
业务背景
橙联股份是一家服务全球跨境电商的科技公司,致力于通过市场分析、系统研发及资源整合,为客户提供物流、金融、大数据等多方面的服务产品,为全球跨境电商提供高品质、全方位的服务解决方案。
随着公司业务的发展和数据的不断增长,早期基于 MySQL 的传统数仓架构已经无法应对公司数据的快速增长。业务的需求和运营的决策对于数据时效性的要求越来越高,对数仓准实时能力的需求越发强烈。
为了适应快速的增长需求,橙联于 2022 年正式引入 Apache Doris,以 Apache Doris 为核心构建了新的数仓架构,构建过程中对服务稳定性、查询稳定性、数据同步等多方面进行了优化,同时建立了以 Apache Doris 为核心的数据中台,在这一过程中积累了诸多使用及优化经验,在此分享给大家。
数仓架构演进
早期数仓架构
公司在成⽴初期业务量不⼤,数据团队规模⽐较⼩,对数据的需求仅局限于少量 T + 1 定制化报表需求。因此,早期数仓架构十分简单,如下图所示,直接使用 MySQL 构建数仓集市层,使用数仓集市层的数据进行报表开发,基于商业化的报表平台向需求方提供 T + 1 的数据报表服务。
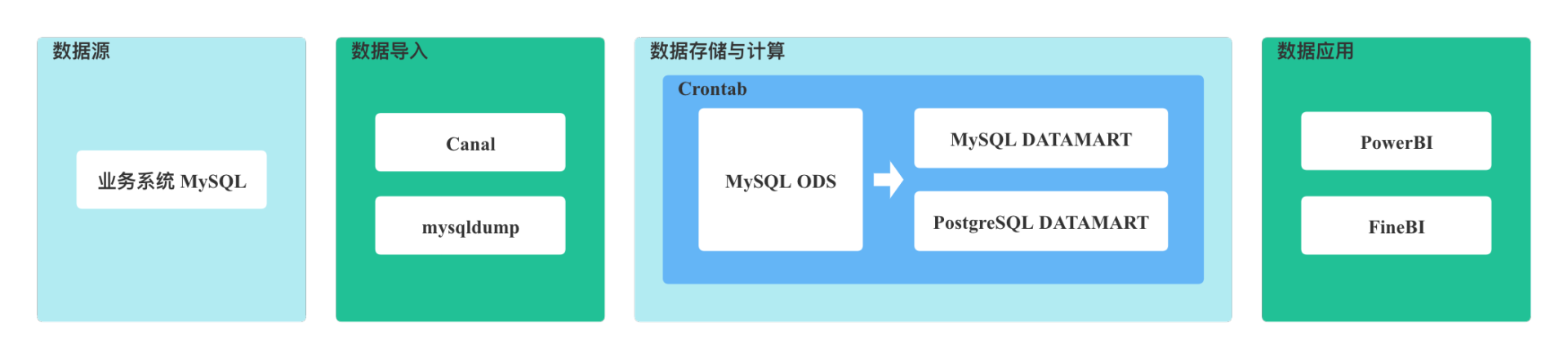
存在的问题
随着公司业务规模扩大、数据量激增以及对数据时效性要求不断提高,使⽤ MySQL 进⾏数据分析越来越不能满⾜业务⽅的要求。
没有对数仓进⾏分层划域,烟囱式的开发模式数据复⽤性很差,开发成本⾼,业务⽅提出的需求不能快速得到响应。对数据的质量和元数据的管理缺乏管控。
新数仓架构
为了解决旧架构日益凸显的问题,适应快速增长的数据和业务需求,今年正式引入 Apache Doris 构建新的数仓架构。
选择 Apache Doris 的原因:
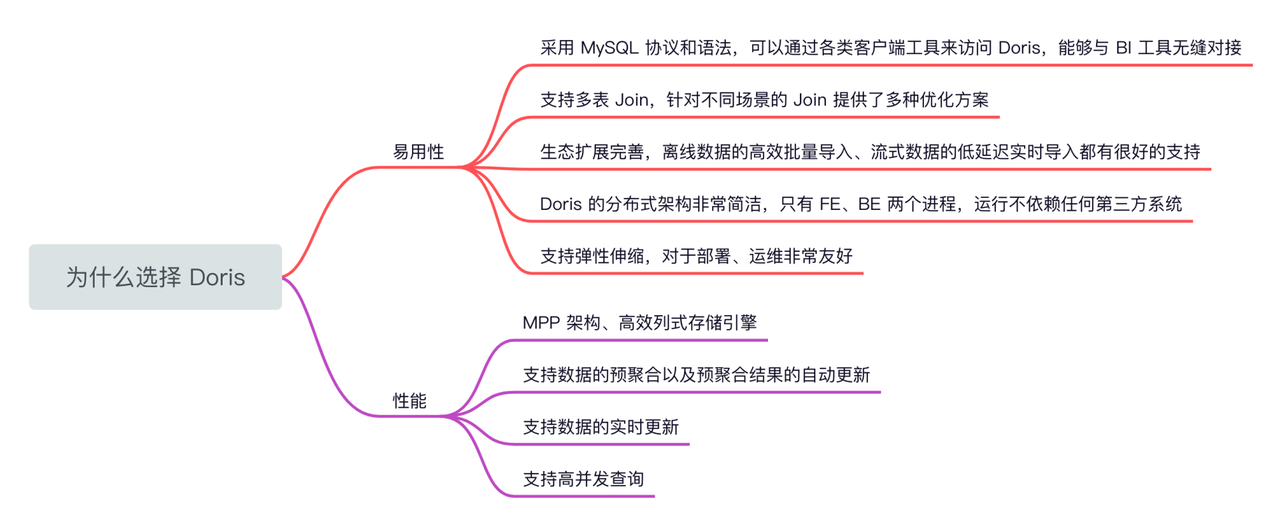
易⽤性 - 在当前应用场景下,引入新技术,将面临大量报表迁移问题,因此必须要考虑的产品易用性问题,而 Apache Doris 在学习成本、报表迁移成本、服务运维成本上有着非常优秀的表现,具体包括:
采⽤ MySQL 协议和语法,⽀持标准 SQL,可以通过各类客户端⼯具来访问 Doris,能够与 BI ⼯具⽆缝对接。
⽀持多表 Join,针对不同场景的 Join 提供了多种优化⽅案。
⽣态扩展完善,离线数据的⾼效批量导⼊、流式数据的低延迟实时导⼊都有很好的⽀持。
