
今天的内容分享将主要包含以下四个方面:
介绍京东到家的订单履约业务背景
在业务背景的基础上说明订单的底层存储方案
基于存储方案的数据异构设计与实践
面向复杂度的架构设计方法论
简单来看,面向复杂度的架构设计方法论与上面 3 个部分没有直接关系,把这部分内容放到文章中来讲,主要是因为数据异构本质上也是解决了软件的写入复杂度问题。在这个基础上,我们向上抽象一层,来讨论一下面向复杂度的架构设计方法论。
一、京东到家订单履约业务背景
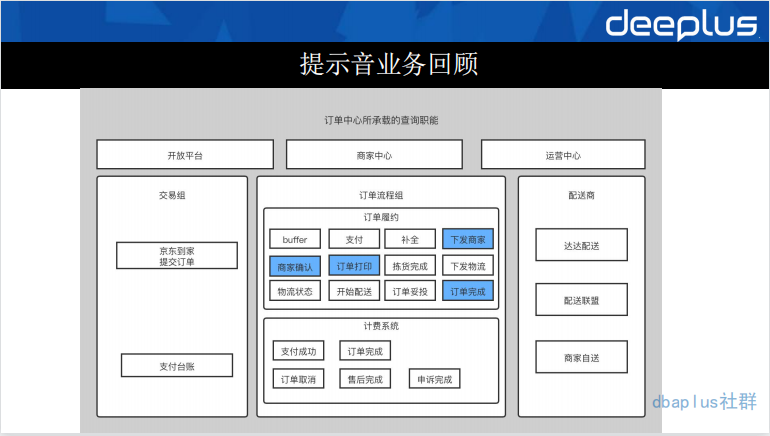
从用户提交订单到服务履约系统,我们大致经历了支付、下发商家、商家确认、订单打印、拣货、下发物流、配送、妥投等环节。这是一个基本的新零售履约流程。这里,我标蓝了一些流程。比如:下发商家、订单打印等环节。主要是因为这些环节是我们要和商家交互的功能点,当我们把订单下发给商家时,首当其冲的环节是商家要确认这个订单,并且开始履约流程。但是,在我们的实际业务中,商家在大促期间往往会出现履约瓶颈,忙到看不到我们下发的订单,甚至不忙的时候也会看不到我们的订单已经下发到他们的系统中,商家需要一个提示功能。这也就是我们的提示音需求。
提示音需求需要不断的查询底层存储 ES,并提示给商家有订单到达了,需要他们去履约,如果商家没有看到,就不断查询,不断提示。就是这样的一个循环查询量级,在大促期间,订单量级增大,查询量级增大。基本上每次大促都会把我们的 ES 查到 CPU 飙高,甚至出现不可用的情况。为了保护履约系统,我们做的临时方案是做一个功能开关,在大促期间对提示音功能降级。可是这样的降级并不是我们想要的。因为最终商家还是收不到提示。导致履约质量下降。于是我们就面临一个问题“存储组件无法支撑大促时提示音业务的查询请求量。
二、底层数据源的职责分工
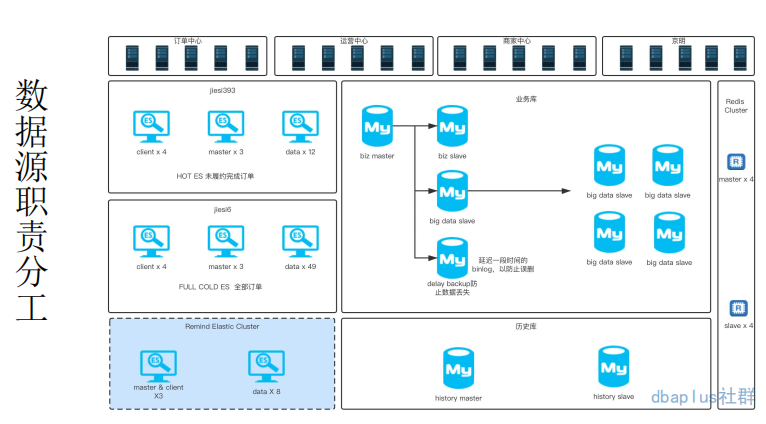
要解决我们面临的查询量级问题,就必须首先分析一下底层的存储方案。以上,是我对到家订单履约系统底层存储的一个整体概括。
1.Redis
