
本文最初发表于 Towards Data Science 博客,经原作者 Sanket Gupta 授权,InfoQ 中文站翻译并分享。
本文详细介绍了如何使用 Docker 用于机器学习项目和 Jupyter Notebook。
对于当前的软件开发,Docker 是一个非常关键的部分。在开发应用程序时,Docker 可以让你将应用程序分开并隔离。对于一名数据科学家来说,依赖于像pyenvor virtualenv这样的虚拟环境库是很常见的,但是使用 Docker 可以解锁你的不仅仅是原型化,而是构建生产级应用。
尽管虚拟环境非常适合快速开发工作,但 Docker 为与同事协作以及在云中部署数据科学应用程序提供了一种很好的方式。在本文中,我们将介绍数据科学和机器学习开发所需了解的 Docker 基础知识。
学习 Docker 的资源有很多,但是当我刚开始学习的时候,我希望有一个小教程能让我快速地学会如何使用 Dockerfile,而不是花时间去学习很多理论。但愿本文能够成为这样的教程。不管怎样,让我们开始吧。
Docker 之所以如此适用于数据科学应用,有以下几个原因:
隔离应用程序:你可以使用
conda和pip来安装库。这给了你很大的灵活性,你可以在一个特定的项目中使用哪些库。例如,最近我想使用 Facebook 的 Prophet 包进行时间序列预测,通过conda就可以轻松地安装,但对于 TensorFlow 等机器学习库,我更喜欢使用pip——在 Docker 上,这两种方法都非常容易使用。Docker 还可以让你使用任何任意的操作系统。你可以构建不同版本的 Ubuntu 或 Alpine,甚至 Windows。对于虚拟环境,你需要使用主机操作系统。
协作更好:通常在 Python 项目中,需要为不同的项目使用不同的虚拟环境。需要安装
requirements.txt,然后在需要的情况下执行特定的步骤。不过,对于 Docker 来说,安装步骤通常是类似的。将Dockerfile与docker-compose一起使用,用户只需运行docker-compose就可以安装所有的需求,并为你设置所有内容。而且无论是机器还是操作系统,这一步骤都是一样的——这一点非常棒!所以,对于与你的同事合作或开源项目,Docker 是非常棒的!
部署到 AWS 这样的云服务变得更容易,将所有内容都封装在 DockerFile 中。只需将其推送到 AWS Elastic Container Registry(ECR),然后在多个地方使用该容器即可。例如,你想将模型部署到 AWS SageMaker,你只需使用同一个 Dockerfile,AWS 就会为你部署该模型。如果你正在部署一个 Flask web 应用程序,那么你可以使用 Dockerfile 将其与 AWS 一起部署。对于虚拟环境,你必须执行相当多的步骤来确保情况是相同的。
要开始使用 Docker,请从这里下载适用于 Windows、Linux 或 Mac 的 Docker。另外,在 Docker Hub 上创建一个账户:hub.docker.com—— Docker Hub,就像 Github 一样,你可以在那里发布和使用其他人的镜像。举例来说,在那里可以看到一堆 Python 镜像。通常,你从 Docker Hub 中的一个映像开始,然后根据你自己的特定需求在其之上进行构建。
由于本文是一个实践指南,所以我们首先从创建一个 Dockerfile 开始。你可以选择使用现有的项目,也可以创建一个新的项目文件夹。我们将通过脚本模式来完成工作流。如果你喜欢用 Jupyter Notebook 学习,我们会在最后单独的章节中介绍它们。
1. Dockerfile
Dockerfile 是一个文本文件,它包含了构建 Docker 镜像所需的所有命令。一个 Docker 镜像是由一系列层构建而成的。每个层代表了镜像的 Dockerfile 中的一条指令。每当 Dockerfile 中的层发生变化时,当你重建镜像时,该变化后的所有层都将被重新构建。
让我们来编写我们的 Dockerfile 吧!用vim Dockerfile创建一个新的 Dockerfile,方法如下:
FROM python:3.8-slim-busterRUN mkdir /appWORKDIR /appRUN pip install numpy==1.19.4 \pandas==1.1.5 \scikit-learn==0.23.2 \tensorflow==2.4.0 \seaborn==0.11.0COPY . .我们要做的是以下几个步骤:
从 Docker Hub 的 Python 3.8 Slim Buster镜像构建。Python 官方提供了很多镜像。对于大多数情况下,Slim Buster 镜像在大小、性能和功能上是一个很好的权衡。想了解更多信息请阅读这篇文章《Python 应用程序的最佳 Docker 基本映像(2020 年 4 月)》(The best Docker base image for your Python application (April 2020))。
在 Docker 容器内创建一个新的
app文件夹。使app作为我们的工作文件夹——默认情况下,这将是我们此后所有的命令的位置。
运行
pip install下载项目需要的库。这些都是机器学习项目所需要的常用库,比如 Numpy 和 Pandas 用于数据探索;Scikit-Learn 用于数据扩展、浅层建模、特征选择和度量;TensorFlow 用于深度学习模型,最后是 Seaborn 用于数据可视化。
将当前目录下的本地文件复制到
app目录下。
2. Docker Image
