介绍
应用程序通常使用数据缓存来提高性能,尤其针对那些大量应用只读事务的应用程序更是如此。当数据发生变化时,这些应用程序会直接更新数据库。问题在于随着负载的增加,响应时间将随着更新的增长而延长。数据库并不擅于执行大量处理少量记录的并发事务。相对而言,处理批量事务才是数据库的强项。
实际上,随着额外负载的增加,响应时间急剧攀升,数据库就会耗用 CPU 或者磁盘。传统方式下,内存中缓存(in-memory caches)的存储会被限制,以满足 JVM 的空余内存空间。一旦我们需要缓存更多数量的数据,缓存就会不停地释放数据,从而为其他数据留出存储空间。而且,所需的记录必须被不停地读取,从而使得缓存无效,并将数据库直接暴露给完整的读操作负载。
目前已有多个可用的产品,包括 IBM? WebSphere? eXtreme Scale,Oracle Coherence 和 Gigaspaces,它们均支持将一簇 JVM 的空闲内存作为缓存,而不是单个的 JVM。这就使得合并 JVM 越多,缓存支持的规模就越大。如果这些 JVM 都是额外的具有 CPU、存储器和网络的服务器,那么读请求的服务就是可伸缩的。通过使用 write-behind 技术,这些产品还提供更新请求的可伸缩服务。write-behind 缓存的可伸缩性使得它可以解决极端事务处理(extreme transaction processing, XTP)场景。Gartner 将 XTP 定义为:“一种应用风格,目的在于支持对分布式事务处理应用程序的设计、开发、部署、管理和维护,其特点在于对性能、可伸缩性、可用性、安全、可管理与可靠性的特别要求。”
本文将使用 IBM WebSphere eXtreme Scale 演示如何利用 write-behind 模式优化应用程序的性能。write-behind 功能能够根据用户配置的间隔时间,异步地对后端数据库进行批量更新。这一方式具备的明显优势就是能够减少数据库调用,从而减少事务负载,更快地访问网格(grid)中的对象。它比 write-through 缓存具有更快的响应时间,后者对缓存的更新会导致对数据库的及时更新。使用 write-behind,不再要求事务等待数据库的写操作完成。此外,它能够避免应用程序出现数据库错误,因为 write-behind 缓冲通过内存复制单元来保持变化,直到它将其传输给数据库。
定义和配置关键概念
什么是“write-behind”缓存
在 write-behind 缓存中,数据的读取和更新通过缓存进行,与 write-through 缓存不同,更新的数据并不会立即传到数据库。相反,在缓存中一旦进行更新操作,缓存就会跟踪脏记录列表,并定期将当前的脏记录集刷新到数据库中。作为额外的性能改善,缓存会合并这些脏记录。合并意味着如果相同的记录被更新,或者在缓冲区内被多次标记为脏数据,则只保证最后一次更新。对于那些值更新非常频繁,例如金融市场中的股票价格等场景,这种方式能够很大程度上改善性能。如果股票价格每秒钟变化 100 次,则意味着在 30 秒内会发生 30 x 100 次更新。合并将其减少至只有一次。
在 WebSphere eXtreme Scale 中,脏记录列表会被复制,以保证 JVM 退出时仍然存在,用户可以通过设置同步和异步复制的数字,指定复制级别。同步复制意味着 JVM 退出时,没有数据丢失,但由于主进程必须等待获得变更信息的复制品,因此速度会慢一些。异步复制更快,但如果 JVM 在复制之前就退出,就会导致最近事务发生的变化可能会丢失。脏记录列表将使用大型的批事务写入到数据源中。如果数据源不可用,则网格会继续处理请求,之后再重新尝试。网格能够随着规模的变化提供更短的响应时间,因为变化会单独地提交到网格,即使数据库被停止,事务仍然能够提交。
