
真实的理赔产品中,绝大部分客户是就医或者患病诊断患病之后去找保险公司进行申请理赔,但是其中有一小部分客户他会制造假的就医记录或者带病投保到保险公司骗取保险金,怎么样保证正常投保客户能够正常理赔的保险权益,同时避免骗保客户给公司带来的经济上的损失成为了一个十分关键的问题。近几年,随着 AI 的蓬勃发展和数据的不断积累,从算法技术来讲,很多行业在欺诈风险识别中表现出了非常优异的效果,产生了一些非常好的价值。但由于算法本身属性的原因,模型的结果却难以解释,但这在真实的业务场景中却非常关键。这次带来的分享内容,就是我们在实际的保险理赔反欺诈场景中的一个模型,可解释性的一些探索经验,希望能够给大家带来一些启发,或者一些其他的帮助。
今天的介绍会围绕下面四点进行展开:
模型可解释的整体背景
目前学术界和工业界现有的一些模型解释方法,例子以及对应原理
模型可解释性在实际的场景中的一个具体的应用和实施方案
对模型可解释性的简单的展望
模型可解释性的整体背景

软件工程学上我们经常用到一个术语叫软件的生命周期,这里把它用在模型上,按照模型的生命周期来看,将模型的可解释性总结为三个方面,或者说三个不同时期的作用。
模型的开发和构建。企业模型解释在优化模型的期间,是一个优化模型的一个非常重要的手段。在实际的模型构建的过程中,这种 bad case 分析寻找模型优化方向还是一个比较困难的问题,如果模型可解释,可以对出错的样本采取针对性的措施对模型进行优化。
