
本文最初发表于Java Advent网站,经原作者A N M Bazlur Rahman授权,由 InfoQ 中文站翻译分享。
Java 已经有 20 多年的历史了,它一直是软件开发领域的主导力量,这种情况应该还会继续下去。然而,它之所以表现如此优异,是有多种原因的,其中之一就是并发。Java 通过引入一个内置的线程模型开始了它的并发旅程。
在本文中,我将会讨论关于线程模型的一些历史知识,阐述它们是如何帮助我们形成使用 Java 进行编程时的理解和实践的,以及我们目前处于何处和它的一个特殊问题。
这篇文章会有点长,但是我相信你会喜欢它的。
让我们开始这段旅程吧!
Java 是由线程组成的
从诞生之初,Java 就引入了线程。线程是 Java 中的基本执行单元。这意味着我们要运行的所有 Java 代码都需要由线程来执行。线程是 Java 平台上执行环境的独立单元。
由此我们可以看出,如果一个程序有更多的线程,那它就有更多可以执行代码的地方。这意味着可以同时做更多的事情,从而给我们带来很多收益。一个特别的收益就是,通过利用机器上所有可用的资源,这能够提高应用的吞吐量。借助这种方式,我们能够从程序中获得更多的效益。
线程广泛存在于 Java 平台的各个层面中。
线程不仅能够执行代码,它还会在其栈中跟踪方法的调用。所以,如果 Java 程序在执行过程中遇到问题的话,我们会抛出异常。异常中会包含栈跟踪信息,基于此我们可以判断出错误的原因。由此,我们可以说线程是获取栈跟踪信息的一种方式。
此处,如果需要通过 IDE 调试程序的话,我们也会用到线程。如果需要对程序或程序的一部分进行剖析(profile)的话,我们也会用到线程。Java 垃圾收集器会运行在一个单独的线程中。所有的这一切都证明,并发或者”线程“是编程平台的一个重要组成部分。
但是,线程是昂贵的
在现代 Java web 应用中,吞吐量是通过使用并发连接实现的。通常情况下,客户端的每个请求都会有一个专门的线程。现代操作系统可以处理上百万的并发连接。这表明,如果我们有更多的并发连接,就能实现更高的吞吐量。
