
2014 年第一分钟,新浪微博的发布量以 808298 条再次刷新记录,第一秒微博发布量相较去年提升 55%。(数据来源:新浪科技 )这是微博平台 RPC 框架 “Motan” 上线后第一次抗峰值,整体表现平稳,基本达到最初的“应用方无感知”的目标。
在 RPC 服务化这个事情上,微博平台不是第一个吃螃蟹的:早的有亚马逊和 eBay 等国外先驱,近的有 Twitter 的 finagle,淘宝的 dubbo 等等,网上各种公开的资料铺天盖地。另一方面,单纯的 RPC 调用功能实现,从技术上看其实并不复杂:client 发起调用,框架拦截调用信息,序列化,传输,server 端收到调用信息,反序列化,根据调用信息发起实际调用获取结果,再原路返回。实现这些功能可能也就三五天的事情,但在一个复杂的业务环境下,稳定可靠的应用它,才是最大的挑战。
微博平台的 RPC 服务化拆分历程始于 2013 年 7 月。在此之前,我们花了很长的时间讨论服务化的目标,主要是项目的范围:哪些问题不属于服务化项目需要解决的问题。 实际的框架代码开发花了三个工程师(王喆 @wangzhe_asdf9 陈波 @fishermen 麦俊生 @麦俊生)大约一个月时间,然后花了将近两个月的时间推动在第一个业务上线:调整工程师的开发模式,调整测试流程,修改上线系统,添加监控和报警,小流量测试,灰度发布,最后才是全量上线。然后又花了一个月,在微博平台主要业务中全部上线。
微博 RPC 的一些基本的数据指标:
- Motan 框架:2w+ 行 Java 代码,1w 行 test 代码,UT 行覆盖率超过 70%(当前 Motan 实现中,与微博平台内部多个系统都有功能绑定,还不具备开源条件,但开源是我们从一开始就设立好的目标之一)
- 支持 2 种调用方式:inJVM 和 TCP 远程调用。inJVM 方式类似 loopback 网卡:数据经过了协议栈流程处理,但没有流经真正的网络设备。inJVM 方式主要用来支持开发调试和测试,以及在 RPC 服务上线初期作为 Fail-Back 降级使用
- 典型业务场景下单实例 tps 极限 20k,微博平台一般采用单机双实例,即单机极限 40k
- 典型业务场景下平均响应时间 <3 ms,框架层额外消耗 < 0.01 ms
- 最大的单个核心业务日调用量超过 800 亿次
RPC 服务化的目的大约有两种:将一个大一统的应用拆分成多个小的 RPC 服务,那么目的就是为了解耦和,提升开发效率;如果是将传统的 Http 或其它方式远程调用改造成高效的 RPC 调用,那么就是为了提升运行效率。不幸的是,微博平台的 RPC 框架,需要同时达到这两个目的:既要在平台内部将一个大一统的应用拆分,又要考虑到后续向开放平台的大客户们提供 RPC 接入的可能。因此,微博平台在技术选型和方案设计上做了很多的权衡和妥协:
- 首先,是选择已有开源方案,还是自己开发一个新方案?选择的依据按重要程度排序:是否满足自己的核心需求,方案成熟度,认知成本(即二次开发难度)。由于是拆分一个已有的复杂应用,微博平台的一个核心需求是:应用开发方希望尽可能的平滑迁移,最好能做到应用方无感知。我们评估的多个开源方案没有一个能满足,所以只能自己做一个了
- 灵活性与误用的可能性:框架开发方总是有一个偏见,觉得我这个框架越灵活越好,最好每个步骤每个环节都是可以由使用方自己配置或定义。但对于一个内部强制使用的框架来说,使用方式的统一性也同样重要,换句话说,对于大部分的环节步骤,都需要保证团队内部各使用方都按同样的方式进行配置,防止误用,并降低学习和沟通成本。我们的经验是,框架开发完成后,还需要有“框架使用方”角色,将所有的灵活性限制在框架使用方的层面,避免直接暴露所有细节到最终的业务开发方
- 序列化方式选择:微博平台从 2011 年引入了 PB 序列化方式,以替代 cache 和 db 中的 json 文本。但在 RPC 框架上线过程中,我们选择了对 Java 对象更为友好的 Hessian2 。因为之前的 PB 序列化需要定义 proto 文件和生成代码,平台只对必要的 model 类做了支持,而 rpc 可能涉及到更多的 wrap 类,业务逻辑类等,为所有的类提供 pb 支持的工作量太大,而且后期维护困难。当然了,Motan 框架支持各种不同的序列化方式配置。
