
微服务的目标是将应用程序尽量分解 / 解耦为围绕业务功能组织的一系列松散耦合服务。这些分布式的微型单元共同满足应用程序的目标。
将单个应用程序拆分为多个微服务后,跨越多个服务的事务(读取和写入)就变得不可避免了。进而,跨各个微服务边界的通信——工作流管理——数据存储机制 就成为了挑战。这一系统应符合被称为分布式计算谬误的准则。当跨多个服务(每个都有自己的业务逻辑和数据库)处理事务时,数据库系统承诺的 ACIDity 是无法保障的。CAP 定理 意味着你需要在一致性(C)和可用性(A)之间做出权衡,因为分区容错(P)在分布式系统中是无法指望的。在这篇博客文章中,我们将探讨针对这些挑战和设计模式的解决方案。
协调服务间通信
针对不同环境和目标的客户和服务可以通过不同的机制来通信。通信可以是同步的或异步的,具体取决于协议。
同步通信——请求响应方法
在同步通信中,需要一个预定义的源服务地址,指明请求要发送到何处,并且 两边的服务(调用方和被调用方)都应处于启动和运行状态。尽管协议可能是同步的,但 I/O 操作可以是异步的,其中客户端不必等待响应。这是 I/O 和协议 之间的区别。Web API 常见的通用请求 - 响应方法包括 REST、GraphQL 和 gRPC。
异步通信
在异步通信的情况下,调用方不必有被调用方的具体地址。这样就可以相对容易地一次处理多个消费者(因为服务可能会增加消费者数量)。此外,如果接收服务关闭,消息就会进入队列,然后在接收服务打开时继续处理。从 松散耦合、多服务通信以及应对部分服务器故障 的角度来看,这尤其重要。正是这些决定性的因素让 微服务倾向于异步通信。诸如 MQTT、STOMP、AMQP 之类的异步协议由 Apache Kafka Stream、RabbitMQ 之类的平台处理。
了解何时何地使用同步模型与异步模型,是设计高效微服务通信机制时的基础要素。
消息与事件
在异步通信中,常见的机制是消息传递和事件流。
消息
消息 是发送到特定目的地的数据项目,它封装了 意图 / 动作(需要发生的事情),并通过消息传递之类的渠道分发。队列负责存储消息,直到它们得到处理和删除。在消息驱动的系统中,可寻址的收件人等待消息到达并做出响应,否则将处于休眠状态。
