
本文讲述了作者在去年的数据科学学习之旅中遇到了一些困难,以及如何解决这些难题的。
Eric Weber(没错,就是那个养着一条可爱小狗的帅哥)最近在 LinkedIn 上发表了一篇文章,讲了十件他希望开始数据科学职业时能少做的事情。本文就是我对这十件事所经历的过程。你应该先读读他的文章。下面是截图。
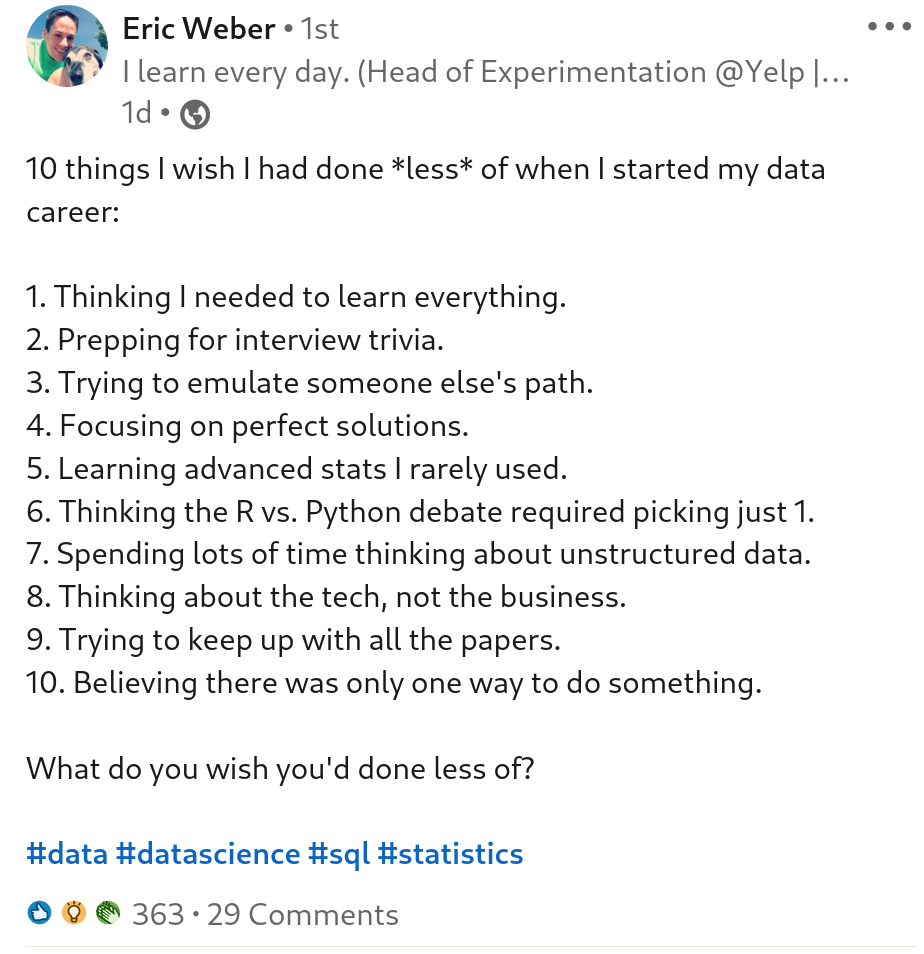
首先,这不会是一篇“内容”的文章。
关于这方面的文章和博客文章已经很多了,大家可以去找找。在本文中,我们将讨论当你渴望成为数据科学家并获得业界关注时,你关注的重点和方向。
1、认为自己什么都要学
是的,这会耗费你大量的时间和精力。你应该立即处理这一障碍。起初我很纠结,但几个月后,就渐渐平静下来。这次突破要归功于我每天阅读的习惯。
我一直在阅读 LinkedIn 的文章(尤其是 Eric Weber 本人的文章)。此外,我每天还会花一两个小时甚至更多时间阅读 Towards Data Science、Medium、KDnuggets 以及来自不同数据科学家和机器学习工程师的个人博客。我由此了解到数据科学在工业工作中的重要性:**你的技术组合能为企业带来多大价值。你将你的技能添加到组织中的价值。你通过构建你感兴趣的内容或构建问题解决方案来定义价值。**在回答问题的过程中,你选择要学什么,这将使你知道什么应该学,什么不应该学。
过了好几个月,我才意识到这一点 (我想大概是半年)。我会把这几个月的时间加起 来,一件一件地做,看看我们能省下多少时间。
2、为面试琐事做准备
没错,这是另一场斗争,原因有几个:
没有一个公认的定义来界定什么是数据科学家。除了一个模糊的概念之外,他的工作职责与数据分析师或机器学习工程师的职责有什么区别?