Redis 在履约系统中主要承载的一个职责是 worker 跑批任务的存储和查询。因我们在系统中大量运用了跑批任务来实现最终一致性的一个设计,而 Redis 的 Zset 结构正好满足了这样的需求,将时间作为分值,不断的提供近期任务的查询是 Redis 充当的根本职能。这里解释一下 Redis 为什么没有承载过多的查询职能。Redis 虽然性能更好一些,但是,在数据量和查询复杂度上,没有 ES 支持的好,关键点是我们的查询条件复杂度是比较高的,所以,Redis 没有承载过多的查询职能。
2.MySQL
MySQL 在履约系统存储中的职能是持久化存储订单数据,这里主要还是使用其强大的事务机制,以保障我们的数据是正确写入的。这是其他的两个组件所不支持的。
从履约流程上来看,我们将数据做了冷热分离,热点数据是我们在履约中的订单(也就是未完成的订单),而完成的订单,由于其使用率不会太高,所以,我们称之为冷数据。这样的一个拆分也就是上图中对应的业务库和历史库。业务库是热库,而历史库则是冷库。这样的一个冷热分离思想,使我们的单库单表数据量级维持在千万级别。从而避免了对应的分库分表复杂度。
从部署架构上看,我们对业务库进行了大量的主从分割。其中 biz slave 是我们的业务库从库,它也会承载一些履约中的订单查询职能。接下来的 big data slave 集群则是大数据抽数据用做统计分析。最后的 delay slave 设置延迟一定时间消费 binlog 则是为了防止 master 被误操作而兜底的。比如有人错误执行了删除 db 的命令,这样的一个延迟消费的机制就可以利用 binlog 进行兜底回滚。
3.Elasticsearch
ES 在数据存储中承担了几乎所有的查询职责,这主要取决于它支持复杂查询,并有天然分布式的特点。在数据量复杂度解决方案上,避免了 MySQL 分库分表的复杂度。这里我们一共有 3 个 ES 集群。其中 HOT ES 和 Full ES 也是进行了冷热分离,这样对我们的查询流量进行拆分。有助于保证履约系统的稳定性。
