
本文是数据库内核系列文章之一。
这一期,内核杂谈我们跟风来聊一个最近很火的话题:自动驾驶。最近各大互联网公司,纷纷宣布,all in 自动驾驶,开始造车。等等,这不是数据库内核杂谈吗?是的,从这一期开始,内核杂谈介绍一个能自动驾驶的数据库管理系统:这是 CMU 数据库领域的教授 Andy Pavlo 的研究领域之一,self-driving database management。
项目的名称叫 NoisePage(网址https://noise.page/about/)。NoisePage 是一个从头开发的致力于自动管理的数据库系统。通过 machine learning 技术来调整,优化系统参数和对系统进行调优。目前支持的参数包括,但不限于,物理数据库设计如如何建立索引,materialized views,如何对数据进行 sharding;系统参数的调优,数据库 SQL 语句的调优,以及硬件扩容策略。学术研究主要负责构建系统来支持这些自动化驾驶型调优,并且,通过预测未来的查询语句 workloads,来提前做好规划,最终目的是构建一个尽量减少人为干预的数据库系统(额...这是想取代 DBA 的节奏啊)。
看了一下相关的学术论文,已经发表了好几篇了。而且,最近在 Professor Pavlo 搞的 Vaccination Database Talks 系列中他的 Phd 学生 Lin Ma 正好给了一个最新的 presentation(https://www.youtube.com/watch?v=YqW9Pq5488s&t=2047s),欢迎大家去学习一下。
这一期,一起来学习第一篇论文,Self-Driving Database Management Systems,发表于 Conference on Innovative Data Systems Research(CIDR) 2017。对整个自动驾驶数据库系统做了一个综述,并分享了当时获得的进展。
简介
数据库的诞生,SQL 语句的盛行,最初想解决的问题就是把数据存储,管理等复杂的逻辑隐藏起来,让程序员可以通过 SQL 这个 declarative language 来描述想要获得什么样的数据。但随着几十年数据库系统的发展,系统本身变得越来越复杂, 需要配置,优化的地方越来越多。因此也催生了一类专门的职业,DBA (Database Administrator)。DBA 的主要职责就是确保数据库系统可以很好地支持现有的业务逻辑需求 workloads,大到存储,节点配置,小到某个 GUC 的设定来优化 SQL 语句,都属于 DBA 的范畴(在我还在上大学那时,DBA 可是个热门职业,传说 Oracle 的 DBA 工资可高了)。而随着分布式数据库,云原生数据库的诞生,新的趋势却是返璞归真,尽量把数据库系统做得越来越傻瓜化,不需要复杂配置,就可以很好地运行业务逻辑。一是,系统越来越复杂,迭代越来越快,成为一个好的 DBA 越发困难;二是随着人工智能的进步,我们觉得机器可以通过算法来优化操作,做的比人类更好。人类是懒惰的,追求自动化,效率最大化是我们的本性。
