
导语:在「个性化图像美学评价」领域,现有方法主要基于图像中所呈现的客观内容进行个性化建模。然而个性化图像美学评价的本质是度量图像所呈现的客观内容被不同的用户主体感知时所激发的美学感受。
因此,图像的客观内容与用户的主观特性共同作用,进而产生差异化的美学评价结果。相应地,理想的个性化图像美学评价模型,也需要同时使用图像内容和用户的主观信息。然而,由于缺乏标注丰富且包含主观信息的数据集,个性化美学评价算法研究进展缓慢。
近日,OPPO 研究院联合西安电子科技大学李雷达教授,结合美学、心理学、用户画像信息等知识,提出了主客观信息融合的个性化美学评价新范式,并开源了带有丰富属性标注的个性化美学评价数据集 PARA,为建模个性化审美偏好提供了崭新的思路和数据可能。
目前,该论文已被 CVPR 2022 接收。美与美感一直是人类追求精神生活的重要部分,也是 OPPO 一直在追逐的理念。图像作为人类社会信息记录与传递的重要媒介之一,广泛存在于多种移动终端和互联网上。因此,图像美学也成为当前计算机视觉与情感计算领域的重要研究课题之一。
图像美学的研究目的是利用人工智能(AI)有效地模拟人类的审美过程,对图像美感进行自动化评估,使得用户获得的图像质量更高,内容更美。该领域不仅涉及计算机,还需要心理学、美学等多个交叉学科的支持。
与一般的计算机视觉任务不同,美学评价具有较强的主观性。受到用户性别、年龄、职业、性格、教育背景等多样化主观因素的影响,即使对相同的图像,不同的用户也会产生不同的美学感受。因此,想要构建准确的个性化图像美学评价方法,需要从图像所呈现的客观内容和用户的主观特性两个维度,共同进行评价算法的设计。
然而,现有的个性化图像美学评价模型往往仅从图像的角度进行个性化美学建模,在研究方法上存在固有的缺陷。近日,OPPO 研究院和西安电子科技大学对个性化图像美学评价进行了全方位的研究,并发表了题为 “Personalized Image Aesthetics Assessment with Rich Attributes”的论文。
论文针对个性化图像美学评价中的客观图像内容与用户的主观属性进行了全面的探索和分析,提出的带条件的 PIAA 算法(Conditional Personalized Image Aesthetics Assessment),是业界首次探讨“用户主观偏好与图像美学相互作用,如何产生个性化品味”的相关工作。
此外,随该算法一并提出的带有丰富属性信息的个性化图像美学数据集也一并开源,打破了学科方面的数据限制。论文已被 CVPR 2022 收录,数据集地址:https://cv-datasets.institutecv.com/#/data-sets
突破学科限制,利用心理学知识设计 AI 数据库
图像美学评价旨在通过计算机对图片的“美丽程度”进行打分。根据审美是否考虑个性偏好,业界将图像美学评价的分为两类:通用和个性化。前者依赖「平均」概念,反映大众美学审美;后者需要考虑到个人独特的审美特点,反映个人的“千人千面”。
与通用图像美学评价相比,个性化图像美学评价也需考虑主观特性、客观属性等更全面的因素,覆盖不同用户审美感知的多样性,具有更加直接的应用价值。但由于当前该领域数据集的标注维度缺乏多样性,个性化图像美学评价的研究面临一定程度的科研挑战性。
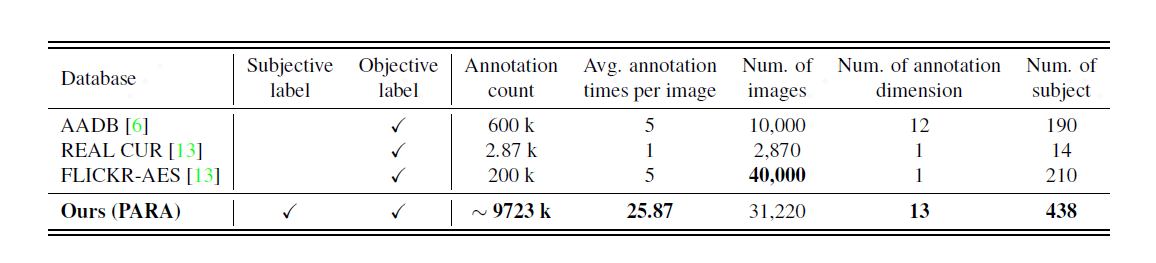
图注:PIAA 数据集之间的比较。此前的主流数据集缺乏主观信息的标签,标注维度和数据规模相对较小。
为了解决上述难题,OPPO 研究院和西安电子科技大学的研究人员利用“跨学科、先验知识”等思维设计了相关数据集和模型。
本文任务
通过丰富的属性标注,实现更加全面的个性化图像美学评价。
本文创新
1.使用跨学科的思维设计了包含主观和客观属性的数据集;
2.通过数据分析探讨主观和客观标注维度的关联性;
3.利用用户画像作为“先验知识” ,提出条件 PIAA 建模方法。
回答业界关心问题
1.数据集如何保证多样性以及解决偏差?