相较于业界其他热⻔ OLAP 数据库,Doris 的分布式架构⾮常简洁,只有 FE、BE 两个进程,运⾏不依赖任何第三⽅系统。
⽀持弹性伸缩,对于部署、运维⾮常友好。
性能 - 当前报表存在大量降耦聚合操作,对多表关联的查询性能和实时查询的时效性有着十分高的要求,而 Apache Doris 基于 MPP 架构实现,并自带了⾼效的列式存储引擎,可以支持:
数据的预聚合以及预聚合结果的⾃动更新。
数据的实时更新。
⾼并发查询。
基于以上的原因,最终选择了以 Apache Doris 为核心构建新的数仓。
架构介绍
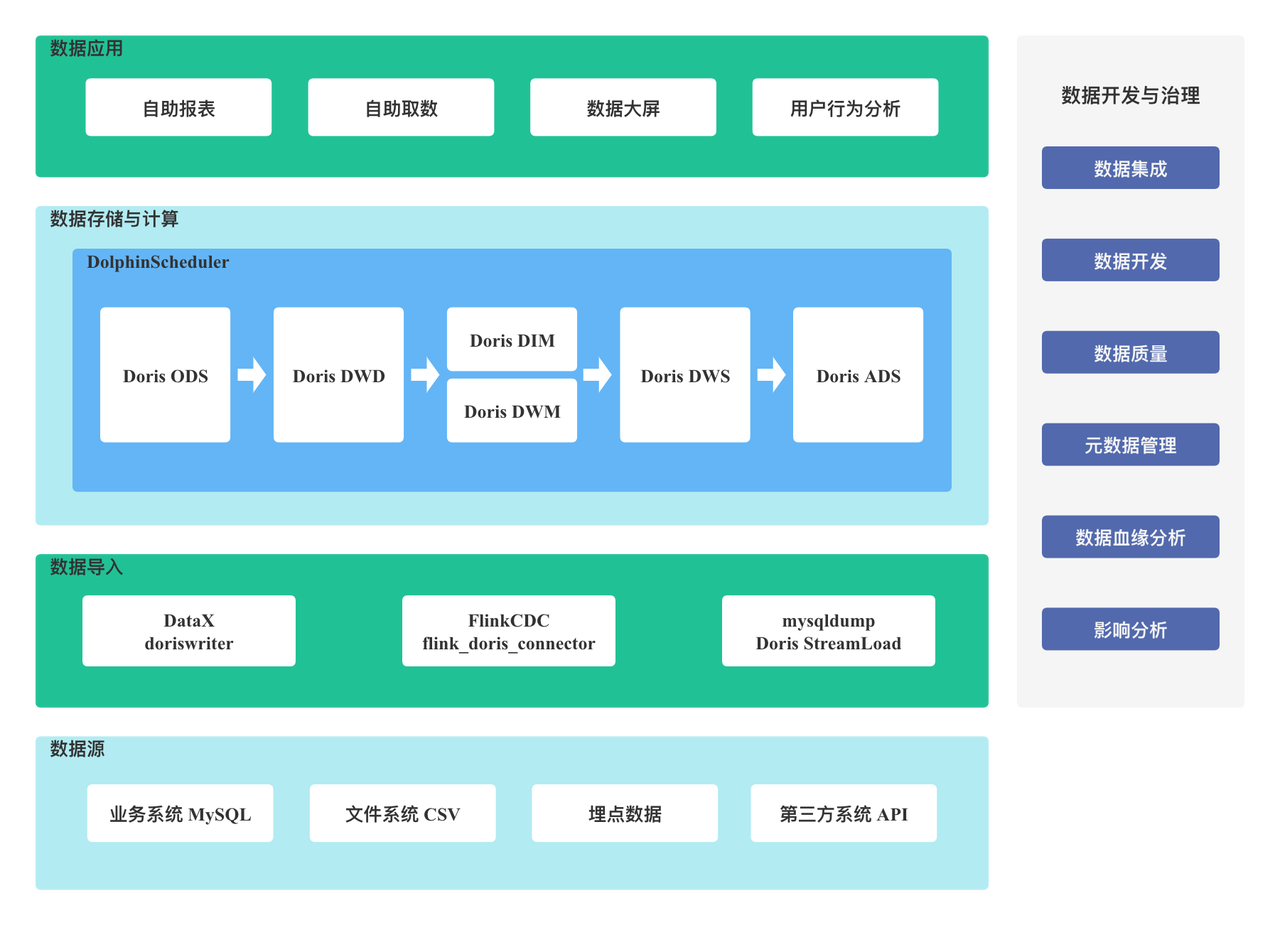
Apache Doris 的数仓架构十分简洁,不依赖 Hadoop 生态组件,构建及运维成本较低。
如以上架构图所示,我们的数据源共有 4 种,业务数据 MySQL、文件系统 CSV、埋点数据和第三方系统 API;针对不同的需求,使用了不同的数据导入方式,文件数据导入使用 Doris Stream Load,离线数据使用 DataX doriswriter 进行数据初始化,实时增量数据使用 Flink CDC + Flink Doris Connector 的方式进行数据同步;数据存储和计算层使用了 Doris ,在分层设计上采用 ODS(Operation Data Store 数据准备区,也称为贴源层)、 明细层 DWD、中间层 DWM、服务层 DWS、应用层 ADS 的分层思想,ODS 之后的分层数据通过 DolphinScheduler 调度 Doris SQL 进行增量和全量的数据更新。最终上层数据应用使用自研的一站式数据服务平台,可以和 Apache Doris 无缝对接,提供自助报表、自助取数、数据大屏、用户行为分析的数据应用服务。
基于 Apache Doris 的数仓架构方案可同时支持离线和准实时应用场景,准实时的 Apache Doris 数仓可以覆盖 80% 以上的业务场景。这套架构大大降低了研发成本,提高了开发效率。
当然在架构构建过程中也遇到一些问题和挑战,我们针对问题进行了相应的优化。
Apache Doris 构建数仓优化方案
在数仓的使用过程中,主要遇到三方面问题。首先是服务稳定性问题,其次是查询速度逐渐变慢的问题,最后是 Doris 数据同步和 Doris SQL 调度问题。具体体现在以下:
服务稳定性
优化前
在 Apache Doris 使用初期,FE 和 BE 的部署方式如下:
FE 负责元数据的管理、用户请求接入、查询的解析规划,资源占用较低,因此将 FE 和其他大数据组件混合部署 FE*3。
BE 负责数据存储、计算、查询计划的执行,资源占用较大,因此 BE 进行独立部署且分配了较多的资源 BE(16C 128G 4T*1)*7。
基于以上方式部署,使用初期运行的稳定性还不错。然而在使用了一段时间之后,这种部署方式暴露的问题就越来越明显。
存在的问题
首先,FE 混合部署存在资源竞争。其他组件与 FE 服务竞争资源,导致 FE 资源不足,服务运行稳定性不好。具体问题表现在:每当机器资源使用率打满,就会导致 FE 节点无法连接,长时间获取不到心跳而被 FE 集群判定为离线。
其次,BE 单磁盘存在 Compaction 效率低的问题。初期,我们在部署 BE 时,每个节点只分配了 1 块 4T 的磁盘,虽然磁盘的空间并不小,但是磁盘的数量比较少,Compaction 线程数只有 2,Compaction 效率很低,这是导致 BE Compaction Score 不健康的原因之⼀。
Compaction 配置参数
compaction_task_num_per_disk 每个磁盘上的任务数,默认为 2
max_compaction_threads Compaction 线程的总数,默认为 10
total_permits_for_compaction_score Compaction 任务配额,默认 10000
Compaction 工作机制:Apache Doris 的数据写⼊模型使⽤了与 LSM-Tree 类似的数据结构。数据以追加(Append)的⽅式写⼊磁盘,在读逻辑中,需要通过 Merge-on-Read 合并处理写入的数据。Merge-on-Read 会影响读取的效率,为了降低数据读取时需要合并的数据量,使⽤ LSM-Tree 的系统会引⼊后台数据合并逻辑,以⼀定策略定期的对数据进⾏合并。
优化后
为了解决以上的问题,对部署方式进行了优化以提升服务的稳定性:
FE 进行独⽴部署,避免了 FE 混合部署资源竞争问题
BE 进行磁盘拆分,多磁盘部署,从原来一块 4T 磁盘变更为 5 块 1T 磁盘,使 BE Compaction 线程数提升 5 倍,Compaction 效率、磁盘 I/O 带宽也得到了提升
增加客户端连接代理层 ProxySQL,对 FE 连接进⾏负载均衡,解决 FE 连接单点问题
增加 Supervisor 对 FE、BE 服务进程状态监控,FE、BE 进程意外宕机可以快速恢复
