
MI 攻击
近几年,模型反演(Model inversion, MI)攻击备受关注。MI 攻击是指滥用经过训练的机器学习(ML)模型,并借此推断模型原始训练数据中的敏感信息。遭受攻击的模型经常会在反演期间被冻结,从而被攻击者用于引导训练生成对抗网络之类的生成器,最终重建模型原始训练数据的分布。
因此,审查 MI 技术对正确建立模型保护机制至关重要。
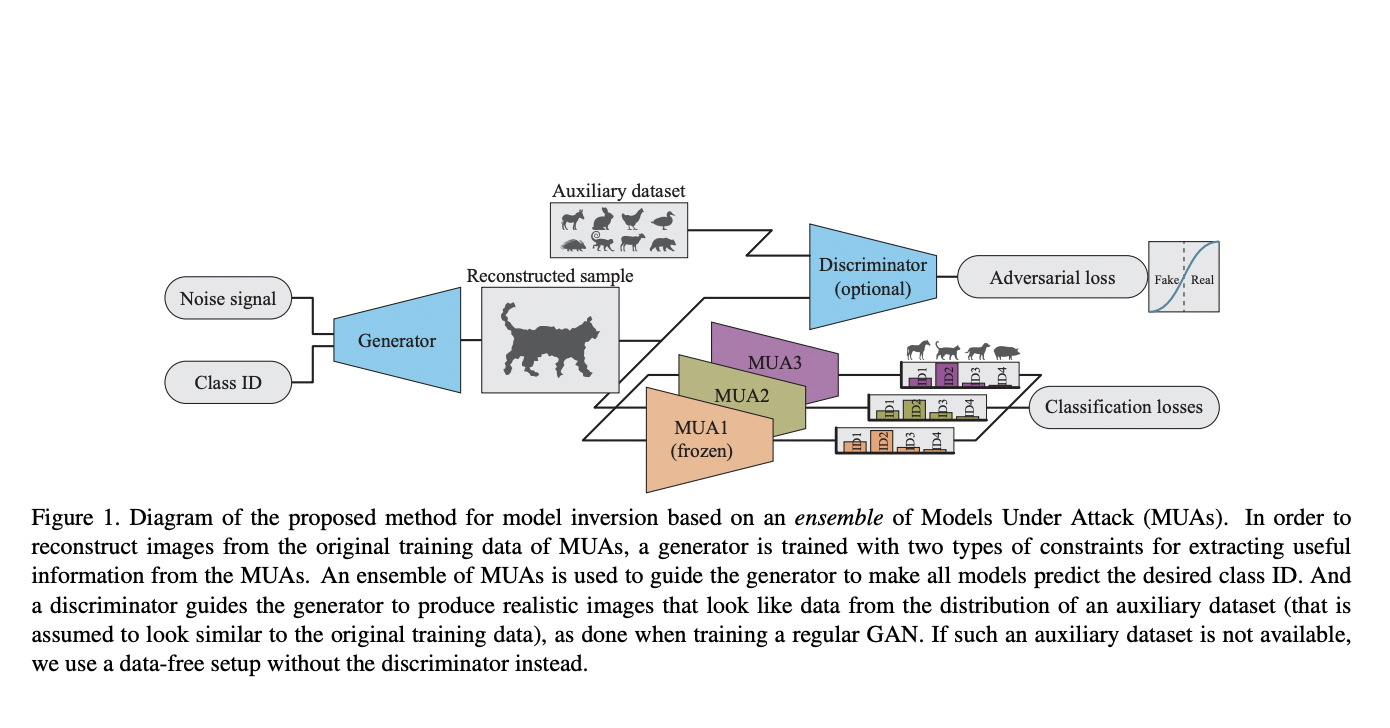
借助单一模型高质量地重建训练数据的过程非常复杂,然而,现有的 MI 相关文献并没有考虑到多个模型同时被攻击的可能性,这类情况中攻击者可以找到额外的信息和切入点。
如果攻击成功,原始训练样本泄露,而其训练数据中如果包含个人的身份信息,那么数据集中的数据本体的隐私将会受到威胁。
集成反演技术
苹果的研究人员提出了一种集成反演的技术,借助生成器来估计模型原始训练数据的分布,而该生成器则被限制在一系列共享对象或实体的训练模型之中。
对比使用单一机器学习模型的 MI,使用该技术生成的样本质量得到了显著的提升,并具备了区分数据集实体间属性的能力。这证明了如果借助与预期训练结果相类似的辅助数据集,可以在不使用任何数据集的情况下依旧可以得到高质量结果,改善反演的结果。通过深入研究集成中模型多样性对结果的影响,并添加多重限制以激励重建样本获得高精确度和高激活度,训练图片的重建准确程度得到了提升。
对比针对单一模型的 MI 攻击,该研究所提出的模型在重建性能上展现了明显的提升。该研究不仅利用最远模型采样法(FMS)进行集成中模型多样性的优化,还创建了一个模型间等级对应关系明确的反演集成,模型的输出向量中的增强信息也被用来生成更优的限制条件,以更好地确定目标质量的高低。
通过随机训练的形式,小批量随机梯度下降(SGD)这类的主流动态卷积神经网络(DCNN),可以使用任意的大型数据集进行训练。DCNN 模型对训练数据集中最初的随机权重和统计上的噪音非常敏感,而由于学习算法的随机性,同一训练集可能会生成侧重特征不同的模型。因此,为减少差异性,研究者一般会使用集成学习,一种简单的技巧来提升 DCNN 辨别式训练的性能。

虽然这篇论文是以集成学习为基础进行的研究,但论文对“集成”一词却有不同的定义。
若想成功对模型进行反演,攻击者不能假定目标模型一定是通过集成学习进行训练的,但他们却可以通过搜集有关联的模型搭建一个攻击模型的集成。换句话来说,在“集成反演攻击”这个语境下,“集成”不是要求模型一定要经过集成训练,而是指攻击者从各种来源所收集到相关模型的集合。
举例来说,研究者可以通过不断收集新的训练数据,对当前模型进行训练并更新结果,而攻击者则可以将这些模型收集为一个集合并加以利用。
借助该策略,无数据的 MNIST 手写数字的反演准确率提升了 70.9%,而基于辅助数据的试验准确率则提高了 17.9%;对比基准实验,人脸反演的准确率提升了 21.1%。论文的目标是,以更系统的方式对现有模型反演策略进行评估。在未来的研究中,需以针对这类集成的模型反演攻击开发相应的保护机制为重点。
结论
论文中提出的集合反演技术,可以利用机器学习模型集合中的多样性特质提升模型反演的性能表现;通过结合 one-hot 损失和最大化输出激活损失函数,让样本质量得到了更进一层的提升。除此之外,过滤掉攻击模型中含有较小最大化激活的生成样本也可以让反演表现更加突出。同时,为确定目标模型的多样性对集合反演性能的影响,研究者深入探索研究了各种差异下目标模型的表现情况。