我们的模型试运行上线期间。模型的可解释性能够提升模型的可信度,同时有利于业务的推广。
模型推广期间,模型预测真正人融入到具体的业务环节流程之中。之后,我们希望这个模型能够可以解释模型预测值的解释内容,能够对后续的一些业务上的处理环节带来指导性的作用。
模型解释性方法
1. 模型解释性方法
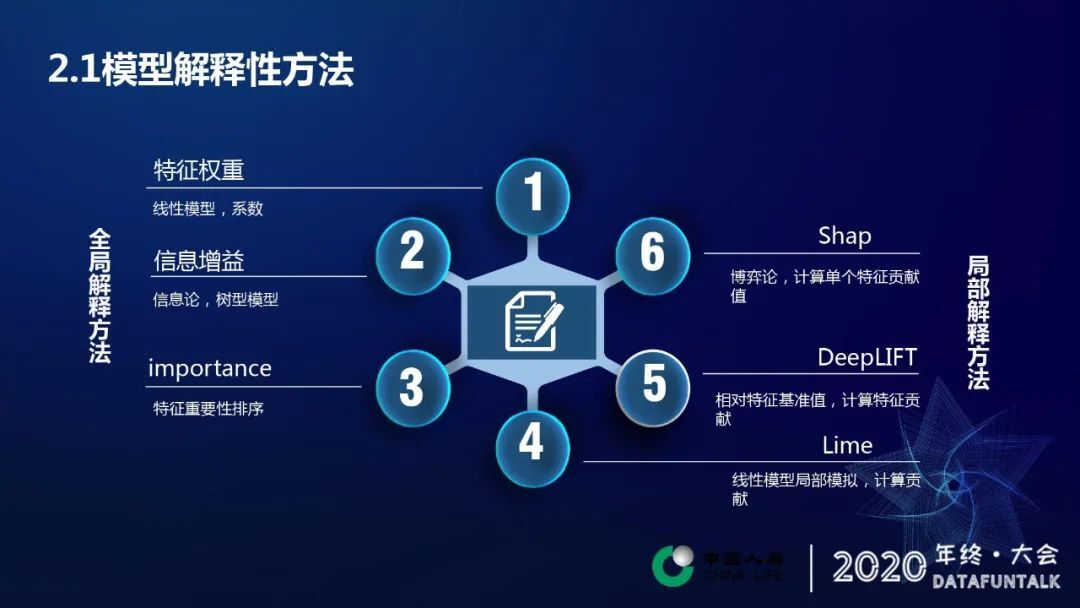
全局的解释方法(全局就是我们考察更偏重对模型整体的一个预测的解释):第一个特征权重,每个特征的权重代表着特征对预测结果的一个影响程度,本质上其实这个权重系数就是一种显示性。第二个信息增益,可以计算出某个特征对预测结果带来的信息量。第三个特征重要性,特征重要性很大程度上就可以解释模型预测的一个判断依据。
局部的解释方法(对这个单条的预测进行解释):第一个 LIME,它本质上是用线性模型在一个局部的样本空间上进行一个模拟。第二个 DeepLIFT,计算每个特征值的一个基准值,然后计算某个特征取值相对于基准值的变动对于预测结果带来的一个提升和影响。第三个 Shap,它本质上是基于博弈论的一种计算方法,计算也是计算特征的贡献。
2. 模型解释性方法-特征重要性
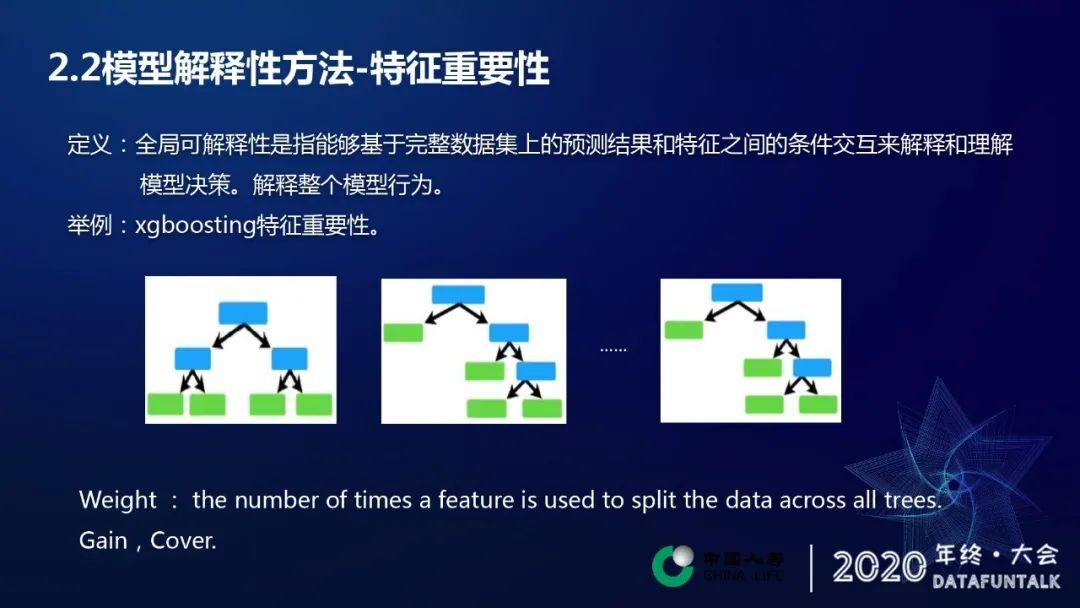
