为左侧、右侧、底部 3 个区域,那么这 3 个区域就是相应的容器,所有子功能都可以归到这 3 个容器中,如下图:
协议
Feed 是用 UITableView 实现,Cell 中除了交互区外只有播放器,因此所有的外部调用都可以抽象,如下图所示。
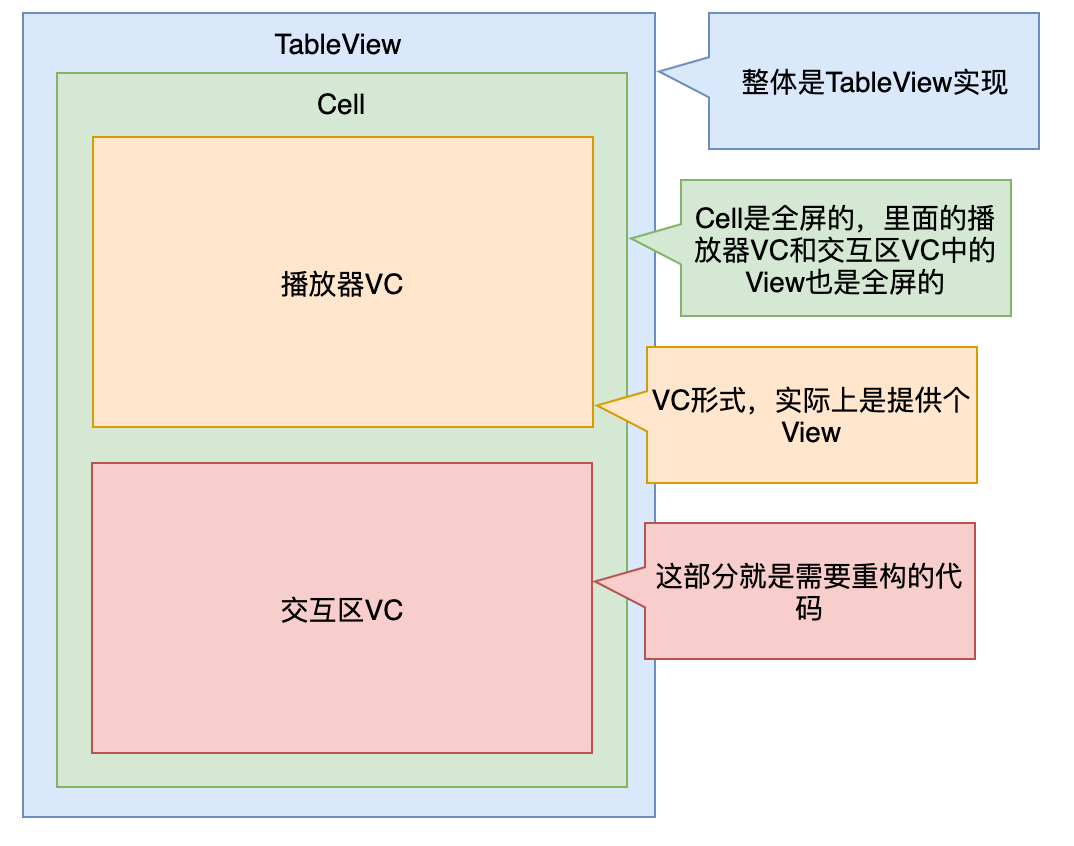
从概念上讲只需要 1 个交互区协议,但这里可以细分为 2 部分:
页面生命周期
播放器生命周期
所有 Element 都要实现这个协议,因此在 SDK 中的 Element 基类之上,继承实现了 PlayInteractionBaseElement,这样具体 Element 中不需要实现的方法可以不写。
@interface PlayInteractionBaseElement : BaseElement <PlayInteractionDispatcherProtocol>@end为了更清晰定义协议职责,用接口隔离的思想继续拆分,PlayInteractionDispatcherProtocol 作为统一的聚合协议。
@protocol PlayInteractionDispatcherProtocol <PlayInteractionCycleLifeDispatcherProtocol, PlayInteractionPlayerDispatcherProtocol>@end页面生命周期协议:PlayInteractionCycleLifeDispatcherProtocol
简单列了部分方法,这些方法都是 ViewController、TableView、Cell 对应的生命周期方法,是完全抽象的、和业务无关的,因此不会随着业务量的增加而膨胀。
@protocol PlayInteractionCycleLifeDispatcherProtocol <NSObject>- (void)willDisplay;- (void)setHide:(BOOL)flag;- (void)reset;@end播放器生命周期协议:PlayInteractionPlayerDispatcherProtocol
播放器的状态和方法,也是抽象的、和业务无关。
@protocol PlayInteractionPlayerDispatcherProtocol <NSObject>@property (nonatomic, assign) PlayInteractionPlayerStatus playerStatus;- (void)pause;- (void)resume;- (void)videoDidActivity;@endManager - 弹窗、蒙层
弹窗、蒙层的 view 规律并不在容器管理之中,所以需要一套额外的管理方式,这里定义了 Manager 概念,是一个相对抽象的概念,即可以实现弹窗、蒙层等功能,也可以实现 View 无关的功能,和 Element 同样,将代码拆分开。
@interface PlayInteractionBaseManager : NSObject <PlayInteractionDispatcherProtocol>- (UIView *)view;@endPlayInteractionBaseManager 同样实现了 PlayInteractionDispatcherProtocol 协议,因此具备了所有的交互区协议调用能力