- 通讯协议选择:在评估了几个开源 RPC 框架的协议设计后,我们最终选择了在 TCP 链接基础上设计自己的 RPC 通讯协议,一个简单的二进制协议:定长 header 中包含一个 length 字段,然后就是二进制的 body payload,即序列化之后的 rpc request 或 response 。
- 集群管理:微博平台 Motan 框架当前依赖于内部开发的 Config Service(Code name Vintage,based on ZooKeeper)来进行服务注册,服务发现和变更通知。
- Trace 系统:微博平台 Motan 框架当前依赖于内部开发的类似 Twitter Zipkin 的 Trace 系统(Code name Watchman)来对 RPC 请求做抽样及全量 trace。
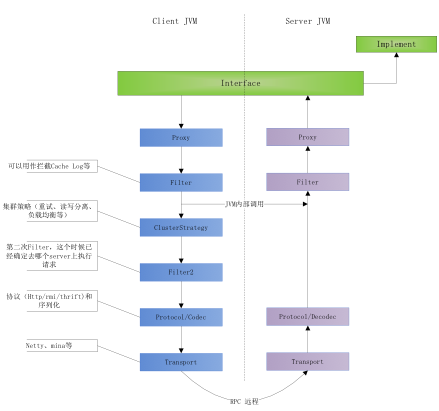
Motan 架构图(RPC 调用数据流图)
一套新的架构在大规模的推广使用过程中总会遇到各种问题,微博平台 RPC 服务化也不例外。总结起来,我们遇到的问题包括:
- 整体服务的 SLA 水平降低。由于前端接口依赖多个后端 RPC 服务,每个 RPC 服务风吹草动都会直接影响接口成功率。初期改造过程中,对 RPC 服务并没有做明确的 SLA 要求,加上前端有些地方对调用超时异常兼容不够,导致前端调用失败几率增加,接口成功率降低。后来我们对每一个 RPC 服务设立了具体的 SLA 要求,并优化了前端重试及失败处理机制,从而保证了整体服务的 SLA。
- 必须提供稳定的测试环境。前期改造过程中,服务调用方在进行线下测试时,由于被调用方同时也在调整,导致经常出现测试环境服务不可用的情况,严重影响了调用方的测试使用。因此快速搭建一个独立的以 RPC 服务为单位的测试环境,在整个服务化过程中还是十分重要的。当前微博平台以 OpenStack 为基础搭建了一套快速测试环境分配系统,支持 RPC 服务粒度的测试环境分配。
- 统一的开发、测试、上线、监控流程。在初期改造中,由于涉及多个部门和开发团队,各 RPC 服务的开发测试上线流程都沿用原来团队的做法,不统一,导致多个互相依赖的 RPC 服务同时上线新版本的时候,经常出现衔接不上,无法线下集成测试,只能线上测试的情况,严重影响业务迭代速度。后来平台通过搭建一套统一的 CI 流程以及优化运维上线系统,初步解决了这个问题。
微博平台 RPC 服务化拆分的故事,2014 年依然继续:当前 Motan 框架完成了在微博平台的核心业务上线,接下来,我们的工作重点方向包括:
- 多语言支持:RPC 多语言支持很难,如果没有特别的理由,建议绕过。RPC 多语言有两种不同的思路:一种是类似 Thrift/PB 定义语言无关的 proto,自动生成对应语言的代码;另一种是没有 proto 定义,只有文档规范说明,业务方自己实现,或者使用框架自带的 lib 实现,类似 Hessian/MsgPack 。微博平台选择的是第二种,当前已经支持 PHP client (兼容 Yar 协议),以及 C Server 。
- RPC Service 运行时环境支持:为 Java 和 C service 提供统一的运行时环境支持。对于 Java RPC Service,目标是让业务方像写 Servlet 一样写 Service,统一打成 war 包后在 Tomcat 中运行;对于 C Service,将业务代码抽离成 so,由框架进行加载。
- 标准化 RPC 接口改造,并推广到其它部门及开放平台使用:将当前平台内部的 Service 改造成类似微博 OpenApi 那样的标准化接口,推广给其它部门使用,并最终通过微博开放平台,开放给外部开发者使用。
微博 RPC 团队招聘进行中,欢迎感兴趣有想法的同学们一起来参与!
关于作者
唐福林( @唐福林),微博技术委员会成员,微博平台资深架 构师,致力于高性能高可用互联网服务开发,及高效率团队建设。从 2010 年开始深度参与微博平台的建设,目前工作重心为微博服务在无线环境下 的端到端全链路优化。业余时间他是一个一岁女孩的爸爸,最擅长以 45°凉开水冲泡奶粉。
感谢丁雪丰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论