从定义上看,全局可解释性是指能够基于完整数据集上的预测结果和特征之间的条件交互来解释和理解模型。简单地理解来,它就是他解释整个模型的行为。举个常见的特征重要度的算法,是每个特征被引用的次数,对次数的值进行一个排序,次数越多,排序越靠前,对应特征越重要,这样就作为模型一种非常直观的解释方法。
3. 模型解释性方法-lime
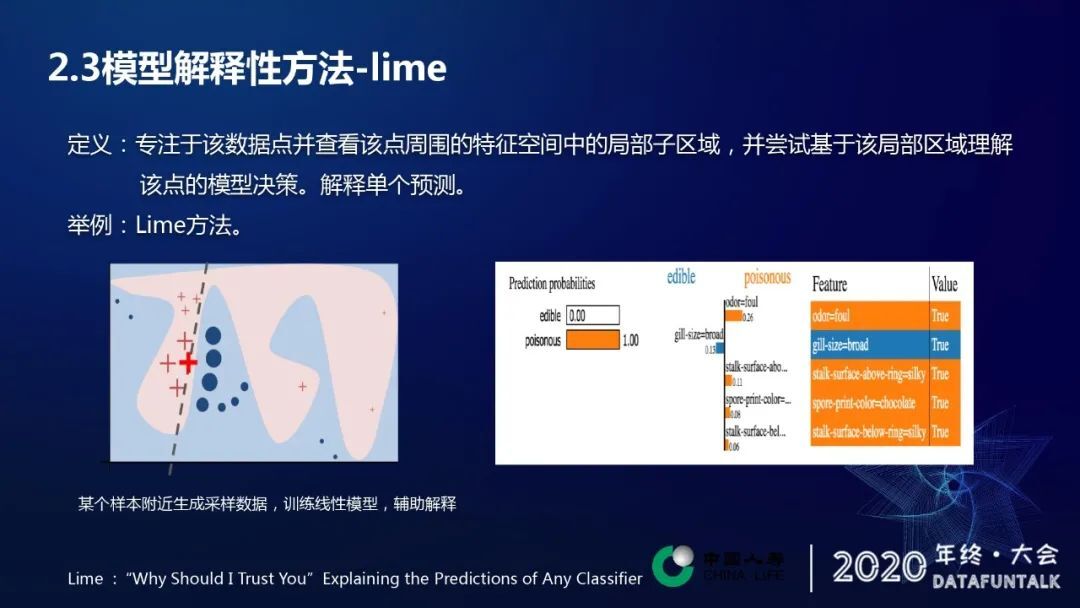
lime 方法其实是非常流行或者非常常见或者经常被大家拿过来讨论的一种方法。它是一种局部解释方法,局部解释性专注于该数据点,并查看该点周围特征空间中的局部次区域,并尝试基该局部及区域去理解该点的模型决策。简单理解为它是解释单个预测样本。以 ppt 中的红叉对应的样本点为例,在选取的样本点的附近选取一定数量的样本点,利用这些样本点重新训练一个简单的模型,如线性模型,然后利用这种解释性较好的方法来解释预测样本。
4. 模型解释性方法-shap
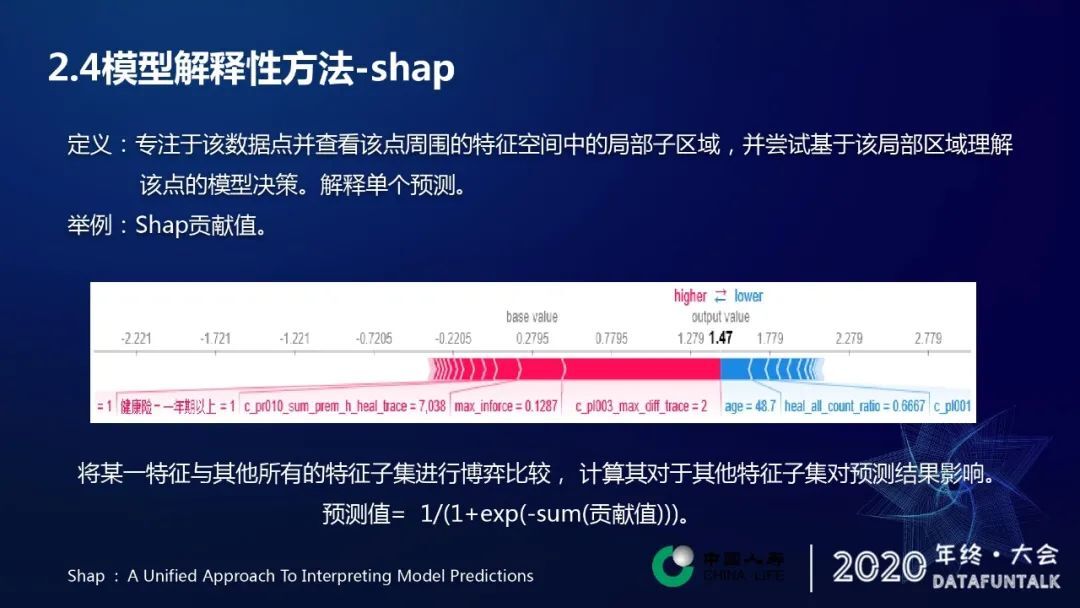
修改方法中将某一特征与其他所有特征子集进行博弈比较,计算其对于其他特征子集对预测结果的影响。预测值和各个特征的贡献值之间存在着这样的映射关系,预测的所有的贡献值求和,代入如上图所示方程式中,得到对应的一个预测样本。其中红色代表对于预测结果具有最大的优先贡献,蓝色的与之相反,对应的是负向的贡献,框的长度代表贡献的绝对值的大小。