这个结论似乎是合理的,但现实情况远非如此。原因在于,我们无法创建尽可能多的线程来实现这一点。
线程是数量有限的昂贵资源。创建一个线程需要在堆外占用 2 MiB 的内存。需要记住的另外一件事情是,按照传统的做法,Java 线程仅仅对操作系统线程做个一层很薄的封装。我们只能创建数量有限的线程。即便我们有了大量的线程,也无法始终保证应用整体的性能。上下文的内容切换会有相关的成本。
你可以通过运行如下的样例看一下能够创建多少个线程。
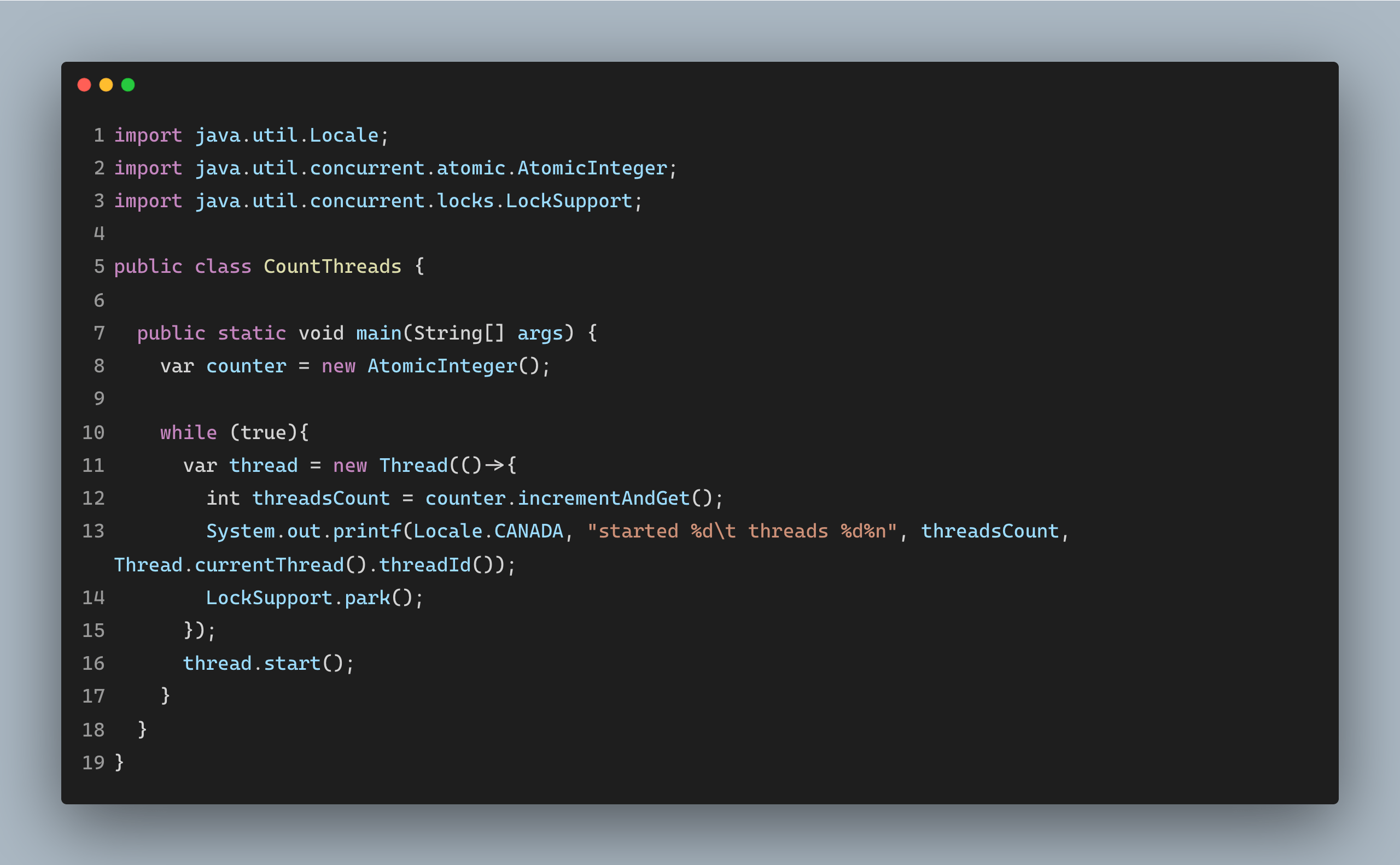
到目前为止,我们已经讨论了 Java 线程的重要性以及它们的一些限制。那么,我们再进一步深入讨论一下。
我们现在遇到了什么问题
现代软件应用开发需要处理大量的数据,而且应用的使用率也会很高。这就带来了相关的成本问题。如果我们不留意的话,云计算的成本会迅速累积。
我们已经确认,创建线程的成本并不低,而且它们的数量是有限制的,所以我们不能浪费任何线程,而是要充分利用它们的能力。但实际上,情况并非如此。在传统的编程模型中,当我们调用一些需要时间才能获取响应的逻辑时,它会阻塞当前线程。例如,如果我们进行一个网络调用(可能是微服务或数据库调用)的话,用来进行调用的线程会被阻塞,直到得到结果为止。在等待结果的过程中,线程什么事情都不会做,基本上就是处于空闲状态,浪费了宝贵的资源,从而导致云账单的无谓增长。
因此,基于上述假设,可以得出结论,阻塞调用对我们并不是什么好事儿。
我们可以看一个样例。

在上述的代码中,我们进行了五个方法的调用。假设所有的方法均需要一些时间来进行处理。为了简单起见,我们假设它们都需要 200 毫秒的时间来处理。
由于我们是一个接一个地进行所有的调用,这将需要至少 200*5=1000 毫秒来完成该方法。因此,开始所有这些调用的线程必须等待它们全部完成。
在这个场景中,我们可以看到,调用calculateCreditForPerson()方法的线程在大部分时间内都是阻塞的,因为它在等待后续方法的完成。当阻塞的时候,它没有做任何事情。基本上来讲,它的资源因为不能做任何事情而被浪费了。
问题是,我们该如何才能改善它呢?