而第三套集群 Remind Elastic Cluster 则是为了解决我们上述提示音的问题。在有提示音集群之前,我们所有的提示音查询流量都是打到热集群的。也正是这样的一个访问量需求,导致了我们的热集群时有发生 CPU 飙高,接口响应缓慢,卡顿业务线程。所以,我们对热集群进行了进一步的拆分,于是就正式提出了提示音单独集群的方案。
三、写入复杂度问题
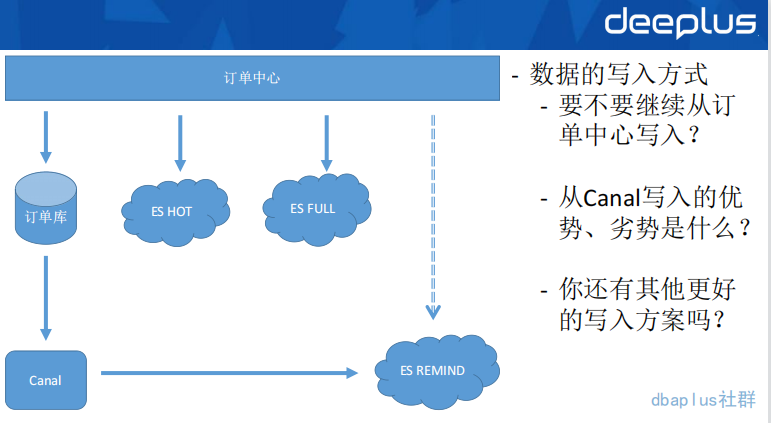
当确定冗余一套提示音集群以后,我们面临的问题就是上述这样的一个写入复杂度问题,从图上来看,我们在拆分这套集群之前,订单中心每次操作一次订单写入。面临的是 3 个数据源的写入工作,这对研发人员是非常不友好的,维护难度过大。于是,我们就开始考虑用异构中间件的方式来去写入这套 ES 数据。
异构中间件的优势是屏蔽了数据同步的复杂度,但是随之而来的是数据写入链路可靠性、及时性等问题。而且,数据传输本身一般都具有高可用的需求,之前高可用在业务应用上,因为业务应用的集群方式本身是计算高可用的。但异构中间件则要在这高可用、可靠性、及时性三个维度上满足我们的要求。
四、数据异构产品选型
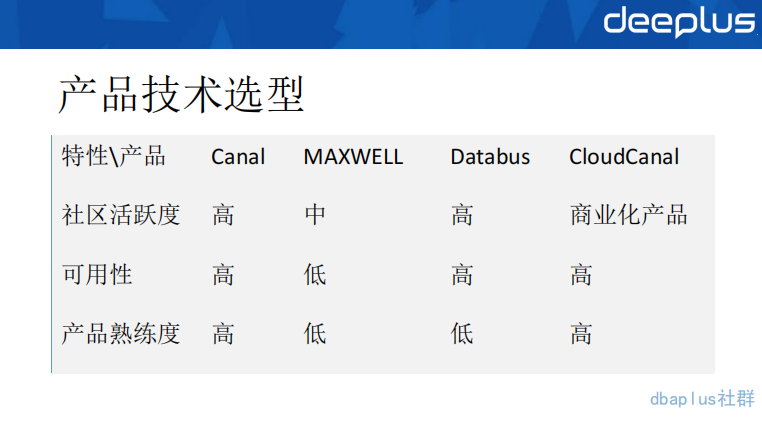
在上述分析之后,我们也陆续调研了一些异构产品,在数据类型支撑上没有太大差别,常用的存储组件,这些异构中间件都是支持的。所以,我们更在意以上 3 个指标。社区活跃度代表了后续的维护性以及开源产品快速的问题响应,可用性方面的需求是非常强烈的,最终采用 Canal 的根本原因还是在学习成本和熟练度上。
五、Canal 简介
这里简单说一下我对于 Canal 的理解,以便于后续有意向应用 Canal 的同学有一个简单的了解。
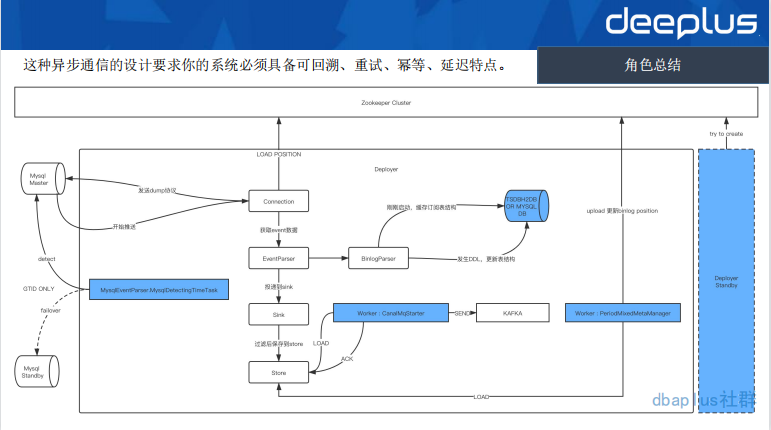
Step1 Load&Store: Connection 从 Zookeeper 获取到当前消费的 binlog filename 和 position 信息。随后将该信息附带到 dump 协议里,mysql master 开始推送 binlog 数据。Binlog 经过 Parser 解析投递到 Sink,Sink 则承载了过滤消息的作用,过滤掉没有订阅的 binlog 事件,最终把消息存储到 Store 中。