还有混乱的岗位描述。因为数据科学家没有一个约定俗成的定义,所以你会看到描述中期望你什么都会:机器学习、软件工程、Python、R、多年的统计学、微积分、线性代数、大〇符号什么的。看看这些职位的说明,你会感觉到你需要超过 50 年的工作经历。
别上当。别太在意职位的描述。大部分“面试琐事”是数据科学新鲜感与组织人才获取、数据科学与软件工程团队之间缺乏沟通渠道的结合。集中精力研究如何解决问题,而不是对此感到无所适从。
解决这个难题的一个办法就是审视现实。如果你认识任何现实生活中的数据科学家、数据分析师和机器学习工程师(在线下,在物理世界中),那么和他们谈谈他们的工作就是个不错的主意。假如你谁也不认识,你可以随时查看博客和文章。
我在线下不认识这方面的专业人士。因此,我就通过阅读博客和文章来学习。据我所知,公司会找很多人来面试,他们都是那种“知道”事情的人,但是很少有人 “做过”事情。因此,与单纯的学习和教育相比,重点放在做过事情上(例如部署和生产是两件大事)。我花了五六个月的时间才意识到这一点。
到目前为止,6 + 6 = 12 个月。
3、试图效仿别人的路子
啊哈,这是我的最爱😊因为我把大部分时间都浪费在这里:
Tetiana Ivanova在 6 个月内找到了一份工作。
Kelly Peng辞去数据分析师工作一年之后,她找到了工作。
Natassha Selvaraj找到了一份工作,她正在大学里读书。
Mikko Koskinen甚至没有打算成为一名数据科学家。
Thomas Hepner在Titanic 数据集之外的任何事情上都感到迷茫,一年后,他成为了这个行业的数据科学家。
请看我的简介,我在软件开发(C 语言)方面已有 4 年半的经验,现已从事数据科学八个月,但仍然无法回答这个问题:
你最喜欢的机器学习算法是什么,为什么?
是的,我同意我的情况看起来就是最糟糕的大〇符号的情况。O(n^n)
我已经阅读了数百篇(不,我没有夸大其词)的博文和文章,这些人都在数据科学领域找到了工作,并改变了行业。在我的生活中,我追寻并仿效他们的数据科学历程,从他们的思考方式到他们的课程选择,甚至在某些书某些特定章节上,他们的选择就像是完美的复本。但我仍然无法回答以上问题,因为我甚至不知道为什么我会喜欢一个机器学习算法,而不喜欢另一个。最终,我只是在“变得和他们一样”的名义下,无脑地咀嚼着所有模型。
我两天前就放弃了,决定照我认为应该做的做。(没想到,今天我看到了 Eric 的帖子。这就像是宇宙想要告诉我,我正在正确的道路上前进,这是我的路。)
我们每一个人都会有一个个性化的旅程。我们的环境、我们的天赋、我们的经验、我们的态度、我们的工作态度、我们的背景、我们的学习能力等各不相同,它们各有特点,各有千秋。正因如此,寻找他人之路可能永远不会成功。
因此,我决定,我要尝试一下,走自己的路,做一个数据科学家。我并非要停止阅读别人的过程,而是要继续阅读,但我不会盲目地追随他们,并试图将他们复制到我的生活中,而是要以他们为指南针,作为引导机制。那使我浪费了八个月。尽管如此,迟到总比不来强。
6 + 6 + 8 = 20 个月
4、专注于完美的解决方案
我的计算机编程经验解决了这个问题。在这个行业里,我花了五年的时间编写程序,写程序为我的雇主创造收入,这使我明白到**“完成”比“完美”更好**。事实上,找出其他人所面临的问题,并建立一个解决方案才是最重要的。简单地学习和教育不是办法。
6 + 6 + 8 + 0 = 20 个月。
5、学习我很少使用的高级统计数据
早在 2018 年,我花了很多时间学习数据科学的数学和统计学。学习花了我四个月的时间。
可汗学院的代数 I 和 II。
edX 上的亚利桑那州立大学的大学代数和问题解决课程。
YouTube上的麻省理工学院大图微积分。
Silvanus P.Thompson 的《Calculus Made Easy》(《微积分很简单》此书尚无中译本)。可从Gutenberg 项目免费获得。
微积分 1A:与edX上的麻省理工学院的区别。
可汗学院的《微积分 -1》中的极限和积分微积分。
阅读不同的统计学书籍,掌握统计学的思维方式。
真是个大错特错 ☹ 据我今天所知,我所需要的就是:
统计学基础。不是统计学本身,而是机器学习和数据分析所特别需要的主题。
贝叶斯定理的基础知识。
线性代数基础(只有矩阵乘法和转置矩阵等一些小东西)。