经过以上对部署的优化,Apache Doris 服务的稳定性有了很大的提升,基本可以满足目前对稳定性的需求。
查询稳定性
初期刚部署时,无论进行数据导入还是数据查询,执行起来都比较顺畅。但随着承载的表和数据导入作业数量不断增多,查询稳定性问题逐渐暴露出来。
优化前
存在的问题
随着使用时间和数据量的增加,集群开始频繁出现不可用的问题,主要体现在以下几个方面:
DDL 操作很难执行,查询速度变得比较缓慢
FE 服务频繁出现 OOM 宕机,有时候甚至出现无法连接的情况
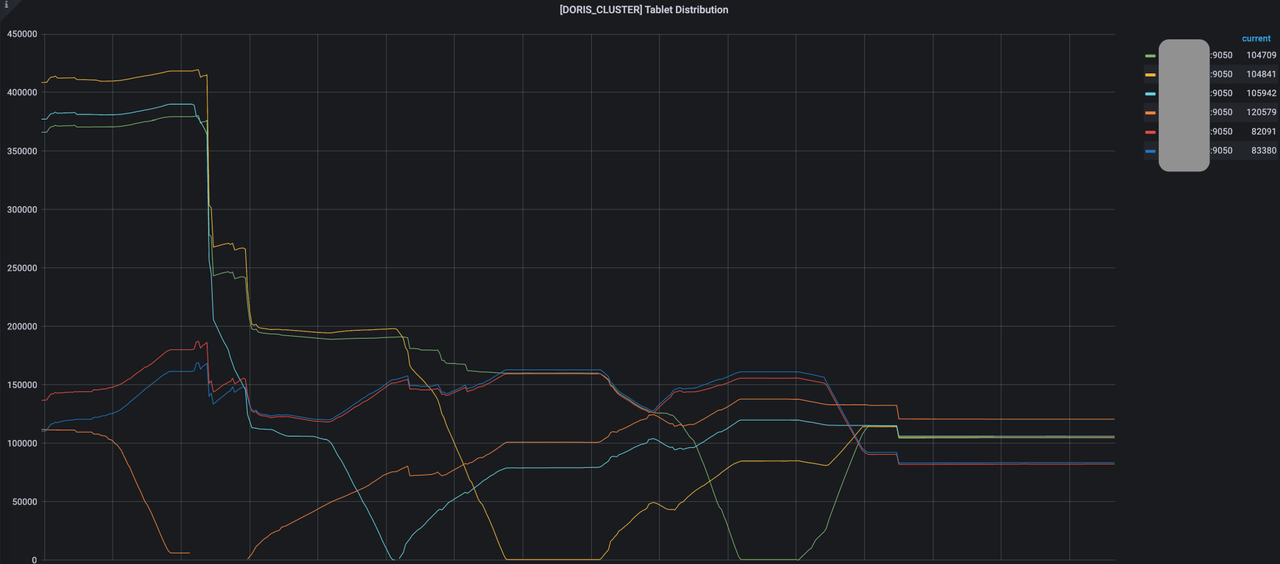
下图是生产环境某张表的体积的大小和 Tablet 数量的情况。这张表的体积只有 275M,但是 Tablet 的数量却达到了 7410,这非常不合理。进一步排查确认整个集群 Tablet 数量非常庞大,集群只有 5T 的数据量,然而 Tablet 数量达到 150 万。

最初我们对 Apache Doris 表数据量大小、分区粒度、Bucket 数量、Tablet 数量的关系及 Tablet 数量对集群的影响没有清晰的概念。开发人员在 Apache Doris 使用中更多的是追求查询速度,将大部分的动态分区表的分区粒度设置的比较小,分区 Bucket 数量设置却比较大。
经过与 Apache Doris 社区小伙伴的沟通交流,了解到 Tablet 数量过大可能会导致元数据管理和运维压力增大,出现查询速度缓慢、FE 不稳定的问题。
优化方案
首先明确 Tablet 数量的计算方式,Tablet 数量 = 分区数量 * Bucket 数量 * 副本数。结合当前实际使用情况,确认可以在分区粒度和 Bucket 数量上进⾏优化。我们将分区的粒度从按天、按周分区更改为按月分区,Bucket 数量按照数据体积大小进行合理的配置。如下图所示,是建议数据体积大小对应的 Bucket 数量设定。
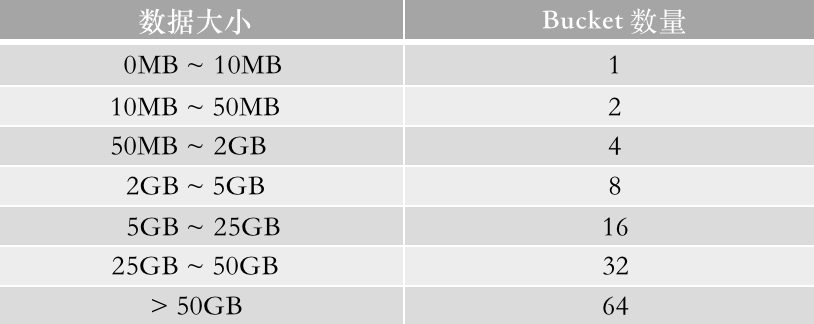
本次的优化目标是将 Tablet 数量从 150 万降低到 15 万,同时我们也对未来的增长速度进行了规划,在三副本情况下,期望 Tablet 数量增长速度是 30000/TB。
优化后
实际上,在仅对 ODS 表进⾏了分区粒度和 Bucket 数量调整后,集群 Tablet 数量从 150 万下降到了 50 万,效果显著。
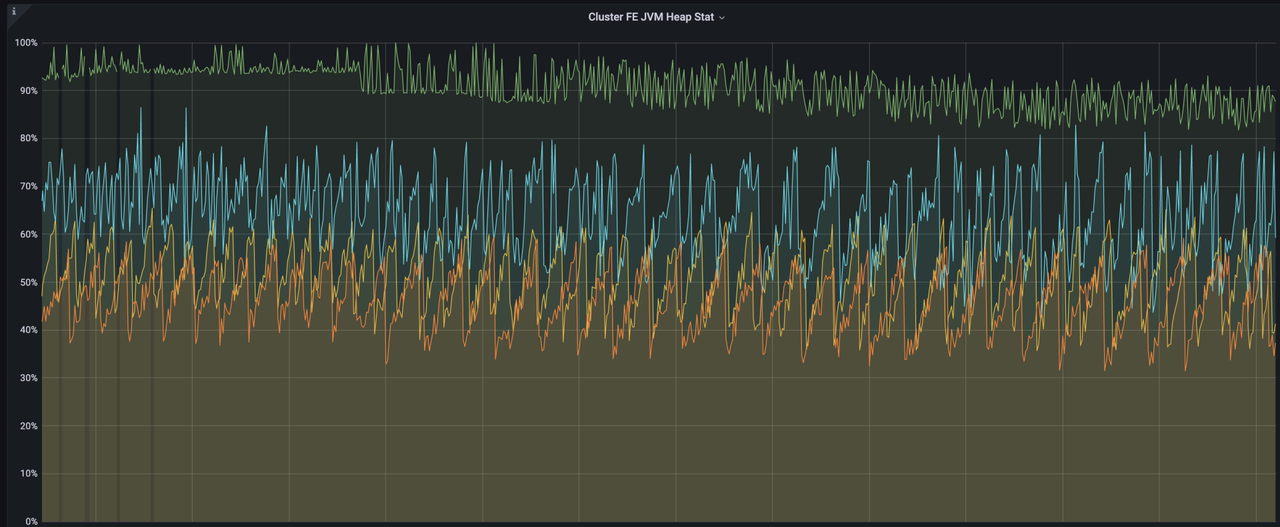