Write-behind 缓存并不能放之四海而皆准。write-behind 的本质注定用户看到的变化,即使被提交也不会立即反映到数据库中。这种时间延迟被称为“缓存写延迟(cache write latency)”或“数据库腐败(database staleness)”;发生在数据库变更与更新数据(或者使得数据无效)以反映其变更的缓存之间的延迟则被称为“缓存读延迟(cache read latency)”或“缓存腐败(cache staleness)”。如果系统的每部分在访问数据时都通过缓存(例如,通过公共接口),那么,由于缓存总是保持最新的正确记录,采用 write-behind 技术就是值得的。可以预见,采用 write-behind 的系统,作出变更的唯一路径就只能是缓存。
不管是稀疏的缓存还是完整的缓存,都可以用于 write-behind 特性。稀疏缓存仅存储数据的子集,可以被延迟填充。它通常使用关键字进行访问,因为缓存中并非所有的数据都能够使用,使用缓存进行查询可能无法执行。完整缓存包含了所有的数据,但在首次加载的时候耗时更长。第三种可行之策则是兼取二者所长。首先在短时间内预装载数据的子集,然后延迟加载其余数据。预装载的子集数据大约在总数的 20%,但它能够满足 80% 的请求。
采用这一方式使用缓存的应用程序适用的场景为:适用简单 CRUD(创建,读取,更新和删除)模式的分区数据模型。
配置 write-behind 功能
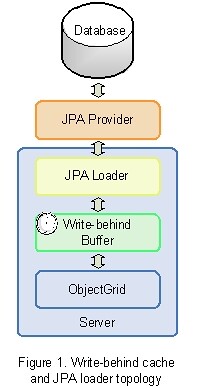
对于 WebSphere eXtrem Scale 而言,在 objectgrid.xml 配置中,通过将 writeBehind 属性添加到 backingMap 元素,就启用了 write-behind 功能,如下所示。参数的值使用语法“"[T(time)][;][C(count)]",用以指定数据库更新发生的时间。当到达设置的时间,或者队列集中的变化次数达到设定的 count 值,更新就会被写入到持久存储中。
列表 1:write-behind 配置的示例
<objectGrid name="UserGrid">
<backingMap name="Map" pluginCollectionRef="User" lockStrategy="PESSIMISTIC" writeBehind="T180;C1000" />
JPA 加载器
WebSphere eXtreme Scale 使用了加载器读取内存中缓存的数据,以及将数据写入到数据库中。从 WebSphere eXtreme Scale 的 6.1.0.3 版本开始,包含了两个内建的加载器,它们与 JPA 提供器相交互,负责将关系数据映射到 ObjectGrid 集中,这两个内建的加载器分别为 JPALoader 和 JPAEntityLoader。JPALoader 用于缓存中存储 POJO,JPAEntityLoader 则用于缓存中存储 ObjectGrid 实体。
若要配置 JPA 加载器,就必须修改添加到 META-INF 目录下的 objectgrid.xml 和 persistence.xml 文件。加载器 bean 可以与必要的实体类名一起被加入到 objectgrid.xml 中。在 objectgrid.xml 中必须定义事务的回调函数,这样就可以接收事务提交或回滚的事件,并将其发送到 JPA 层。persistence.xml 文件则表示一个特殊的 JPA 提供器,它针对具有提供器的特定属性的持久化单元。
考察一个商业案例
考察一个在线的银行网站,当用户数增长时,响应时间变慢,且存在可伸缩性问题。他们需要在现有硬件环境下支持客户需求。接下来,我们就以这一案例来展示 write-behind 特性是如何帮助他们解决这一问题的。
用例:门户个性化