从健康状况、工作经历、个体性格、个人画像四个方面来选择标注人员,保证人员多样性;在从 Flickr 下载约 28,000 张 CC0 图片的基础上,从 Unsplash 网站和 SPAQ、KonIQ-10K 等主流图像质量评估数据集添加大约 3,000 张具有明确美学共识的图像,保证语义和分数分布相对平衡。
2.主观信息中的个人性格特征如何确定?
使用心理学领域权威的 BFI-10 人格调查问卷进行用户摸底,然后计算大五人格特征分数,并添加到标注维度中。
3.如何证明数据库的可用性和优越性?
可用性:baseline 模型的个性化美学评价结果比较准确,测试指标较好。
优越性:设计两种基准模型:有条件和无条件的 PIAA。实验结果显示:加入用户画像信息一组的实验结果高于对照组,证明通过加辅助信息可以超越仅利用美学分数学习的模型。
4.“先验知识”在个性化图像美学评估中能起到什么作用?
建模时加入了三种条件信息,包括个人性格、美学经验以及摄影经验。实验结果显示:利用主观属性信息进行 PIAA 建模可以提高模型性能。
强调主观信息,探究美学评价与个性化之间的相互作用
数据集设计原则
数据集制作分为四步:图片收集、标签设计、人员选择以及主观实验。
图片收集过程中,使用了场景识别模型预测每张图片的场景标签,然后人工修正保证标签质量;随后根据场景标签采样收集了 31,220 张图像。
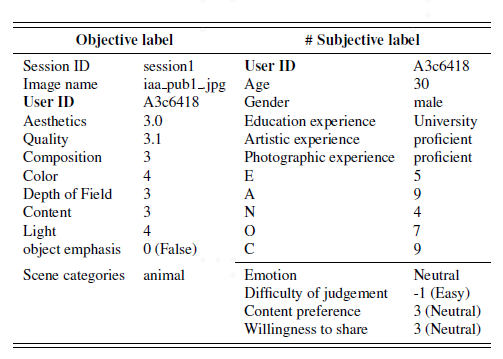
图注:单张图片的标签信息。分为主观、客观两类,通过 User ID 识别。
在参考已有美学评价主流数据集的基础上,设计的标签如上表所示,每张图片的一条“打分”记录都包含 13 个属性标签以及相关联的用户画像信息。13 个属性标签包含 9 个客观属性(例如图像美学、情感等),4 个主观属性(例如内容偏好、分享意愿等)。