优化前的 FE
下图是 FE JVM Heap Stat 的监控情况,每当 FE 执行 Checkpoint 时,元数据就会在内存中复制一份。体现在 FE JVM Heap Stat 上就是形成一个个的波峰。优化之前 FE 对内存占用几乎持续在 90% 以上,而且每一个波峰都非常的尖锐。
优化后的 FE
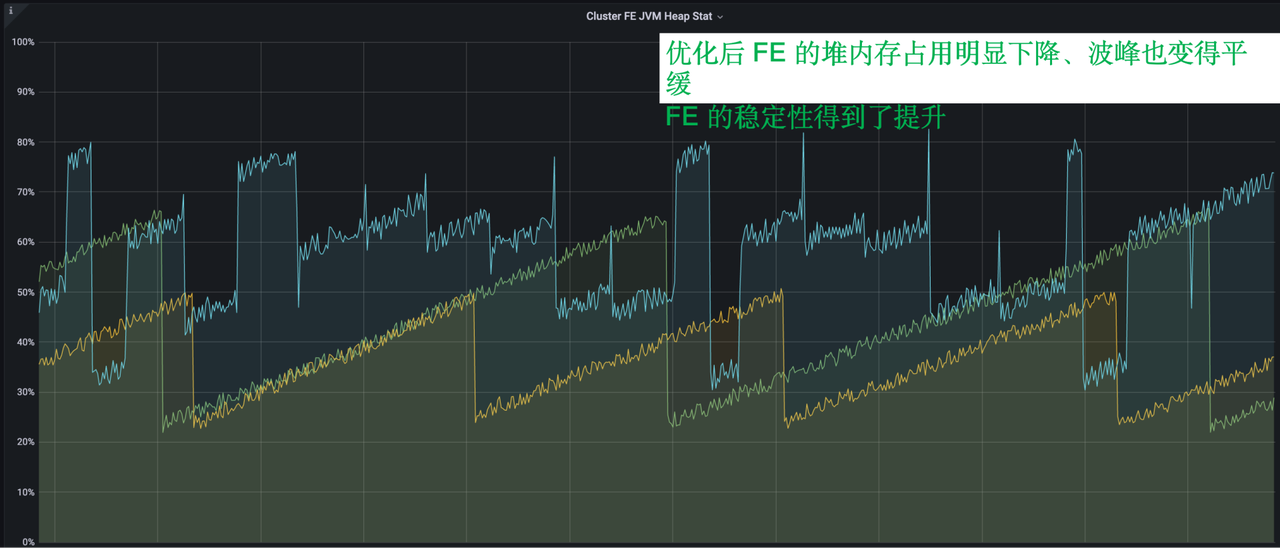
优化后,FE 堆内存占用明显下降,波峰也变得很平缓。FE 的稳定性得到了比较明显的提升。
优化前、后的 BE
BE Compaction Score 监控反映版本的堆积情况,版本堆积的数值在 100 内属于正常范围,超过 100 说明集群可能存在潜在风险。上文也讲到,查询时需要先进行文件合并,再进行数据查询,如果 Tablet 版本过多,版本合并会影响到查询的速度和稳定性。
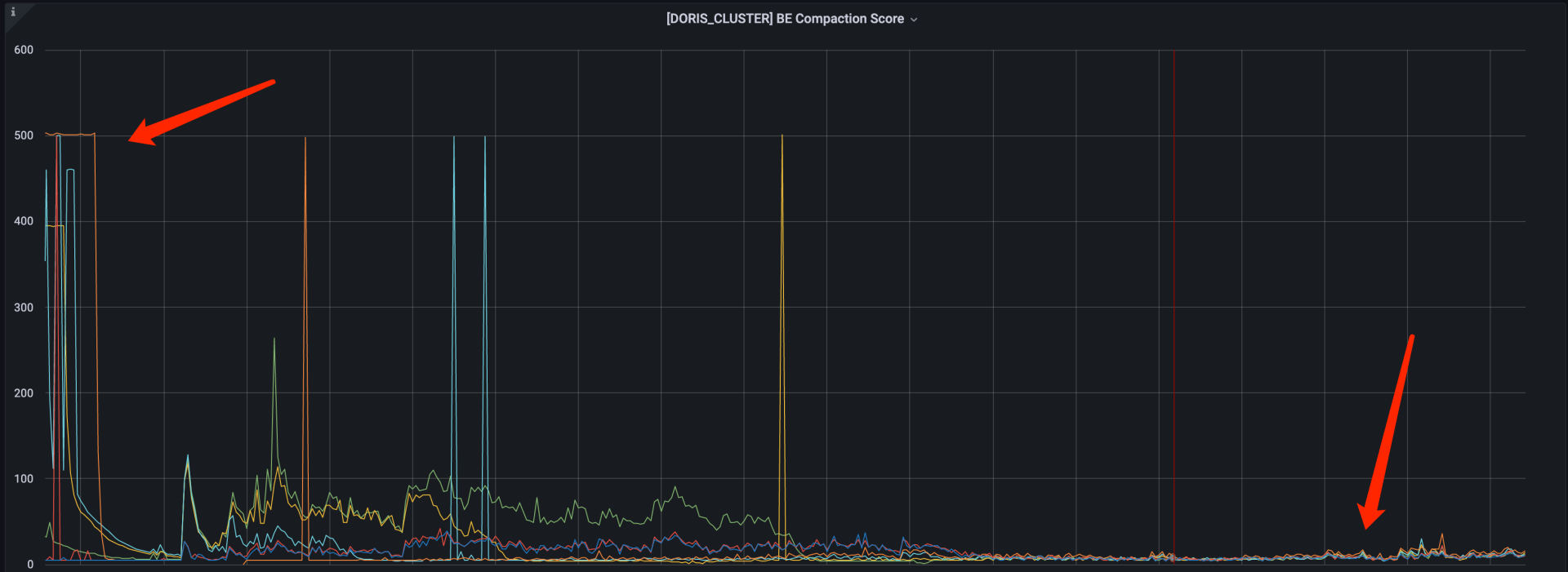
经过磁盘的部署优化和 Tablet 优化后,BE Compaction Score 可以稳定在 50 以内,查询的稳定性和性能都得到了非常大的提升。
数据同步优化
优化前:
MySQL 数据同步使用 Flink CDC -> Kafka -> Flink Doris Connector -> Doris 的方式全量 + 增量进入 Apache Doris。
在这个方案中,虽然 Flink CDC 支持全量历史数据的初始化,但由于历史遗留问题,部分表数据量较大,单表有几亿数据,而且这种表大多是没有设置任何分区和索引,在执行简单的 COUNT 查询时都需要花费十几分钟的时间。
其次,Flink CDC 虽然可以进行增量数据同步,但对于这类表的全量数据初始化几乎是不能实现的,因为 Flink CDC 做全量同步要先读取全量数据,然后对数据分块,再做数据同步,这种情况下,读取是非常非常缓慢的。
优化后
针对这种情况,在数据同步上,我们做了以下优化:
全量同步使用 MySQL Dump -> CSV -> Doris Stream Load -> Doris
增量同步使用 Flink CDC -> Kafka -> Flink Doris Connector -> Doris
数据调度优化