目前,业界已经有很多方案尝试来改善这种情况,使线程在这种情况下不会被阻塞。我将从 Java 历史的最开始说起。
经典的实现方式
上述样例中,在方法内部的各个方法调用并不都是互相依赖的。所以,第二个、第三个和第四个调用可以并行进行。如果这三个方法并行执行的话,我们就可以做一些改进。这样,调用者线程将花费更少的时间,这意味着更少的阻塞时间。这将是一个巨大的改进。在这里,我们没有解决阻塞的问题,但是负责调用该方法的主线程处于阻塞状态的时间会大幅减少。它将有更多的时间去做其他的事情。
那么,我们该如何实现这一经典的方式呢?
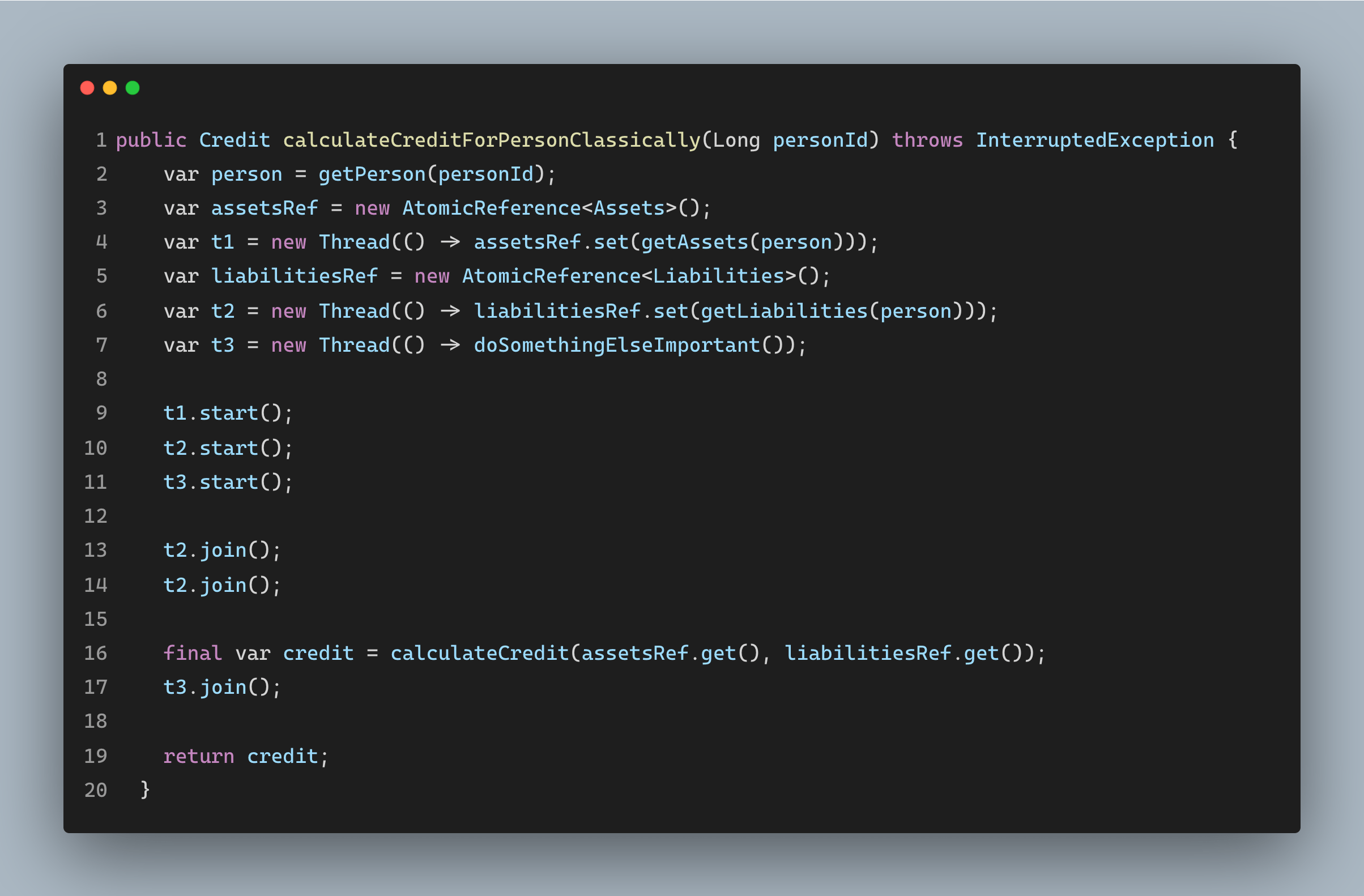
最终的代码将类似于如上所示。我们将临时创建一个新的线程,并将结果存储在一个AtomicReference中。
这种方式很不错,但是我们无法控制要创建多少个线程。如果持续地创建临时线程,我们最终可能会创建过多的线程,这对应用是有害的。此外,如果试图创建过多线程的话,应用可能会抛出java.lang.OutOfMemoryError异常。
所以,我们需要进一步地改进。
Executor 框架
Java 5 引入了 Executor 框架,以及Future和Callable/Runnable。它允许我们控制要创建多少个线程,并对它们进行池化管理。
基于此,我们可以按照如下方式改善上述代码:

对于代码编写来讲,这是一个相当大的改进,但是我们尚未达到目的。Future的机制依然非常复杂。对它的get()调用依然是一个阻塞式的调用。尽管我们进行的是异步调用,但最终还是需要一个阻塞式调用以便于从Future中获取值。