事件
事件封装了状态的变化(发生了什么),而事件侦听器会附加到事件源上,以便在事件发出时调用它们。
域事件:与应用程序生成的业务域相关的事件(下图中的 OrderRequested、CreditReserved、InventoryReserved)。这些事件是事件源关注的。
更改事件:从数据库生成的事件,指示状态转换。这些事件是更改数据捕获所关心的。
事件 streamer 是耐用的、持久的、容错的,不受消费者干预。在这种情况下,处理器是 dumb 类型(从某种意义上说,它仅充当消息路由器),并且客户端 / 服务拥有以域为中心的,负责 转储处理器与活跃客户端 的逻辑。这样就避免了复杂的集成平台,例如传统 SOA 设计中使用的 ESB。
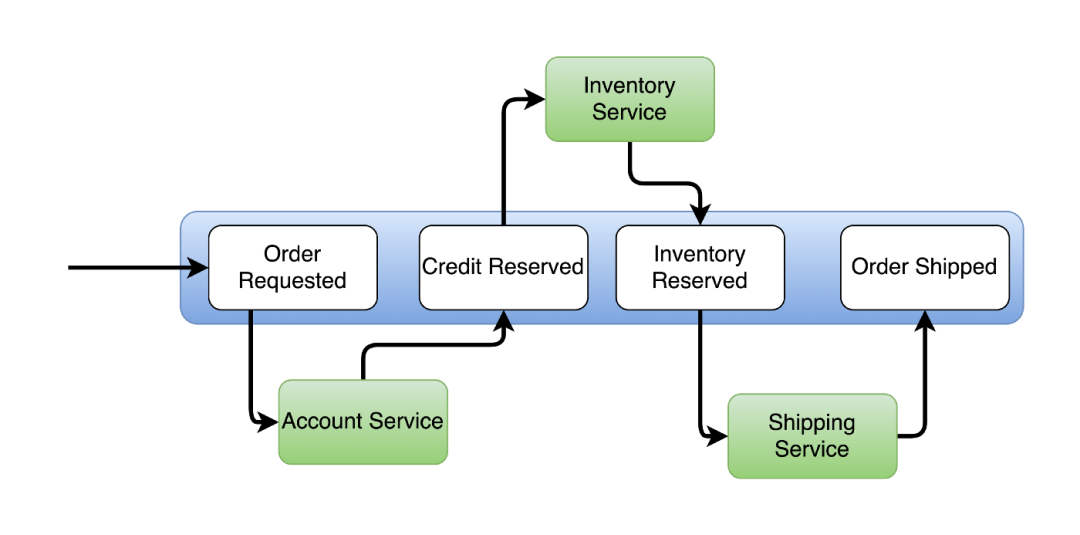
图:微服务设计中的事件
微服务原理——智能消费者与哑管道
微服务社区提出了智能端点和哑管道的理念。Martin Fowler 是他称为微服务通信的智能端点和哑管道的拥护者。统治 SOA 领域的 ESB 存在与复杂性、成本和故障排除相关的诸多问题。
异步通信协议
MQTT——消息队列遥测传输(MQTT)是一项基于发布 / 订阅的轻量级消息传递协议 ISO 标准,已在物联网中广泛使用。
AMQP——高级消息队列协议(AMQP)是一项开放标准应用程序层协议,用于面向消息的中间件。
STOMP——简单文本定向消息传递协议(STOMP)是 HTTP 上基于文本的协议,用于在服务之间交换数据。
通用消息 / 流平台
ActiveMQ
Kafka
RabbitMQ
Redis Streams
评估标准的一些常见基准包括可用性、持久性 / 耐用性、耐用性、推 / 拉模型、可伸缩性和消费者能力。
微服务设计模式
微服务建立在独立和自治服务、可伸缩性、低耦合 + 高内聚和容错性等原则上。这些原则会带来许多挑战,包括复杂的管理和配置需求。微服务设计模式的目的是在给定的上下文中描述问题的可重用解决方案。我们将探讨这些模式如何应对挑战,以提供经过验证的解决方案来打造更高效的微服务架构。
Saga 模式——跨多个服务维护原子性