我们在使用 DolphinScheduler 进行 Doris SQL 的任务调度时,同一 node 下配置多条 SQL 时会出现 node 执行状态异常的情况,导致工作流 DAG 的 node 依赖失效,前一个节点未执行完,后一个节点就开始执行,结果会有缺数据甚至没有数据的情况。这个问题是因为 DolphinScheduler 2.x 在同一个 node 下不支持按顺序执行 MySQL 的多段 SQL,而 Doris 在 DolphinScheduler 中使用 MySQL 数据源创建连接。
此问题在 DolphinScheduler 3.0.0 版本被修复,配置中可以设置多段 SQL 的分隔符,解决了 DAG 依赖关系失效的问题。
Apache Doris 元数据管理和数据血缘实现方案
在没有元数据管理和数据血缘之前,我们经常会遇到一些问题,比如想找一个指标,却不知道指标在哪张表,只能找相关开发人员来确认,当然也存在开发人员忘记指标的位置和逻辑的情况。因此只能通过层层筛选确认,此过程十分耗费时间。
之前我们将表的分层划域、指标口径、负责人等信息放在 Excel 表中,这种维护方式很难保证其完整性,维护起来也比较困难。当需要对数仓进行优化时,无法确认哪些表是可以复用的、哪些表是可以合并的。当需要对表结构进行变更时,或者需要对指标的逻辑进行修改时,也无法确定变更是否会对下游的报表产生影响。
在以上问题背景下,我们经常遭到用户的投诉,接下来介绍如何通过元数据管理和数据血缘分析方案来解决这些问题。
实现方案
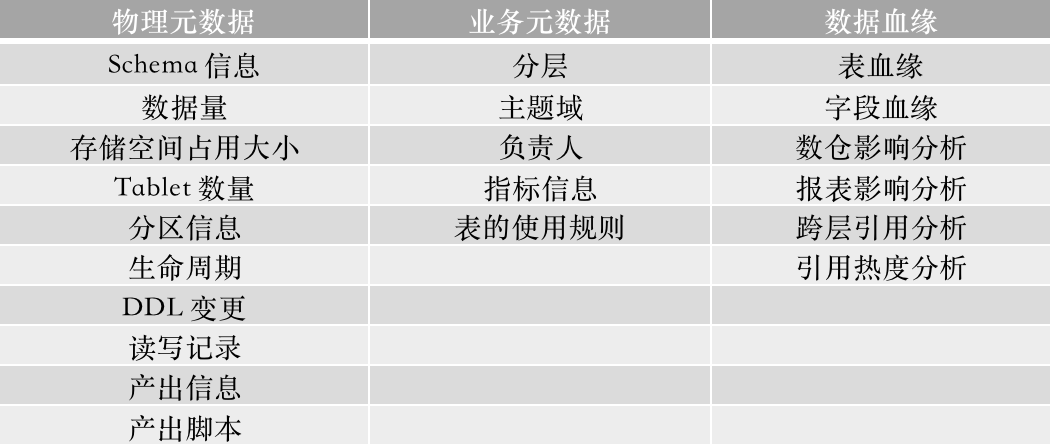
元数据管理和数据血缘是围绕 Apache Doris 展开,同时对 DolphinScheduler 的元数据进行了整合。
我们将元数据分为物理元数据和业务元数据两大类:
物理元数据维护表的属性信息和调度信息
业务元数据维护数据在应用过程中约定的口径和规范信息
数据血缘实现了表级血缘和字段级血缘:
表级血缘支持粗粒度表关系和跨层引用分析
字段级血缘支持细粒度的影响分析
上图中,右侧表格是物理元数据业务,元数据指标和血缘分析能够提供的数据服务。
接下来,一起看下元数据管理和数据血缘的架构和工作原理。
架构介绍
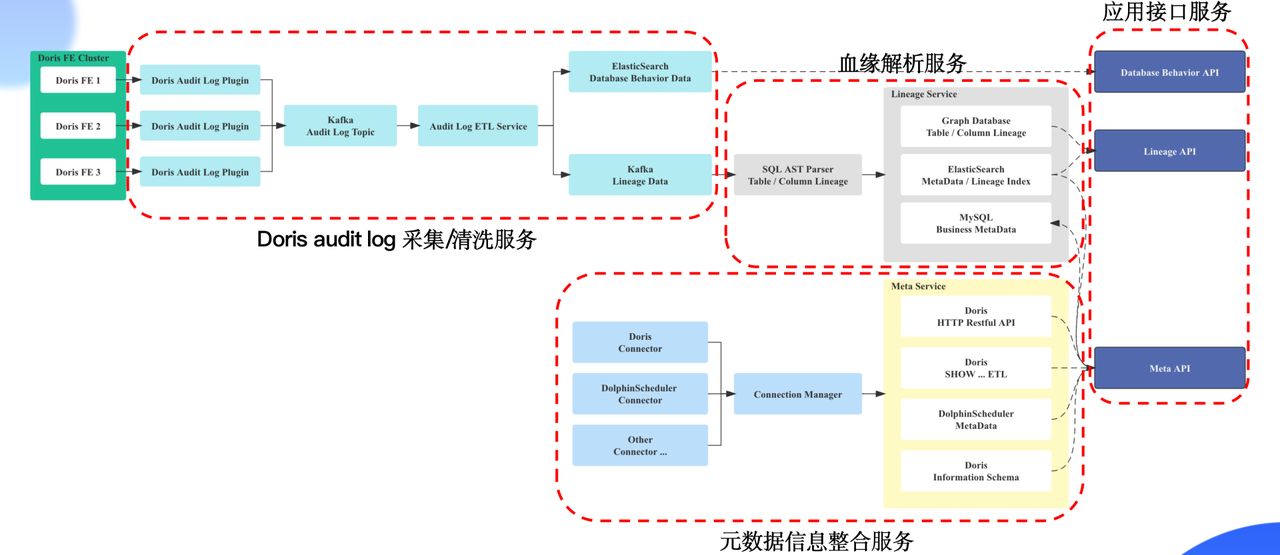
元数据管理和数据血缘实现方案技术栈
数据采集:使用 Apache Doris 提供的审计日志插件 Doris Audit Plugin 进行数据采集
数据存储:对审计日志插件做了定制化开发,使用 Kafka 存储 Doris 审计日志数据
血缘解析:使用 Druid 进行 Doris SQL 解析