与直接从数据库中拉取用户个人信息不同,我们首先会将数据库中取出的个人信息,预先加载到缓存中。这意味着缓存是为读请求服务,而不是数据库。在旧系统中,个人信息的更新同样是直接写入到数据库。在可接受的响应时间内,随着数据库服务器的超负荷,每秒钟发生的并发更新数将受到限制。新的系统则是将个人信息的变更写入到网格中,然后使用 write-behind 技术将这些变更推到数据库中。这就保证了服务的质量和性能,并完全解除了单实例数据库与读写个人信息操作之间的耦合。现在,客户只需要将更多的 JVMs/server 添加到网格中,就可以扩大个人信息服务的规模。数据库不再成为瓶颈,因为发送到后端的事务数得到了锐减。更快的响应时间带来更快的页面加载,大大改善了用户体验,有效地利用了个人信息服务器的规模,提高了可用性,因为数据库不再成为单一失败点。
对于本用例,我们对 DB2O 数据库采用了 WebSphere eXtreme Scale 以及 OpenJPA 提供器。这一场景的数据模型为 User 与 UserAccount 以及 UserTransaction 之间的一对多关系。下面为 User 类的代码片段,展现了这样一种关系:
列表 2:用例的实体关系
@OneToMany(mappedBy = "user", fetch = FetchType.EAGER, cascade = { Cas-cadeType.ALL })
private Set<UserAccount> accounts = new HashSet<UserAccount>();
@OneToMany(mappedBy = "user", fetch = FetchType.EAGER, cascade = { Cas-cadeType.ALL })
private Set<UserTransaction> transactions = new HashSet<UserTransaction>();
1. 生成数据库
示例代码包含了 PopulateDB 类,它能够加载某些用户数据到数据库中。DB2 数据库的连接信息被定义在之前展示的 persistance.xml 文件中。在 persistence.xml 中的持久单元名(persistence unit name)将用于创建 JPA EntityManagerFactory。用户对象会被创建,然后被批量地持久化到数据库中。
2. 准备缓存
一旦数据库被加载,数据网格代理(data grid agents)就会预先加载缓存。记录被批量写入到缓存中,因此在客户端与服务器之间几乎没有产生通信。还可以使用多客户端 (multiple clients) 来加快准备时间。在准备缓存时,一些“热门”数据可以作为所有记录的子集,其余数据则可以采用延迟加载。预先加载缓存提高了缓存命中的几率,减少了从后端层中获取数据的需要。在这个例子中,匹配数据库记录的数据会被插入到缓存中,而不是从数据库中加载,从而加快了执行时间。
3. 在网格上生成加载
示例代码包含一个客户端驱动器,模仿在网格上的操作,用以演示 write-behind 缓存功能如何提高性能。客户端包含多个选项调整加载行为。下面的命令使用了 10 个线程,以每个线程 200 个请求将 500k 的记录加载到“UseGrid”网格中。
$JAVA_HOME/bin/java -Xms1024M -Xmx1024M -verbose:gc -classpath
$TEST_CLASSPATH ogdriver.ClientDriver -m Map -n 500000 -g UserGrid -nt 10 -r
200 -c $CATALOG_1
4. 结果
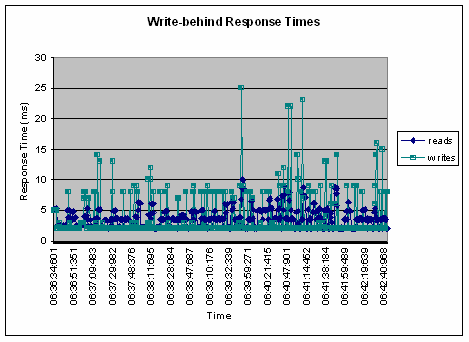
使用 write-behind 特性能够显著提高性能。我们分别使用了 write-through 和 write-behind 技术运行示例代码,比较了各自的响应时间以及数据库的 CPU 占用率。插入到缓存中的数据与数据库中的记录相匹配,这就避免了缓存的准备时间,保证读取的响应时间一致,这样才能比较写的响应时间。列表 3 展示了 write-through 场景下的响应时间,读取数据花费了不到 10ms,而写花费的时间达到了 450——550ms。在执行过程中,网络跳转与磁盘 I/O 操作耗费了大多数时间。列表 4 展示了 write-behind 场景下的响应时间,在这种情况下所有的事务都被提交到网格中。从图表中可以看出,它所消耗的读和写的响应时间几乎相同,都消耗了 2.5-5ms。这两个图表极为明显地说明,对于更新而言,write-through 响应时间更长,而 write-behind 耗费的更新时间几乎与读取操作相同。如果添加更多的 JVM,则能够增加缓存的容量,无需改变响应时间,数据库也不再成为瓶颈。
列表 3:采用 write-through 缓存的响应时间图表
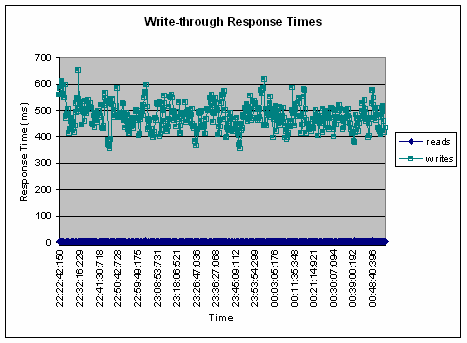
列表 4:采用 write-behind 缓存的响应时间图表
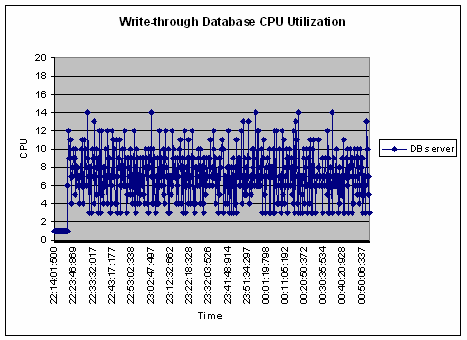
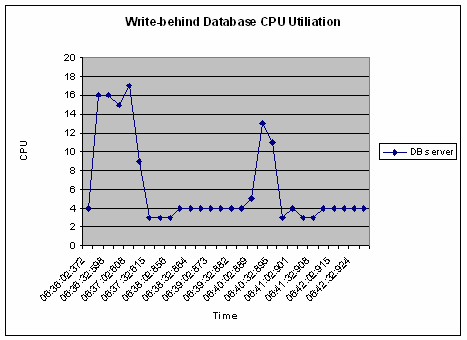
数据库的 CPU 占用率图表展现了使用 write-behind 对后端加载的改善。列表 5 是一幅采用 write-through 产生的数据库 CPU 占用图。可以看见,在运行及时写入数据库的所有更新时,CPU 的使用是连续的。使用时,CPU 空闲状态的波动在 4% 到 10-12% 之间。采用 write-through 技术,后端加载保持了恒定的值。如果采用 write-behind,在满足缓存的间隔时间内,后端的加载耗费了更低的 CPU 占用率,如列表 6 所示。该图显示,当数据库较为空闲时,占用率为 4%,在三分钟间隔时间结束,或者更新记录数达到峰值时,会批量地将更新写入到磁盘中,此时 CPU 占用率会在短时间内达到 12-16%。write-behind 的配置可以调整,以满足自己的运行环境,这其中包括写事务的比例,相同记录更新的频率,以及数据库的更新延迟。
列表 5:采用 write-through 缓存的数据库 CPU 占用率图表
列表 6:采用 write-behind 缓存的数据库 CPU 占用率图表
结论
本文重新审视了 write-behind 缓存技术,并展示了如何在 WebSphere eXtreme Scale 下实现这一特性。write-behind 缓存功能减少了后端加载,降低了事务的响应时间,并将应用程序与后端失败隔离开。这些优势以及它配置的简单性,都使得 write-behind 缓存异常的强大。
参考
- Gartner RAS Core Research Note G00131036, Gartner Group - http://www.gartner.com/
- Gartner RAS 核心研究备忘录 G00131036,Gartner 组织 - http://www.gartner.com/
- User’s Guide to WebSphere eXtreme Scale
- WebSphere eXtreme Scale 用户指南
- WebSphere eXtreme Scale Wiki
资源
- WebSphere eXtreme Scale free trial download
- WebSphere eXtreme Scale V7.0 on Amazon Elastic Compute Cloud (EC2 )
致谢
感谢 Billy Newport,Jian Tang,Thuc Nguyen,Tom Alcott 和 Art Jolin 对撰写本文给予的帮助。
查看英文原文: Extreme Transaction Processing Patterns: Write-behind Caching
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




