IPython Notebook 是一套基于 Web 的交互环境,允许大家将代码、代码执行、数学函数、富文档、绘图以及其它元素整合为单一文件。从后端层面看,IPython Notebook 会将此类信息保存为一个 JSON 文件。
相较于传统 REPL 或者传统写入 / 上传 / 测试任务流程,Notebook 的突出优势在于允许大家将交互式内容与图片及绘图相结合。在数据分析类任务领域,Notebook 能够出色地完成探索性测绘工作、快速筹备原型方案并将其与同事进行分享。而这也正是 IPython 的闪光点所在:当大家分享 Notebook 内容时,我们可以通过有组织的方式提供相关背景,并允许同事们就此进行效果体验。IPython 官方网站上提供了丰富的说明文档与示例资料,旨在帮助大家快速上手 IPython。而在将 Notebook 运行在 Amazon EMR 上时,我们则能够通过运行 Hadoop 任务并将结果绘制成视图的方式快速实现数据集分析。
在今天的博文中,我们将共同了解如何启动一套运行有 IPython Notebook 的 EMR 集群,通过自己的浏览器与目标 Notebook 相对接、利用 Hadoop Straming 进行分析并以图形化方式显示分析结果。通过 EMR bootstrap 操作,我们能够将 IPython Notebook 以及关联性安装在主节点之上,并同时获得用于实现基础性科学计算的工具包。
大家可以利用以下命令启动一套 EMR 集群:
aws emr create-cluster --name iPythonNotebookEMR \ --ami-version 3.2.3
--instance-type m3.xlarge --instance-count 3 \ --ec2-attributes
KeyName=<> \ --bootstrap-actions
Path=s3://elasticmapreduce.bootstrapactions/ipython-notebook/install-
ipython-notebook,Name=Install_iPython_NB \ --termination-protected
大家也可以使用 EMR 控制台并选定以下 bootstrap 操作:
s3://elasticmapreduce.bootstrapactions/ipython-notebook/install-ipython-notebook
在集群开始运行之后,Notebook 服务器将运行在端口 8192 上。我们可以通过打开由本地设备到目标 EMR 主节点间通道的方式实现接入。以下示例介绍了如何打开一条通往主节点的通道:
ssh -o ServerAliveInterval=10 -i <<credentials.pem>> -N -L
8192:<<master-public-dns-name>>:8192 hadoop@<<master-
public-dns-name>>
顺利打开通道之后,开启我们的浏览器并通过以下 URL 访问该 Notebook:
现在页面已经顺利开启,接下来选择New Notebook。
下载字数统计代码
首先,大家需要将字数统计代码下载到自己的设备上。我们可以使用与 IPython 功能相契合的 wget 命令运行 shell 命令行,命令开头需要以!作为前缀:
!wget https://elasticmapreduce.s3.amazonaws.com/samples/wordcount/wordSplitter.py
在字数统计代码下载完成后,大家可以将对待其它 Hadoop 任务一样将其付诸执行。该程序的输入结果读取自 Amazon S3,而输出结果则写入至 HDFS。
运行 MapReduce 程序
!hadoop jar /home/hadoop/contrib/streaming/hadoop-*streaming*.jar
-files wordSplitter.py -mapper wordSplitter.py -reducer aggregate -input
s3://elasticmapreduce/samples/wordcount/input -output /output
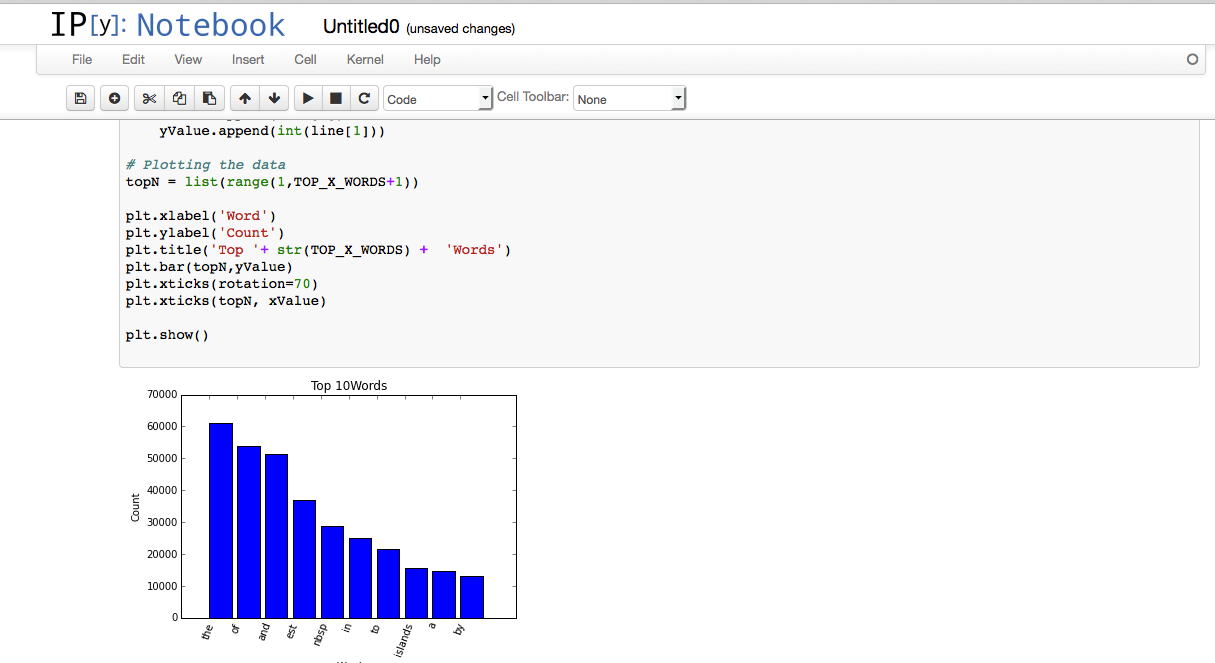
在该 Hadoop 任务运行完毕后,大家可以在 EMR 集群上的本地 HDFS 中检查输出文件内容。接下来,我们要做的是利用该结果绘制出一份条状图。大家可以点击此处从AWS 大数据博客GitHub 库中下载示例代码。(请记住,如果大家打算复制并粘贴这部分代码,请预留足够的空间!)
以下截图所示为运行示例代码后的显示结果。
清理
在体验过了IPython Notebook 的使用流程之后,大家可以通过控制台或者AWS 命令行关闭自己的集群,以免其闲置带来额外使用成本。
总结
在今天的文章中,大家了解了如何启动一套运行有IPython Notebook 的EMR 集群、通过浏览器接入Notebook、使用Hadoop Streaming 实现数据分析外加以图形化方式显示分析结果。现在大家可以利用IPython 的强大能力组织自己的代码并加以分享,这样其他人就能轻松了解我们项目的背景信息与实验效果了。
如果您有任何问题或者建议,请在评论栏中与我们交流。