Step2:Send&Ack:用任务 worker 的方式,不断扫描 store,最终将 store 中的数据发送到目的地,目的地可以是具体的存储,也可以是 mq 产品。图中,我用了 kafka 也主要是因为我们的实践方案。投递消息完成之后将消息 ACK 给 Store 组件。
Step3:Update MetaInfo:这个时候数据虽然发送了。但是,我们的元信息 binlog 的 filename 和 position 仍然没有更新,在这个操作上,Canal 仍然采取了异步的方式去同步该信息。
Canal 这种异步通信的设计要求你的系统必须具备可回溯、重试、幂等、延迟特点。
以上,是我对整个 Canal 的一个理解,图中的两个 HA,后续将会和大家说到。这里,我讲 Canal 的工作的角色、运作规则都是从一个 4R 视角来说明的,这是为了后续来讲复杂度方法论的时候大家也好理解一些。
六、提示音功能基于 Canal 数据异构实践
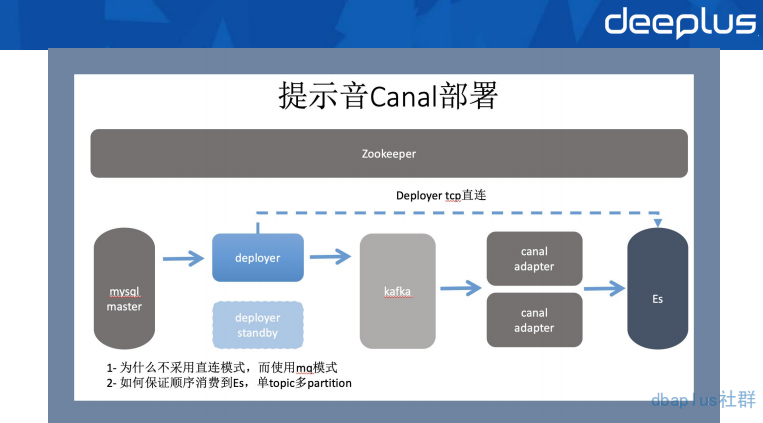
提示音异构生产部署方式如上图。我们部署了两台 Deployer 用于数据传输的高可用。同时把消息投递到了 kafka,利用 adapter 的集群部署进行批量消费,插入到提示音集群的 ES 中。
在顺序性保障上采用了订单 id hash 的策略,保证在 partition 上是有序的。这样也就保证了在业务操作上是整体有序的。
在链路上采用 kafka 来传输,主要还是应对大促期间 binlog 数据量级的特点,保证插入到 ES 之前有缓冲 buffer 的一个作用。这也是直连方式的弱点,直连方式在大数据量短时间写入时,对目的地存储组件有可能会造成瞬间的大量插入,从而损耗目的地存储组件的资源,可能影响到业务使用。但是,长链路也有数据延迟的缺点,如果对数据时效要求比较高的业务。还是建议用直连方式来搭建对应的异构方案。