人员选择的原则是保证被试人员的质量和多样性,研究员从健康状况、标注经历、用户画像以及培训考核等方面选择“入库人群”。例如,只有具有一定标注经验,身心健康的个体,且通过每日的标注培训和考核后,才可以进行数据标注。
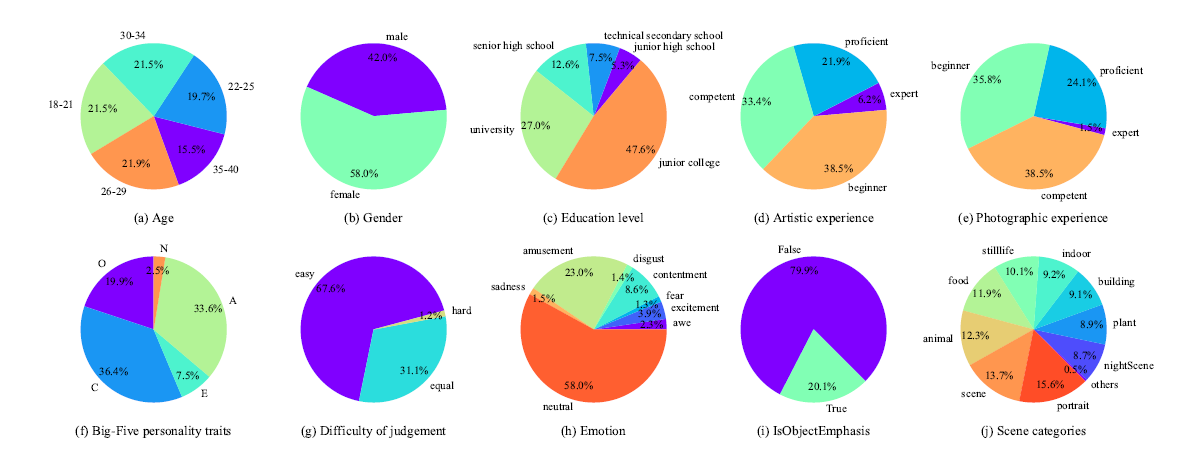
图注:数据库统计分布信息
主观实验遵循心理学主观实验规范。研究员将整个数据库分成 446 个标注会话,每个标注会话包含 70 张待标记的图像,5 张有标记的图像(提前多人标注作为标准图校验标注是否符合通用标准),以及 5 张重复的图像(需要打两次标注的,从而测试标注的一致性)。
数据分析结果
通过分析数据集,研究员发现,每个美学属性的分布是相似的,但也存在微小的差异,这表明各个美学属性相互关联的同时,每个维度仍然能够提供独特的信息。如美学评分(4,5)区间比其他区间有更低的方差,这意味着对 "什么是美 "有共同的认知,但存在不同的审美观点。
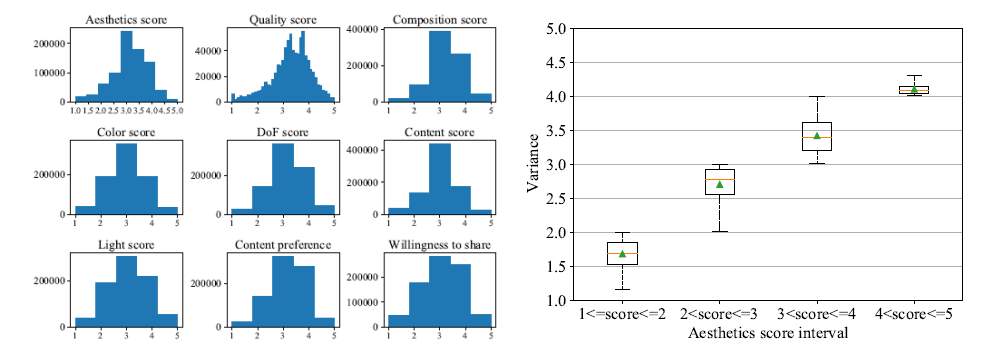
图注:(左)标签分数的分布;(右)美学得分箱线图
同时,进一步分析发现,个体性格、美学评分和美学属性之间具有相关性。例如具有 "神经质(Neuroticism)"性格的受试者倾向于对外部刺激作出过度反应;“内容偏好”和“分享意愿”维度高度相关,证明人们在喜好图片内容时更容易分享照片。
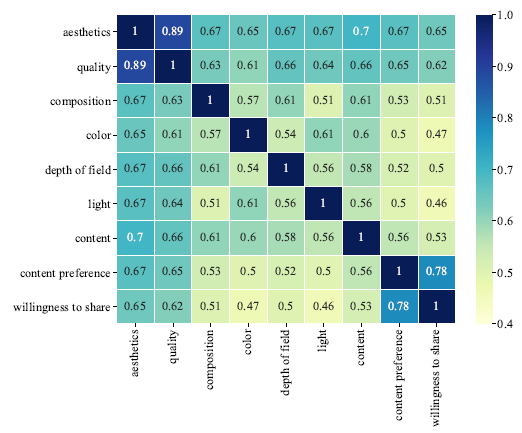
图注:属性维度之间的相关系数
基准模型设计
最后,为了证明数据集的可用性和优越性,研究员对数据集进行了基准模型研究。包括有条件和无条件的 PIAA 两种建模方法,训练方式如下图所示。