大〇符号的基础知识。
是啊,没什么特别的,就是一些基本的东西。一切新奇的事,你找了工作以后就可以做。在此之前,使用 Python 或 R 库进行处理。与其像在学校或大学里一样尝试学习数学公式,不如尝试用 Python 中的库调用来学习如何使用它,比如用 Scipy 计算学生 t 检验,并学习理解它所需要的数学知识。
译注:学生 t 检验(英语:Student's t-test)是指虚无假设成立时的任一检定统计有学生 t- 分布的统计假说检定,属于母数统计。学生 t 检验常作为检验一群来自常态分配母体的独立样本之期望值的是否为某一实数,或是二群来自常态分配母体的独立样本之期望值的差是否为某一实数。
Scipy 讲义 3.1:《Python 中的统计》
一个简单的线性回归,给定两组观测值 x 和 y,我们要检验假设 y 是一个线性……
嗯,花了有八到十个月的时间。
6 + 6 + 8 + 0 + 10 = 30 个月。
6、认为 R 与 Python 之争,只需二选一
关于这个问题,我很纠结:
从Hadley Wickham的《R 数据科学》(R for Data Science)开始。因为我看到 Python 在工业中越来越重要,所以读了几章之后就放弃了。
我从 Python 开始,尝试了几本书,然后我又回到了 R,因为 ggplot 看起来比 matplotlib 要好。
后来我又回到了 Python,因为它更有软件工程的感觉。
之所以回到 R,是因为 tidyverse 作为一个包,在数据分析和可视化方面看起来比 Python 的工具更加成熟。
当我从一家公司得到一份带回家的任务时,这个问题就消失了,这家公司找我做与 R 相关的工作。在使用 R 和 Python 完成任务后,我再也不想碰 R 了。根据我的经验,Python 更适合软件工程实践,当涉及到为现实生活中的工业工作编写数据科学代码时,软件工程实践肯定是需要的。这和你做软件开发的时候差不多。之后我就全面使用 Python 了。我个人认为,如果要用其他语言的话,我会用 Julia 代替。大概四到六个月就可以了。
6 + 6 + 8 + 0 + 10 + 4 = 34 个月。
7、花大量时间思考非结构化数据
这个错误是我在“数学错误”之后犯的。我花了几个月的时间思考 SQL 与 NoSQL。当我们看到某事物时,我们会从自己的角度来思考,认为这就是它的意义。众所周知,现在是数据时代,每天都有数百万、数千万兆的数据产生。其中大部分是非结构化的。我猜想我应该学习 NoSQL。但之后,几乎所有的职位描述都只是提及 SQL。然后我会考虑使用 SQL。
我既没有学过 SQL,也没有学过 NoSQL。所以在一件事上犹豫不决会浪费你好几个月的时间。
我没有按照我的方式来解释事情,而是开始观察那些找到数据科学工作的人,以及他们所学到的东西。他们都把 SQL 列为一项技能。于是我转而学习 SQL。SQLBolt是一个不错的起点。
我不会觉得在这里浪费时间,因为尽管我什么都没学,但是我却利用这段时间学习了其他的东西。所以,目前的等式是:
6 + 6 + 8 + 0 + 10 + 4 + 0 = 34 个月。
8、只考虑技术,不考虑业务
你需要认真地改变你的思维方式,我也需要这样的改变。在计算机编程方面,我是个 100% 的技术男,除了团队合作,我真的不知道怎样做得更好。对团队有贡献是我社交和交流能力的终点。
起初我并不知道,但是由于我的阅读习惯,我发现了很多数据科学的特点,这些特点使它与其他科技工作相去甚远。解决这个问题的一种方法是与我认识的人或我所遇到的人讨论大数据。把机器学习的概念解释给我的朋友和其他人听。但是因为我从事自由职业者和学习数据科学需要我在计算机上花费很多时间,所以我没有机会练习更多。
数据科学不仅仅是编程,它也不仅仅是网络开发,它也不仅仅是分析数据和建模。这是故事的一半。数据科学的另一半是能够与不太懂技术的人沟通。业务利益相关者、管理层的决策者和客户是你要面对的三种不同类型的非技术人士。所以,如果我们把与人合作看作是“另一个技术工作”,那么与人合作将是一个很大的痛苦。有一本关于沟通数据见解的优秀书籍,名为《用数据讲故事》(Storytelling With data),作者是Cole Nussbaumer Knaflic。这算是一本必读的书。
还有另一面:业务问题。你建立的模型,你所做的比较,以及你所达到的正确度,它是如何有利于业务的?要知道,一个数据科学家的工作,如果不能给企业带来一些利润或者好处,或者一些增值,那他的工作就没有意义。像我这样的技术出身的人,很难掌握并且做得很好。在这种情况下,技术思维所做的事情,就是让你的思维只关注于建立模型和分析数据,因为这是我们的工作。我们没有业务背景。
由于从未有个人经验,所以我没有很好的解决方法。因此,我对我的建议持怀疑态度。也可以搜寻自己。只有看博客、帖子和文章才能知道该怎么做。而且我不认识任何产品经理(我见过一两个 IT 服务部门的经理,但我不知道这是否够资格)。 有两种方法可以解决我遇到的这个问题:
阅读案例分析、产品案例分析。这就是产品经理的工作。所以,如果你认识任何一个产品经理(甚至是项目经理),你应该就其产品 / 项目如何为公司带来价值与他们进行交谈。
请阅读由Gayle Laakmann McDowell和Jackie (Bodine) Bavaro撰写的《产品经理面试宝典》(Cracking the PM Interview)等书籍。
如果你是程序员或软件开发人员,不了解这一点,你就会在技术技能上花费大量的时间和精力。浪费了六个月的时间。
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 = 40 个月。
9、努力跟上所有的论文
另一个你需要避免的陷阱。我在这个问题上卡了一段时间。我自己也想落实一两篇论文,但现在我的第一关注点总是在“做些什么”上。少学点东西,因为你需要开始努力去建立一些东西。
是的,那些论文看起来真的很厉害,很好看。而论文大多是关于学术方面的。你是想在行业里找到一份工作。学术界和工业界并不匹配,除了两个可能的例外:
你正在寻找一个行业内的研究职位。这样的话,你的投资组合将只限于 10~20% 的雇主。
你想为四大公司工作,也就是 Facebook、亚马逊、谷歌和微软。
除以上所说外,我不认为自己有必要在一家优秀的一级或二级公司找到一名数据科学家的职位。别误会,我喜欢做研究。其实,我在大学的时候就想读微内核研究的博士学位了。研究工作需要耗费大量的时间和精力。我觉得一个更好的生活方式是在你的事业中找到一个平衡点:在你的兴趣和市场 / 行业需求之间找到一个平衡点。不要站在任何一边。
与其跟上所有的论文,不如用更好的方式来平衡自己的学习:
学习使用Pandas 进行数据清洗的基础知识(Kaggle 数据集已经为你完成了 90% 的工作。在现实生活中,你必须做所有的清理工作。学会抓取一些数据并进行清洗)。
了解机器学习建模的基础知识,以及我们为什么选择一种模型而不是其他模型。什么样的模型适合什么样的领域问题,如医疗与金融。
了解如何将模型部署到生产环境中(你将了解使用Strealmlit、Heroku和Voila时实际工作的感觉。我在这里使用 Voila实现了 bear-detection 模型。)
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 + 10= 50 个月。
10、认为做某事只有一种方法
这个是个大问题。而我认为,我这辈子都在与此作斗争。有些人有,有些人没有。我倾向于说,也许聪明人并不存在这一问题(我遇到的或读到的聪明人,他们没有这一问题)。像我这样的人一生都在和它较劲。这是一个监狱,相信我。生活在“只有一条路可走”的心态中是很让人沮丧的。看一看现实生活中的故事,你就会发现想法是无限的。
它并不是技术上的障碍,而更像是个人发展上的障碍,因为无论你将从事什么领域,这个障碍都会出现,而和技术完全没有关系。现在我仍在努力解决。在此期间,我发现了一个解决办法,那就是当我找不到解决问题的办法的时候,我会下机,如果是晚上就去散步,如果不是晚上就去读一本完全无关的书(比如一些非小说),或者去骑摩托车,完全忘记这个问题。然后我再回来,试着从不同的文章或博文中学习同样的东西,而不会提及我曾经卡在的地方。只是从别人的角度对同一个问题有一个全新的看法。
我不能对此设定任何时间限制。我一生都在为这个问题而奋斗。
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 + 10 + 终身 = 50 个月 + 终身。
所以,我已经浪费了将近 50 个月的时间?