在 META Manager 上使用 Zookeeper 来存储,与 Deployer 的 HA 形成有效配合。
问题一:(网络环境问题)kafka 不可用
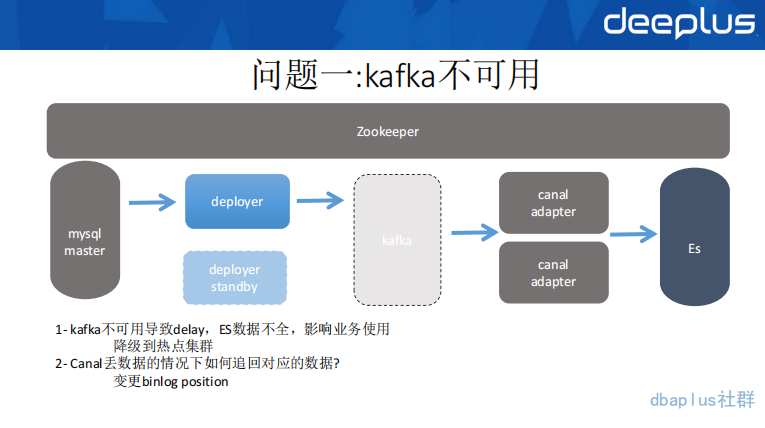
在实践中,我们遇到第一个比较有代表性的问题是 kafka 集群不可用,直接导致 ES 数据断层,从而影响到商家的履约体验。
首先,kafka 集群所在的网络环境和机器主机发生问题,deployer 的 store 数据存满,直接导致 delay 了 8 个小时。提示音没有提示,也会有电脑端的管理系统同步订单,但是需要人工刷新,所以,过了很久我们才发现这样一个问题。紧急把访问切到之前的 ES 热集群,之后,我们重新把 kafka 服务部署到可用状态,数据虽然慢慢追上了,但是原来在 kafka 中没有被 adapter 消费的一部分数据却丢掉了,这主要还是因为设置的 kafka 落盘频率问题。
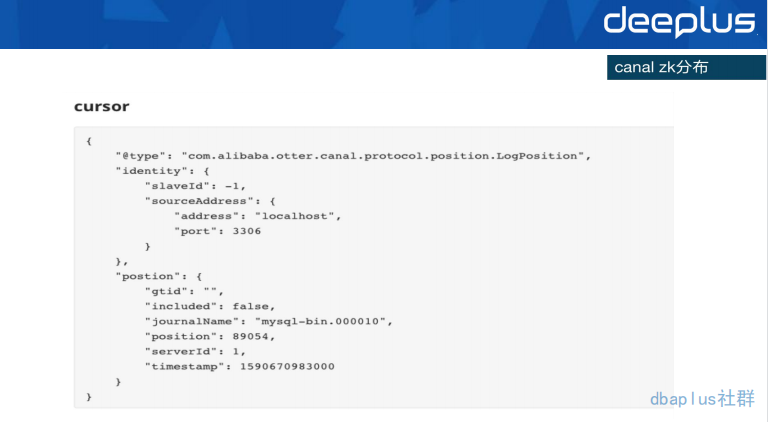
丢数据在数据异构的需求中是不可容忍的事情,索性这次事故基本上锁定了丢数据的原因,所以,我们将 Zookeeper 中的 jouralName 和 position 设置到对应的事故之前的位置,将数据重新跑到 ES 中,至此问题解决。
总结一
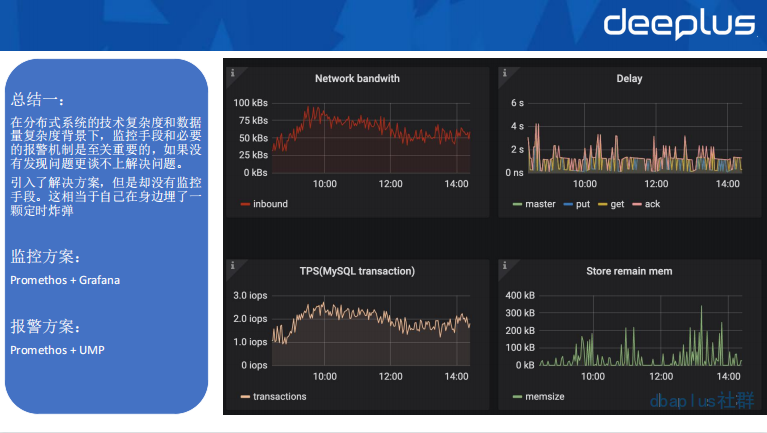
总结二

至此,总结以上两点,数据异构的实践在问题监控、报警、及时降级方面是非常重要的。希望这样的总结经验能够让大家少走弯路。
问题二:Deployer 故障,自动 HA
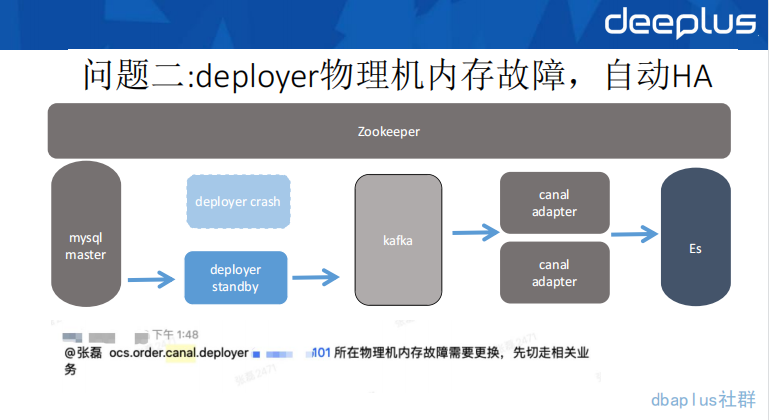
Deployer 机器发生故障,系统自动 HA 到备机,任务得以继续消费。总起来说,问题二并没有给我们的业务带来任何的损耗,但是,还是比较经典的一个案例。这主要反应出来,对于数据异构这样一个需求。它的链路上所有环节,基本上都是有高可用的要求的。