当下,已经有很多相关研究在这一领域开展。但是,本文指出,之前的研究大部分都集中在某一个单点领域,比如如何更好地设计物理数据库,如何设计 index,如何设计存储格式,或者 partition scheme;其他的一些研究旨在给出最优化的 GUC 调整来提高 SQL 语句的运行效率。文中也指出了现有研究的一些缺陷。比如,大部分的优化管理都并不是原生于数据库系统中(外部构建);并且更多的是反应式地来提供优化,并不能主动去适应查询语句的变化;大部分的优化都是关注局部,而不能从全局角度来考虑最优。
而本文介绍的研究,是如何从宏观角度,支持自动管理整个数据库系统。并且提出了一种新的架构,即自动驾驶模块需要被构建在数据库系统内部。文中所用的系统是 Peloton,就是 CMU database group 自己构建的数据库系统,用于尝试和支持各种研究。
要使数据库自动驾驶,需要解决哪些问题
第一个挑战就是,如何预测未来的 workloads,即哪些 SQL 语句会被执行。如果能够准确预测这些语句,能解决什么问题? 试想一下,即便只是了解到这些 workloads 属于 online transaction processing (OLTP) 或是 online analytical processing (OLAP),数据库已经可以进行优化:如果 workloads 属于 OLTP,系统可以选择 row-store(行存)来优化写操作,反之,如果 workloads 属于 OLAP,系统可以选择 column-store(列存)来优化读取操作。如果各种 workloads 都有,一个可行的优化是部署两套系统,行存用来优化写操作,然后将数据同步到列存数据库中来支持读取操作。另一种优化方式就是部署 HTAP(hybrid transaction-analytical processing)数据库来同时处理读操作和写操作。
除了预测未来 workloads,还有什么信息可以帮助优化数据库配置?第二个能想到的就是这些语句的资源使用情况。如,需要多少 CPU,多少内存来执行 SQL 语句。如果能够准确地预测这些信息,数据库就可以提前做好准备,来确保性能不受影响。这就好比,DBA 通常会把数据库清理,或更新操作安排在业务需求量最小的时候,比如深夜。
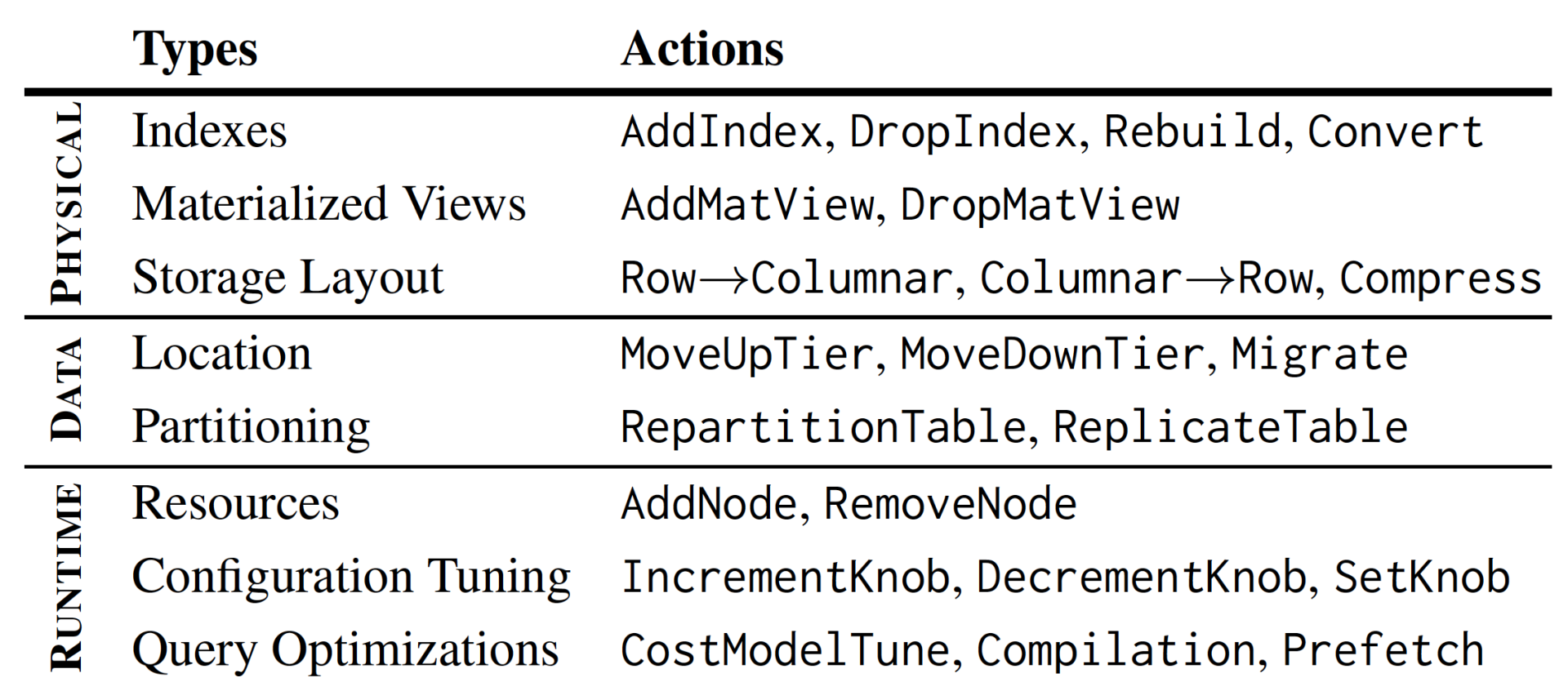
在能够预测未来 workloads 和 resource utilization 的情况下,数据库系统可以支持哪些优化呢?本文给出了三个大类:
1)physical design(物理设计):比如添加或者删除 index,materialized view 来加速查询或者插入操作,选择 row store 或者 column store 来优化写操作或者读操作。
2)data design(数据存储):根据查询语句的需求,对数据进行冷热区分或者进行 sharding 操作。
3)runtime(运行时优化):比如针对 SQL 语句的 optimization,或者 knob 的 tuning,再或者,根据查询语句的容量大小来决定是否需要增加新的计算节点。
文中同时提到,非常重要的一点就是,自动优化的数据库系统必须支持动态地对配置进行更改,致使优化配置能够即时生效。试想,如果一个数据库系统,需要重启才能更新配置,那自动驾驶带来的优化就需要大打折扣了。
总结一下,本文认为,一款自动驾驶的数据库, 应该具备预测 workloads 和资源使用情况,提供多种优化操作,并且支持动态更新配置。
自动驾驶架构
要如何构建一个系统来实现上述提到的种种操作呢?文章介绍的架构基于 Peloton,CMU 数据库小组自主构建的系统。下图给出了具体架构图。
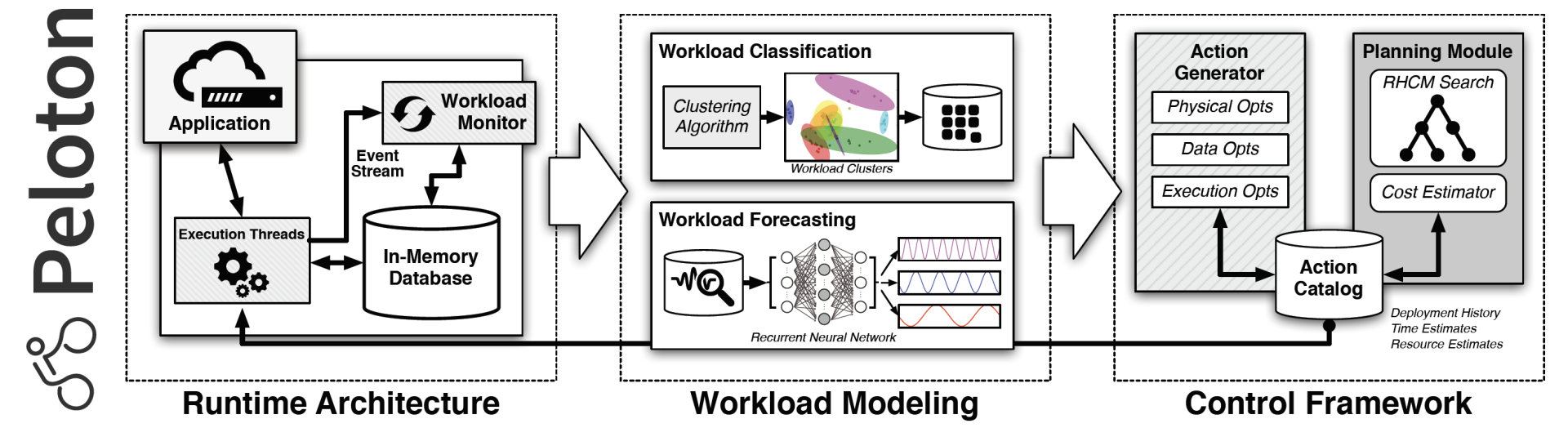
目前市场上的所有自动驾驶,都是人工智能驱动的。自动驾驶的数据库也不例外。而人工智能最重要的就是,数据。因此,整个架构都是围绕数据来打造的。结合架构图,一个部件一个部件来看。
第一个介绍的部件就是用来做数据收集的 workload monitor。Workload monitor 负责收集所有 workload 运行的相关信息,除了 SQL 语句之外,数据操作量,资源使用等,都会被记录。此外,还会定期收集数据库系统随时间流的硬件指标,比如 CPU,内存,IO 使用率等等。
收集了原始数据,第二个部件负责 workload classification(workload 分类)。文中使用的是 unsupervised learning(非监督型学习)来把具有类似属性(characteristic)的语句分到一起。机器学习的术语是 clustering,聚类。聚类的作用就是去重,只为相似的语句保留一个 model 即可,让预测更容易。文中使用的方法是 DBSCAN,是一个已经被验证过的聚类方法。
聚类的挑战在于,什么 feature 属性应该被考虑进去?这样的属性分成两类,语句的运行时 feature 和语句的 semantic logic。前者的好处在于,能够将类似的语句分类在一起,甚至不需要去理解这些 SQL 语句,但这样的 modeling 也会对数据库的任何更改变得敏感,任何物理上的改动都可能使得预测变得不准确。另一个问题就是,当类似的语句在不同的并发程度下运行,那运行时属性就可能完全不一样,这同样使得数据变得不准确。另一个方法就是从 SQL 语句的语义出发,比如物理执行计划,读取了哪些表,用到了哪些 index,等等。这些信息往往独立于数据库本身。文中并没有给出结论哪个更好,应该还处于探索中。我认为,应该一股脑全交给 ML model 来自己决定。以我粗浅的对与深度学习的理解,它要解决的就是能够减少 feature engineering,让 model 自己决定哪些 feature 更重要(欢迎指正)。