5. 模型解释性方法-选型
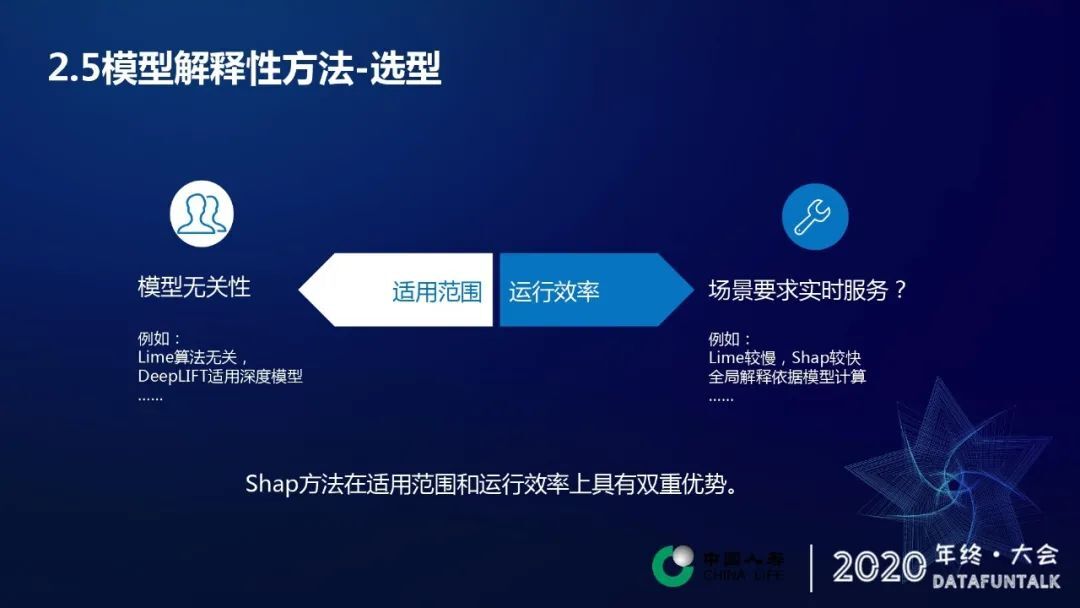
实际的使用过程当中,还需要面对一个选择的问题。两个方面需要考虑:
解释方法的适用范围:在实际场景中,其实我们能希望某一种解释方法与模型无关,或者说至少适用于实际的我们使用的模型算法。
解释方法的运行效率:在实际场景中,需要根据场景对运行效率的要求做出适当的选择。对于那种实时服务的响应要求的服务,或者多长时间之内必须要反馈结果,那么这个时候我们就需要考虑这个方法的解释方法的一个运行效率。
综合以上因素考虑,Shap 方法具有一定的综合性优势。理赔反欺诈实践中也采用了这样上的这样一种方法。
可解释性实践
1. 可解释性实践-场景
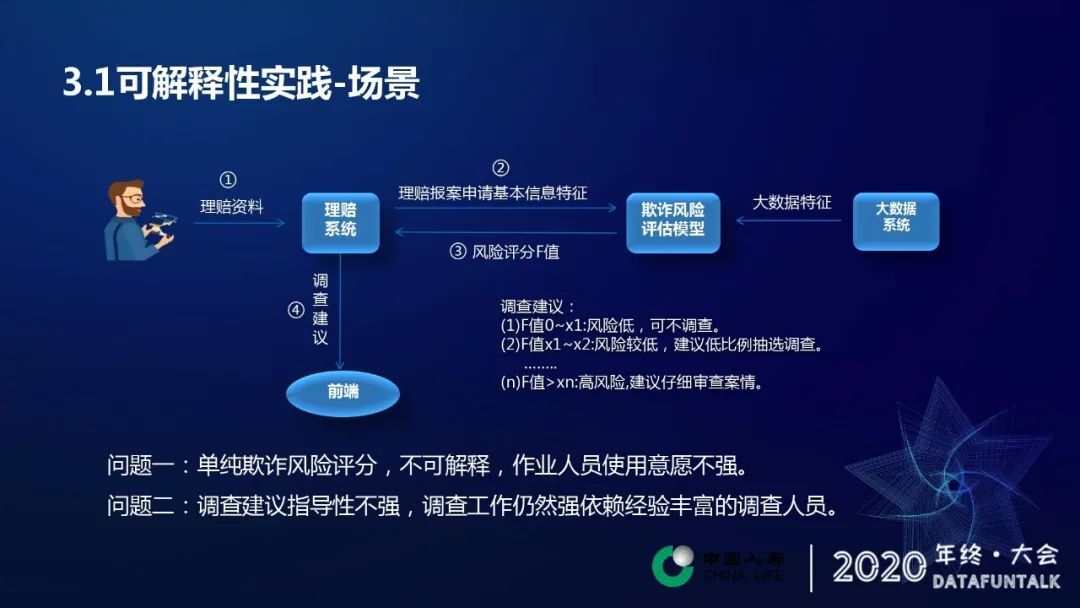
保险理赔反欺诈的一个具体应用场景:
客户会向理赔系统提交理赔申请
理赔系统将理赔相关信息会传入反欺诈模型接口
接口根据理赔信息,一些基本的信息,以及在我们大数据系统中的一些既往历史数据,然后进行整合,进行一个综合的模型预测。
遇到的两个问题
一个单纯的欺诈风险评分是不可解释的。
模型预测的结果对于调查建议的指导性不强。
2. 可解释性实践-方法
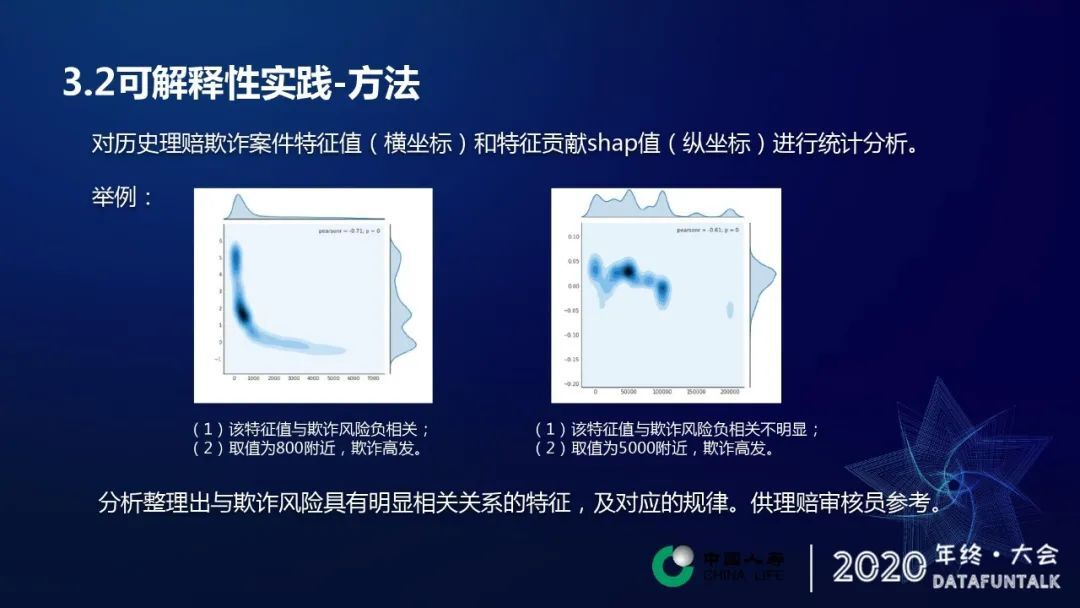
