腾讯 AI Lab 此次公布的图像数据集 ML-Images,包含了 1800 万图像和 1.1 万多种常见物体类别,在业内已公开的多标签图像数据集中规模最大,足以满足一般科研机构及中小企业的使用场景。此外,腾讯 AI Lab 还将提供基于 ML-Images 训练得到的深度残差网络 ResNet-101。该模型具有优异的视觉表示能力和泛化性能,在当前业内同类模型中精度最高,将为包括图像、视频等在内的视觉任务提供强大支撑,并助力图像分类、物体检测、物体跟踪、语义分割等技术水平的提升。
以深度神经网络为典型代表的深度学习技术已经在很多领域充分展现出其优异的能力,尤其是计算机视觉领域,包括图像和视频的分类、理解和生成等重要任务。然而,要充分发挥出深度学习的视觉表示能力,必须建立在充足的高质量训练数据、优秀的模型结构和模型训练方法,以及强大的的计算资源等基础能力之上。
各大科技公司都非常重视人工智能基础能力的建设,都建立了仅面向其内部的大型图像数据集,例如谷歌的 JFT-300M 和 Facebook 的 Instagram 数据集。但这些数据集及其训练得到的模型都没有公开,对于一般的科研机构和中小企业来说,这些人工智能基础能力有着非常高的门槛。
当前业内公开的最大规模的多标签图像数据集是谷歌公司的 Open Images, 包含 900 万训练图像和 6000 多物体类别。腾讯 AI Lab 此次开源的 ML-Images 数据集包括 1800 万训练图像和 1.1 万多常见物体类别,或将成为新的行业基准数据集。除了数据集,腾讯 AI Lab 团队还将在此次开源项目中详细介绍:
-
大规模的多标签图像数据集的构建方法,包括图像的来源、图像候选类别集合、类别语义关系和图像的标注。在 ML-Images 的构建过程中,团队充分利用了类别语义关系来帮助对图像的精准标注。
-
基于 ML-Images 的深度神经网络的训练方法。团队设计的损失函数和训练方法,可以有效抑制大规模多标签数据集中类别不均衡对模型训练的负面影响。
-
基于 ML-Images 训练得到的 ResNet-101 模型,具有优异的视觉表示能力和泛化性能。通过迁移学习,该模型在 ImageNet 验证集上取得了 80.73% 的 top-1 分类精度,超过谷歌同类模型(迁移学习模式)的精度,且值得注意的是,ML-Images 的规模仅为 JFT-300M 的约 1/17。
据了解,“Tencent ML-Images”项目的深度学习模型,目前已在腾讯多项业务中发挥重要作用,如“天天快报”的图像质量评价与推荐功能。
以下是 AI 前线记者对 ML-images 团队的专访内容:
Q:腾讯这次开源的“Tencent ML-Images”图像数据集,与此前谷歌的 Open Images 图像数据集相比,除了数据量变得更大,还有哪些不同之处?