也不是。
在谈到我浪费时间的地方时,这些点都是相互重叠的。其实是十二个月:2019 年 12 月到 2020 年 11 月。在最初的几个月里,我甚至不知道该怎么做。直到去年的 2020 年 3 月,事情才开始变得有意义。如果事情清楚一点的话,我想我能省下四到六个月的时间,但这只是一个胡乱的猜测,一些真正聪明的人告诉我:无论付出什么代价都要打破壁垒。请允许我再次重申:
每一个人都有自己的数据科学旅程。我们的环境、我们的天赋、我们的经验、我们的态度、我们的工作态度、我们的背景以及我们的学习能力,都是不同的、独一无二的。正因如此,寻找他人之路可能永远不会成功。正因为如此,你需要不断地强迫自己去学习可以学到的东西,让自己了解行业的发展,不断地修正自己的道路(就像智能手机上的地图等应用,不断为我们修正和指路一样)。
你的精神面貌
当我还没有弄明白逻辑回归比线性回归更适合哪些问题时,我就在尝试学习神经网络。在机器学习有任何意义之前,我就在做深度学习。对于我而言,原因是:
人工智能和深度学习的媒体炒作。
我致力于创造一种伟大的,令人印象深刻的东西。
假设大家都在做,我想要找到工作,就要比他们做得更好。毕竟,市场竞争是如此激烈。
关注四大公司。
我对医疗数据有兴趣,《Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD》(本书尚无中译本)就有关于医学影像诊断的章节。你可以在这里看到一个例子。
媒体上到处都有深度学习和人工智能。人们常常认为自己比别人更优秀,别人已经在写高度数学化的博文,用他们华丽的公式以及大量的代码。不相信我的话?那就看看[这个](https://medium.com/search?q=gradient descent in Python)吧。当这样的人已经掌握了深度学习和数据科学的时候,谁还会来接近我们呢?
是啊,这太常见了,他们给它起了个名字,这就是所谓的“冒名顶替症候群”。你去看看吧。我以为我是唯一一个受其折磨的人。但是之后我发现它是如此的常见。是的,市场竞争非常激烈,而且由于目前的新冠肺炎疫情,许多人失去了工作。我在 LinkedIn 上看到过几篇数据科学家和机器学习工程师失业的文章。我看到过他们在寻找工作,甚至还会恳求点赞和分享。看到这一点真令人心碎。每个人都应该过上好日子。
我们来看看积极的一面,这场瘟疫扰乱了这个世界,它使许多企业陷入停滞,而一些企业的客户数量却直线上升(播客和视频会议服务就是其中之一)。在这样一个颠覆性的时代,我们需要更多的忍痛割爱,并想方设法坚定自己的决心。我们出生在某一年,我认为,并非偶然,这就是我们如何在这场大瘟疫中幸存下来的原因。我认为我们本应从中吸取教训,并在这个时代创造更美好的生活。祝大家在数据科学学习的道路上越走越好,同时也希望我们能不断地相互学习,共同进步。
作者介绍:
ArnuldOnData(Arnuld),是一名工业软件开发人员,拥有 C、C++、Linux 和 UNIX 领域的工作经验。在转型到数据科学家并担任数据科学内容作者一年多之后,目前是一名自由数据科学家。家住印度特伦甘纳邦海得拉巴。
原文链接:
https://www.kdnuggets.com/2021/01/data-science-learning-journey.html