针对上述问题,采用 shap 方法进行解决。对历史理赔欺诈案件特征值和特征贡献的 shap 值进行了一下统计分析。由上述 ppt 中左边图看出,横坐标代表某一个特征的取值,纵坐标的是特征的贡献值,图中的每一个点代表是一个欺诈样本,我们通过这样一个热图可以发现从这张图上发现两点内容,一个是特征与其欺诈评分或者欺诈程度是呈一个负相关的,因为我们明显能看到大概有一个随着特征值的增加,有一个递减的这样一个过程,第二个特征特征值在取值在小于 1000800 附近,这个地方就是它的热度是最高的,说明在附近欺诈案件是非常高发的,因为这个颜色是最重的,欺诈样本的密度也最高。从右图中可以看出特征与欺诈程度没有明显的相关性,但在特征值在取值在 5000 附近的时候,欺诈案件是非常高发的。这两个规律可以反馈给我们的业务人员去使用,或者是做一些启发性的东西,方便他们进行后续的使用。
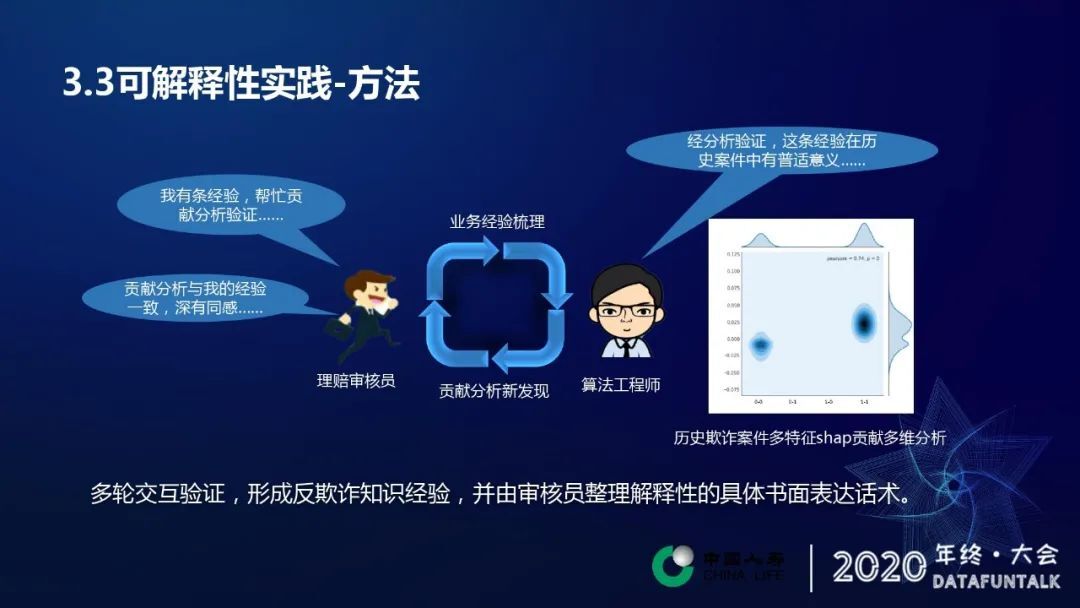
除了一维特征,也可以和业务人员共同进行各个特征交叉情况下对多维特征进行 shap 值分析。举个简单例子,上述图中是两个类别特征的交叉分析,其中,每个特征都只有 0,1 取值。从图中可以看到,两个特征变量都取 1 时欺诈风险较高。我们可以将分析结果我们会反馈给我们的理赔作业人员,有由于作业人员来根据实际的工作经进行一个验证,然后去整理出具体的书面的表达话术。