在得到了 workload cluster 聚类后,要做的就是预测这些 workload cluster 未来什么时候会再次出现。预测的作用在于能够帮助数据库系统更好地应对未来的 workloads,提前做好配置优化或者扩容等。文中使用的技术,是对于每个执行的语句,tag 预测后的 clusterID,然后通过收集这些 cluster 出现的时间,来预测未来再次出现的时间(对于部署在生产环境中的数据库,大部分的 workloads 应该是具备周期性的,比如定点的 auto script 等。因此,预测并不会特别困难)。文中提到了 RNN 以及 long short-term memory (LSTM) 长,短记忆模型能够更好地预测周期性和重复性的 pattern,也提及了用多个 RNN 来预测模型。
预测了未来 workloads 的模型,下一步就是实施优化来提前让数据库做好准备。文中介绍了管理模块,用来根据预测的模型做出优化决策并实施。第一个部件就是 action generator,负责搜索 action 可以用来优化性能,这里需要提到,优化函数就是减少语句运行的时间,提高性能。但文中同时提到,优化函数是可以扩展到 throughtput,资源消耗等等。那系统是如何做的呢?首先,系统存储了一系列可能的优化 action,并记录了它们对数据库的影响,相当于 step function。
万事俱备,只欠东风。有了 action 库,有了预测 workload 的模型,目前的数据库配置,就可以根据目标函数来产生 action plan 来逐渐逼近目标。文中使用的方法是 control theory, 控制理论来操作。文中提到了 receding-horizon control model (RHCM)模型,是被广泛应用在真.自动驾驶汽车中的模型。 RHCM 的工作原理,简单而言就是,在每个时间周期内,用模型预测可能出现的 workloads,然后在 action catalog 中搜索一系列的 action 来使得目标函数得到最小值(逼进优化目标)。但是,数据库只把这一系列的 action 中的第一个 apply 到数据库当中,等待数据库响应这个 action,然后到下一个周期,再重复上述操作。整个优化过程就可以被类比为一个对树状图的搜索过程,从根节点作为第一个 time epoch。作者也强调,为什么需要一个高性能,并且可以动态更新配置的数据库来支持自动驾驶。因为需要对更新过得数据库系统重新收集数据来判断加载的 action 是否产生了效果。
总结
读完整篇文章,给我最大的感受就是,一开始提到如何自动驾驶数据库系统,完全无头绪。但是作者通过把问题分解成各个步骤,大家是否也觉得,整个逻辑通顺。并且,会觉得,真的,好像这样一步一步去做,就可以实现。 我觉得这就是一流学者所做的,能把一个复杂的问题想清楚,抽丝剥茧,然后找出解决方案。
感谢阅读!下一期,我们接着学习第一个模块,workload forecasting。