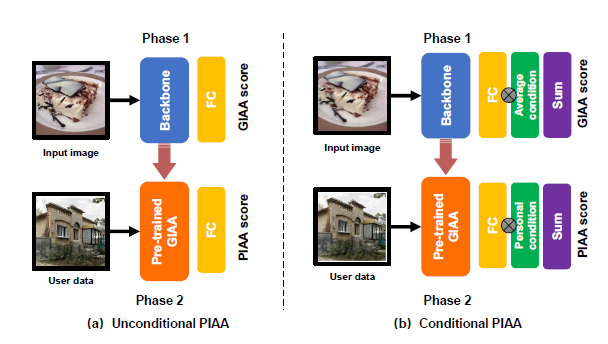
PIAA 模型产生于通用美学评价模型(GIAA),区别之处在于:使用个人数据微调,强调学习个性化偏好。相比无条件的 PIAA 模型,条件 PIAA 建模时分别添加了三种条件信息,包括个体性格、美学经验和摄影经验。由于 PIAA 是一个典型的小样本问题,研究员们参考 零样本学习以及之前的相关工作进行实验设置,例如分为三组:无微调组(“对照组”)、10-shot 组、100-shot 组。
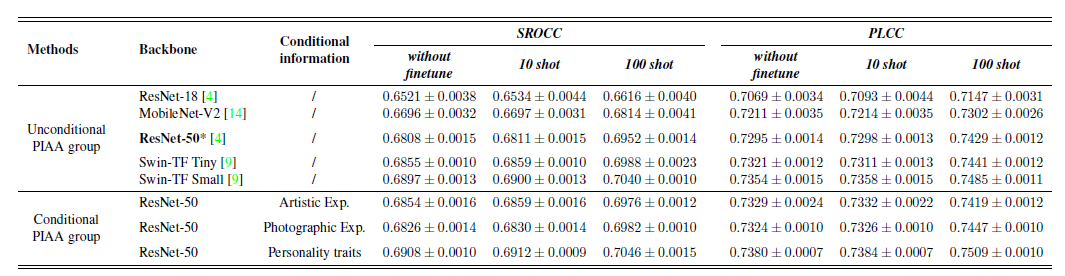
图注:在 PARA 上提出的有条件和无条件 PIAA 的实验结果
实验结果显示,通过对 10-shot 组和 100-shot 组的个性化数据进行微调,PIAA 的表现可以超过对照组;更多的个性化训练数据可以进一步提高微调的性能;与无条件的 PIAA 组相比,利用主观信息进行 PIAA 建模可以提高模型性能。
结语
美学评价类相关研究任务具有很强的主观性,不同的个体有不同的美感认知,通用的美学评价在建模时忽略了个体审美主观性。针对个性化图像美学目前存在的主观性问题,本文提出了结合用户画像信息以及丰富的标注维度的个性化美学评价算法,并开源了所使用的个性化图像美学评价数据集 PARA,打破个性化美学评价学术研究的思路和数据壁垒。
未来,OPPO 研究员会将该数据集以及相关技术应用到相册、相机、互联网内容理解等实际场景中,从而为用户打造更极致的个性化体验。
Project Page: https://cv-datasets.institutecv.com/#/data-