A:相比于 Open Images, 除了图像数据量更大,ML-Images 图像数据集还有两个主要不同之处:
1)更多的可训练物体类别,达到 1 万多种类别,而 Open Images 的可训练类别只有约 7200 种;
2)ML-Images 的图像标注质量更高,因为在标注过程中我们充分利用了类别语义关系(见问题 4 详细介绍),而 Open Images 的训练图像标注来源于已有分类器的自动生成。
A:利用 ML-Images 的图像,科研人员可以设计,训练,验证新的模型和算法;工程师可以利用此次开源的高精度 ResNet-101 模型,快速迁移到其他视觉任务。数据是深度神经网络的燃料,只有充足的高质量训练图像,才能充分发挥深度神经网络的视觉学习能力。
A:大规模图像数据集的构建主要包含图像来源,物体类别集合,图像标注三个步骤。图像来源一般有两种形式,一种是利用图像搜索引擎(例如 Flickr)来爬取, 另一种是融合已有图像数据集。
我们选择利用 ImageNet 和 Open Images 提供的部分图像 URL 进行融合。我们称之为多源数据集融合,其最大难点在于物体类别集合的融合。我们采取的方法是利用 WordNet,将所有数据源中的类别,规范化成统一的 WordID。如果不同类别的 WordID 相同,则可以将它们进行融合成一个类别,即类别去重;如果不同类别的 WordID 在 WordNet 中是同义关系,同样可以将它们进行融合成一个类别,即类别去冗余。
在完成类别的去重和去冗余后,剩下的 WordID 对应的都是含义相对独立的类别。它们的语义关系结构可以从 WordNet 中提取, 从而形成一个完整的、无冗余的、具有统一语义关系结构的物体类别集合,进而完成训练图像的融合与标注。
A:如上述回答中所介绍的,ML-Images 中的类别语义关系来源于 WordNet。常见的语义关系有:
(1)属种关系,比如“马”是一种“动物”,因此“马”是“动物”的子类;
(2)整部关系,比如 “树叶”是“树”的一部分,因此 “叶”是“树”的子类。
从语义关系中可知,如果子类别存在于一幅图像中,其父类别也应该存在。利用这种约束关系,我们可以对自动标注的结果进行快速甄别、矫正,从而得到更精准的标注。另外,类别语义关系还将用来筛选类别共现关系(即不同物体类别同时出现在一幅图像中),而类别共现关系也将为精准标注提供重要帮助。
A:大规模多标签数据集中的类别不均衡主要有两种形式:
(1)同一类别中正负图像的不均衡,即对于一种特定类别而言,其正图像(即该类别存在的图像)在整个数据集中所占的比例往往很小,远小于其负图像的比例。
(2)不同类别间的正图像不均衡。例如,常见大类别(比如“动物”、“植物”)的正图像的比例有可能超过整个图像数据集的 10%,而罕见小类别的正图像比例往往不到千分之一。
针对以上两种不均衡,我们设计了:
a) 带有权重交叉熵损失函数,
b) 损失函数权重的自适应衰减,
c) 负图像降采样,可以有效抑制类别不均衡对模型训练的不利影响。
A:对比谷歌、微软所公布的 ResNet-101 模型,我们此次开源的 ResNet-101 模型具有更强的视觉表示能力和泛化性能,这一点通过迁移学习在 ImageNet 验证集上精度可以体现。之所以能得到这么优秀的模型,主要原因包括 ML-Images 提供的高质量训练图像,和我们设计的损失函数、训练算法。详情可参见下表:
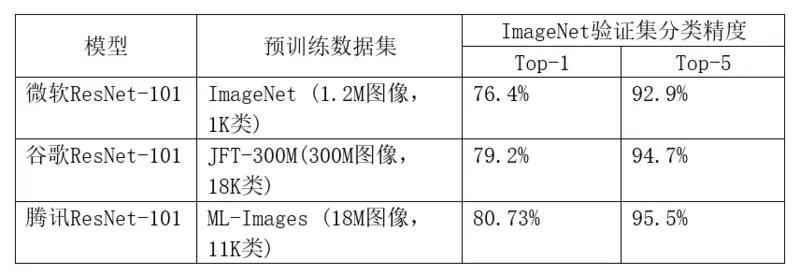
注:微软 ResNet-101 模型为非迁移学习模式下训练得到,即 1.2M 预训练图像为原始数据集 ImageNet 的图像。
A:“Tencent ML-Images”项目的 ResNet-101 模型,目前已在腾讯多项业务中发挥重要作用,如“天天快报”的图像质量评价与推荐功能,显著提高了图像推荐的效果,如下图所示:

左侧为优化前,右侧为优化后
腾讯 ML-Images 团队在采访最后表示,他们将持续扩充数据集的图像数量和物体类别范围。团队还将基于 Tencent ML-Images 的 ResNet-101 模型迁移到很多其他视觉任务,包括图像物体检测,图像语义分割,视频物体分割,视频物体跟踪等。这些视觉迁移任务进一步验证了该模型的强大视觉表示能力和优异的泛化性能。“Tencent ML-Images”项目未来还将在更多视觉相关的产品中发挥重要作用。
该数据集将于本月底正式开源,感兴趣的读者届时可访问此链接:




