
我曾经亲身经历过一次突发事件,某家电子商务网站近七天内的数据遭遇丢失、站点整体也在八天当中彻底陷入瘫痪(而且很明显,工作人员在这八天中一直在努力寻找最新的备份内容,并希望借此执行恢复操作)。这一事件发生之后,我开始研究如何才能构建起一套永久性的灾难恢复(简称 DR)环境。这套环境需要具备成本较低、且能够在出现设施出现故障时以最低程度时间 / 精力投入实现恢复等能力。在今天的文章中,我们将共同了解如何利用 AWS 构建起这样一套灾难恢复解决方案。根据我的当前状况,其每月运行成本不足 1 美元。如果需要,整个恢复周期只需要 30 分钟,而且能够涵盖最高 24 小时之内的数据丢失问题。
该电子商务网站基于 LAMP(即 Linux Apache MySQL 加 PHP)。这里介绍的步骤共分为两个部分——准备步骤与恢复步骤。准备步骤包括首交在 AWS 当中设置环境及数据副本。恢复步骤则包括在尝试上线这套灾难恢复环境时的各项“待办事宜”。
准备步骤:
1) 利用 Amazon Linix AMI 启动一个新的 EC2 微实例,随后安装 PHP、Apache 以及 MySQL。复制网站代码及数据。测试并确保其运行状态与预期相符。创建镜像快照,这将成为该环境恢复过程当中的重要依据。
2) 创建一套规程,并将全部日常数据库备份复制到 Amazon S3 存储桶当中。要完成这项任务,我们需要在生产环境下安装 AutoMySQLBackup 工具,而后添加一个 cron 任务以调用 _automysqlbackup_ 脚本、从而在每天午夜时段创建数据库备份。大家可以通过以下 URL 获取该工具:
http://sourceforge.net/projects/automysqlbackup/
3) 在备份完成之后,cron 任务会将该备份文件复制到一套 Amazon S3 存储桶当中。要实现这一目标,我们需要在生产服务器上安装 AWS PHP SDK,同时创建一套 php 脚本(利用 S3 客户端)以保证系统每天午夜时刻将数据库备份文件复制到 S3 存储桶内。如果大家希望了解与 AWS PHP SDK 安装相关的指令以及 S3 客户端编写方法,请查看以下 AWS 链接:
http://aws.amazon.com/developers/getting-started/php/
以上第二与第三步旨在确保日常数据库备份副本始终存在于远程高可靠性站点(也就是 AWS S3)当中。
恢复步骤:
接下来的各个步骤阐述了如何在 AWS 当中构建辅助环境。
- 通过之前在准备步骤中创建好的 Gold AMI 启动 EC2 实例。
- 从 S3 上下载对应数据库备份文件,并将其导入至 MySQL。AWS 提供能够调用 S3 存储桶当中下载文件(即对象)的命令行 API。举例来说,以下 3 行用于从 S3 存储桶处下载数据库备份并进行导入:
- aws s3 cp s3://bucket-name/db_backup.sql.gz db_backup.sql.gz
- gunzip db_backup.sql.gz
- mysql -u username -p database-name < db_backup.sql
其中 db_backup.sql.gz 部分为我们在负责将副本交付至 S3 存储桶的上传脚本内所使用的 S3 对象名称。
3. 为 AWS Route 53 中的域创建托管区。AWS 利用该托管区将流量路由至 EC2 实例处。
4. 将域名注册供应商的名称服务器指向该 AWS 名称服务器。为了找到该 AWS 名称服务器,点击对应托管区记录,其中名称服务器的值将被显示在 AWS 控制台的右侧。在完成名称服务器更新之后,系统可能需要耗费约 30 分钟到数小时进行全局 DNS 更新。在 DNS 更新完成之后,网络流量的路由走向将由此发生变化。
上述方案的总体使用成本为每月 1 美元到 10 美元之间。以下表格提供的是本示例的基本或者最低使用成本(每月 0.95 美元)。
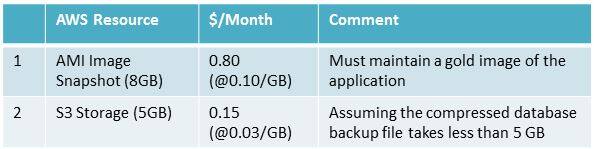
这套解决方案的起效关键在于保证核心 AMI 镜像始终得到更新。如果相关应用程序代码一直在频繁变更,那么建议大家准备一套永久保留实例。整套方案能够用于预生产环境,不过其运行成本将增加到每月 5 美元,具体如下:
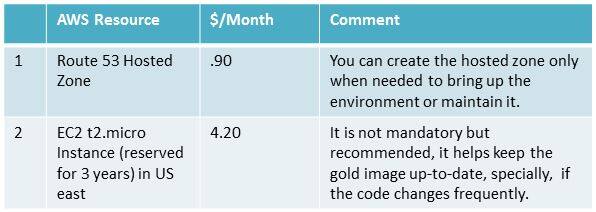
在本示例中,AWS 发挥了巨大的实践价值。保存在任意给定 Amazon S3 存储桶中的数据会在跨地理区域的多座数据中心之间往来复制,而这正是我们实现高可用性水平的必要手段。

原文链接: https://www.linkedin.com/pulse/using-amazon-aws-dr-from-just-1month-devesh-gupta

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论