单个事务可能会跨越多个服务。例如,在电子商务应用程序中,新订单(与订单服务链接)不应超过客户信用额度(与客户服务链接),并且货品(与库存服务链接)应处于可用状态。这个事务根本不能使用本地 ACID 事务。
一个 saga 是一系列本地事务,这些事务可更新各个服务并发布一个消息 / 事件以触发下一个本地事务。有任何本地事务失败的情况下,saga 会执行一系列 补偿事务,以回退先前的本地事务所做的更改,从而保持 原子性。
基于编舞(Choreography)的 saga——参与者在没有中心化控制点的情况下交换 事件。
基于编排的 saga——一个中心化控制器告诉 saga 参与者要执行哪些本地事务。
在这两种模式之间具体选择哪一种,取决于工作流程的复杂性、参与者数量、耦合水平以及其他因素。
两阶段提交
与 saga 类似,一个事务会分为两个阶段:准备和提交阶段。在准备阶段,要求所有参与者准备数据;在提交阶段则进行实际更改。但是,由于同步存在副作用和性能问题,因此这种模式在微服务架构中被认为是行不通的。
事件源——面向状态的持久性策略的替代方案
保持数据的传统方法是更新已有数据来保持实体状态的最新版本。假设,如果我们必须更改用户实体的名称,我们将使用新的用户名来改变当前状态。如果我们需要在任何时间点或一段时间上重建状态该怎么办?在这种情况下,我们需要考虑这种持久性策略的替代方案。
与这种面向状态的持久性相反,事件源将每个状态突变存储为一个单独事件,而应用程序状态则存储为 不可变 事件的一个序列 / 日志,而不是修改数据。通过有选择地重播事件,我们可以随时了解应用程序的状态。应用程序在称为事件存储的仅附加事件日志中保持数据。一个著名的例子是事务数据库系统的事务日志。
事件源基于三个服务层:
命令:由一个命令处理器处理的状态更改请求。
事件:状态更改的不可变表示。
聚合:域模型当前状态的聚合表示。
事件源模式有很多优势,包括提供准确的审核日志、重建任意时间点的状态、方便的时间查询、时间旅行、高性能和可伸缩性等。Netflix 通过事件源解决了离线下载功能需求。
CQRS——命令查询职责隔离
如果我们将 CRUD 操作设计为可以用两种独立的读写模型来处理,会有什么后果呢?它显然增加了系统的复杂性,但收益是什么?何时需要它?这种隔离增加了另一层可伸缩性、性能和灵活性,从而在处理复杂的域模型时实现精细的读写优化。