另外一个问题在于,它有可能会导致缓存受损(cache corruption,作者在这里指的应该是需要跨 CPU 内核存取数据,从而导致 CPU 级别的缓存失效——译者注)。例如,如果主线程向线程池提交任务的话,该任务将会由池中的某个线程来执行。主线程需要数据,但是这些数据却在另外一个线程中。这两个线程可能会位于不同的内核上,从而导致缓存受损。除此之外,在不同核心的上下文之间进行切换也是代价高昂的操作。
它还需要使用组合操作。所以,代码更多是命令式的。命令式的代码本身没有什么问题,不过函数式和声明式代码也很有意思。所以,至少我们在这里还可以进行一些改进。
Fork/Join 池
Java 引入了 Fork/Join 池,它是 Java 5 所引入的ExecutorService的实现,也是 Executor 框架的实现。它解决了我们在旧的 Executor 框架中遇到的很多问题,如缓存受损的问题。除此之外,它的运行理念是,刚刚创建的一批任务很可能会需要更紧密的缓存。这意味着,新创建的任务应该在同一个 CPU 上运行,而旧的任务可能需要在另外一个 CPU 上运行。与其他线程池实现相比,Fork/Join 池中的每个线程都有自己的队列。此外,Fork/Join 池的实现采用了工作窃取(work-stealing)算法。如果池中的某个线程完成了自己的任务,它可以从另外一个线程的队尾窃取任务。所有的这些都能帮助我们实现更好的性能。
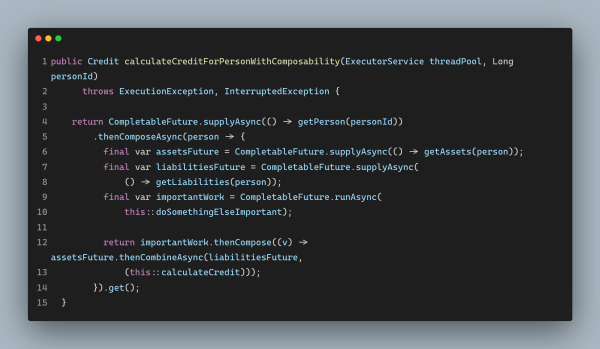
将这一切组合在一起
Java 8 基于 Fork/Join 池引入了CompletableFuture。它包含了我们非常喜欢的组合特性。有了它,我们可以将上述代码改写成如下所示的样子:
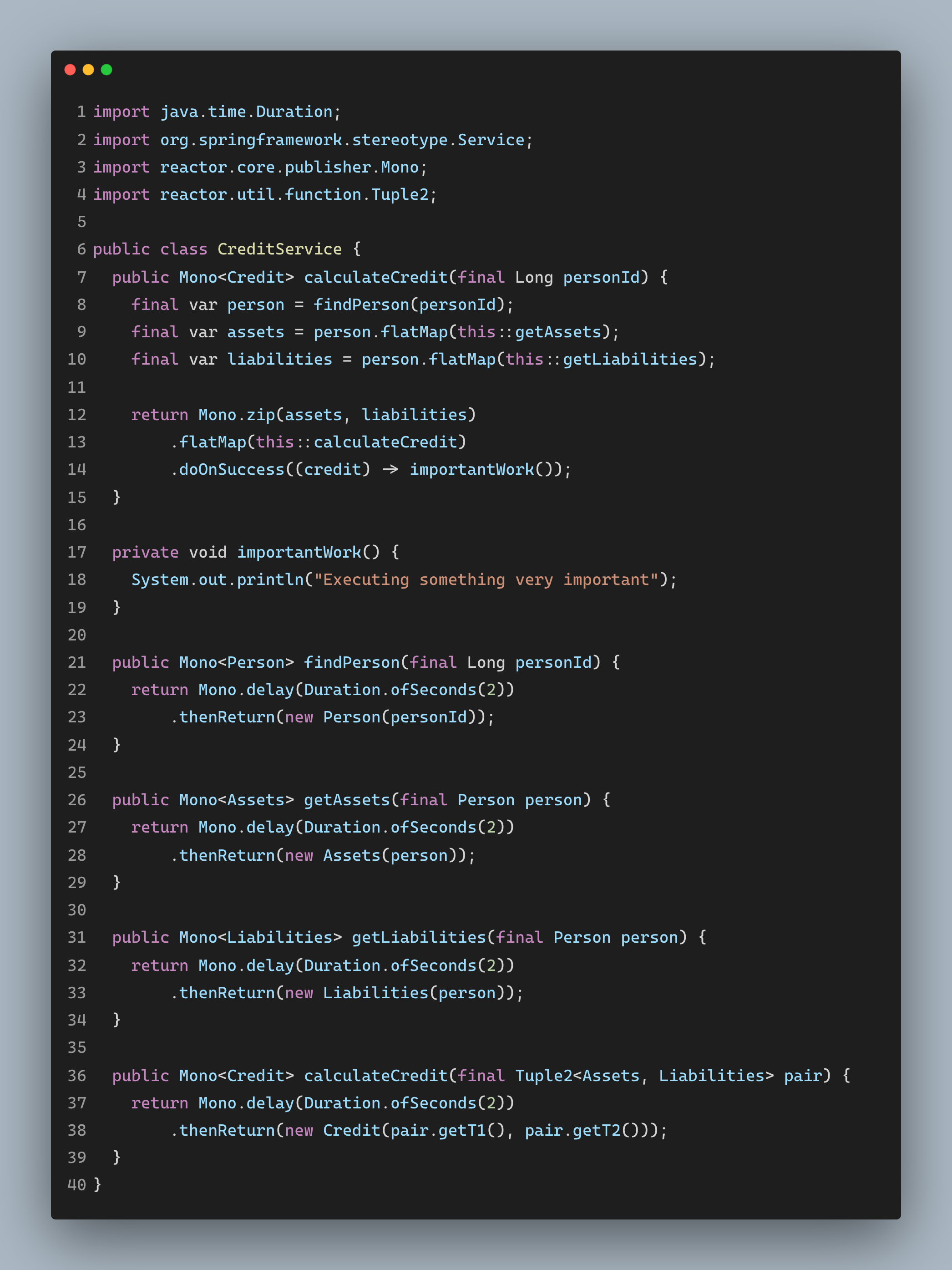
反应式 Java
非常不错,我们已经得到了自己想要的一切,也就是通过可组合性实现性能的提升。但是,市场上还有其他的替代方案。像 RxJava、Akka、Eclipse Vert.x、Spring WebFlux、Slick 这样的反应式框架,也能够为我们带来性能和可组合性的收益。我们来看看 WebFlux 的样例。
但是,这种方式也有一些弊端,比如:
这种框架的学习曲线比较陡峭。有些模式对初学者来说可能会很难理解。
与之相关的认知体验要求很高,这会损害代码的阅读体验。
出现任何问题都很难调试。因为我们不知道特定的代码会在哪个线程上运行,完成任务的路径可能是各种各样的。这就是为何即便有线程转储文件也没有太大的用处的原因。
那么,解决方案是什么呢?
如果我们能够同时使用最初的命令式代码,又能实现简单的异步功能,那就太完美了。这就是 Loom 项目的用武之地了。
Loom 项目
Loom 项目允许我们临时创建任意数量的线程,而不必承担前文所述的各种负担。我们甚至不用关心到底要创建多少个线程,事实上,我们可以创建上百万个线程,而且它们的成本很低廉。
此处之外,我们还可以继续使用命令式和阻塞代码。所以,根本不用担心阻塞式的代码。
Java 19 引入了虚拟线程,有了它之后,我们可以拥有任意数量的阻塞代码。
如果想要使用虚拟线程的话,我们可以使用如下的 Executor:

我们之前为 Executor 编写的代码不需要做任何改变,只需要传入newVirtualThreadPerTaskExecutor Executor 服务即可。