Docker Image(镜像)是一个只读的模板文件,它包含了应用程序运行所需的源代码、库、依赖关系、工具和其他文件。它是用一组层构建的。
命令行的 docker 命令的基本思想是:
docker <management command> <command>Docker 镜像需要知道的重要命令是:
# List all docker imagesdocker image ls# Build an image with name "hello" from Dockerfile in this directorydocker image build -t hello .# Delete image with name "hello"docker image rm hello如上所述,现在让我们运行docker image build-t hello。在带有 DockerFile 的文件夹中。它会显示一些所有库的安装步骤和它们的依赖关系。最后,它将显示:
Successfully built <IMAGE_ID>Successfully tagged hello:latest如果我们只想要 Python 3.8 镜像,而不需要额外的命令,我们可以运行:docker image pull python:3.8-slim-buster。
3. Docker Container
Docker Container(容器)是 Docker 镜像的运行实例:容器运行实际的应用程序。容器包括一个应用程序及其所有的依赖关系。容器与其他容器共享内核,并作为一个独立进程在主机操作系统上运行。镜像可以在没有容器的情况下存在,而容器需要运行镜像才能存在。你可以从同一个镜像中拥有许多运行中的容器。需要知道的重要命令如下:
现在要运行已构建的 Docker 镜像:
让我们运行镜像并进入 Docker 容器内的 bash shell:
docker container run -it hello bash你需要指定-it才能通过终端 shell 与容器交互。上面的命令不会继续将我们的本地文件来回复制到 Docker 容器中。这一点非常重要,因为我们需要使用像 Atom 或 Sublime Text 这样的文本编辑器来编写代码,而且我们希望将在文本编辑器上看到的代码反映到 Docker 容器中,而不必一直重建容器!
null 要做到这一点,你需要使用volumes。运行docker container run -it -v $PWD:/app hello bash:这将在 Docker 内部启动一个 bash shell,并创建一种在我们的本地机器和 Docker 容器之间来回复制文件的方法。
我们将在后面的步骤中使用
docker-compose,这样你就不用记住这个长长的命令了。
# Run the container from previously built "hello" image# It will take you to a bash shell inside the docker container# where you can run commands and scriptsdocker container run -it -v $PWD:/app hello bash# List all running docker containersdocker container ls# List all docker containers even stopped onesdocker container ls -a如果我们只想在 Python 3.8 容器中运行一些 bash 命令,我们可以运行:docker container run -it python:3.8-slim-buster bash
下图有助于说明 Dockerfile、Docker 镜像和 Docker 容器之间的区别:
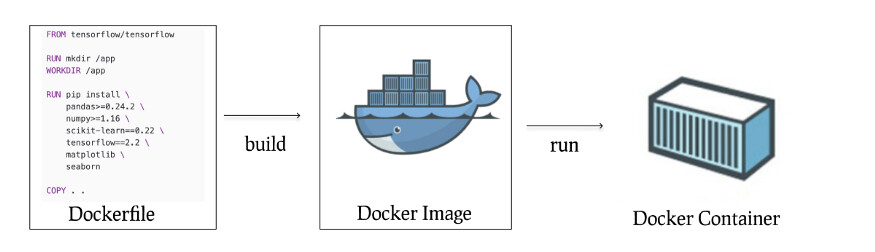
Dockerfile 帮助构建一个 Docker 镜像,然后用来运行 Docker 容器。
4. Docker Compose
Docker compose 是一种用于定义和运行多容器 Docker 应用程序工具。即使你正在运行一个单一的应用程序,它也是一个有用的工具,你可以不记得所有不同的volumes参数、端口设置等。
要创建 docker-compose 文件,请在 Dockerfile 所在的文件夹中运行vim docker-compose.yml:
version: "3"services:hello:build: .image: hellovolumes:- ".:/app"这个 Docker 文件是一个 YAML 文件,它告诉 Docker 从不同的 Dockerfiles 构建各种服务,配置镜像名称、环境变量、卷和端口。
要运行这个文件,请执行命令docker-compose build hello:这将像之前一样构建 hello 镜像。接下来的命令docker-compose run hello bash将运行容器并设置卷等。这个命令会替换步骤 3 中的整个docker container run -it -v $PWD:/app hello bash命令。
需掌握的重要命令:
# Build the docker service "hello"docker-compose build hello# Run a container from image "hello" and open a bash shelldocker-compose run hello bash现在,你可以在 Docker 镜像中编写代码,并分析和运行数据科学代码了!