CQRS 将在应用程序中进行更改的模型 / 对象与读取应用程序数据的模型 / 对象清楚地区分开。命令只是方法,其唯一目的是执行动作(创建、更新、删除),并且可以被接受或拒绝,而不会暴露系统状态。查询是无需修改即可读取系统状态的方法。更进一步,我们可以引入一种保持同步的机制来拆分数据存储的写入部分和读取部分(可以由多个数据库管理)。
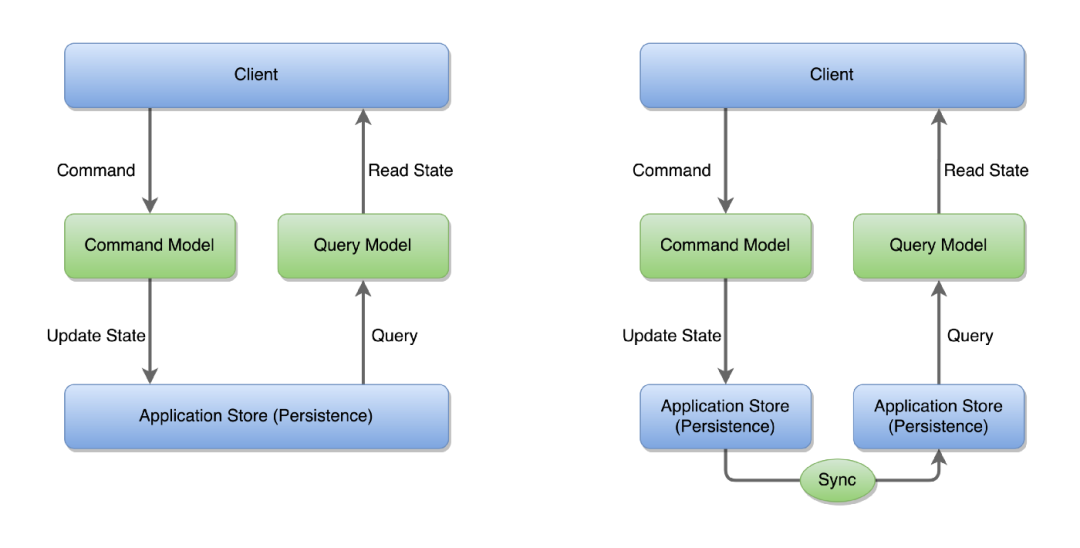
图:具有相同和不同数据存储的 CQRS
事件源和 CQRS
这些通常被称为补充模式。
“没有事件源的情况下也可以使用 CQRS,但有了事件源,你就必须使用 CQRS”——GregYoung,CQRS and Event Sourcing——Code on the Beach 2014。
如前所述,事件存储由不可变事件的一个序列组成。通常,业务需求想要 执行复杂的查询,而这些查询无法由一个聚合响应。每次都重播事件序列需要花费大量计算资源(并且在庞大的数据集中很难做到)。在这种情况下,隔离就会是有益的。
在下图中,更新事件存储的命令将发布事件。查询服务消费了更改日志事件,并为将来的查询建立一个预测。
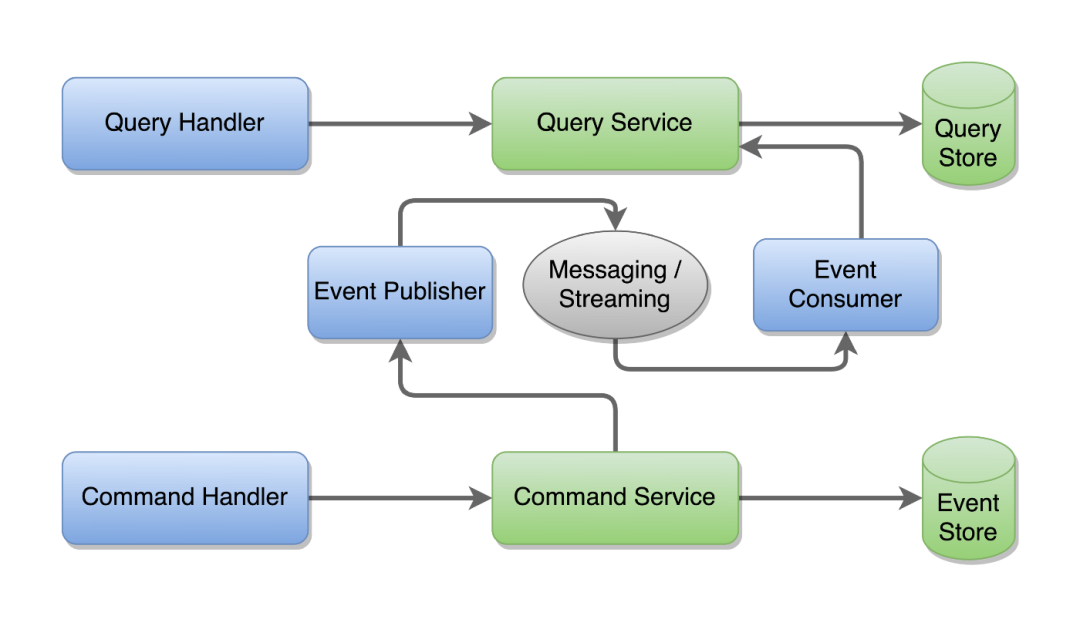
图:一个服务中的事件源和 CQRS
事务发件箱模式
在某些情况下,我们需要在数据库中进行更新,经常还要在外部系统上调用另一个动作。例如,在电子商务应用程序中,我们需要保存订单并向客户发送电子邮件。如果其中一个事务失败,就可能导致系统不一致。
在这种情况下,发件箱(outbox) 和 消息中继(message relay) 可以共同作用,可靠地保持状态并调用其他动作。“发件箱”表位于服务的数据库中。与主要更改(例如在订单表中创建订单)一起,代表事件(orderPlaced)的记录也被引入同一数据库事务中的发件箱表中。在非关系数据库中,这通常是通过将事件存储在文档内部来实现的。
然后,消息中继读取发件箱表,并将消息转发到相应的目的地。消息分派过程可以是轮询发布者(轮询发件箱表)或事务日志跟踪(跟踪数据库提交日志)。
