今年 9 月,由国际知名科技媒体集团 O’Reilly 举办的 Artificial Intelligence 研讨会,及 Strata + Hadoop World 在纽约召开。TalkingData 有三位数据科学家亲临现场,与来自世界各地的 AI、大数据领域的学者、专家进行沟通。为了能够让国内的小伙伴第一时间了解到大会上各位嘉宾分享的内容,TalkingData 将与 InfoQ 全程合作,第一时间为大家带来大会现场的各种信息,并对最新技术、理论、成果进行点评,帮助大家了解到 AI 及大数据领域各大企业、研究机构的最新观点和研究成果。
路瑶 – 深度学习的创新应用
Interactive learning systems: Why now and how? Alekh Agarwal (Microsoft Research)
这位来自微软的主讲首先用超级玛丽的例子阐述了监督学习的局限,他认为监督学习是一种开环结构,无法自动调整策略,故而无法适应复杂环境,在解决复杂的,难以预估的问题时会陷入困境。比如在超级玛丽游戏中,用监督学习会出现例如卡在管子一侧的情况。而交互式学习是一个闭环的机器学习结构,可以从实际问题中改进自己的性能,从而适应复杂环境。具体的交互式学习包括 reinforce learning, active learning, bandit 等方法,在近年来成为热点。主讲重点介绍了 contextual bandit learning, 特别是在多策略选择上的运用,即在线上的算法运行过程中,如何自动选择并更新当下的最优策略。微软开发了 multi world decision service. 更多细节参考 http://mwtds.azurewebsites.net


Making AI a reality for the enterprise and the physical world Aman Naimat (Demandbase), MARK PATEL (McKinsey & Company)
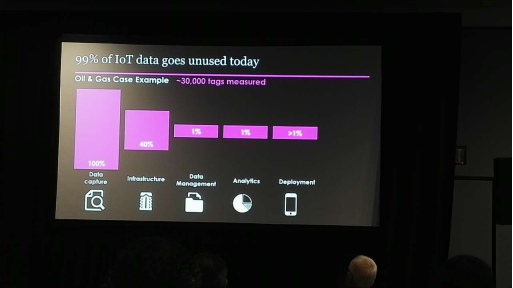
麦肯锡的这个讲座探讨两个问题,一是 AI 如何在实际业务,特别是物理世界中发挥作用,一是 AI 有什么样的潜力。开篇介绍现在 AI 有多火,大量公司如 Google,微软等都在 AI 上投入了大量资金。物联网使得 AI 技术得以在物理世界得以发力。然而现在大量物联网的数据并没有被充分使用。以某油气 case 为例,数据在所有收集的数据中,只有 40% 被架构,1% 被管理,1% 被分析,不足 1% 被真正运用。而如果想要 AI 在物理世界中被运动,关键工作包括去除垃圾,创造盈余,增加易用性,提高质量。随后主讲介绍了在供应链管理中 AI 可以在闭环管理,需求发现,利润优化等方向上发挥作用的可能。具体的,以民主选举为例,AI 如何分析选票,如何从个人在其他领域的兴趣预测他本人的选举倾向,如何预测选举结果。最后总结,AI 将有助于商业模型分解,激励设计,为现有问题提供新价值。

Lessons learned from deploying the top deep learning frameworks in production Kenny Daniel (Algorithmia)
Algorithmia 是一家提供算法服务的公司。用户可以用很少的代码迅速在自己产品上实现关键词提取,人脸识别,情感分析等功能。这个讲座中,Algorithmia 的 CTO Kenny 为我们介绍了在现实项目中大规模深度学习的那些坑。
讲座涵盖了做 DL 的几个痛点,包括 1. GPU 对 DL 很关键,但是现在却不是主流,2. 选择哪个深度学习的框架,3. 如何调节深度学习的模型。GPU 上,无疑 Nvidia 是霸主,性能优越,特别是几乎所有深度学习的主流框架都选择与 CUDA 结合,在这些方面领先 AMD 很多。接下来比较了几种主流深度学习框架的特点,包括 tensorflow,theano,torch,caffe 等知名工具,赞赏了 caffe,特别是在 CV 领域的地位,吐槽了 tensorflow,另外最近在 Kaggle 上表现突出的深度学习高级工具 Keras 也有提及。最后在模型调优上,DL 在训练和运行上都很有挑战,现在很多研究人员为训练上的挑战提供了很多方案,但是在实际运行中的问题关注的不够,Kenny 认为 DL 在运行上的方案优化是非常必要的,而且需要具备和训练模型时候不一样的 skillset。具体的,Kenny 建议在更多硬件上执行更轻量级的模型,也建议了去尝试 SqueezeNet,Docker 等工具。