虚拟线程会在原始线程之上运行,这些原始线程被称为平台线程。平台线程基本上也就是 Fork/Join 池中的线程。因此,通过运行虚拟线程,我们可以获得 Fork/Join 池带来的所有好处。
简而言之,虚拟线程的做法是,当它们看到阻塞调用时,就会让出它所占用的平台线程。然后,平台线程就能继续执行其他的虚拟线程。阻塞调用通常会在我们调用睡眠或网络操作时发生,当这些操作完成时,虚拟线程可以重新在平台线程中恢复,以完成其余的任务。
通过这种方式,我们没有因为空闲浪费任何的线程时间,它们一直处于繁忙状态。另一方面,虚拟线程是一个 Java 结构,它可以暂停,并在随后恢复,而不会消耗额外的 CPU。
这使我们的编程变得非常简单。
结论
综上所述,对我们来讲,阻塞调用长期以来都是一个敌人。为了解决它,我们发明了很多方案。最后,基于所有的发明,我们提出了一个新的范式,那就是虚拟线程,有了它,我们不再需要把阻塞调用当作敌人了。
基于此,我们可以放心地调用任何阻塞操作,想调用多少就调用多少。
这就是我们对待阻塞操作和线程的历史。业界有很多连接二者的方式,都能使我们的开发工作更加轻松。
原文链接:
https://www.javaadvent.com/2022/12/a-tale-of-two-cities-how-blocking-calls-are-treated.html
相关阅读:
Java近期新闻:Gradle 8.0、Maven、Payara平台、Piranha、Spring Framework、MyFaces和Piranha