血缘关系存储:使用 Nebula Graph 存储血缘关系数据
业务元数据:因为业务元数据经常发生 CRUD,因此使用 MySQL 存储业务元数据信息
搜索数据:使用 ElasticSearch 存储血缘关系查询索引以及表和字段的搜索索引数据
接下来介绍一下个架构四个组成部分:审计日志的采集和清洗服务、血缘解析服务、元数据信息整合服务、应用接口服务。
Apache Doris 审计日志的采集/清洗服务
考虑到如果将数据清洗逻辑放在审计日志插件中,当数据清洗逻辑发生变更,可能会出现数据遗漏,这样会对血缘分析和元数据管理产生影响,所以我们将审计日志插件数据采集和数据清洗进行了解耦,对 Apache Doris 的审计日志插件进行了改造,改造后审计日志插件可以实现审计日志数据的格式化以及将数据发送到 Kafka 的功能。
数据清洗服务,首先在清洗逻辑中增加数据重排逻辑,针对多个审计日志插件发送的数据进行重新排序,解决数据乱序的问题。其次把非标准 SQL 转化成标准 SQL,虽然 Apache Doris 支持 MySQL 协议以及标准 SQL 语法,但有一些建表语句、SQL 查询语法与标准 SQL 存在一定差异,因此将非标准 SQL 转化为 MySQL 的标准语句,最后将数据发送到 ES 和 Kafka 中。
血缘解析服务
血缘解析服务使用 Druid 进行 Doris SQL 的解析,通过 Druid 抽象语法树逐层递归获取表和字段的血缘关系,最后将血缘关系数据封装发送到图数据库、血缘查询索引发送到 ES 。进行血缘解析的同时会将物理元数据和业务元数据发送到对应存储位置。
元数据信息整合服务
元数据信息整合服务借鉴了 Metacat 的架构实现方案。
Connector Manager 负责创建 Apache Doris 和 DolphinScheduler 的元数据链接,同时也支持后续其他类型数据源接入的扩展。
Meta Service 负责元数据信息获取的具体实现。Apache Doris 元数据信息主要从 information Schema 库、Restful API、以及 SHOW SQL 的查询结果三种途径来获取。DolphinScheduler 的工作流元数据信息和调度记录信息从 DolphinScheduler 元数据库获取。
应用接口服务
我们提供了 3 种类型的应用接口服务,分别是血缘应用接口服务、元数据应用接口服务和数据行为分析应用接口服务。
血缘应用接口服务提供表、字段、血缘关系、影响分析的查询服务。