5. Docker Management
当你构建更多的 Docker 镜像和容器时,你需要在系统上管理所有这些镜像和容器的方法。这些命令将帮助你浏览 Docker 世界。让我们来了解一些 Docker 系统命令。
docker system info命令用来获取所有关于容器数量、镜像等信息。docker system df命令用来了解通过删除未使用的容器、镜像等可以回收多少空间。docker system prune后面带Y参数将清理所有停止的容器和所有悬空(dangling)镜像,这非常有用。如果你在上面的命令中加上-a参数,它将清理所有的镜像,而不仅仅是悬空镜像。
6. 用 Docker 运行 Jupyter Notebook
如果你更喜欢使用 Jupyter Notebook,那么它会稍微复杂一些,但是我们可以根据前面部分的知识进行构建。你还必须修改你的镜像和docker-compose文件。
# Dockerfile for working with Jupyter notebooksFROM python:3.8-slim-busterWORKDIR /home/notebooks # This is different from usualRUN pip install numpy==1.19.4 \pandas==1.1.5 \scikit-learn==0.23.2 \tensorflow==2.4.0 \seaborn==0.11.0 \jupyter \notebookCOPY . .EXPOSE 8888ENTRYPOINT ["jupyter", "notebook","--ip=0.0.0.0","--allow-root", "--no-browser"]在现有的项目中创建上述 Dockerfile,然后将docker-compose文件更改为:
version: "3"services:hello:build: .image: hellovolumes:- ".:/home/notebooks" # This is different from usualports:- 8888:8888下面是要运行的命令:
# Build the docker service "hello"docker-compose build hello# Create a Docker container from image "hello"# It will use ENTRYPOINT in Dockerfile to start Jupyter notebookdocker-compose up hello和前面一样,运行 build 命令。但是不需要调用 bash,只需要运行up命令,并使用上面的ENTRYPOINT,Docker 就会启动一个 Jupyter Notebook 服务器,你可以在本地访问http://127.0.0.1:8888/?token=,现在你可以使用电脑上的浏览器在 Docker 容器上进行 Jupyter 操作。
恭喜!希望以上工作流程对你的数据科学开发非常有用。让我们快速回顾一下,当你将 Docker 和数据科学项目结合起来时,有哪些可能性:
数据科学 / 机器学习开发的 Docker 用例:
你可以与其他数据科学家分享你的
Dockerfile和docker-compose文件,方便合作。你可以将此镜像部署到 AWS ECR 中,以便部署到 SageMaker 端点中。这将允许你将你的模型构建为一个端点,供用户使用你的网站等。我写了一篇博文《Amazon SageMaker 非常适合机器学习的十个原因》(10 Reasons Amazon SageMaker is great for Machine Learning),详细介绍了这些步骤。
你可以在 AWS ECS Fargate 里面部署这些容器,以便定期运行机器学习模型。如果你不想将模型公开给最终用户,而是定期运行(比如说在这个月来的所有新用户上),你可以使用这种方法。
这篇关于使用 Docker 和数据科学的实践指南到此结束。
作者介绍:
Sanket Gupta,Octopart 数据科学家。目前正在与金融、营销、产品和工程团队合作。侧重于端到端管道,包括数据工程、数据分析以及数据科学。
原文链接:
https://towardsdatascience.com/hands-on-guide-to-docker-for-data-science-d5d1f6f4a326