Manager 不提供 View 的创建能力,这里的 view 是 UIViewController 的 view 引用,比如需要加蒙层,那么加到 manager 的 view 中就相当于加到 UIViewController 的 view 中
弹窗、蒙层通过此种方式实现,Manager 并不负责弹窗、蒙层间的互斥、优先级逻辑处理,需要单独的机制去做
方法派发
业务框架层中定义的协议,需要框架层调用,SDK 层是感知不到的,由于 Element、Manager 众多,需要一个机制来封装批量调用过程,如下图所示:
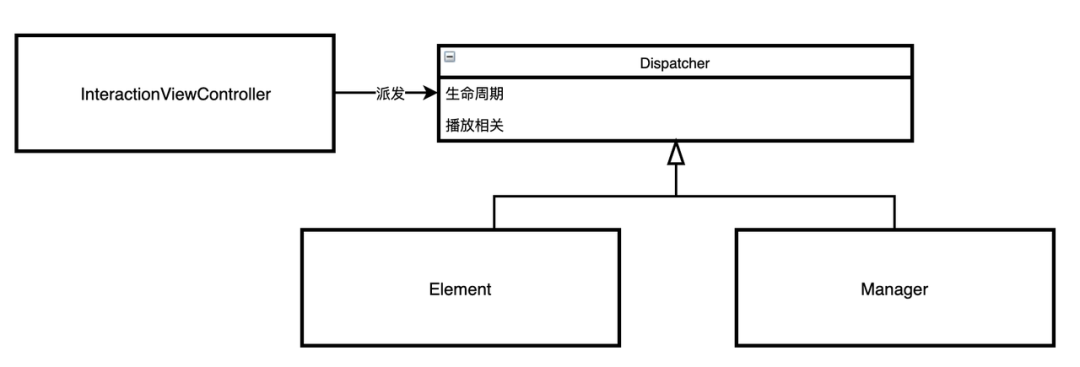
分层结构
旧交互区使用了 VIPER 范式,抖音里整体使用的 MVVM,多套范式会增加学习、维护成本,并且使用 Element 开发时,VIPER 层级过多,因此考虑统一为 MVVM。
VIPER 整体分层结构
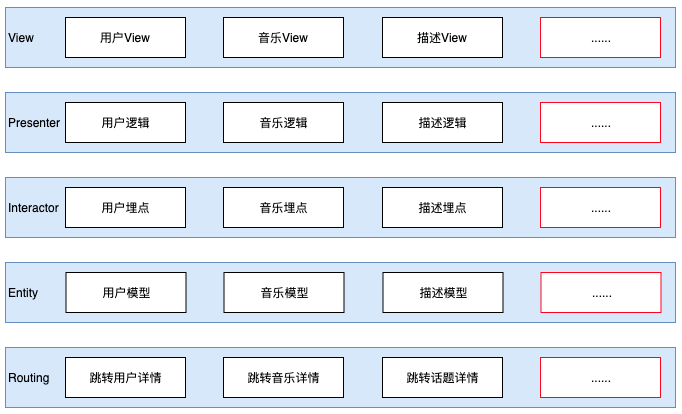
MVVM 整体分层结构
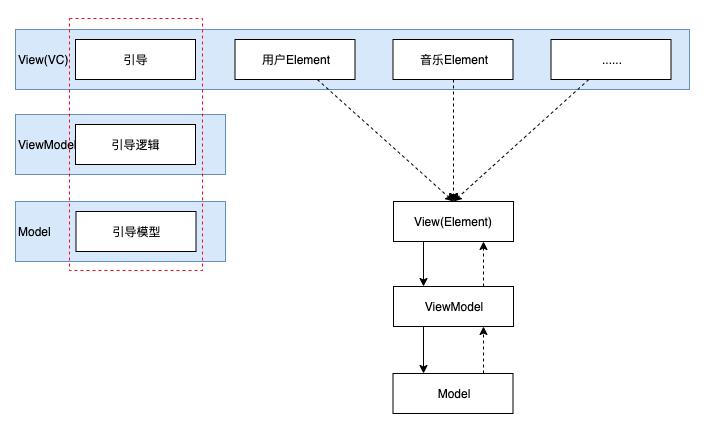
在 MVVM 结构中,Element 职责和 ViewController 概念很接近,也可以理解为更纯粹、更专用的的 ViewController。
经过 Element 拆分后,每个子功能已经内聚在一起,代码量是有限的,可以比较好的支撑业务开发。
Element 结合 MVVM 结构
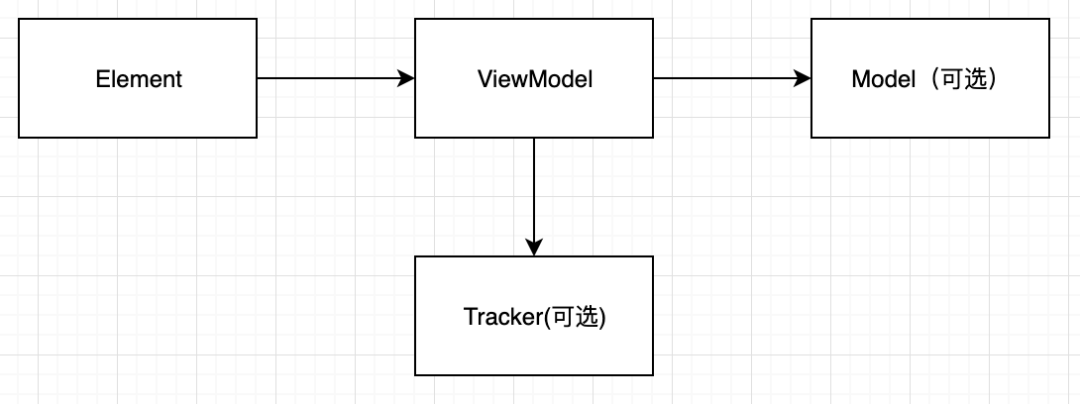
Element:如果是特别简单的元素,那么只提供 Element 的实现即可,Element 层负责基本的实现和跳转
ViewModel:部分元素逻辑比较复杂,需要将逻辑抽离出来,作为 ViewModel,对应目前的 Presentor 层
Tracker:埋点工具,埋点也可以写在 VM 中,对应目前的 Interactor
Model:绝大多数使用主 Model 即可
业务层
业务层中存放的是 Element 实现,主要有两种类型:
通用业务:如作者信息、描述、头像、点赞、评论等通用的功能
子业务线业务:十几条子业务线,不一一列举
通用业务 Element 和交互区代码放在一起,子业务线 Element 放在业务线中,代码物理隔离后,职责会更明确,但是这也带来一个问题,当框架调整时,需要改多个仓库,并且可能修改遗漏,所以重构初期可以先放一起,稳定后再迁出去。
过度设计误区
设计往往会走两个极端,没有设计、过度设计。
所谓没有设计是在现有的架构、模式下,没有额外思考过差异、特点,照搬使用。
过渡设计往往是在吃了没有设计的亏后,成了惊弓之鸟,看什么都要搞一堆配置、组合、扩展的设计,简单的反而搞复杂了,过犹不及。
设计是在质量、成本、时间等因素之间做出权衡的艺术。
实施方案
业务开发不能停,一边开发、一边重构,相当于在高速公路上不停车换轮胎,需要有足够的预案、备案,才能保证设计方案顺利落地。
改动评估
先估算一下修改规模、周期:
代码修改量:近 4 万行
时间:半年