元数据应用接口服务提供元数据的查询和字段搜索的服务。
数据行为分析应用接口服务提供表结构变更记录、数据读写记录、产出信息的查询服务。
以上就是元数据管理和数据血缘分析架构的整体方案的全部内容介绍。
总结及收益
今年我们完成了以 Apache Doris 为核心的准实时数仓建设,Apache Doris 经过半年的使用和优化,现在已经趋于稳定,能够满足我们生产的要求。
新的准实时数仓,对数据计算效率、数据时效的提升是巨大的。
以 On Time Delivery 业务场景报表计算为例,计算 1000w 单轨迹节点时效变化,使用 Apache Doris 之前需要计算 2 个多小时,并且计算消耗的资源非常大,只能在空闲时段进行错峰计算;使用 Apache Doris 之后,只需要 3min 就可以完成计算,之前每周更新一次的全链路物流时效报表,现在可以做到每 10 分钟更新最新的数据,达到了准实时的数据时效。
得益于 Apache Doris 的标准化 SQL,上手难度小,学习成本低,报表的迁移工作全员都可以参与。
原来报表使用 PowerBI 进行开发,需要对 PowerBI 有非常深入的了解,学习成本很高,开发周期也很长,而且 PowerBI 不使用标准 SQL,代码可读性差;现在基于 Doris SQL 加上自研的拖拉拽形式的报表平台,报表的开发成本直线下降,大部分需求的开发周期从周下降到了天。
未来规划
后续我们也将继续推进基于 Apache Doris 的数据中台建设,对元数据管理的完善、数据血缘的解析率持续进行优化,考虑到数据血缘是大家都渴望的应用,在未来血缘解析成熟后,我们会考虑将其贡献给社区。
与此同时,我们正在着手进行用户行为分析平台的构建,也在考虑使用 Apache Doris 作为核心的存储和计算引擎。目前 Apache Doris 在部分分析场景支持的函数还不够丰富,例如在有序窗口漏斗分析场景,虽然 Apache Doris 已经支持了 window_funnel 函数,但是每层漏斗转化的计算需要用到的 Array 相关计算函数还没有得到很好的支持。不过好在即将发布的 Apache Doris 1.2 版本将包含了 Array 类型以及相关函数,相信未来在越来越多的分析场景中 Apache Doris 都将得到落地。
作者介绍
付帅,橙联(中国)有限公司数字化团队,大数据研发经理,负责数字化团队数据中台的研发以及 OLAP 引擎的应用落地及性能优化。