Canal 一共提供两种 HA,其中 Deployer 的 HA 是靠 Zookeeper 的临时节点和重试机制实现的,而 Mysql 的 HA 则是靠一个单独的线程不断的 Detect 来实现的。
但是 MySQL 的 HA,只能用 GTID 的模式,这是因为 Mysql master 和 slave 的 binlogfile name、position 是不一样的。如果用 master 的 binlogfilename 和 position 去 slave 发送 dump 协议,这会出现无法匹配的问题。但是 GTID 是全局有序的,这也就保证了 Mysql 的 HA 只在 GTID 模式下才可用。
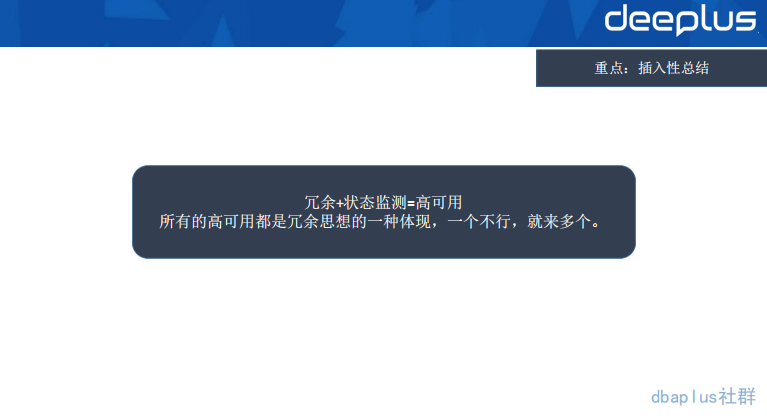
谈到高可用,提出上述总结。这里我与大家互动了一个问题:“单机器部署两台 Canal 实例是否算是高可用?”答案是:“不算高可用,原因是单机部署了两台 Deployer,但是机器如果故障,两台 Deployer 均不可用。”
问题比较有代表性,也有一些同学掉进了坑里。这里我与大家一起回顾一下高可用的范围:多机器、多机房、多地区、多国家。范围越大,高可用自然越是稳定。但是带来的成本和数据传输要求也越高,一般都是根据业务量级和重要程序进行取舍的。
总结三
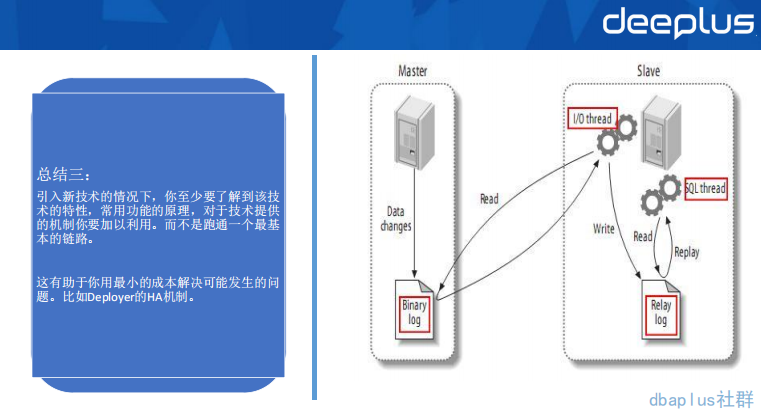
以上就是我在数据异构中的一些经验教训。下面我们将问题向上抽象,聊一聊面向复杂度的架构设计方法论。
七、面向复杂度的架构设计方法论
1.4R 模型
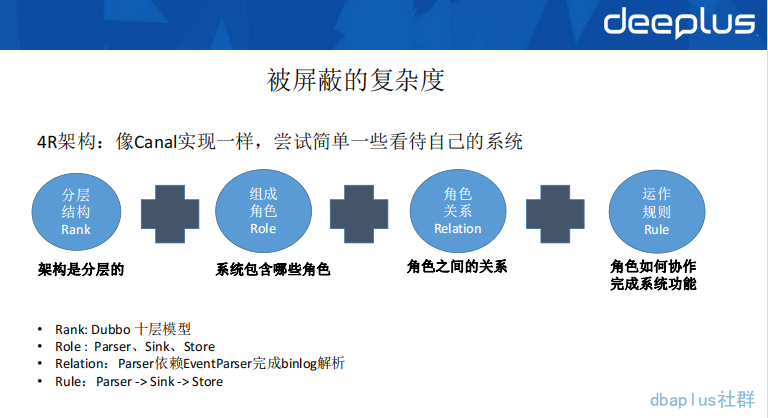
大家是否发现,我在和大家聊 Canal 或是到家的数据异构方案时,更多的都是以角色、关系、规则这种描述方法。相信大家也不是第一次碰到这种描述方式,在很多的架构中,都是这样的一种描述方法。就像上图中,说到的 Parser、Sink、Store。这些角色的职责是什么?他们是如何配合完成 Canal 这样的一个产品功能的呢?