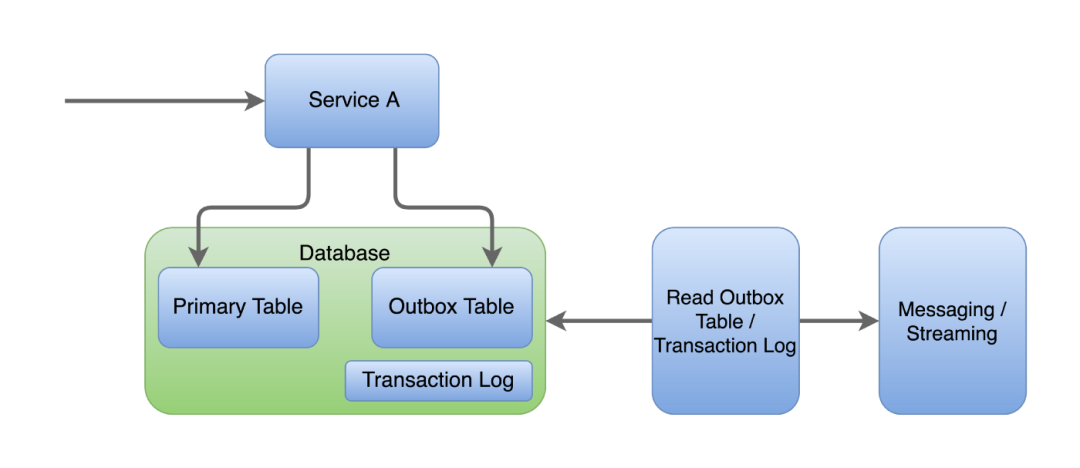
图:事务发件箱模式
更改数据捕获(CDC)
应用程序状态保留在数据库中。更改数据捕获(Change Data Capture)跟踪一个源数据库中的更改,并将这些更改转发到预定目的地,以和相同的增量更改同步。CDC 可以是基于日志的(事务数据库将所有更改存储在事务日志中)或基于查询的(定期用查询检查源数据库,因为事务日志可能在 Teradata 这样的数据库中不可用)。
下图显示了基于日志的 CDC,用于捕获发件箱表中的新条目(使用 Debezium connector for Postgres)并将它们流式传输到 Apache Kafka。事件捕获发生时的开销非常低,几乎是实时的,并且这些事件是订阅的目的地服务。
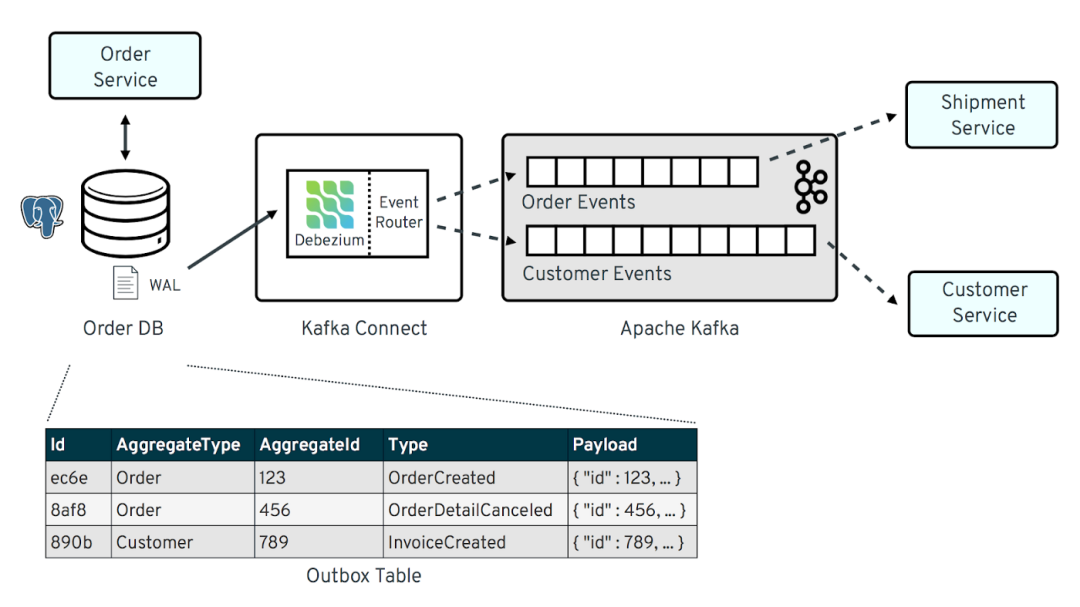
图:事务发件箱与 CDC 使用 ApacheKafka
微服务设计注意事项
我们将简要介绍设计微服务时需要的其他一些思想 / 原理。
幂等事务
幂等事务指的是发出多个相同请求的事务,这些事务具有与发出单个请求相同的效果。在 REST API 中,GET 方法是幂等的(可以反复调用,结果与单次处理的结果是确定一致的),而 POST 方法不是幂等的(每个请求都会添加新项目)。
在分布式系统的上下文中,你不能实现消息的精确一次传递。消息代理(例如 Apache Kafka 或 RabbitMQ)实现了至少一次传递,从而为同一事务带来了多次调用的可能性。因此,在分布式系统中,消费者需要是幂等的。如果消费者不是幂等的,则多次调用可能导致错误和不一致。、
Airbnb 将一个名为“Orpheus”的 通用幂等库 实现到了多个支付服务中,其中一个 幂等键 被传递到框架中,表示一个单独的幂等请求。Paypal 使用 MsgSubId(消息提交 ID)在 API 中实现了幂等性,而 Google Service Payment 使用 request ID 实现了幂等性。

图:“火车目的地”标志控制中的“开 / 关”按钮。按下“开”按钮是幂等的,因为无论执行一次还是多次都具有相同的效果。同样,按下“关”也是幂等的。(来源:维基百科)