Leveraging artificial intelligence in creative technology Jennifer Rubinovitz (DBRS Innovation Lab), Amelia Winger-Bearskin (DBRS Innovation Lab)
DBRS 是一家著名的加拿大信用评级公司。DBRS Innovation Lab 专注于大数据技术在 FinTech 上的应用。该公司的开发了交互式可视化分析工具帮助客户理解信用评分,留存管理,以及风险控制等问题。本次讲座着重于介绍他们使用 AI 实现创作性质的工作,比如音乐制作,现场展示了深度学习所作的钢琴曲,听起来简单和谐。其他 demo 包括用 VR 做深度学习计算过程的可视化,用 word2vector 模仿不同诗人的风格作诗等等,特别有趣的是,可以调节一首诗和某两个诗人风格的中和的程度。更多 demo 参见 https://dbrslabs.com
深度学习表现了在创作上的潜力,把动画片转化为不同画风,甚至可以写电影剧本,如今年发布的 9 分钟短片 Sunspring,可以在 YouTube 上观看 https://www.youtube.com/watch?v=LY7x2Ihqjmc
期待未来深度学习在创作型工作上给我们带来更多惊喜。



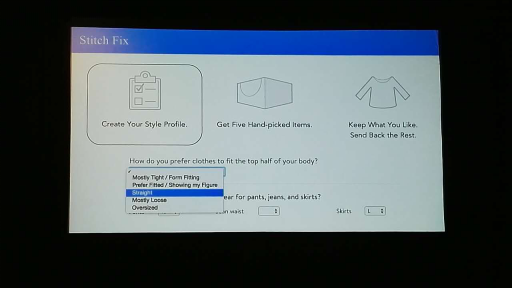
Combining statistics and expert human judgement for better recommendations Jianqiang (Jay) Wang (Stitch Fix), Jasmine Nettiksimmons (Stitch Fix)
Stitch Fix 为线上用户提供衣服选择服务,用户输入自己的尺码喜好等基本信息,算法为用户选择衣服并和用户再进行交互,最终锁定用户要购买的衣服。
服装推荐是电商推荐系统中重要且非常有挑战的一环,近年来的研究已经从简单的单品推荐衍化到更丰富的推荐场景,比如 eBay 的搭配推荐。同时用户的穿衣风格和审美也是科学家感兴趣的话题,而基于风格的用户推荐是服装推荐的一个重要方向。
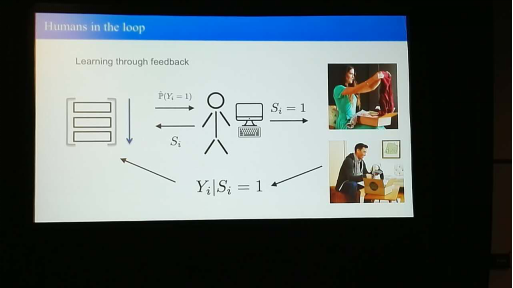
本次讲座介绍了他们如何将机器学习算法和人的反馈结合起来,为用户提供 Fashion 推荐。这里面涉及很多技术点,其中一个重点是如何根据用户的反馈来迅速改进结果。他们尝试了不同的机器学习算法,对比了在选择过程中机器和人的判断对与最终结果来说哪个更可靠,并基于若干具体事例介绍他们的调优技巧。

张夏天 – 微软 CNTK 开源平台以及其他公司的深度学习框架
Progress of delivering real AI workloads 支持真实 AI 应用的进展,Xuedong (XD) Huang (Microsoft Research)


微软在 AI 落地方面做了很多工作,从代理,应用,服务和基础设施方法都做了大量的工作。Cortana 个人助理,能够了解人,了解人的工作和生活,以及我们的世界,并在所有设备上未人提供服务,现在有超过 1.3 亿用户和 120 亿个请求。在应用上,微软用 chatbot 技术来支持客服服务,使得用户自服务的成功率从 12% 提高到 25%. 在服务方面,微软开放了认知服务接口,包括知识,搜索,语言,语音,视觉等方面的识别服务以及机器学习服务。在基础设施方面,微软也将认识能力植入在 Azure 平台上。而支持以上这些能力的一个重要工具就是微软的 Cognitions Toolkit - CNTK。CNTK 现在已经开源,帮助实现 AI 能力的民主化。CNTK 相对于其他深度学习框架,其中比较的优势是随着 GPU 数量的增长,计算能力是线性增长的。而且可以比较容易的支持深度学习集群上的分布式。而且,基于 CNTK, 微软实现了语音识别上的一大突破,将单词的识别错误率降到了 6.2%。
Unlocking AI: How to enable every human in the world to train and use AI 解锁 AI: 如何让所有人都能训练和使用 AI,Matt Zeiler (Clarifai, Inc.)