改动巨大、时间很长,风险是难以控制的,每个版本都有大量业务需求,需要改大量的代码,在重构的同时,如果重构的代码和新需求代码冲突,是非常难解的,因此考虑分期。
上面已经多次说到功能的重要性,需要考虑重构后,功能是否正常,如果出了问题如何处理、如何证明重构后的功能和之前是一致的,对产品数据无影响。
实施策略
基本思路是实现一个新页面,通过 ABTest 来切换,核心指标无明显负向则放量,全量后删除旧代码,示意图如下:
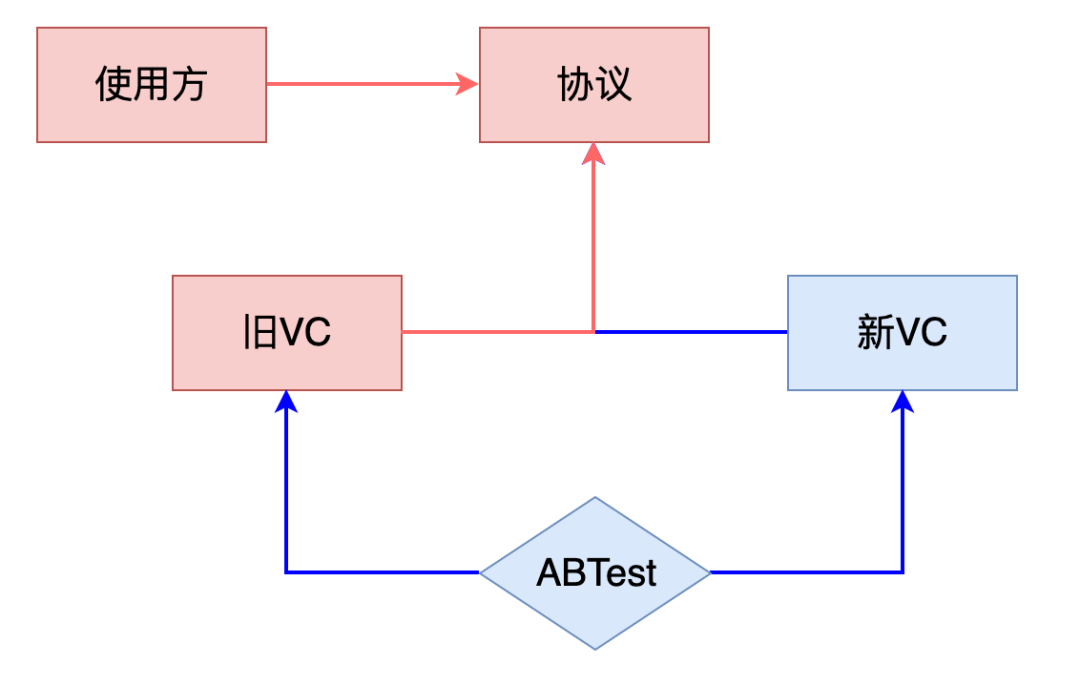
共分为三期:
一期改造内容如上图红色所示:抽取协议,面向协议编程,不依赖具体类,改造旧 VC,实现协议,将协议之外暴露的方法、属性收敛到内部
二期改造内容如蓝色所示:新建个新 VC,新 VC 和旧 VC 在功能上是完全一致,实现协议,通过 ABTest 来控制使用方拿到的是旧 VC 还是新 VC
三期内容:删掉旧 VC、ABTest,协议、新 VC 保留,完成替换工作

其中二期是重点,占用时间最多,此阶段需要同时维护新旧两套页面,开发、测试工作量翻倍,因此要尽可能的缩短二期时间,不要着急改代码,可以将一期做完善了、各方面的设计准备好再开始。
ABTest
2 个目的:
利用 ABTest 作为开关,可以灵活的切换新旧页面
用数据证明新旧页面是一致的,从业务功能上来说,二者完全一致,但实际情况是否符合预期,需要用留存、播放、渗透率等核心指标证明
两套页面的开发方式
在二期中,两套页面 ABTest 切换方式是有成本的,需求开发两套、测试两遍,虽然部分代码可共用,但成本还是大大增加,因此需要将这个阶段尽可能缩短。
另外开发、测试两套,不容易发现问题,而一旦出问题,即便能用 ABTest 灵活切换,但修复问题、重新上线、ABTest 数据有结论,也需要非常长的周期。
如果每个版本都出问题,那将会是上线、发现问题,重新修复再上线,又发现了新问题,无限循环,可能一直无法全量。
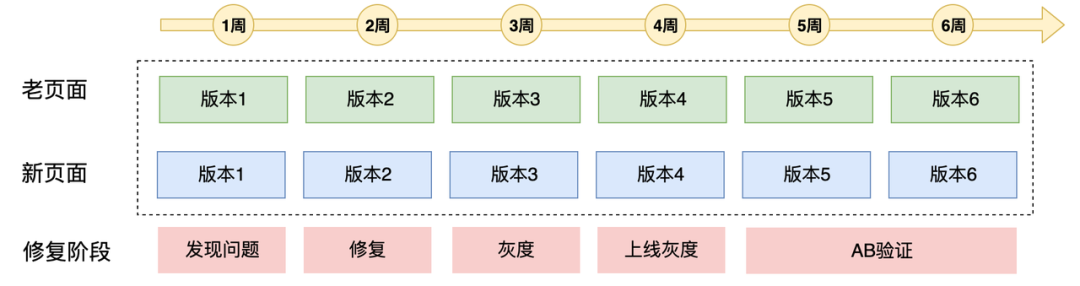
如上图所示,版本单周迭代,发现问题跟下周修复,那么需要经过灰度、上线灰度(AppStore 的灰度放量)、ABTest 验证(AB 数据稳定要 2 周),总计要 6 周的时间。
让每个同学理解整体运作机制、成本,有助于统一目标,缩短此阶段周期。
删掉旧代码
架构设计上准备充足,删掉旧代码非常简单,删掉旧文件、ABTest 即可,事实上也是如此,1 天内就完成了。
代码后入后,有些长尾的事情会持续 2、3 个版本,例如有些分支,已经修改了删掉的代码,因为文件已经不存在了,只要修改,必定会冲突,合之前,需要 git merge 一下源分支,将有冲突的老页面再删掉。
防崩溃兜底
面向协议开发两套页面,如果增加一个功能时,新页面遗漏了某个方法的话,期望可以不崩溃。利用 Objective-C 语言消息转发可以实现这特性,在 forwardingTargetForSelector 方法中判断方法是否存在,如果不存在,添加一个兜底方法即可,用来处理即可。
- (id)forwardingTargetForSelector:(SEL)aSelector { Class clazz = NSClassFromString(@"TestObject"); if (![self isExistSelector:aSelector inClass:clazz]) { class_addMethod(clazz, aSelector, [self safeImplementation:aSelector], [NSStringFromSelector(aSelector) UTF8String]); } Class Protector = [clazz class]; id instance = [[Protector alloc] init]; return instance;}- (BOOL)isExistSelector:(SEL)aSelector inClass:(Class)clazz { BOOL isExist = NO; unsigned int methodCount = 0; Method *methods = class_copyMethodList(clazz, &methodCount); NSString *aSelectorName = NSStringFromSelector(aSelector); for (int i = 0; i < methodCount; i++) { Method method = methods[i]; SEL selector = method_getName(method); NSString *selectorName = NSStringFromSelector(selector); if ([selectorName isEqualToString: aSelectorName]) { isExist = YES; break; } } return isExist;}- (IMP)safeImplementation:(SEL)aSelector { IMP imp = imp_implementationWithBlock(^(){ // log }); return imp;}线上兜底降低影响范围,内测提示尽早发现,在开发、内测阶段时可以用比较强的交互手段提示,如 toast、弹窗等,另外可以接打点上报统计。
防劣化
需要明确的规则、机制防劣化,并持续投入精力维护。
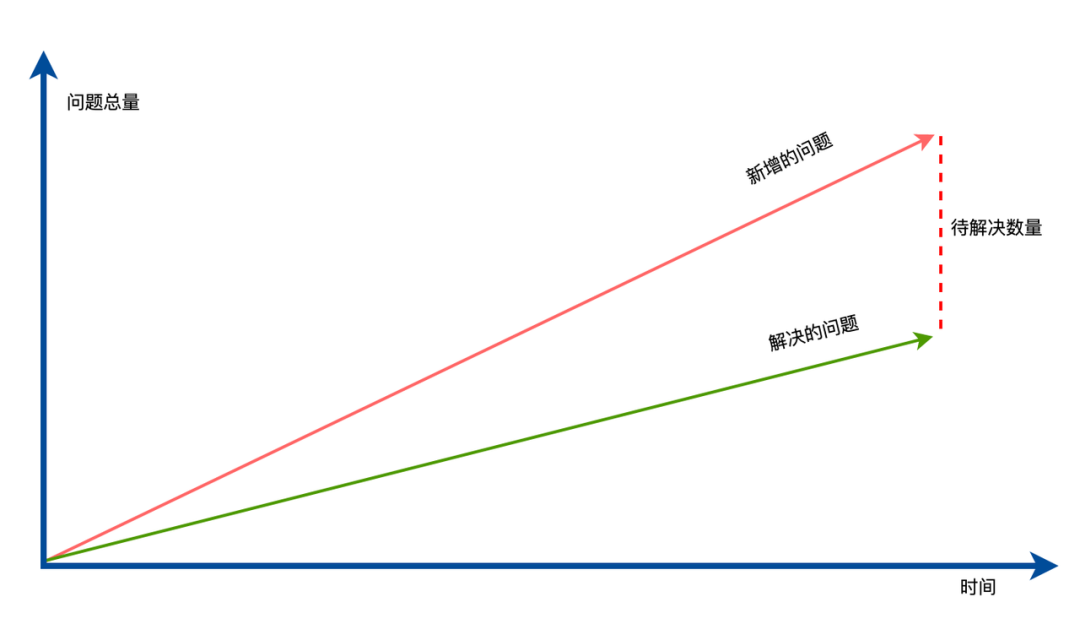
不是每个人都能理解设计意图,不同职责的代码放在应该放的位置,比如业务无关的代码,应该下沉到框架层,降低被破坏的概率,紧密的开发节奏,即便简单的 if else 也容易写出问题,例如再加 1 个条件,几乎都会再写 1 个 if,直至写了几十个后,发现写不下去了,再推倒重构,期望重构一次后,可以保持得尽可能久一些。
更严重的是在重构过程中,代码就可能劣化,如果问题出现的速度超过解决的速度,那么将会一直疲于救火,永远无法彻底解决。
新方案中,业务逻辑都放在了 Element 中,ViewController、容器中剩下通用的代码,这部分代码业务同学是没必要去修改,不理解整体也容易改出问题,因此这部分代码由专人来维护,各业务同学有需要改框架层代码的需求,专人来修改。
各 Element 按照业务线划分为独立文件,自己维护的文件可以加 reviewer 或文件变更通知,也可以迁到业务仓库中,进行物理隔离。
日志 & 问题排查
稳定复现的问题,比较容易排查和解决,但概率性的问题,尤其是 iOS 系统问题引起的概率性问题,比较难排查,即便猜测可能引起问题的原因,修改后,也难以自测验证,只能上线再观察。
关键信息提前加日志记录,如用户反馈某个视频有问题,那么需要根据日志,找到相应的 model、Element、View、布局、约束等信息。
信息同步
改动过广,需要及时周知业务线的开发、测试、产品同学,几个方式:
拉群通知
周会、周报
开发同学最关注的点是什么时候放量、什么时候全量、什么时候可以删掉老代码,不用维护 2 套代码。
其次是改动,框架在不够稳定时,是需要经常改的,如果改动,需要相应受影响的功能的维护同学验证,以及确认测试是否介入。
产品同学也要周知,虽然产品不关注怎么做,但是一旦出问题,没有周知,很麻烦。
保证质量
最重要的是及时发现问题,这是避免或者减少影响的前提条件。
常规的 RD 自测、QA 功能测试、集成测试等是必备的,这里不多说,主要探讨其他哪些手段可以更加及时的发现问题。
新开发的需求,需要开发新、老页面两套代码,同样,也要测试两次,虽然多次强调,但涉及到多个业务线、跨团队、跨职责、时间线长,很容易遗漏,而新页面 ABTest 放量很小,一旦出问题,很难被发现,因此对线上和测试用户区分处理:
线上、线下流量策略:线上 AppStore 渠道 ABTest 按数据分析师设计放量;内测、灰度等线下渠道放量 50%,新旧两套各占一半,内测、灰度人员还是有一定规模的,如果是明显的问题,比较容易发现的
ABTest 产品指标对照:灰度、线上数据都是有参考价值的,按照 ABTest 数据量,粗评一下是否有问题,如果有明显问题,可及时深入排查
Slardar ABTest 技术指标对照:最常用的是 crash 率,对比对照组和实验组的 crash 率,看下是否有新 crash,实验组放量比较小,单独的看 crash 数量是很难发现的,也容易忽略。另外还要别的技术指标,也可以关注下
Slardar 技术打点告警配置:重构周期比较长,难以做到每天都盯着,关键位置加入技术打点,系统中配置告警,设置好条件,这样在出现问题时,会及时通知你
单元测试:单测是保证重构的必要手段,在框架、SDK 等核心代码,都加入了单测
UI 自动化测试:如果有完整的验证用例,可以一定程度上帮助发现问题
排查问题
稳定复现的问题比较容易定位解决,两类问题比较头疼,详细讲一下:
ABTest 指标负向
概率性出现的问题
ABTest 指标负向
ABTest 核心指标负向,是无法放量的,甚至要关掉实验排查问题。
有个分享例子,分享总量、人均分享量都明显负向,大体经过这样几个排查过程:

排查 ABTest 指标和排查 bug 类似,都是找到差异,缩小范围,最终定位代码。
对比功能:从用户使用角度找差异,交互设计师、测试、开发自测都没有发现有差异
对比代码:对比新老两套打点代码逻辑,尤其是进入打点的条件逻辑,没有发现差异
拆分指标:很多功能都可以分享,打点平台可以按分享页面来源拆分指标,发现长按弹出面板中的分享减少,其他来源相差不大,进一步排查弹出面板出现的概率发现明显变低了,大体定位问题范围。另外值得一提的是,不喜欢不是很核心的指标,并且不喜欢变少,意味着视频质量更高,所以这点是从 ABTest 数据中难以发现的