最终一致性
在分布式系统中,一致性定义了对一个节点 / 服务的更新是否以及如何传播到所有服务。最终一致性也称为 乐观复制,它只是一个声明,表明将一台计算机上所做的更改传播到所有其他副本上的操作存在不受约束的延迟。
网络分区是分布式系统需要面对的一个现实,那就是网络可能会出故障。由于分区容限(P)是不可避免的,因此 CAP 定理要求你在一致性和可用性之间做出权衡。如果选择可用性,就不能有很强的一致性,但你仍然可以在系统中提供最终一致性。
许多业务系统对数据不一致的容忍度比预期的要高。BASE(基本可用、软状态和最终一致性)系统优于 ACID 系统。
“对于分布式系统而言,保持强一致性非常困难,这意味着所有人都必须管理最终一致性。”——Martin Fowler

图:分布式系统中的最终一致性
分布式跟踪
在微服务中,与(可能跨越多个服务的)请求相关联的元数据在很多场景中都能发挥作用:监视、日志聚合、故障排除、延迟和性能优化、服务依赖分析,以及分布式上下文传播。
分布式跟踪是从头到尾捕获请求的 元数据 的过程,以将日志记录开销保持在最低水平。一个 唯一事务 ID 被分配给外部请求,并通过分布式拓扑中各个事务的调用链传递,还包含在所有消息中(包括时间戳和元数据)。
可以使用数据库票证服务器(由 Flickr 使用)、UUID 或 Twitter SnowFlake 生成唯一标识符。常见的分布式跟踪工具包括 OpenTracing、Jaeger、Zipkin 和 AppDash。
服务网格
微服务中的服务网格是处理进程间通信的可配置网络基础设施层。它和通常称为 Sidecar 代理或 Sidecar 网关之的东西很像。它提供了以下功能:
负载均衡
服务发现
健康检查
安全性
Envoy 是专为云原生应用程序设计的流行开源代理。Istio 是一个开放平台,用于连接、管理和保护 Kubernetes 社区中流行的微服务。
原文链接:
https://medium.com/dev-genius/microservice-architecture-communication-design-patterns-70b37beec294