Clarifai 是一家视觉人工智能的创业公司,该公司对自己的使命是“理解每一张图片和每一个视频来改善人们的生活”。该公司提供简单易用的视觉识别服务,包括 API 和网站两种形式。其服务非常简单易用,最基本的功能就是识别图片,该公司的图片标签有超过 11000 个,通过服务可以识别任何一张图片的标签。除了通用识别模型,该公司还针对食品,旅行等领域提供了领域识别模型,可以更精细的识别某一领域的图片。最让人感兴趣的是该公司提供的定制化推向识别模型训练服务。如果客户需要建立自己的识别模型,只要在现有模型基础上,人通过很简单的代码接口或者网页服务,通过标注少量正负样本图片就可以即时得到一个新的定制化图片识别模型。比如识别你自己养的狗,或者婴儿是不是在婴儿床里的模型。训练一个定制化的图片的识别模型,按传统方法需要数据科学家在昂贵的硬件上,使用大量数据训练几周,而 Clarifai 提供的定制化识别模型,仅需要几秒钟就可以完成此项工作,大大降低了图像识别技术的应用门槛。
Chainer: A flexible and intuitive framework for complex neural networks Chainer: 灵活且符合直觉的负责神经网络框架,Orion Wolfe (Preferred Networks), Shohei Hido (Preferred Networks)


Chainer 是由 Preferred Networks 公司主导的深度学习框架,该公司总部在日本,在旧金山湾区有分支机构。与 TensorFlow 主要面向解决深度学习的规模化问题,Chainer 是完全面向解决深度学习的灵活性问题。Chainer 相信 90% 以上的深度学习问题并没有那么大的规模,都是可以在一台多 GPU 机器上解决的,但是在不同的行业中,比如机器人,机器手,机械自动化等领域,因为面临的问题是多种多样的,并没有标准模型可用,所以需要灵活的深度学习框架能够高效的支持的模型结构的调整和测试, 而 Chainer 就是致力于解决这个问题。因此,Chaine 采用的是命令式语言。Chainer 基于 Python 接口,为了更高效的使用 GPU, 还实现了一个 CuPy 的基础库,使得 Chainer 可以更高效的利用 GPU。目前 Chainer 在 FANUC 的机器臂,丰田的自动驾驶技术,松下的停车位检测和 Amazon Picking Challenge 中取得了第二名的好成绩。
The identities of bots: A learning architecture for conversational software 聊天机器人也有自己的身份:对话软件的学习框架,Suman Roy (betaworks)

<

作为流量入口的移动应用的下载量,活跃量和留存量都有下降的趋势,下一个兴起的流量入口可能就是聊天机器人,各行各业对聊天机器人越来越感兴趣。对话是最有效的沟通方式,但是聊天机器人要做到有效的跟人沟通需要注意几点:1. 推送人需要的信息;2. 能够从对话中了解用户;3. 能够理解社会,理解用户的社会性,比如政治倾向;4. 具有短暂记忆,能够根据对话的上下文来进行交流 ; 5. 具有自己的个性。为什么聊天机器人不使用 Deep Learning 来实现端到端的解决方案?首先因为复杂模型会使得历史数据的价值变差,而历史数据对了解用户很有用。其次,为了防止错误传播的诅咒,必须将技术分层来限制的错误的无限传播。再就是为了使得聊天机器人不冒犯用户,我们需要有办法对聊天机器人进行审计,但是这对深度神经网络是不可能的。
阎志涛 – AI 在生医上的应用
Intel’s new processors:A machine-learning perspective

在 AI 时代,为了提高模型训练的性能,各个硬件厂商也都在使出浑身解数来通过硬件加速机器学习的性能。作为通用处理器的老大,Intel 在这个 AI 时代自然也不甘落后。整个 AI 大会 Intel 和 NVIDIA 都是主要的赞助商,而 NVIDIA 更是称自己为深度学习方案公司。为了应对 NVIDIA 的冲击,Intel 的答案是 PHI。由于目前 AI 的发展极度依赖深度学习,而深度学习目前很多的解决方案都是采用 GPU,Intel 希望自己支持 PHI 协处理器的 XEON CPU 能够与 GPU 抗争,关于新的支持 PHI 的 XEON 和 XEON 的对比,参看下图:

另外 Intel 也针对机器学习和深度学习开发了针对 CPU 优化的算法库,希望能够更好的将开发者吸引到自己的平台和解决方案中。对于 CPU 的选择,如果是普通的机器学习模型训练,Intel 建议还是采用普通的 Xeon E5 处理器,而如果是进行深度学习,则建议采用 Intel Xeon Phi。
相信在未来,Intel 和 NVIDIA 在深度学习芯片领域的竞争,还会持续下去。
Genetic architect:Investigating the structure of biology with machine Learning