另一方面这个时候我们的理赔作业人员也有可能会自发地去总结一些他自身的经验,然后通过这样一个反馈给我们的算法工程师,不断的循环往复,从而得到更丰富的欺诈经验。
3. 可解释性实践-应用
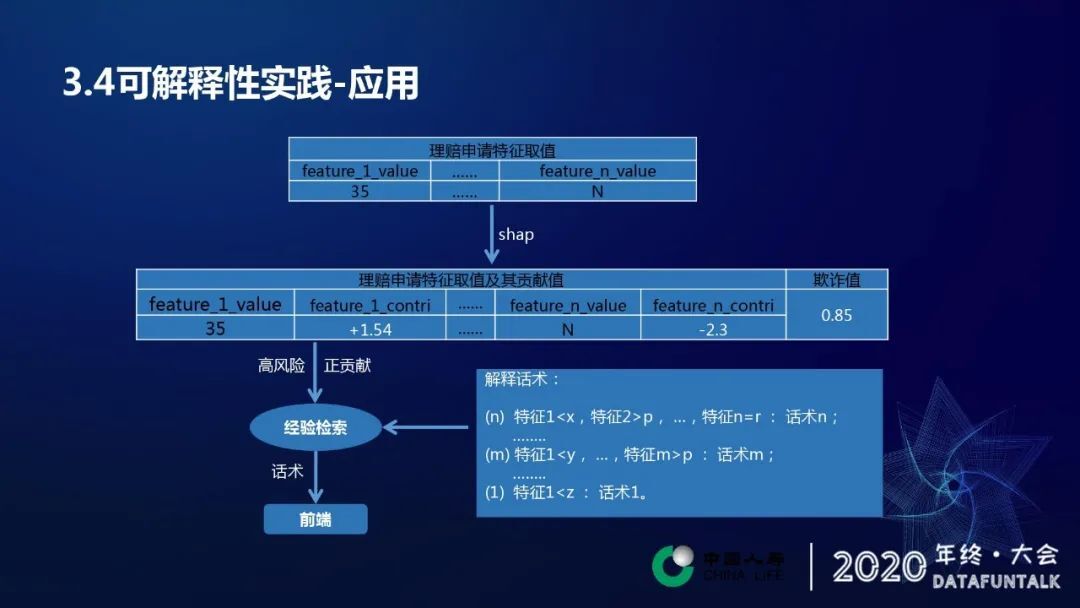
我们可以从上面看这个例子,最上面的表格是我们理赔反欺诈模型考察理赔申请的所有特征,在特征输入模型还有上和值分析的之后,会得到第二行这样一个结果,通过 shap 分析和风险评估预测会得到我们的欺诈值期价值显示是 0.85,代表被欺诈的风险是 0.85,然后同时通过 shap 方法计算出所有的特征的贡献值。然后我们拿到计算结果之后,会做一定程度的筛选。根据业务规则,筛选出欺诈值较高风险的样本,筛选出来之后,我们再去筛选它的特征,根据贡献值去做,筛选出具有对特征值具有正向贡献的几个特征值,然后拿到这几个特征及其特征取值进行检索。右边这张图是根据分析做出来的经验规则,比如说最简单的开始,可能从一味的去考虑特征一小于某一个数的时候,它可能就是一种欺诈的迹象。这个时候我们的理赔作业人员总结出来,这样一个经验和话术就会显示在这里,然后扩充到二维,比如特征一小于 Y 特征 M 大 P 或者说其他更高维,特征一小于 X 特征二小 P…特征 N 等于 R 的时候,这样的话也有对应的一个话术显示,通过这样一步的检索过程,就是我们把这些能够碰撞上的规则以及经验显示到给我们前端从作业人员做参考,指导他们进行后续的业务开展。
可解释性展望
简单展望:
图技术:图这种数据结构的话,它具有比较天然的可解释性的优势,比如说它有自己的实体,有自己的属性,实体属性之间它有相互的之间的一个关系。当然这两种技术的话可能是差别比较大,找到这样一种桥梁,能够让他们两个联合起来,或者说一种方式能够相互配合起来,也是一个比较困难的事情。
模型蒸馏:模型蒸馏也是被广泛采用模型整理的一个整体思路就是用一个结构简单的模型在保证准确率下降不是太大,或者说在我们一个可接受的范围之内去尽量的去简化这模型,把这个模型变得更简单,因为我们更加简单的模型的话,其实它是更容易去解释的,同时也提高了运行效率。
领域知识:在短期内与领域专家和领域的领域知识相结合,设计一套比较可行的落地方案,仍然是一种比较有效的选择。我们能够用这种方式快速落地,快速的实现模型可解释性。
分享嘉宾:
张洪涛
中国人寿 | 算法工程师
张洪涛,中国人寿保险股份有限公司,研发中心,算法工程师。从事人工智能算法在核保、调查、理赔等保险风控领域的应用研究。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:模型可解释性在保险理赔反欺诈中的实践




