在用户价值多变的情况下进行软件开发,为了能更快速地向用户交付有价值的软件,开发团队应该专注于用户价值覆盖率,而不是代码覆盖率。
代码覆盖率(Code Coverage)[1] 是一种用来描述程序的源代码被特定的测试套件所测试的程度的度量手段。与具有低代码测试覆盖率的程序相比,具有高代码测试覆盖率的程序会被更加全面地加以测试,并且其缺陷会更少。
代码覆盖率是 Miller 和 Maloney 两人在 1963 年出版的 Communications of the ACM 杂志上首先提出的。对于那时以用户价值变化很少的科学计算为主的软件应用开发来说,开发团队将软件开发质量的重心放到代码覆盖率上是适宜的。但随着强调用户体验的互联网时代的到来,在当前大量的软件开发过程中,用户价值的变化速度已经大大超过 50 多年前的水平。如果开发团队继续“将软件开发质量的重心放到代码覆盖率上”,那么会造成大量的工作时间被浪费在开发和测试已无用户价值的代码之上,从而导致开发有用户价值的代码时间减少,进而延期交付对用户有价值的软件产品。
下图以一个新项目的开发过程为例来说明上述问题。
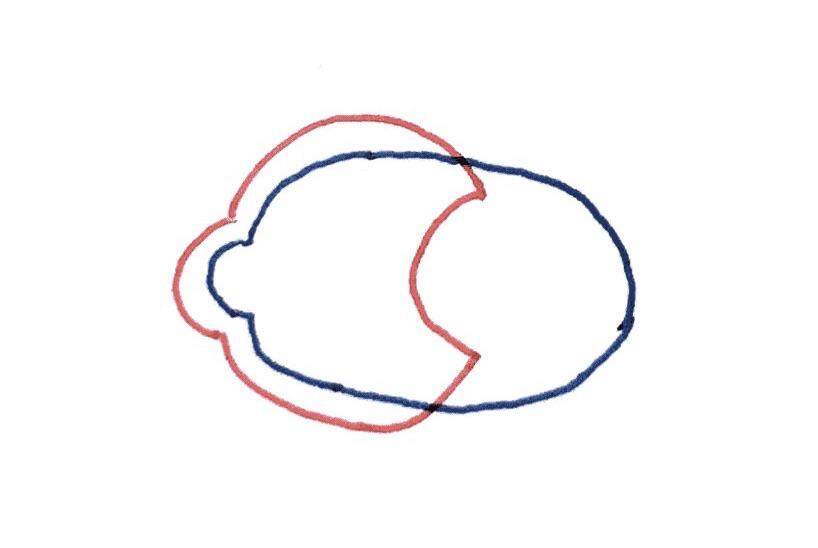
上图中红圈代表团队识别出来并要实现的用户价值,蓝圈代表系统已有的代码所实现的功能,两个圈相交的部分,表示代码实现了用户价值的部分。
在项目启动时,红圈较小,且随着识别的用户价值的增多而不断地增大,另外,它会随着用户价值的变化而不断变化,从而产生移动。此时由于编程工作刚刚起步,所以蓝圈很小。
重要通知:接下来 InfoQ 将会选择性地将部分优秀内容首发在微信公众号中,欢迎关注 InfoQ 微信公众号第一时间阅读精品内容。

随着项目的进展,代码实现也逐渐变多。但由于下面 3 个原因,代表代码实现的蓝圈会与代表用户价值的红圈发生偏离:1)由于诸如程序员和领域专家各讲各自的方言所致的误解等原因,代码仅实现部分甚至没有实现原先识别的用户价值;2)当针对原先识别的用户价值的代码编写完毕后,团队识别出原先的用户价值有部分功能需要删减(用上图中最下边那个右边缺了半圆的红圈来代表);3)团队又识别出新的尚未编写代码的用户价值(用上图中最下边那个左边多了半圆的红圈来代表)。
而在面对上述第 2)个原因中那些不再具备用户价值代码时,程序员会将其删除吗?在自动化测试覆盖不全面、手工测试反馈较慢、代码逻辑和耦合复杂、进度很紧等等这些很“骨感”的现实情况下,程序员往往选择不去删除。“谁会保证在删代码时,不会把系统搞挂?”程序员不删那些已经不具备用户价值的代码,又加剧了红圈与蓝圈的分离。随着过时的用户价值不断被删减,那些不会被删除的已经失去用户价值的代码就会越积越多,这使得蓝圈右侧删不掉的尾巴会越拖越长。
在这种情况下,就出现了“代码覆盖率悖论”:如果 IT 企业只将注意力放到提高代码覆盖率,而忽视提高不断变化的用户价值覆盖率,那么就导致团队会把时间浪费在阅读和测试哪些已经失去用户价值的代码上,从而延误开发那些新演进出来的用户价值,无法快速满足用户需求。
相对“用户价值”这个“终”来说,代码仅仅是一个阶段的“始”。要快速地交付用户价值,我们需要“以终为始”地进行软件开发,将注意力放到以红圈所代表的用户价值这个“终”之上,随着它的不断变化来持续追求用户价值的覆盖率,也就是用自动化测试来把红圈所代表的用户价值保护起来,而不是盲目地追求已有代码的覆盖率。
[1] 引自: https://en.wikipedia.org/wiki/Code_coverage
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