定位代码:排查面板出现条件发现,老代码中是在长按手势中,排除了个别的点赞、评论等按钮,其他位置(如果没有添加事件)都是可点的,比如点赞、评论按钮之间的空白位置,而新代码中是将右侧按钮区域、底部统一排除了,这样空白区域就不能点了,点击区域变小了,因此出现概率变小了
解决问题:定位问题后,修复比较简单,还原了旧代码实现方式
这个问题能思考的点是比较多的,重构时,看到了不好的代码,到底要不要改?
比如上面的问题,增加了功能后,不知道是否应该排除点击,很容易被忽略,长按属于底层逻辑,具体按钮属于业务细节,底层逻辑依赖了细节是不好的,可维护性很差,但是修改后,很可能影响交互体验和产品指标,尤其是核心指标,一旦影响,没有太多探讨空间。
具体情况具体评估,如果预估到影响了功能、交互,尽量不要改,大重构尽可能先解决核心问题,局部问题可以后续单独解决。
下面是长按面板中的分享数据截图,明显降低,其他来源基本保持一致,就不贴图了。
长按蒙层出现率降低 10%左右,比较自然的猜测蒙层出现率降低。
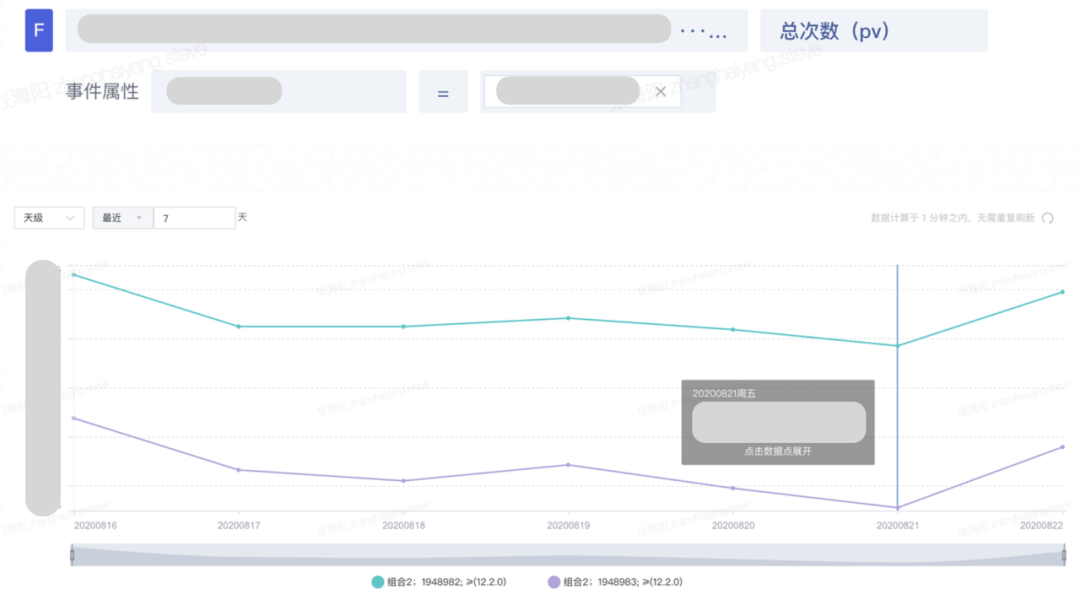
对比 View 视图差异确认问题。

类似的问题很多,ABTest 放量、全量过程要有充足的估时和耐心,这个过程会大大超过预期。抖音核心指标几乎都和交互区相关,众多分析师和产品都要关注,因此先理解一下分析师、产品和开发同学对 ABTest 指标负向的认知差别。
大部分指标是正向,个别指标负向,那么会被判断为负向。
开发同学可能想的是设计的合理性、代码的合理性,或者从整体的收益、损失角度的差值考虑,但分析师会优先考虑不出问题、别有隐患。两种方式是站在不同角度、目标考虑的,没有对错之分,事实上分析师帮忙发现了非常多的问题。目前的分析师、产品众多,每个指标都有分析师、产品负责,如果某个核心指标明显负向,找相应的分析师、产品讨论,是非常难达成一致的,即使是先放量再排查的方案也很难接受,建议自己学会看指标,尽早跟进,关键时找人帮忙推进。
概率性出现的问题
概率性出现的问题难点在于,很难复现,无法调试定位问题,修改后无法测试验证,需要上线后才能确定是否修复,举一个实际的例子的 iOS9 上 crash 例子,发现过程:
通过 slardar=>AB 实验=>指定实验=>监控类型=>崩溃 发现的,可以看到实验组和对照组的 crash 率,其他的 OOM 等指标也可以用这个功能查看
下面是 crash 的堆栈,crash 率比较高,大约 50%的 iOS 9 的用户会出现:
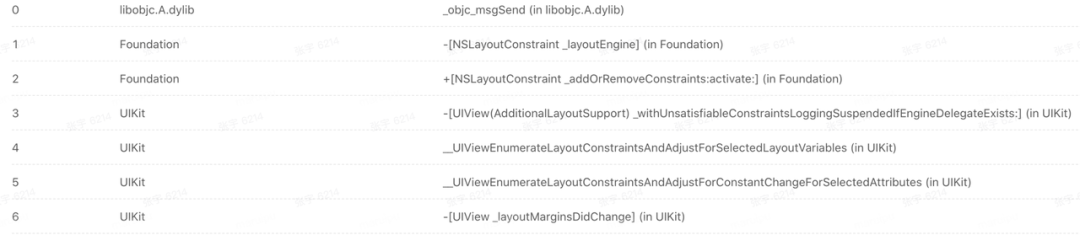
crash 堆栈在系统库中,无法看到源码,堆栈中也无法找到相关的问题代码,无法定位问题 ,整个解决过程比较长,尝试用过的方式,供大家参考:
手动复现,尝试修改,可以复现,但刷一天也复现不了几次,效率太低,对部分问题来说,判断准的话,可以比较快的解决
swizzle 系统崩溃的方法,日志记录最后崩溃的 View、相关 View 的层次结构,缩小排查范围
自动化测试复现,可以用来验证是否修复问题,无法定位问题
逆向看 UIKit 系统实现,分析崩溃原因
逆向大体过程:
下载 iOS9 Xcode & 模拟器文件
提取 UIKit 动态库
分析 crash 堆栈,通过 crash 最后所在的_layoutEngine、_addOrRemoveConstraints、_withUnsatisfiableConstraintsLoggingSuspendedIfEngineDelegateExists 3 个关键方法,找到调用路径,如下图所示:
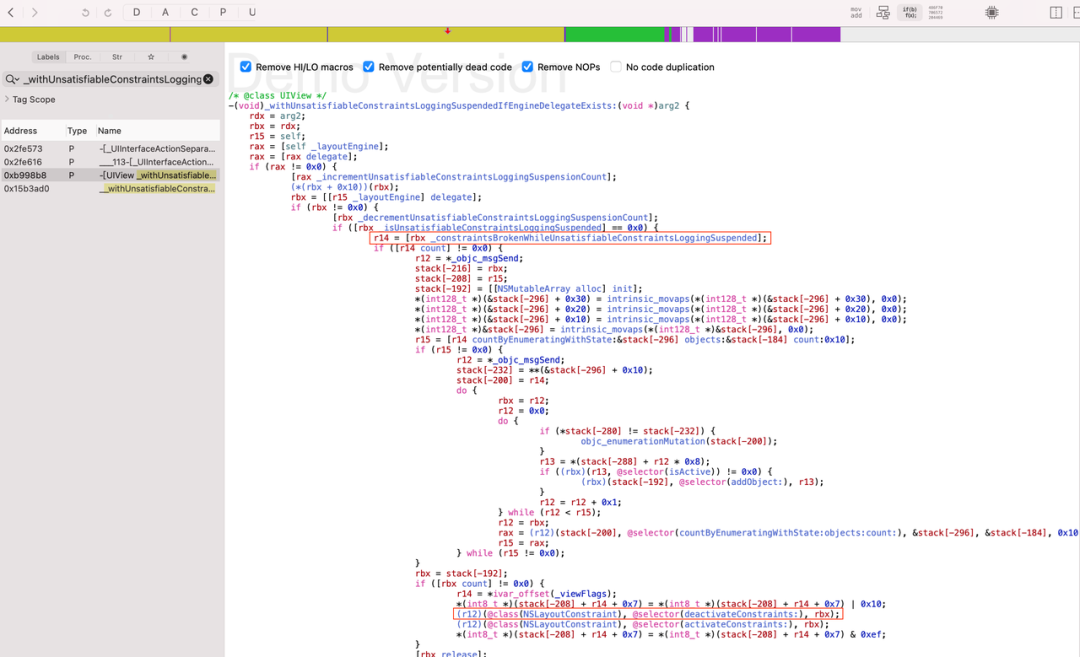
_withUnsatisfiableConstraintsLoggingSuspendedIfEngineDelegateExists 中调用了 deactivateConstraints 方法,deactivateConstraints 中又调用了_addOrRemoveConstraints 方法,和 crash 堆栈中第 3 行匹配,那么问题就出在此处,为方便排查,逆向出相关方法的具体实现,大体如下:
@implementation UIView- (void)_withUnsatisfiableConstraintsLoggingSuspendedIfEngineDelegateExists:(Block)action { id engine = [self _layoutEngine]; id delegate = [engine delegate]; BOOL suspended = [delegate _isUnsatisfiableConstraintsLoggingSuspended]; [delegate _setUnsatisfiableConstraintsLoggingSuspended:YES]; action(); [delegate _setUnsatisfiableConstraintsLoggingSuspended:suspended]; if (suspended == YES) { return; } NSArray *constraints = [self _constraintsBrokenWhileUnsatisfiableConstraintsLoggingSuspended]; if (constraints.count != 0) { NSMutableArray *array = [[NSMutableArray alloc] init]; for (NSLayoutConstraint *_cons : constraints) { if ([_cons isActive]) { [array addObject:_cons]; } } if (array.count != 0) { [NSLayoutConstraint deactivateConstraints:array]; // NSLayoutConstraint 入口 [NSLayoutConstraint activateConstraints:array]; } } objc_setAssociatedObject( self, @selector(_constraintsBrokenWhileUnsatisfiableConstraintsLoggingSuspended), nil, OBJC_ASSOCIATION_RETAIN_NONATOMIC);}@end@implementation NSLayoutConstraint+ (void)activateConstraints:(NSArray *)_array { [self _addOrRemoveConstraints:_array activate:YES]; // crash堆栈中倒数第3个调用}+ (void)deactivateConstraints:(NSArray *)_array { [self _addOrRemoveConstraints:_array activate:NO];}@end从代码逻辑和_constraintsBrokenWhileUnsatisfiableConstraintsLoggingSuspended 方法的命名语义上看,此处代码主要是用来处理无法满足约束日志的,应该不会影响功能逻辑
另外,分析时如果无法准确判断 crash 位置,则需要逆向真机文件,相比模拟器,真机的堆栈是准确的,通过原始 crash 堆栈偏移量找到最后的代码调用
拿到结果
开发效率:将之前 VIPER 结构的 5 个文件,拆分了大约 50 个文件,每个功能的职责都在业务线内部,添加、修改不再需要看所有的代码了,调研问卷显示开发效率提升在 20%以上
开发质量:从 bug、线上故障来看,新页面问题是比较少的,而且出问题一般的都是框架的问题,修复后是可以避免批量的问题的
产品收益:虽然功能一致,但因为重构设计的性能是有改进的,核心指标正向收益明显,实验开启多次,核心指标结论一致
勇气
最后这部分是思考良久后加上的,重构本身就是开发的一部分,再正常不过,但重构总是难以进行,有的浅尝辄止,甚至半途而废。公司严格的招聘下,能进来的都是聪明人,不缺少解决问题的智慧,缺少的是勇气,回顾这次重构和上面提到过的“曾经尝试过的方式”,也正是如此。
代码难以维护时是比较容易发现的,优化、重构的想法也很自然,但是有两点让重构无法有效开展:
什么时候开始
局部重构试试
在讨论什么时候开始前,可以先看个词,工作中有个流行词叫 ROI,大意是投入和收益比率,投入越少、收益越高越好,最好是空手套白狼,这个词指导了很多决策。
重构无疑是个费力的事情,需要投入非常大的心力、时间,而能看到的直接收益不明显,一旦改出问题,还要承担风险,重构也很难获得其他人认可,比如在产品看来,功能完全没变,代码还能跑,为什么要现在重构,新需求还等着开发呢,有问题的代码就是这样不断的拖着,越来越严重。
诚然,有足够的痛点时重构是收益最高的,但只是看起来,真实的收益是不变的,在这之前需要大量额外的维护成本,以及劣化后的重构成本,从长期收益看,既然要改就趁早改。决定要做比较难,说服大家更难,每个人的理解可能都不一样,对长期收益的判断也不一样,很难达成一致。

思者众、行者寡,未知的事情大家偏向谨慎,支持继续前行的是对技术追求的勇气。
重构最好的时间就是当下。
局部重构,积少成多,最终整体完成,即便出问题,影响也是局部的,这是自下向上的方式,本身是没问题的,也经常使用,与之对应的是自上向下的整体重构,这里想强调的是,局部重构、整体重构只是手段,选择什么手段要看解决什么问题,如果根本问题是整体结构、架构的问题,局部重构是无法解决的。
比如这次重构时,非常多的人都提出,能否改动小一点、谨慎一点,但是设计方案是经过分析梳理的,已经明确是结构性问题,局部重构是无法解决的,曾经那些尝试过的方式也证明了这一点。
不能因为怕扯到蛋而忘记奔跑。
本文转载自:字节跳动技术团队(ID:BytedanceTechBlog)