4R 模型本质上就是一个视角,它是 Rank、Role、Relation、Rule 这 4 个单词的首字母构成,它强调了描述方法、也强调了我们要用这样的视角来看待我们的系统。这样整体来看,系统会更加清晰和简洁。
2.区分复杂度

如上图,将复杂度问题分为技术方向和业务方向两个部分,其中灰色的部分,一般都有一些开源软件来帮我们解决,比如 Dubbo、Spring、Canal 等。而红色的部门正是我们日常工作中所不能避免的复杂度。
这些复杂度问题,如果平时不加以重视,忽视掉的复杂度问题最终则会演变成为不可维护的技术债务,最终打掉系统的可维护性,只能重新推倒重来了。很多重构行为都是因为复杂度的忽视累积而成的后果。所以,学会如何区分复杂度就是比较重要的点了。比如这次 Canal 的数据异构,同时面临了数量级复杂度和写入复杂度两个。
3.复杂度的架构设计环
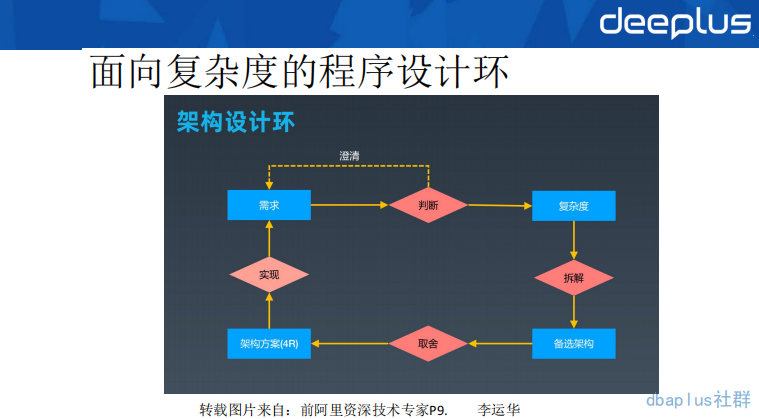
同样,面向复杂度的架构设计方法论,最终会归结到业务实现上。下面描述一下具体的步骤含义:
1-需求:产品同学提出需求描述,或一句话需求、或完善的 PRD 文档
2-判断:对需求进行判断,需要什么样的数据量,什么样的峰值,是否要高可用等等,如果不能理解清楚,则找对应的需求人员不断澄清,直到清晰为止
3-复杂度识别:将需求精确化以后,对需求的复杂度问题进行识别,比如业务复杂度问题、数据量复杂度问题
4-拆解到备选架构:针对识别出来的复杂度设计出多个具体的架构方案。比如采用 ES 存储数据屏蔽分库分表的数据量复杂度、采用数据异构的方式写入数据,从而屏蔽数据写入的复杂度。
5-取舍:对备选架构进行取舍,任何的架构方案都有好的一面和坏的一面。在不同的时间都有不同的选择,这里建议大家从简单、合适、演进三个架构原则来进行方案取舍,选择最适合自己的那一套方案。
6-架构方案 4R:用 4R 视角来设计系统分层、角色、关系、规则。以这种视角设计出来一套抽象模型
7-实现需求:将 4R 架构模型实践即可。
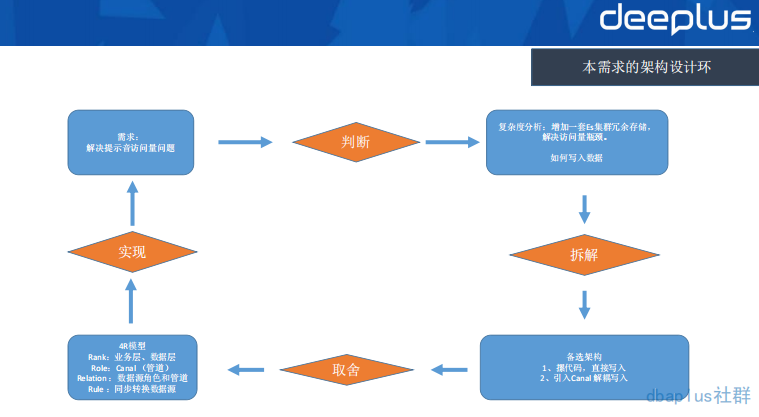
同样,将本需求的一个架构设计环案例呈现给大家。(由于部分设计有保密性,4R 此处用 Canal4R 代替)
以上,就是我和大家分享的全部内容啦,谢谢大家!
Q&A
Q1:订单表中,如果有一些商品 id,那么同步到 ES 中也是 id 吗,不会关联出 name 打成宽表存到 ES 吗?
A1:具体的映射字段需要在 Adapter 中配置映射即可,存入到 ES 中的情况也与配置的映射是直接且唯一关系。是否宽表要在实际应用中把控字段的个数。
Q2:Canal 部署 deploy 主从和 canal-adapter 有没有遇到官方的 bug?有,改动了哪些?
A2:遇到过 Column not match 的异常.具体看 Canal 的 TSDB 来解决。
Q3:这套复杂度方法论如何落地到实际应用?
A3:需要对系统进行 4R 视角拆分、识别复杂度类型并按照架构设计环的方式来评定需求。
Q4:平时的 Canal 有消息延迟吗?
A4:有一定延迟的,binlog 的数量、网络等因素,都会造成一定的延迟,所以,建议异构还是要建立在业务数据可延迟的基础上的。
Q5:我主要用 canal-adapter 读取 Kafka 中的 binlog 日志然后写到数据库中,Kafka 中有多个表的日志,我 rdb 目录下的 yml 文件只配置了一个表的为什么其他的表也会同步?
A5:Yml 的作用是配置映射关系,具体的过滤职能在 Deployer 的 Sink 配置。
Q6:异构数据是直接同步原表吗,还是做了关联?
A6: 做了关联,直接在 Adapter 中配置对应映射关系即可。
Q7:请问为什么不直接增加热集群的节点和分片,而是重新建一套 ES 集群呢?
A7: 这里主要还是一个数据拆分的思想,如果通过提高配置来解决访问量问题,那么,随着业务量级增加,流量混在一起,对应的 ES 集群流程会呈现不可评估的情况。本质上还是一个数据存储职责的问题。
Q8:如何保证 Zookeeper 的高可用?
A8: Zookeeper 本身就是高可用的,如果想在机房或异地方面做高可用,建议做主备同步、多集群部署等手段。
Q9:新集群的查询请求峰值是多少?
A9: 大约 2000-4000 QPS。
Q10:怎么把握冗余尺度呢?
A10: 冗余的维度在机器、机房、地区、国家是不断增加的。维度越大,对应的高可用方案越可靠,但是,对应的费用以及实现复杂度也会变高。因为这种冗余方案肯定会有数据 copy。
嘉宾介绍:
张磊,京东到家高级研发工程师。
8 年+软件研发经验,曾先后就职于链家地产、互动吧、寺库网等公司,任研发人员或团队 leader,在解决业务系统设计落地方面拥有丰富经验;
现就职于达达-京东到家,主要负责订单履约、金额拆分、计费相关业务域的研发设计工作。业余时间主攻软件复杂度优化。
本文转载自:dbaplus 社群(ID:dbaplus)