提到 AI,一个非常重要的领域我相信是在健康领域,而基因工程无疑是深度学习可以有用武之地的一个非常重要的部分,国内做基因大数据的创业公司也有不少了。这个 Session 就是关于深度学习在基因方面的应用,有两个美女进行分享。在美国听大会,经常会存在两个演讲者进行演讲的情况,国内则很少见,这可能也是文化的区别吧。在这个专题中,演讲者主要讲了为什么基因工程适合用深度学习。基因的编码非常类似于计算机的编码,基因部分有结构,类似于计算机语言,而基因的数据量又非常大,因此基因的解码就非常适合用深度学习来做。深度神经网络非常适合进行基因的测序,并且帮助进行疾病的预测。而应用在基因处理的模型是 AttentionNet,并且通过对比可以发现 AttentionNet 比 DeepBind 和 DeepMotif 相比都有很大的优势。
Achieving Precision medicine at scale:Building medical AI to predict individual disease evolution in real time

听完了 AI 在基因方面的应用,紧接着是 AI 在个人疾病预测方面的应用。演讲者 Ash 所在的公司 Lumiata 是一家 2013 年成立的一家智能医疗创业公司,利用 AI 的能力实时的帮助医院或者保险公司对一个人的疾病进行预测。在这个演讲中,Ash 提到了在精准医疗领域 AI 具有广阔的前景,但是医疗的数据却又很多的挑战,包括数据脏、数据不一致、各种错误的分类、数据缺失、连续数据少,另外由于数据的来源不同,各种数据的整合也是一个巨大的挑战。
笔者相信,在国内医疗相关的数据情况比美国更差,挑战也更大。对于这些脏数据处理,无疑 AI 能够起到不错的作用。这点笔者是深感认同,在大数据时代,任何领域的数据都会面临类似的问题,我相信 AI 在数据处理上有很多可以帮助人们的地方。
对于 AI 驱动的精准医疗,需要三方面的能力:领域知识、数据科学能力、IT 技能,这个和《数据科学指南》中的论述完全相同。具体到支撑实时疾病预测,则和大家认知的差不多:Kafka, Spark,GPU 等等。不知道中国的智慧医疗在未来的发展会是怎样呢?
Beyesian program learning for the enterprise

说是 AI 大会,大部分的技术都是深度学习,不过这个 session 却不是深度学习,是介绍的 Bayesian Program learning,来自于 Gamalon 公司的 CEO Benjamin Vigoda。深度学习依赖于大量的有标注的数据去进行训练,而传统的专家系统则是利用规则以及贝叶斯网络。而 Bayesian Program learning 则是融合数据驱动和规则驱动的一个机器学习系统。整个系统和第一天的 Bansai 的理念有一些类似,都是 Probabilistic Programming 的一种实现思路。从演讲中的例子看,是给定了一个目标照片,然后有一个程序随机的生成线,然后将生成的线的图片与目标照片进行相似度对比,满足要求的留下,不满足要求的抛弃,最终通过这些线就能够生成目标的照片。代码很简单,如下图:

并且演讲者给了一个利用 BPL、人以及深度学习在 one-shot classification 的对比,BPL 的效果最好。在深度学习占 AI 主流的今天,这些新的思路也说不定有很好的未来。
作者介绍:
路瑶:TalkingData 数据科学家 前阿里巴巴算法专家,瑞士洛桑联邦理工大学访问学者,清华大学自动化系硕士。2016 年加入 TalkingData 任数据科学家,负责图算法、时间序列分析等方向。TalkingData 全球算法大赛技术负责人。
张夏天:TalkingData 首席数据科学家,北京邮电大学硕士毕业,长期从事数据挖掘,机器学习相关领域的研究和应用工作。曾在 IBM 中国研究院,腾讯数据平台部,华为诺亚方舟实验室任职,2013 年加入腾云天下任首席数据科学家,全面负责数据挖掘工作,包括移动应用推荐系统、移动广告优化、移动应用受众画像、移动设备用户画像、游戏数据挖掘、位置数据挖掘等工作。同时负责大数据机器学习算法的研究和实现工作。发表学术论文 10 篇,申请专利 9 个。
阎志涛:现任 TalkingData 研发副总裁,领导研发了公司的数据管理平台 (DMP)、数据观象台等产品,并且负责公司大数据计算平台的研发。目前专注于构建一个融合多种计算模型,支持机器学习和数据挖掘的大数据计算平台。关注 Spark、Hadoop、HBase、MongoDB 等技术。超过 15 年的 IT 领域从业经验,一直从事大规模分布式计算系统、中间件、BI 等相关工作。
本科毕业于北京大学大气物理专业,硕士毕业于华北计算计算技术研究所,研究方向为分布式计算系统。在加入 TalkingData 之前,历任 IBM CDL 资深架构师,Oracle 亚太区首席中间件技术顾问,BEA 亚太区首席中间件技术顾问等职务。参与一系列跨国以及大型的国内的中间件、BI 等项目。




